16.4 早停法
16.4 早停法 Early Stopping⚓︎
16.4.1 想法的由来⚓︎
从图16-20来看,如果我们在第2500次迭代时就停止训练,就应该是验证集的红色曲线的最佳取值位置了,因为此时损失值最小,而准确率值最大。
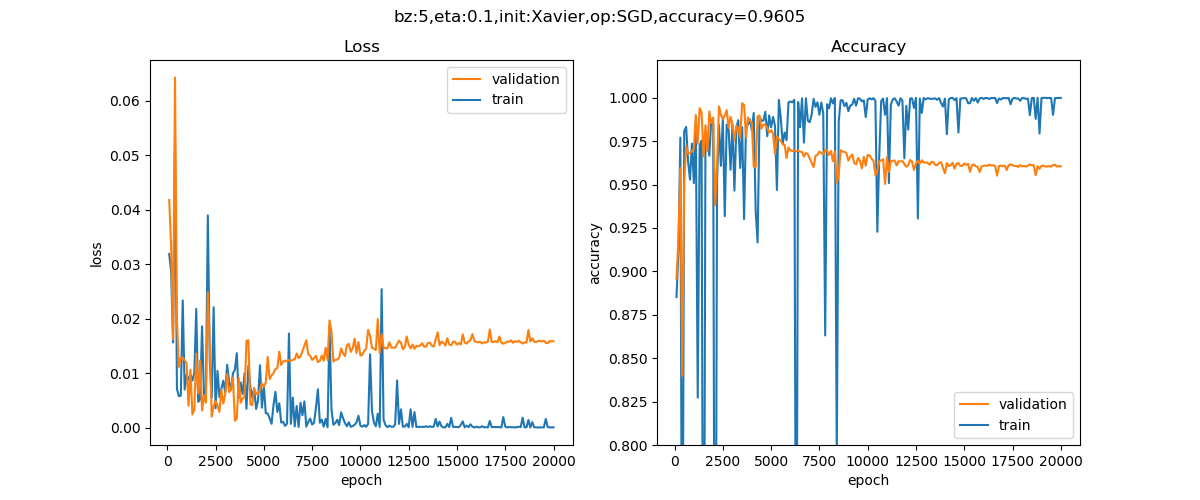
图16-20 训练过程中损失函数值和准确率的变化曲线
这种做法很符合直观感受,因为准确率都不再提高了,损失值反而上升了,再继续训练也是无益的,只会浪费训练的时间。那么该做法的一个重点便是怎样才认为验证集不再提高了呢?并不是说准确率一降下来便认为不再提高了,因为可能在这个Epoch上,准确率降低了,但是随后的Epoch准确率又升高了,所以不能根据一两次的连续降低就判断不再提高。
对模型进行训练的过程即是对模型的参数进行学习更新的过程,这个参数学习的过程往往会用到一些迭代方法,如梯度下降(Gradient descent)学习算法。Early stopping便是一种迭代次数截断的方法来防止过拟合的方法,即在模型对训练数据集迭代收敛之前停止迭代来防止过拟合。
16.4.2 理论基础⚓︎
早停法,实际上也是一种正则化的策略,可以理解为在网络训练不断逼近最优解的过程种(实际上这个最优解是过拟合的),在梯度等高线的外围就停止了训练,所以其原理上和L2正则是一样的,区别在于得到解的过程。
我们把图16-21再拿出来讨论一下。
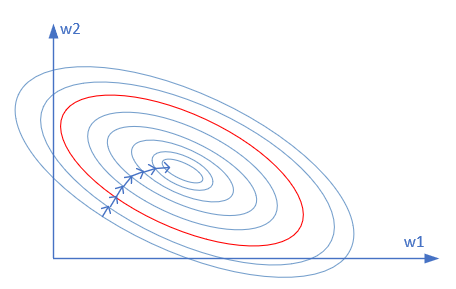
图16-21 损失函数值的等高线图
图中所示的等高线图,是当前带噪音的样本点所组成梯度图,并不代表测试集数据,所以其中心位置也不代表这个问题的最优解。我们假设红线是最优解,则早停法的目的就是在到达红线附近时停止训练。
16.4.3 算法⚓︎
一般的做法是,在训练的过程中,记录到目前为止最好的validation 准确率,当连续N次Epoch(比如N=10或者更多次)没达到最佳准确率时,则可以认为准确率不再提高了。此时便可以停止迭代了(Early Stopping)。这种策略也称为“No-improvement-in-N”,N即Epoch的次数,可以根据实际情况取,如10、20、30……
算法描述如下:
初始化
初始权重均值参数:theta = theta_0
迭代次数:i = 0
忍耐次数:patience = N (e.g. N=10)
忍耐次数计数器:counter = 0
验证集损失函数值:lastLoss = 10000 (给一个特别大的数值)
while (epoch < maxEpoch) 循环迭代训练过程
正向计算,反向传播更新theta
迭代次数加1:i++
计算验证集损失函数值:newLoss = loss
if (newLoss < lastLoss) // 新的损失值更小
忍耐次数计数器归零:counter = 0
记录当前最佳权重矩阵训练参数:theta_best = theta
记录当前迭代次数:i_best = i
更新最新验证集损失函数值:lastLoss = newLoss
else // 新的损失值大于上一步的损失值
忍耐次数计数器加1:counter++
if (counter >= patience) 停止训练!!!
end if
end while
此时,theta_best和i_best就是最佳权重值和迭代次数。
要注意的问题⚓︎
- 门限值
patience不能太小,比如小于5,因为很可能在5个epoch之外,损失函数值又会再次下降 patience不能太大,比如大于30,因为在这30个epoch之内,由于样本数量少和数据shuffle的关系,很可能某个epoch的损失函数值会比上一次低,这样忍耐次数计数器counter就清零了,从而不能及时停止。- 当样本数量少时,为了获得平滑的变化曲线,可以考虑使用加权平均的方式处理当前和历史损失函数值,以避免某一次的高低带来的影响。
16.4.4 实现⚓︎
首先,在TrainingTrace类中,增加以下成员以支持早停机制:
early_stop:True表示激活早停机制判断patience:忍耐次数上限,缺省值为5次patience_counter:忍耐次数计数器last_vld_loss:到目前为止最小的验证集损失值
class TrainingTrace(object):
def __init__(self, need_earlyStop = False, patience = 5):
......
# for early stop
self.early_stop = need_earlyStop
self.patience = patience
self.patience_counter = 0
self.last_vld_loss = float("inf")
def Add(self, epoch, total_iteration, loss_train, accuracy_train, loss_vld, accuracy_vld):
......
if self.early_stop:
if loss_vld < self.last_vld_loss:
self.patience_counter = 0
self.last_vld_loss = loss_vld
else:
self.patience_counter += 1
if self.patience_counter >= self.patience:
return True # need to stop
# end if
return False
- 判断loss_vld是否小于last_vld_loss,如果是,清零计数器,保存最新loss值
- 如果否,计数器加1,判断是否达到门限值,是的话返回True,否则返回False
在main过程中,设置超参时指定正则项为RegularMethod.EarlyStop,并且value=8 (即门限值为8)。
from Level0_OverFitNet import *
if __name__ == '__main__':
dr = LoadData()
hp, num_hidden = SetParameters()
hp.regular_name = RegularMethod.EarlyStop
hp.regular_value = 8
net = Model(dr, 1, num_hidden, 1, hp)
ShowResult(net, dr, hp.toString())
注意,我们仍然使用和过拟合试验中一样的神经网络,宽度深度不变,只是增加了早停逻辑。
运行程序后,训练只迭代了2500多次就停止了,和我们预想的一样,损失值和准确率的曲线如图16-22所示。
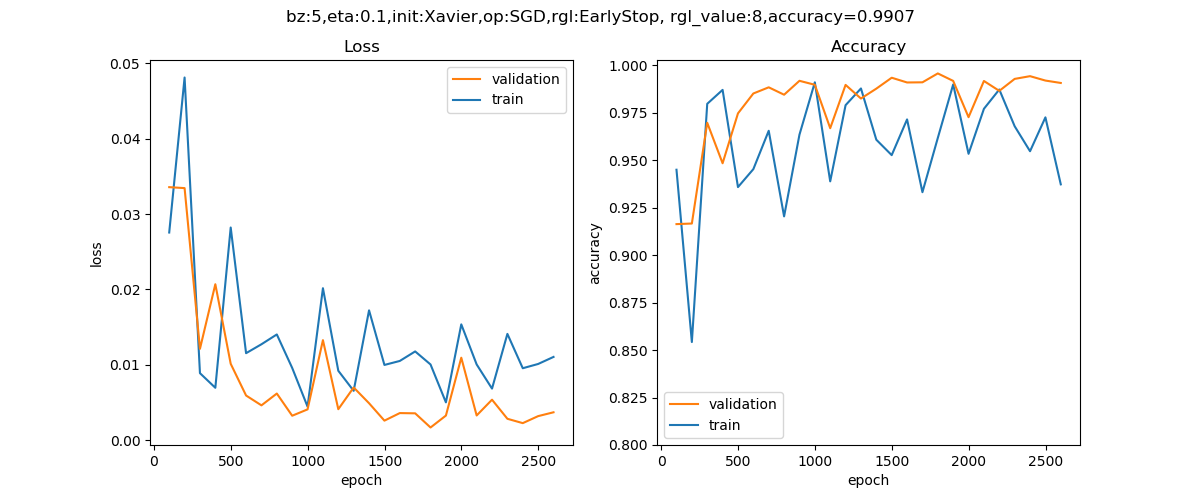
图16-22 训练过程中损失函数值和准确率的变化曲线
早停法并不会提高准确率,而只是在最高的准确率上停止训练(前提是知道后面的训练会造成过拟合),从上图可以看到,最高的准确率是99.07%,达到了我们的目的。
最后的拟合效果如图16-23所示。
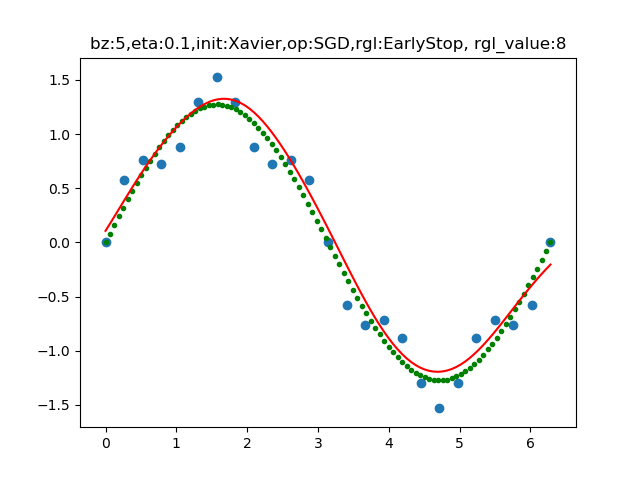
图16-23 拟合后的曲线与训练数据的分布图
蓝点是样本,绿点是理想的拟合效果,红线是实际的拟合效果。
16.4.5 后续的步骤⚓︎
在得到早停的迭代次数和权重矩阵参数后,后续有几种方法可以选择。
彻底停止⚓︎
就是啥也不做了,最多再重复几次早停的试验,看看是不是稳定,然后就使用\theta_{best}做为训练结果。
再次训练⚓︎
由于第一次早停是通过验证集计算loss值来实现的,所以这次不再分训练集和验证集,记住了早停时的迭代次数,可以重新初始化权重矩阵参数,使用所有数据再次训练,然后到达第一次的i_{best}时停止。
但是由于样本多了,更新批次也会变多,所以可以比较两种策略:
1) 总迭代次数epoch保持不变
2) 总更新梯度的次数保持不变
优点:使用更多的样本可以达到更好的泛化能力。
缺点:需要重新花时间训练。
继续训练⚓︎
得到\theta_{best}后,用全部训练数据(不再分训练集和验证集),在此基础上继续训练若干轮,并且继续用以前的验证集来监控损失函数值,如果能得到比以前更低的损失值,将会是比较理想的情况。
优点:可以避免重新训练的成本。
缺点:有可能不能达到目的,损失值降不到理想位置,从而不能终止训练。
代码位置⚓︎
ch16, Level4
思考与练习⚓︎
- 本示例代码中给出的
patience值为8,即有连续8次的loss值上升,就停止训练。试着修改这个值从5到20,看看对训练结果有什么影响。
参考资料⚓︎
- 《深度学习》- 伊恩·古德费洛