15.6 批量归一化的实现
15.6 批量归一化的实现⚓︎
在这一节中,我们将会动手实现一个批量归一化层,来验证批量归一化的实际作用。
15.6.1 反向传播⚓︎
在上一节中,我们知道了批量归一化的正向计算过程,这一节中,为了实现完整的批量归一化层,我们首先需要推导它的反向传播公式,然后用代码实现。本节中的公式序号接上一节,以便于说明。
首先假设已知从上一层回传给批量归一化层的误差矩阵是:
求批量归一化层参数梯度⚓︎
则根据公式9,求\gamma,\beta的梯度:
注意\gamma和\beta的形状与批大小无关,只与特征值数量有关,我们假设特征值数量为1,所以它们都是一个标量。在从计算图看,它们都与N,Z的全集相关,而不是某一个样本,因此会用求和方式计算。
求批量归一化层的前传误差矩阵⚓︎
下述所有乘法都是element-wise的矩阵点乘,不再特殊说明。
从正向公式中看,对z有贡献的数据链是:
- z_i \leftarrow n_i \leftarrow x_i
- z_i \leftarrow n_i \leftarrow \mu_B \leftarrow x_i
- z_i \leftarrow n_i \leftarrow \sigma^2_B \leftarrow x_i
- z_i \leftarrow n_i \leftarrow \sigma^2_B \leftarrow \mu_B \leftarrow x_i
从公式8,9:
公式13的右侧第一部分(与全连接层形式一样):
上式等价于:
公式14中,我们假设样本数为64,特征值数为10,则得到一个64\times 10的结果矩阵(因为1\times 10的矩阵会被广播为64\times 10的矩阵):
公式13的右侧第二部分,从公式8: $$ \frac{d n_i}{dx_i}=\frac{1}{\sqrt{\sigma^2_B + \epsilon}} \tag{15} $$
公式13的右侧第三部分,从公式8(注意\sigma^2_B是个标量,而且与X,N的全集相关,要用求和方式):
公式13的右侧第四部分,从公式7: $$ \frac{d \sigma^2_B}{dx_i} = \frac{2(x_i - \mu_B)}{m} \tag{17} $$
公式13的右侧第五部分,从公式7,8:
公式18的右侧第二部分,根据公式8:
公式18的右侧第四部分,根据公式7(\sigma^2_B和\mu_B与全体x_i相关,所以要用求和):
所以公式18是:
公式13的右侧第六部分,从公式6:
所以,公式13最后是这样的:
15.6.2 代码实现⚓︎
初始化类⚓︎
class BnLayer(CLayer):
def __init__(self, input_size, momentum=0.9):
self.gamma = np.ones((1, input_size))
self.beta = np.zeros((1, input_size))
self.eps = 1e-5
self.input_size = input_size
self.output_size = input_size
self.momentum = momentum
self.running_mean = np.zeros((1,input_size))
self.running_var = np.zeros((1,input_size))
momentum、running_mean、running_var,是为了计算/记录历史方差均差的。
前向计算⚓︎
def forward(self, input, train=True):
......
反向传播⚓︎
def backward(self, delta_in, flag):
......
d_norm_x需要多次使用,所以先计算出来备用,以增加代码性能。
公式16中有一个(\sigma^2_B + \epsilon)^{-3/2},在前向计算中,我们令:
self.var = np.mean(self.x_mu**2, axis=0, keepdims=True) + self.eps
self.std = np.sqrt(self.var)
放在分母中就是(-3/2)次方了。
另外代码中有很多np.sum(..., axis=0, keepdims=True),这个和全连接层中的多样本计算一个道理,都是按样本数求和,并保持维度,便于后面的矩阵运算。
更新参数⚓︎
def update(self, learning_rate=0.1):
self.gamma = self.gamma - self.d_gamma * learning_rate
self.beta = self.beta - self.d_beta * learning_rate
15.6.3 批量归一化层的实际应用⚓︎
首先回忆一下第14.6节中的MNIST的图片分类网络,当时的模型如图15-15所示。
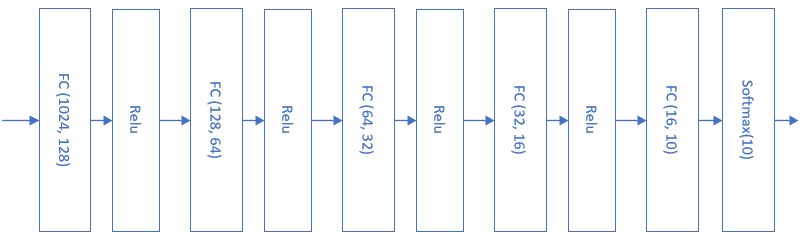
图15-15 第14.6节中MNIST图片分类网络
当时用了6个epoch(5763个Iteration),达到了0.12的预计loss值而停止训练。我们看看使用批量归一化后的样子,如图15-16所示。
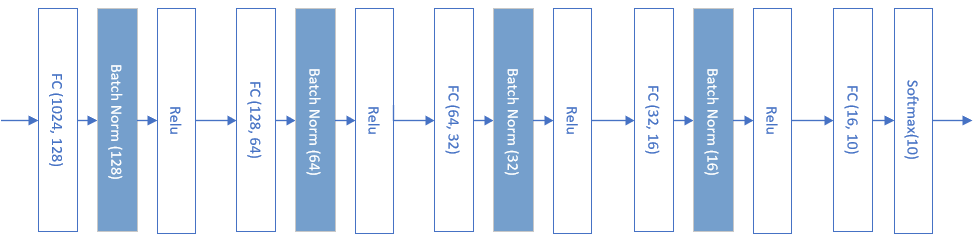
图15-16 使用批量归一化后的MNIST图片分类网络
在全连接层和激活函数之间,加入一个批量归一化层,最后的分类函数Softmax前面不能加批量归一化。
主程序代码⚓︎
if __name__ == '__main__':
......
params = HyperParameters_4_1(
learning_rate, max_epoch, batch_size,
net_type=NetType.MultipleClassifier,
init_method=InitialMethod.MSRA,
stopper=Stopper(StopCondition.StopLoss, 0.12))
net = NeuralNet_4_1(params, "MNIST")
fc1 = FcLayer_1_1(num_input, num_hidden1, params)
net.add_layer(fc1, "fc1")
bn1 = BnLayer(num_hidden1)
net.add_layer(bn1, "bn1")
r1 = ActivationLayer(Relu())
net.add_layer(r1, "r1")
......
前后都省略了一些代码,注意上面代码片段中的bn1,就是应用了批量归一化层。
运行结果⚓︎
为了比较,我们使用与14.6中完全一致的参数设置来训练这个有批量归一化的模型,得到如图15-17所示的结果。
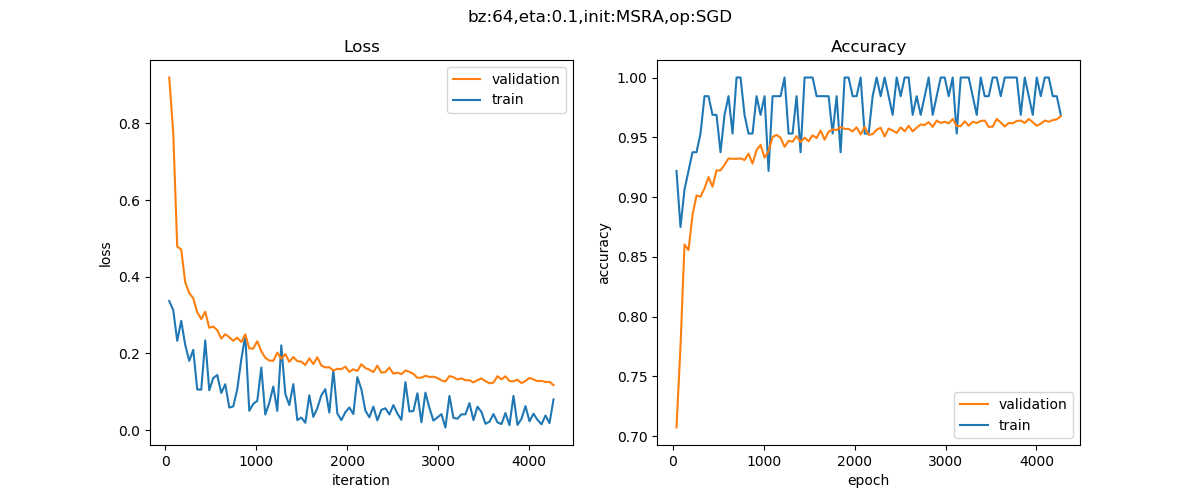
图15-17 使用批量归一化后的MNIST图片分类网络训练结果
打印输出的最后几行如下:
......
epoch=4, total_iteration=4267
loss_train=0.079916, accuracy_train=0.968750
loss_valid=0.117291, accuracy_valid=0.967667
time used: 19.44783306121826
save parameters
testing...
0.9663
列表15-12比较一下使用批量归一化前后的区别。
表15-12 批量归一化的作用
| 不使用批量归一化 | 使用批量归一化 | |
|---|---|---|
| 停止条件 | loss < 0.12 | loss < 0.12 |
| 训练次数 | 6个epoch(5763次迭代) | 4个epoch(4267次迭代) |
| 花费时间 | 17秒 | 19秒 |
| 准确率 | 96.97% | 96.63% |
使用批量归一化后,迭代速度提升,但是花费时间多了2秒,这是因为批量归一化的正向和反向计算过程还是比较复杂的,需要花费一些时间,但是批量归一化确实可以帮助网络快速收敛。如果使用GPU的话,花费时间上的差异应该可以忽略。
在准确率上的差异可以忽略,由于样本误差问题和随机初始化参数的差异,会造成最后的训练结果有细微差别。
代码位置⚓︎
ch15, Level6