15.1 权重矩阵初始化
15.1 权重矩阵初始化⚓︎
权重矩阵初始化是一个非常重要的环节,是训练神经网络的第一步,选择正确的初始化方法会带了事半功倍的效果。这就好比攀登喜马拉雅山,如果选择从南坡登山,会比从北坡容易很多。而初始化权重矩阵,相当于下山时选择不同的道路,在选择之前并不知道这条路的难易程度,只是知道它可以抵达山下。这种选择是随机的,即使你使用了正确的初始化算法,每次重新初始化时也会给训练结果带来很多影响。
比如第一次初始化时得到权重值为(0.12847,0.36453),而第二次初始化得到(0.23334,0.24352),经过试验,第一次初始化用了3000次迭代达到精度为96%的模型,第二次初始化只用了2000次迭代就达到了相同精度。这种情况在实践中是常见的。
15.1.1 零初始化⚓︎
即把所有层的W值的初始值都设置为0。
但是对于多层网络来说,绝对不能用零初始化,否则权重值不能学习到合理的结果。看下面的零值初始化的权重矩阵值打印输出:
W1= [[-0.82452497 -0.82452497 -0.82452497]]
B1= [[-0.01143752 -0.01143752 -0.01143752]]
W2= [[-0.68583865]
[-0.68583865]
[-0.68583865]]
B2= [[0.68359678]]
可以看到W1、B1、W2内部3个单元的值都一样,这是因为初始值都是0,所以梯度均匀回传,导致所有W的值都同步更新,没有差别。这样的话,无论多少轮,最终的结果也不会正确。
15.1.2 标准初始化⚓︎
标准正态初始化方法保证激活函数的输入均值为0,方差为1。将W按如下公式进行初始化:
其中的W为权重矩阵,N表示高斯分布,Gaussian Distribution,也叫做正态分布,Normal Distribution,所以有的地方也称这种初始化为Normal初始化。
一般会根据全连接层的输入和输出数量来决定初始化的细节:
当目标问题较为简单时,网络深度不大,所以用标准初始化就可以了。但是当使用深度网络时,会遇到如图15-1所示的问题。
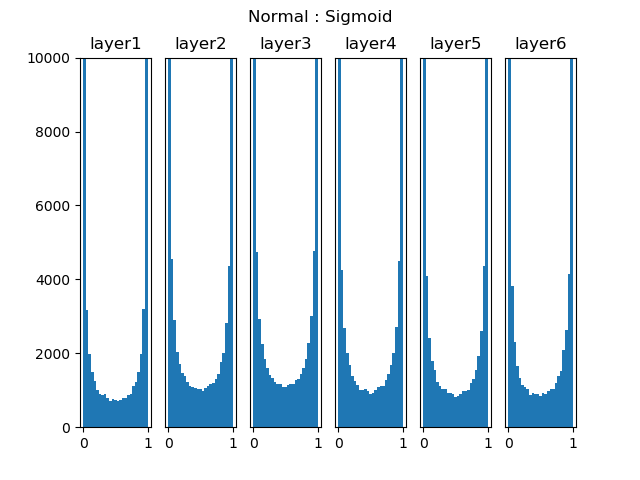
图15-1 标准初始化在Sigmoid激活函数上的表现
图15-1是一个6层的深度网络,使用全连接层+Sigmoid激活函数,图中表示的是各层激活函数的直方图。可以看到各层的激活值严重向两侧[0,1]靠近,从Sigmoid的函数曲线可以知道这些值的导数趋近于0,反向传播时的梯度逐步消失。处于中间地段的值比较少,对参数学习非常不利。
15.1.3 Xavier初始化方法⚓︎
基于上述观察,Xavier Glorot等人研究出了下面的Xavier^{[1]}初始化方法。
条件:正向传播时,激活值的方差保持不变;反向传播时,关于状态值的梯度的方差保持不变。
其中的W为权重矩阵,N表示正态分布(Normal Distribution),U表示均匀分布(Uniform Distribution)。下同。
假设激活函数关于0对称,且主要针对于全连接神经网络。适用于tanh和softsign。
即权重矩阵参数应该满足在该区间内的均匀分布。其中的W是权重矩阵,U是Uniform分布,即均匀分布。
论文摘要:神经网络在2006年之前不能很理想地工作,很大原因在于权重矩阵初始化方法上。Sigmoid函数不太适合于深度学习,因为会导致梯度饱和。基于以上原因,我们提出了一种可以快速收敛的参数初始化方法。
Xavier初始化方法比直接用高斯分布进行初始化W的优势所在:
一般的神经网络在前向传播时神经元输出值的方差会不断增大,而使用Xavier等方法理论上可以保证每层神经元输入输出方差一致。
图15-2是深度为6层的网络中的表现情况,可以看到,后面几层的激活函数输出值的分布仍然基本符合正态分布,利于神经网络的学习。
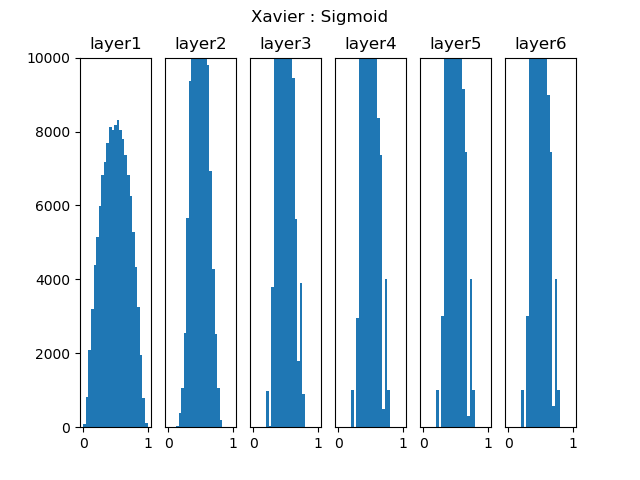
图15-2 Xavier初始化在Sigmoid激活函数上的表现
表15-1 随机初始化和Xavier初始化的各层激活值与反向传播梯度比较
| 各层的激活值 | 各层的反向传播梯度 | |
|---|---|---|
| 随机初始化 | 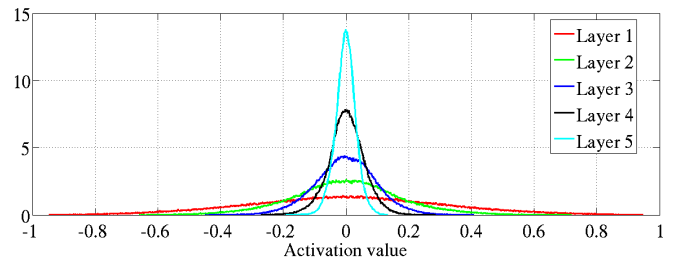 激活值分布渐渐集中 |
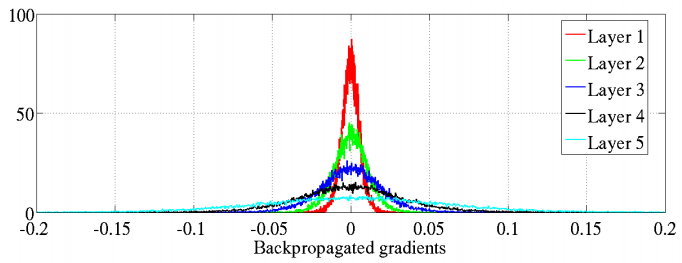 反向传播力度逐层衰退 |
| Xavier初始化 | 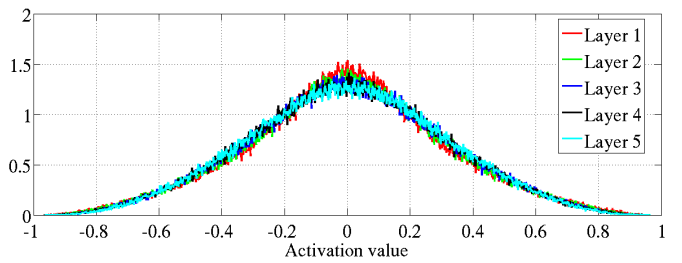 激活值分布均匀 |
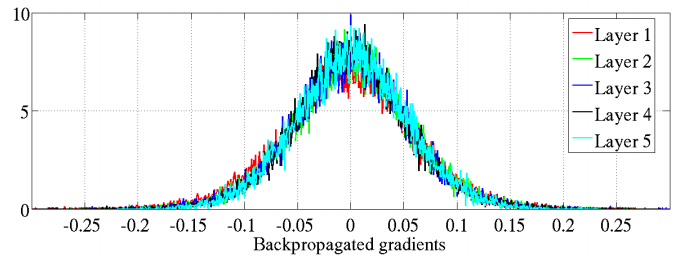 反向传播力度保持不变 |
但是,随着深度学习的发展,人们觉得Sigmoid的反向力度受限,又发明了ReLU激活函数。图15-3显示了Xavier初始化在ReLU激活函数上的表现。
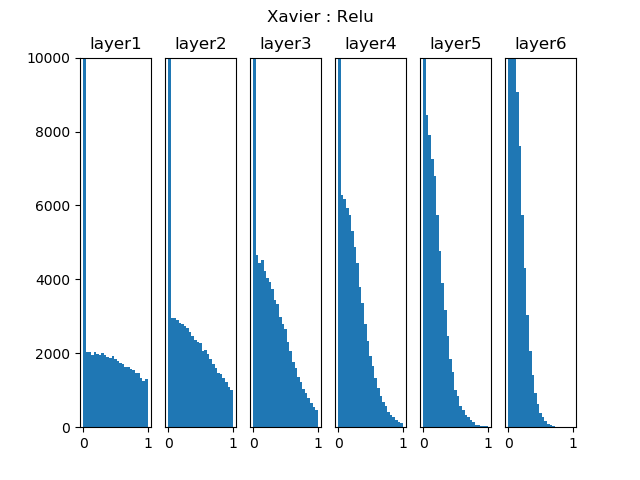
图15-3 Xavier初始化在ReLU激活函数上的表现
可以看到,随着层的加深,使用ReLU时激活值逐步向0偏向,同样会导致梯度消失问题。于是He Kaiming等人研究出了MSRA初始化法,又叫做He初始化法。
15.1.4 MSRA初始化方法⚓︎
MSRA初始化方法^{[2]},又叫做He方法,因为作者姓何。
条件:正向传播时,状态值的方差保持不变;反向传播时,关于激活值的梯度的方差保持不变。
网络初始化是一件很重要的事情。但是,传统的固定方差的高斯分布初始化,在网络变深的时候使得模型很难收敛。VGG团队是这样处理初始化的问题的:他们首先训练了一个8层的网络,然后用这个网络再去初始化更深的网络。
“Xavier”是一种相对不错的初始化方法,但是,Xavier推导的时候假设激活函数在零点附近是线性的,显然我们目前常用的ReLU和PReLU并不满足这一条件。所以MSRA初始化主要是想解决使用ReLU激活函数后,方差会发生变化,因此初始化权重的方法也应该变化。
只考虑输入个数时,MSRA初始化是一个均值为0,方差为2/n的高斯分布,适合于ReLU激活函数:
图15-4中的激活值从0到1的分布,在各层都非常均匀,不会由于层的加深而梯度消失,所以,在使用ReLU时,推荐使用MSRA法初始化。
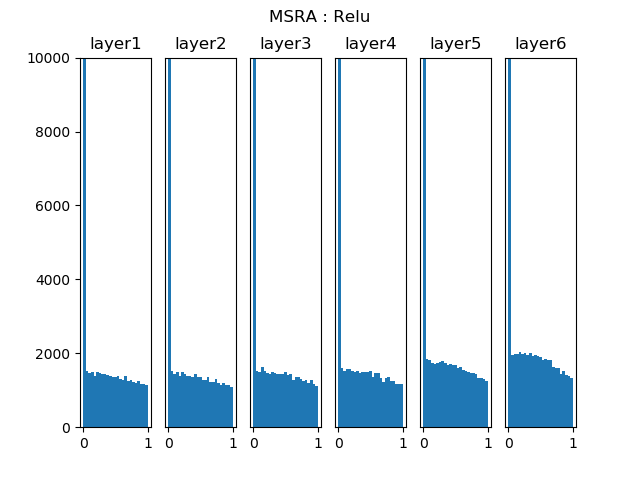
图15-4 MSRA初始化在ReLU激活函数上的表现
对于Leaky ReLU:
15.1.5 小结⚓︎
表15-2 几种初始化方法的应用场景
| ID | 网络深度 | 初始化方法 | 激活函数 | 说明 |
|---|---|---|---|---|
| 1 | 单层 | 零初始化 | 无 | 可以 |
| 2 | 双层 | 零初始化 | Sigmoid | 错误,不能进行正确的反向传播 |
| 3 | 双层 | 随机初始化 | Sigmoid | 可以 |
| 4 | 多层 | 随机初始化 | Sigmoid | 激活值分布成凹形,不利于反向传播 |
| 5 | 多层 | Xavier初始化 | Tanh | 正确 |
| 6 | 多层 | Xavier初始化 | ReLU | 激活值分布偏向0,不利于反向传播 |
| 7 | 多层 | MSRA初始化 | ReLU | 正确 |
从表15-2可以看到,由于网络深度和激活函数的变化,使得人们不断地研究新的初始化方法来适应,最终得到1、3、5、7这几种组合。
代码位置⚓︎
ch15, Level1
思考与练习⚓︎
- 多层时,不能用零初始化。但是如果权重矩阵的所有值都初始化为0.1,是否可以呢?
- 用14.6中的例子比较Xavier和MSRA初始化的训练效果。
参考资料⚓︎
[1] Understanding the difficulty of training deep feedforward neural networks. link: http://proceedings.mlr.press/v9/glorot10a/glorot10a.pdf
by Xavier Glorot, Yoshua Bengio in AISTATS 2010.
这是中译版,感谢译者。
[2] 何凯明,Microsoft Research Asia,2015。https://arxiv.org/pdf/1502.01852.pdf