15.2 梯度下降优化算法
15.2 梯度下降优化算法⚓︎
15.2.1 随机梯度下降 SGD⚓︎
先回忆一下随机梯度下降的基本算法,便于和后面的各种算法比较。图15-5中的梯度搜索轨迹为示意图。
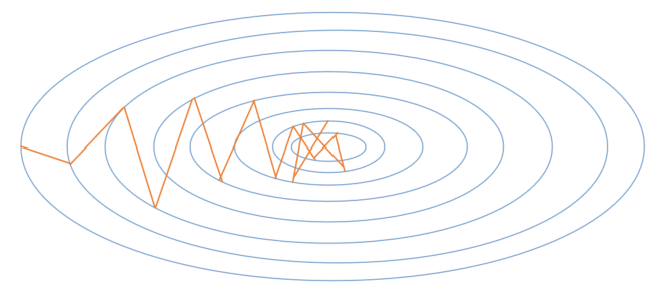
图15-5 随机梯度下降算法的梯度搜索轨迹示意图
输入和参数⚓︎
- \eta - 全局学习率
算法⚓︎
计算梯度:g_t = \nabla_\theta J(\theta_{t-1})
更新参数:\theta_t = \theta_{t-1} - \eta \cdot g_t
随机梯度下降算法,在当前点计算梯度,根据学习率前进到下一点。到中点附近时,由于样本误差或者学习率问题,会发生来回徘徊的现象,很可能会错过最优解。
实际效果⚓︎
表15-3 学习率对SGD的影响
| 学习率 | 损失函数与准确率 |
|---|---|
| 0.1 |  |
| 0.3 |  |
SGD的另外一个缺点就是收敛速度慢,见表15-3,在学习率为0.1时,训练10000个epoch不能收敛到预定损失值;学习率为0.3时,训练5000个epoch可以收敛到预定水平。
15.2.2 动量算法 Momentum⚓︎
SGD方法的一个缺点是其更新方向完全依赖于当前batch计算出的梯度,因而十分不稳定,因为数据有噪音。
Momentum算法借用了物理中的动量概念,它模拟的是物体运动时的惯性,即更新的时候在一定程度上保留之前更新的方向,同时利用当前batch的梯度微调最终的更新方向。这样一来,可以在一定程度上增加稳定性,从而学习地更快,并且还有一定摆脱局部最优的能力。Momentum算法会观察历史梯度,若当前梯度的方向与历史梯度一致(表明当前样本不太可能为异常点),则会增强这个方向的梯度。若当前梯度与历史梯度方向不一致,则梯度会衰减。
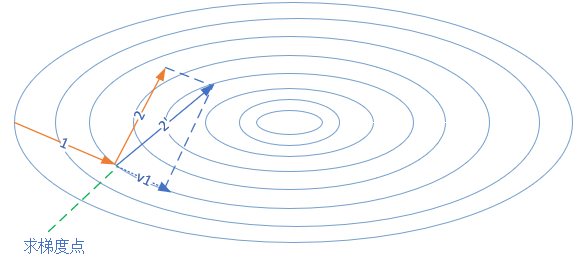
图15-6 动量算法的前进方向
图15-6中,第一次的梯度更新完毕后,会记录v_1的动量值。在“求梯度点”进行第二次梯度检查时,得到2号方向,与v_1的动量组合后,最终的更新为2'方向。这样一来,由于有v_1的存在,会迫使梯度更新方向具备“惯性”,从而可以减小随机样本造成的震荡。
输入和参数⚓︎
- \eta - 全局学习率
- \alpha - 动量参数,一般取值为0.5, 0.9, 0.99
- v_t - 当前时刻的动量,初值为0
算法⚓︎
计算梯度:g_t = \nabla_\theta J(\theta_{t-1})
计算速度更新:v_t = \alpha \cdot v_{t-1} + \eta \cdot g_t (公式1)
更新参数:\theta_t = \theta_{t-1} - v_t (公式2)
但是在花书上的公式是这样的:
v_t = \alpha \cdot v_{t-1} - \eta \cdot g_t (公式3)
\theta_{t} = \theta_{t-1} + v_t (公式4)
这两个差别好大啊!一个加减号错会导致算法不工作!为了搞清楚,咱们手推一下迭代过程。
根据算法公式(1)(2),以W参数为例,有:
- v_0 = 0
- dW_0 = \nabla J(w)
- v_1 = \alpha v_0 + \eta \cdot dW_0 = \eta \cdot dW_0
- W_1 = W_0 - v_1=W_0 - \eta \cdot dW_0
- dW_1 = \nabla J(w)
- v_2 = \alpha v_1 + \eta dW_1
- W_2 = W_1 - v_2 = W_1 - (\alpha v_1 +\eta dW_1) = W_1 - \alpha \cdot \eta \cdot dW_0 - \eta \cdot dW_1
- dW_2 = \nabla J(w)
- v_3=\alpha v_2 + \eta dW_2
- W_3 = W_2 - v_3=W_2-(\alpha v_2 + \eta dW_2) = W_2 - \alpha^2 \eta dW_0 - \alpha \eta dW_1 - \eta dW_2
根据公式(3)(4)有:
- v_0 = 0
- dW_0 = \nabla J(w)
- v_1 = \alpha v_0 - \eta \cdot dW_0 = -\eta \cdot dW_0
- W_1 = W_0 + v_1=W_0 - \eta \cdot dW_0
- dW_1 = \nabla J(w)
- v_2 = \alpha v_1 - \eta dW_1
- W_2 = W_1 + v_2 = W_1 + (\alpha v_1 - \eta dW_1) = W_1 - \alpha \cdot \eta \cdot dW_0 - \eta \cdot dW_1
- dW_2 = \nabla J(w)
- v_3=\alpha v_2 - \eta dW_2
- W_3 = W_2 + v_3=W_2 + (\alpha v_2 - \eta dW_2) = W_2 - \alpha^2 \eta dW_0 - \alpha \eta dW_1-\eta dW_2
通过手工推导迭代,我们得到两个结论:
- 可以看到两种方式的第9步结果是相同的,即公式(1)(2)等同于(3)(4)
- 与普通SGD的算法W_3 = W_2 - \eta dW_2相比,动量法不但每次要减去当前梯度,还要减去历史梯度W_0,W_1乘以一个不断减弱的因子\alpha,因为\alpha小于1,所以\alpha^2比\alpha小,\alpha^3比\alpha^2小。这种方式的学名叫做指数加权平均。
实际效果⚓︎
表15-4 SGD和动量法的比较
| 算法 | 损失函数和准确率 |
|---|---|
| SGD | |
| Momentum |  |
从表15-4的比较可以看到,使用同等的超参数设置,普通梯度下降算法经过epoch=10000次没有到达预定0.001的损失值;动量算法经过2000个epoch迭代结束。
在损失函数历史数据图中,中间有一大段比较平坦的区域,梯度值很小,或者是随机梯度下降算法找不到合适的方向前进,只能慢慢搜索。而下侧的动量法,利用惯性,判断当前梯度与上次梯度的关系,如果方向相同,则会加速前进;如果不同,则会减速,并趋向平衡。所以很快地就达到了停止条件。
当我们将一个小球从山上滚下来时,没有阻力的话,它的动量会越来越大,但是如果遇到了阻力,速度就会变小。加入的这一项,可以使得梯度方向不变的维度上速度变快,梯度方向有所改变的维度上的更新速度变慢,这样就可以加快收敛并减小震荡。
15.2.3 梯度加速算法 NAG⚓︎
Nesterov Accelerated Gradient,或者叫做Nesterov Momentum。
在小球向下滚动的过程中,我们希望小球能够提前知道在哪些地方坡面会上升,这样在遇到上升坡面之前,小球就开始减速。这方法就是Nesterov Momentum,其在凸优化中有较强的理论保证收敛。并且,在实践中Nesterov Momentum也比单纯的Momentum 的效果好。
输入和参数⚓︎
- \eta - 全局学习率
- \alpha - 动量参数,缺省取值0.9
- v - 动量,初始值为0
算法⚓︎
临时更新:\hat \theta = \theta_{t-1} - \alpha \cdot v_{t-1}
前向计算:f(\hat \theta)
计算梯度:g_t = \nabla_{\hat\theta} J(\hat \theta)
计算速度更新:v_t = \alpha \cdot v_{t-1} + \eta \cdot g_t
更新参数:\theta_t = \theta_{t-1} - v_t
其核心思想是:注意到 momentum 方法,如果只看 \alpha \cdot v_{t-1} 项,那么当前的θ经过momentum的作用会变成 \theta - \alpha \cdot v_{t-1}。既然我们已经知道了下一步的走向,我们不妨先走一步,到达新的位置”展望”未来,然后在新位置上求梯度, 而不是原始的位置。
所以,同Momentum相比,梯度不是根据当前位置θ计算出来的,而是在移动之后的位置\theta - \alpha \cdot v_{t-1}计算梯度。理由是,既然已经确定会移动\theta - \alpha \cdot v_{t-1},那不如之前去看移动后的梯度。
图15-7是NAG的前进方向。
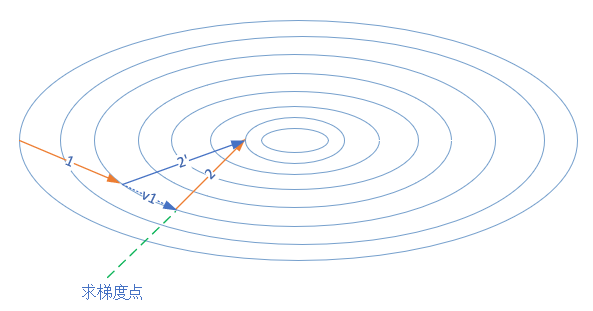
图15-7 梯度加速算法的前进方向
这个改进的目的就是为了提前看到前方的梯度。如果前方的梯度和当前梯度目标一致,那我直接大步迈过去; 如果前方梯度同当前梯度不一致,那我就小心点更新。
实际效果⚓︎
表15-5 动量法和NAG法的比较
| 算法 | 损失函数和准确率 |
|---|---|
| Momentum | |
| NAG |  |
表15-9显示,使用动量算法经过2000个epoch迭代结束,NAG算法是加速的动量法,因此只用1400个epoch迭代结束。
NAG 可以使 RNN 在很多任务上有更好的表现。
代码位置⚓︎
ch15, Level2