19.3 通用的循环神经网络模型
19.3 通用的循环神经网络模型⚓︎
19.3.1 提出问题⚓︎
在19.1节和19.2节的情况不同,都是预知时间步长度,然后以纯手工方式搭建循环神经网络。表19-5展示了前两节和后面的章节要实现的循环神经网络参数。
表19-5 不同场景下的循环神经网络参数
| 回波检测问题 | 二进制减法问题 | PM2.5预测问题 | |
|---|---|---|---|
| 时间步 | 2 | 4 | 用户指定参数 |
| 网络输出类别 | 回归 | 二分类 | 多分类 |
| 分类函数 | 无 | Logistic函数 | Softmax函数 |
| 损失函数 | 均方差 | 二分类交叉熵 | 多分类交叉熵 |
| 时间步输出 | 最后一个 | 每一个 | 最后一个 |
| 批大小 | 1 | 1 | 用户指定参数 |
| 有无偏移值 | 有 | 无 | 有 |
如果后面再遇到多分类情况,或者其它参数有变化的话,我们不能像19.1节和19.2节那样纯手写代码,而是要抽象出来,写一个比较通用的框架。
“比较通用”是什么意思呢?那就是应该满足以下条件:
- 既可以支持分类网络(二分类和多分类),也可以支持回归网络;
- 每一个时间步可以有输出并且有监督学习信号,也可以只在最后一个时间步有输出;
- 第一个时间步的前向计算中不包含前一个时间步的隐层状态值(因为前面没有时间步);
- 最后一个时间步的反向传播中不包含下一个时间步的回传误差(因为后面没有时间步);
- 可以指定超参数进行网络训练,如:学习率、批大小、最大训练次数、输入层尺寸、隐层神经元数量、输出层尺寸等等;
- 可以保存训练结果并可以在以后加载参数,避免重新训练。
19.3.2 全输出网络通过时间反向传播⚓︎
前两节的内容详细地描述了循环神经网络中的反向传播的方法,尽管如表19-5所示,二者有些许不同,但是还是可以从中总结出关于梯度计算和存储的一般性的规律,即通过时间的反向传播(BPTT,Back Propagation Through Time)。
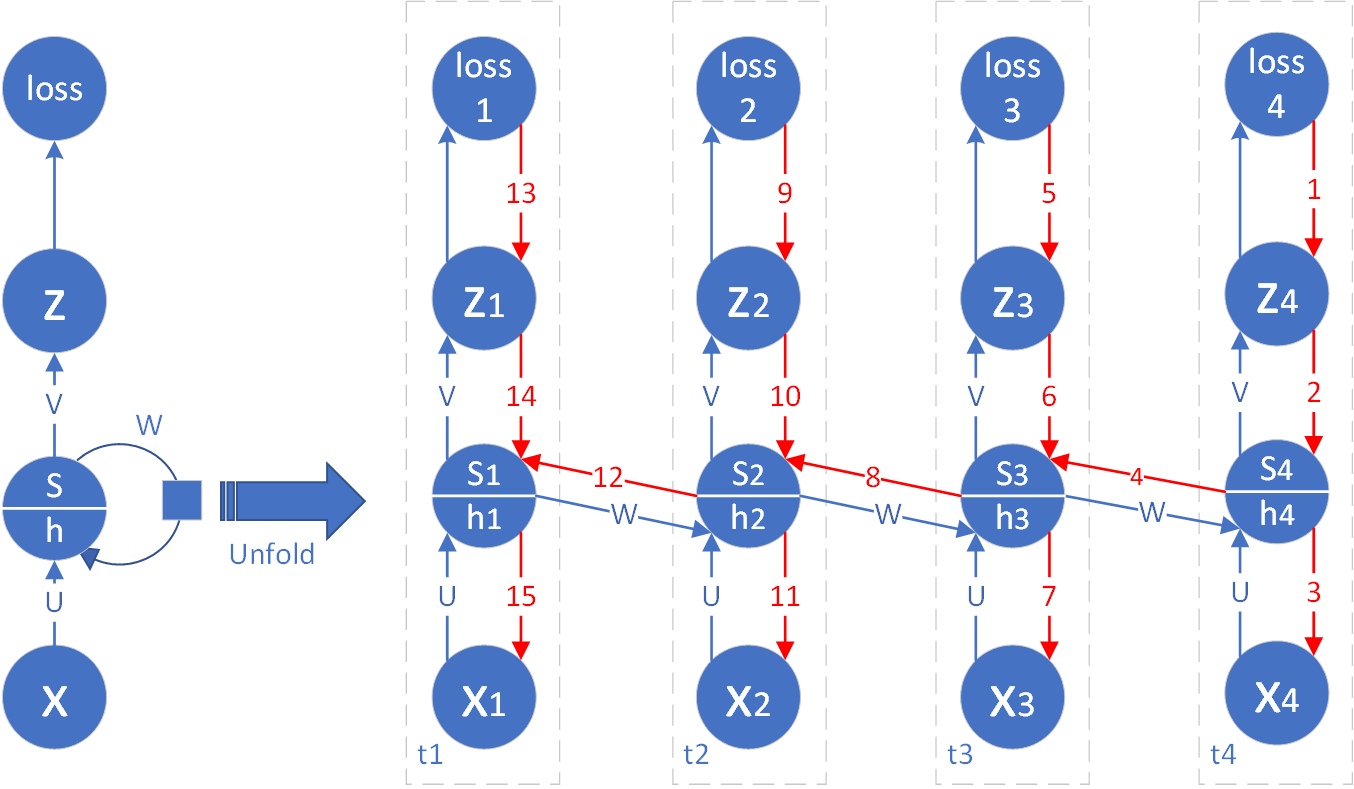
图19-14 全输出网路通过时间的反向传播
如图19-14所示,我们仍以具有4个时间步的循环神经网络为例,推导通用的反向传播算法,然后再扩展到一般性。每一个时间步都有输出,所以称为全输出网路,主要是为了区别与后面的单输出形式。
图中蓝色箭头线表示前向计算的过程,线上的字符表示连接参数,用于矩阵相乘。红色的箭头线表示反向传播的过程,线上的数字表示计算梯度的顺序。
正向计算过程为:
只有在时间步t1时,公式1中的s_{t-1}为0。
后续过程为:
公式2中的\sigma是激活函数,一般为Tanh函数,但也不排除使用其它函数。公式4中的分类函数 C 和公式5中的损失函数 L 因不同的网络类型而不同,如表19-5所示。
公式6中的\tau表示最大时间步数,或最后一个时间步数。
对于图19-14的最后一个时间步来说,节点s和h的误差只与loss_{\tau}有关:
对于其它时间步来说,节点s的反向误差从红色箭头的2和横向的dh两个方向传回来,比如时间步t3:
扩展到一般性:
从公式12可以看到,求任意时间步t的dh_t是关键的环节,有了它之后,后面的问题都和全连接网络一样了,在19.1和19.2节中也有讲述具体的方法,在此不再赘述。求dh_t时,是要依赖dh_{t+1}的结果的,所以,在通过时间的反向传播时,要先计算最后一个时间步的dh_{\tau},然后按照时间倒流的顺序一步步向前推导。
19.3.3 单输出网络通过时间的反向传播⚓︎
图19-14描述了一种通用的网络形式,即在每一个时间步都有监督学习信号,即计算损失函数值。另外一种常见的特例是,只有最后一个时间步有输出,需要计算损失函数值,并且有反向传播的梯度产生,而前面所有的其它时间步都没有输出,这种情况如图19-15所示。
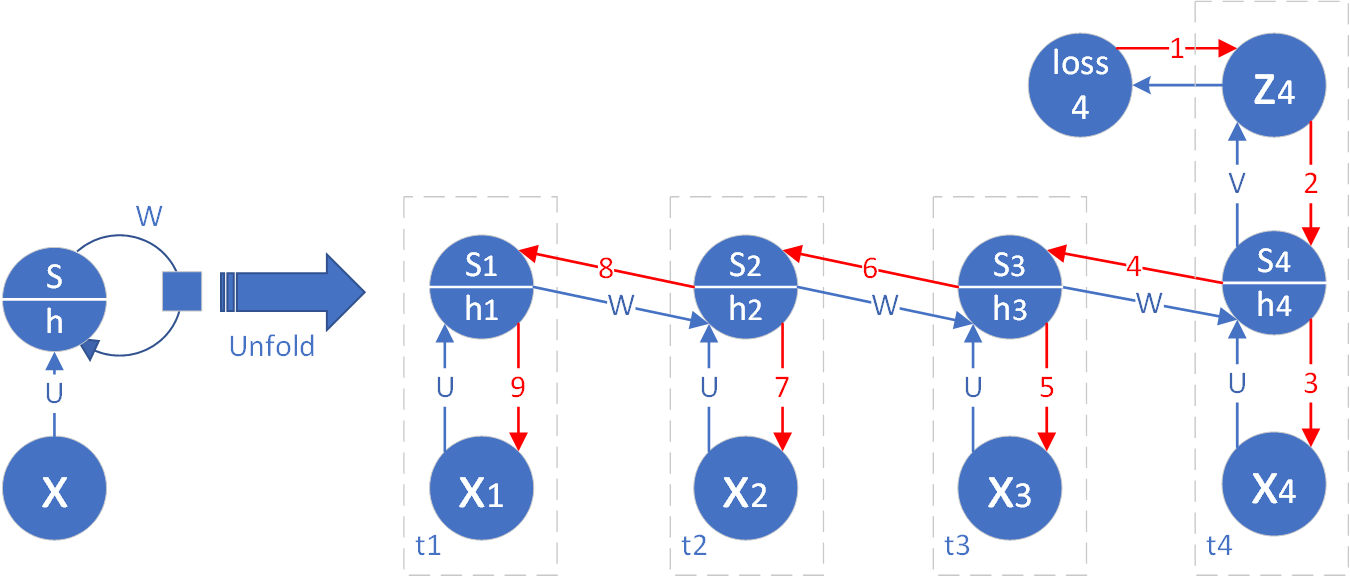
图19-15 单输出网络通过时间的反向传播
这种情况的反向传播比较简单,首先,最后一个时间步的梯度公式9依然不变。但是对于公式10,由于loss_3为0,所以公式简化为:
扩展到一般性:
如果有4个时间步,则第一个时间步的h节点的梯度为:
扩展到一般性:
公式17为最后一个时间步的梯度(公式9)的一般形式。
19.3.4 时间步类的设计⚓︎
时间步类(timestep)的设计是核心,它体现了循环神经网络的核心概念。下面的代码是该类的初始化函数:
初始化⚓︎
class timestep(object):
def __init__(self, net_type, output_type, isFirst=False, isLast=False):
self.isFirst = isFirst
self.isLast = isLast
self.netType = net_type
if (output_type == OutputType.EachStep):
self.needOutput = True
elif (output_type == OutputType.LastStep and isLast):
self.needOutput = True
else:
self.needOutput = False
- isFirst和isLast参数指定了该实例是否为第一个时间步或最后一个时间步
- netType参数指定了网络类型,回归、二分类、多分类,三种选择
- output_type结合isLast,可以指定该时间步是否有输出,如果是最后一个时间步,肯定有输出;如果不是最后一个时间步,并且如果output_type是OutputType.EachStep,则每个时间步都有输出,否则就没有输出。最后的判断结果记录在self.needOutput上
前向计算⚓︎
def forward(self, x, U, bu, V, bv, W, prev_s):
...
if (self.isFirst):
self.h = np.dot(x, U) + bu
else:
self.h = np.dot(x, U) + np.dot(prev_s, W) + bu
#endif
self.s = Tanh().forward(self.h)
if (self.needOutput):
self.z = np.dot(self.s, V) + bv
if (self.netType == NetType.BinaryClassifier):
self.a = Logistic().forward(self.z)
elif (self.netType == NetType.MultipleClassifier):
self.a = Softmax().forward(self.z)
else:
self.a = self.z
#endif
#endif
- 如果是第一个时间步,在计算隐层节点值时,则只需要计算np.dot(x, U),prev_s参数为None,不需要计算在内;
- 如果不是第一个时间步,则prev_s参数是存在的,需要增加np.dot(prev_s, W)项;
- 如果该时间步有输出要求,即self.needOutput为True,则计算输出项;
- 如果是二分类,最后的输出用Logistic函数;如果是多分类,用Softmax函数;如果是回归,直接令self.a = self.z,这里的赋值是为了编程模型一致,对外只暴露self.a为结果值。
反向传播⚓︎
def backward(self, y, prev_s, next_dh):
if (self.isLast):
assert(self.needOutput == True)
self.dz = self.a - y
self.dh = np.dot(self.dz, self.V.T) * Tanh().backward(self.s)
self.dV = np.dot(self.s.T, self.dz)
else:
assert(next_dh is not None)
if (self.needOutput):
self.dz = self.a - y
self.dh = (np.dot(self.dz, self.V.T) + np.dot(next_dh, self.W.T)) * Tanh().backward(self.s)
self.dV = np.dot(self.s.T, self.dz)
else:
self.dz = np.zeros_like(y)
self.dh = np.dot(next_dh, self.W.T) * Tanh().backward(self.s)
self.dV = np.zeros_like(self.V)
#endif
#endif
self.dbv = np.sum(self.dz, axis=0, keepdims=True)
self.dbu = np.sum(self.dh, axis=0, keepdims=True)
self.dU = np.dot(self.x.T, self.dh)
if (self.isFirst):
self.dW = np.zeros_like(self.W)
else:
self.dW = np.dot(prev_s.T, self.dh)
# end if
19.3.5 网络模型类的设计⚓︎
这部分代码量较大,由于篇幅原因,我们就不把代码全部列在这里了,而只是列出一些类方法。
初始化⚓︎
- 接收传入的超参数,超参数由使用者指定;
- 创建一个子目录来保存参数初始化结果和训练结果;
- 初始化损失函数类和训练记录类;
- 初始化时间步实例。
前向计算⚓︎
循环调用所有时间步实例的前向计算方法,遵循从前向后的顺序。要注意的是prev_s变量在第一个时间步是None。
反向传播⚓︎
循环调用所有时间步实例的反向传播方法,遵循从后向前的顺序。要注意的是prev_s变量在第一个时间步是None,next_dh在最后一个时间步是None。
参数更新⚓︎
在进行完反向传播后,每个时间步都会针对各个参数有自己的误差矩阵,由于循环神经网络的参数共享特性,需要统一进行更新,即把每个时间步的误差相加,然后乘以学习率,再除以批大小。
以W为例,其更新过程如下:
dw = np.zeros_like(self.W)
for i in range(self.ts):
dw += self.ts_list[i].dW
#end for
self.W = self.W - dw * self.hp.eta / batch_size
一定不要忘记除以批大小,笔者在开始阶段忘记了这一项,结果不得不把全局学习率设置得非常小,才可以正常训练。在加上这一项后,全局学习率设置为0.1就可以正常训练了。
保存和加载网络参数⚓︎
- 保存/加载初始化网络参数,为了比较不同超参对网络的影响
- 保存/加载训练过程中最低损失函数时的网络参数
- 保存/加载训练结束时的网络参数
网络训练⚓︎
代码片段如下:
for epoch in range(self.hp.max_epoch):
dataReader.Shuffle()
for iteration in range(max_iteration):
# get data
batch_x, batch_y = GetBatchTrainSamples()
# forward
self.forward(batch_x)
# backward
self.backward(batch_y)
# update
self.update(batch_x.shape[0])
# check loss and accuracy
if (checkpoint):
loss,acc = self.check_loss(X,Y)
代码位置⚓︎
ch19, Level3_Base