16.2 L2正则
16.2 L2正则⚓︎
16.2.1 朴素的想法⚓︎
从过拟合的现象分析,是因为神经网络的权重矩阵参数过度地学习,即针对训练集,其损失函数值已经逼近了最小值。我们用熟悉的等高线图来解释,如图16-11所示。
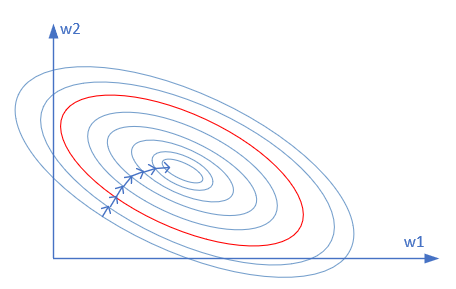
图16-11 损失函数值的等高线图
假设只有两个参数需要学习,那么这两个参数的损失函数就构成了上面的等高线图。由于样本数据量比较小(这是造成过拟合的原因之一),所以神经网络在训练过程中沿着箭头方向不断向最优解靠近,最终达到了过拟合的状态。也就是说在这个等高线图中的最优解,实际是针对有限的样本数据的最优解,而不是针对这个特点问题的最优解。
由此会产生一个朴素的想法:如果我们以某个处于中间位置等高线上(比如那条红色的等高线)为目标的话,是不是就可以得到比较好的效果呢?如何科学地找到这条等高线呢?
16.2.2 基本数学知识⚓︎
范数⚓︎
回忆一下范数的基本概念:
范数包含向量范数和矩阵范数,我们只关心向量范数。我们用具体的数值来理解范数。假设有一个向量a:
注意p可以是小数,比如0.5:
一个经典的关于P范数的变化如图16-12所示。
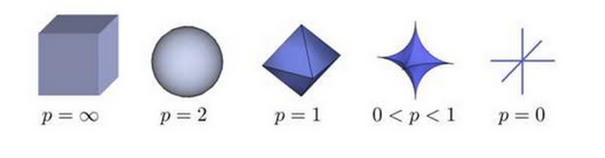
图16-12 P范数变化图
我们只关心L1和L2范数:
- L1范数是个菱形体,在平面上是一个菱形
- L2范数是个球体,在平面上是一个圆
高斯分布⚓︎
请参考15.2一节。
16.2.3 L2正则化⚓︎
假设:
- W参数服从高斯分布,即:w_j \sim N(0,\tau^2)
- Y服从高斯分布,即:y_i \sim N(w^Tx_i,\sigma^2)
贝叶斯最大后验估计:
因为\sigma,b,n,\pi,m等都是常数,所以损失函数J(w)的最小值可以简化为:
看公式4,相当于是线性回归的均方差损失函数,再加上一个正则项(也称为惩罚项),共同构成损失函数。如果想求这个函数的最小值,则需要两者协调,并不是说分别求其最小值就能实现整体最小,因为它们具有共同的W项,当W比较大时,第一项比较小,第二项比较大,或者正好相反。所以它们是矛盾组合体。
为了简化问题便于理解,我们用两个参数w_1,w_2举例。对于公式4的第一项,我们用前面学习过损失函数的等高线图来解释。对于第二项,形式应该是一个圆形,因为圆的方程是r^2=x^2+y^2。所以,结合两者,我们可以得到图16-13。
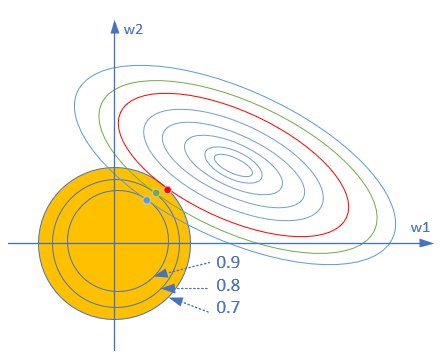
图16-13 L2正则区与损失函数等高线示意图
黄色的圆形,就是正则项所处的区域。这个区域的大小,是由参数\lambda所控制的,该值越大,黄色圆形区域越小,对w的惩罚力度越大(距离椭圆中心越远)。比如图16-13中分别标出了该值为0.7、0.8、0.9的情况。
还以图16-13为例,当\lambda为0.7时,L2正则区为图中所示最大的黄色区域,此区域与损失函数等高线图的交点有多个,比如图中的红、绿、蓝三个点,但由于红点距离椭圆中心最近,所以最后求得的权重值应该在红点的位置坐标上(w_1,w_2)。
在回归里面,把具有L2项的回归叫“岭回归”(Ridge Regression),也叫它“权值衰减”(weight decay)。 weight decay还有一个好处,它使得目标函数变为凸函数,梯度下降法和L-BFGS都能收敛到全局最优解。
L2范数是指向量各元素的平方和然后求平方根。我们让L2范数的规则项最小,可以使得W的每个元素都很小,都接近于0,因为一般认为参数值小的模型比较简单,能适应不同的数据集,也在一定程度上避免了过拟合现象。可以设想一下对于一个线性回归方程,若参数很大,那么只要数据偏移一点点,就会对结果造成很大的影响;但如果参数足够小,数据偏移得多一点也不会对结果造成什么影响,专业一点的说法是“抗扰动能力强”。
关于bias偏置项的正则⚓︎
上面的L2正则化没有约束偏置(biases)项。当然,通过修改正则化过程来正则化偏置会很容易,但根据经验,这样做往往不能较明显地改变结果,所以是否正则化偏置项仅仅是一个习惯问题。
值得注意的是,有一个较大的bias并不会使得神经元对它的输入像有大权重那样敏感,所以不用担心较大的偏置会使我们的网络学习到训练数据中的噪声。同时,允许大的偏置使我们的网络在性能上更为灵活,特别是较大的偏置使得神经元更容易饱和,这通常是我们期望的。由于这些原因,通常不对偏置做正则化。
16.2.4 损失函数的变化⚓︎
假设是均方差损失函数:
如果是交叉熵损失函数:
在NeuralNet.py中的代码片段如下,计算公式5或公式6的第二项:
for i in range(self.layer_count-1,-1,-1):
layer = self.layer_list[i]
if isinstance(layer, FcLayer):
if regularName == RegularMethod.L2:
regular_cost += np.sum(np.square(layer.weights.W))
return regular_cost * self.params.lambd
在计算Loss值时,用上面函数的返回值再除以样本数m,即下面代码中的train_y.shape[0],附加到原始的loss值之后即可。下述代码就是对公式5或6的实现。
loss_train = self.lossFunc.CheckLoss(train_y, self.output)
loss_train += regular_cost / train_y.shape[0]
16.2.5 反向传播的变化⚓︎
由于正则项是在损失函数中,在正向计算中,并不涉及到它,所以正向计算公式不用变。但是在反向传播过程中,需要重新推导一下公式。
假设有一个两层的回归神经网络,其前向计算如下:
公式8是W1,W2的总和,公式9对dJ/dW2求导时,由于是W1^2+W2^2的关系,所以W1对W2求导的结果是0,所以公式9最后只剩下W2了。
B不受正则项的影响:
再继续反向传播到第一层网络:
从上面的公式中可以看到,正则项在方向传播过程中,唯一影响的就是求W的梯度时,要增加一个\lambda \odot W,所以,我们可以修改FullConnectionLayer.py中的反向传播函数如下:
def backward(self, delta_in, idx):
dZ = delta_in
m = self.x.shape[1]
if self.regular == RegularMethod.L2:
self.weights.dW = (np.dot(dZ, self.x.T) + self.lambd * self.weights.W) / m
else:
self.weights.dW = np.dot(dZ, self.x.T) / m
# end if
self.weights.dB = np.sum(dZ, axis=1, keepdims=True) / m
delta_out = np.dot(self.weights.W.T, dZ)
if len(self.input_shape) > 2:
return delta_out.reshape(self.input_shape)
else:
return delta_out
regular == RegularMethod.L2时,走一个特殊分支,完成正则项的惩罚机制。
16.2.6 运行结果⚓︎
下面是主程序的运行代码:
from Level0_OverFitNet import *
if __name__ == '__main__':
dr = LoadData()
hp, num_hidden = SetParameters()
hp.regular_name = RegularMethod.L2
hp.regular_value = 0.01
net = Model(dr, 1, num_hidden, 1, hp)
ShowResult(net, dr, hp.toString())
运行后,将训练过程中的损失和准确率可视化出来,并将拟合后的曲线与训练数据做比较,如图16-14和16-15所示。
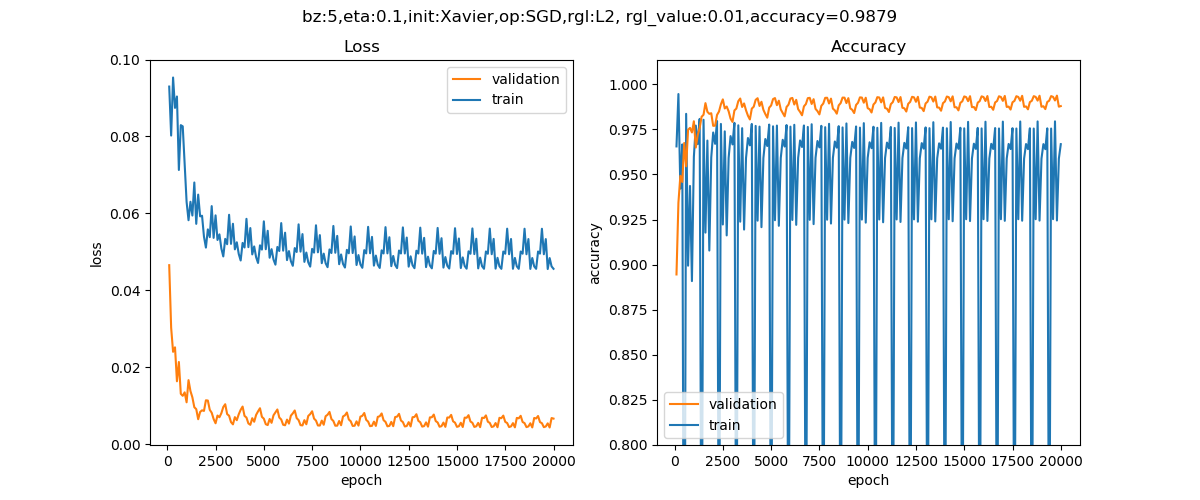
图16-14 训练过程中损失函数值和准确率的变化曲线
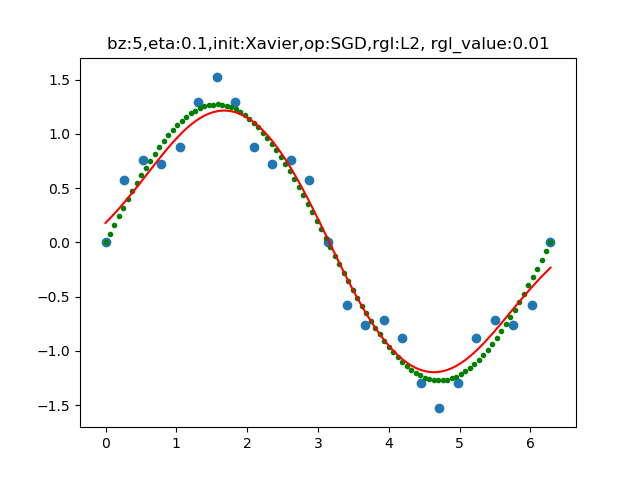
图16-15 拟合后的曲线与训练数据的分布图
代码位置⚓︎
ch16, Level2
思考和练习⚓︎
- 观察代码的打印输出的最后一部分,关于Norm1和Norm2的结果,仔细体会L2的作用。
- 尝试改变代码中\lambda的数值,看看最后的拟合结果及准确率有何变化。
参考资料⚓︎
http://charleshm.github.io/2016/03/Regularized-Regression/
https://blog.csdn.net/red_stone1/article/details/80755144
https://www.jianshu.com/p/c9bb6f89cfcc