19.6 深度循环神经网络
19.6 深度循环神经网络⚓︎
19.6.1 深度循环神经网络的结构图⚓︎
前面的几个例子中,单独看每一时刻的网络结构,其实都是由“输入层->隐层->输出层”所组成的,这与我们在前馈神经网络中学到的单隐层的知识一样,由于输入层不算做网络的一层,输出层是必须具备的,所以网络只有一个隐层。我们知道单隐层的能力是有限的,所以人们会使用更深(更多隐层)的网络来解决复杂的问题。
在循环神经网络中,会有同样的需求,要求每一时刻的网络是由多个隐层组成。比如图19-20为两个隐层的循环神经网络,用于解决和19.4节中的同样的问题。
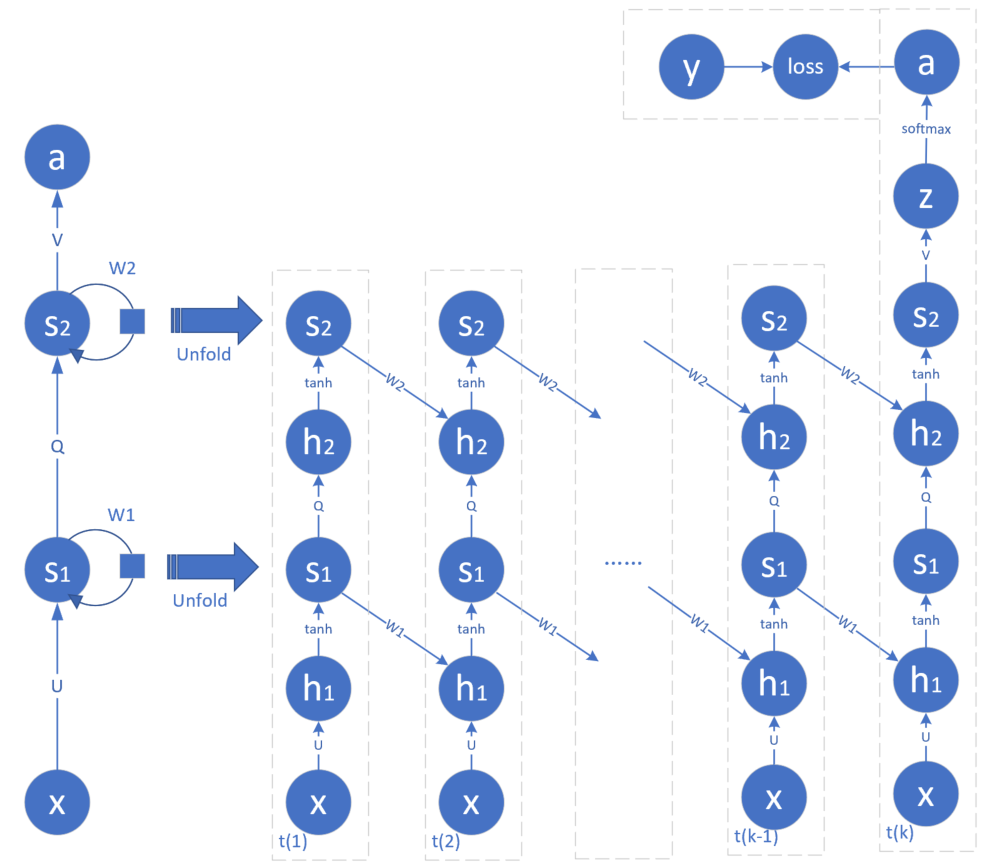
图19-20 两个隐层的循环神经网络
注意图19-20中最左侧的两个隐藏状态s1和s2是同时展开为右侧的图的, 这样的循环神经网络称为深度循环神经网络,它可以具备比单隐层的循环神经网络更强大的能力。
19.6.2 前向计算⚓︎
公式推导⚓︎
对于第一个时间步: $$ h1 = x \cdot U \tag{1} $$ $$ h2 = s1 \cdot Q \tag{2} $$
对于后面的时间步: $$ h1 = x \cdot U + s1_{t-1} \cdot W1 \tag{3} $$
对于所有的时间步:
对于最后一个时间步: $$ z = s2 \cdot V \tag{7} $$ $$ a = Identity(z) \tag{8} $$ $$ Loss = loss_{\tau} = \frac{1}{2} (a-y)^2 \tag{9} $$
由于是拟合任务,所以公式8的Identity()函数只是简单地令a=z,以便统一编程接口,最后用均方差做为损失函数。
注意并不是所有的循环神经网络都只在最后一个时间步有监督学习信号,而只是我们这个问题需要这样。在19.2节中的例子就是需要在每一个时间步都要有输出并计算损失函数值的。所以,公式9中只计算了最后一个时间步的损失函数值,做为整体的损失函数值。
代码实现⚓︎
注意前向计算时需要把prev_s1和prev_s2传入,即上一个时间步的两个隐层的节点值(矩阵)。
class timestep(object):
def forward(self, x, U, V, Q, W1, W2, prev_s1, prev_s2, isFirst, isLast):
...
19.6.3 反向传播⚓︎
公式推导⚓︎
反向传播部分和前面章节的内容大致相似,我们只把几个关键步骤直接列出来,不做具体推导:
对于最后一个时间步: $$ \frac{\partial Loss}{\partial z} = a-y \rightarrow dz \tag{10} $$
对于其他时间步:
对于第一个时间步:
对于其他时间步:
对于所有时间步:
代码实现⚓︎
class timestep(object):
def backward(self, y, prev_s1, prev_s2, next_dh1, next_dh2, isFirst, isLast):
...
19.6.4 运行结果⚓︎
超参设置⚓︎
我们搭建一个双隐层的循环神经网络,隐层1的神经元数为2,隐层2的神经元数也为2,其它参数保持与单隐层的循环神经网络一致:
- 网络类型:回归
- 时间步数:24
- 学习率:0.05
- 最大迭代数:100
- 批大小:64
- 输入特征数:6
- 输出维度:1
训练结果⚓︎
训练过程如图19-21所示,训练结果如表19-10所示。
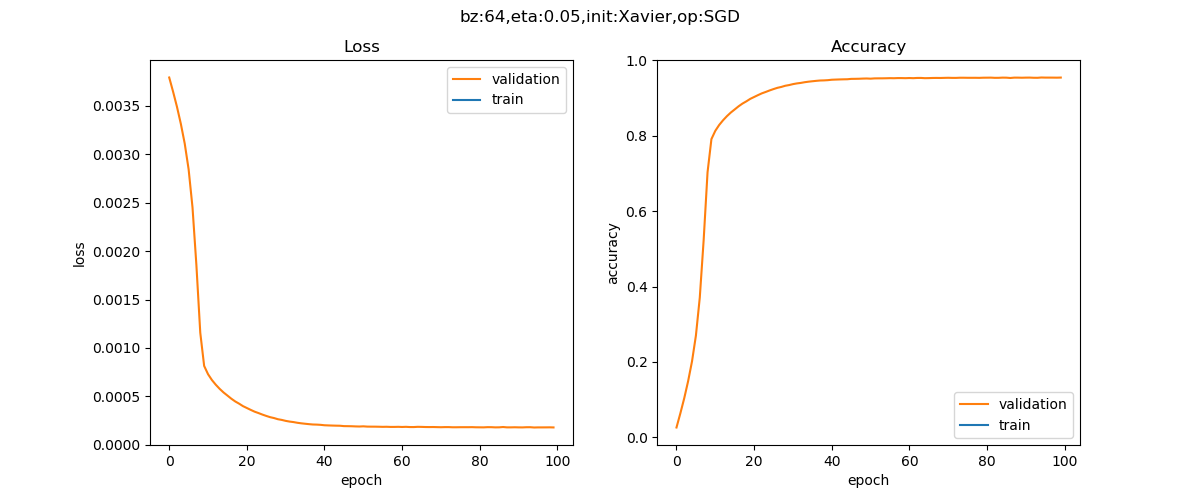
图19-21 训练过程中的损失函数值和准确度的变化
表19-10 预测时长与准确度的关系
| 预测时长 | 结果 | 预测结果 |
|---|---|---|
| 8 | 损失函数值: 0.001157 准确度: 0.740684 |
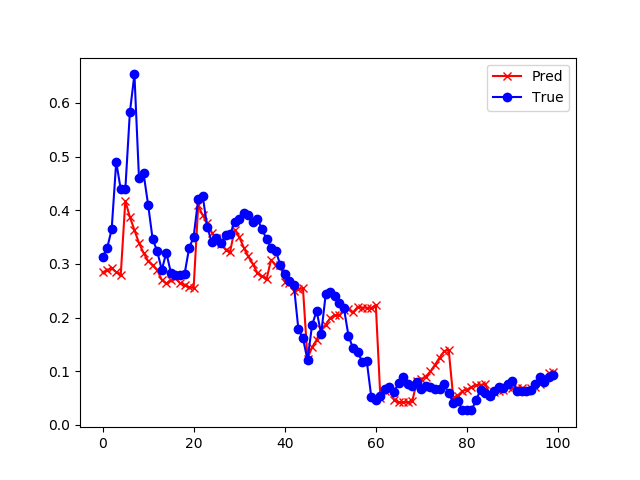 |
| 4 | 损失函数值: 0.000644 准确度: 0.855700 |
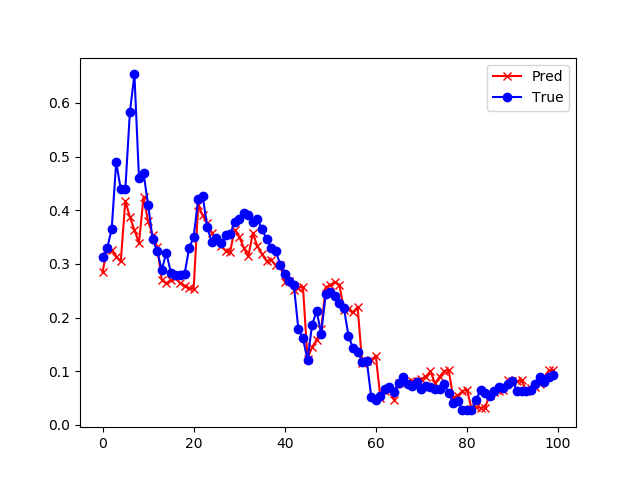 |
| 2 | 损失函数值: 0.000377 准确度: 0.915486 |
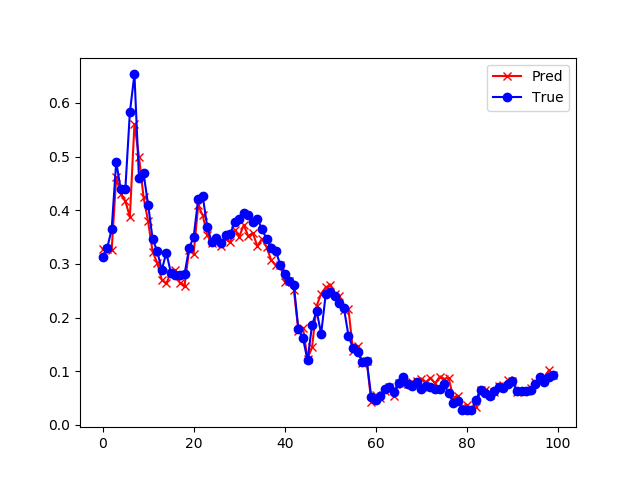 |
| 1 | 损失函数值: 0.000239 准确度: 0.946411 |
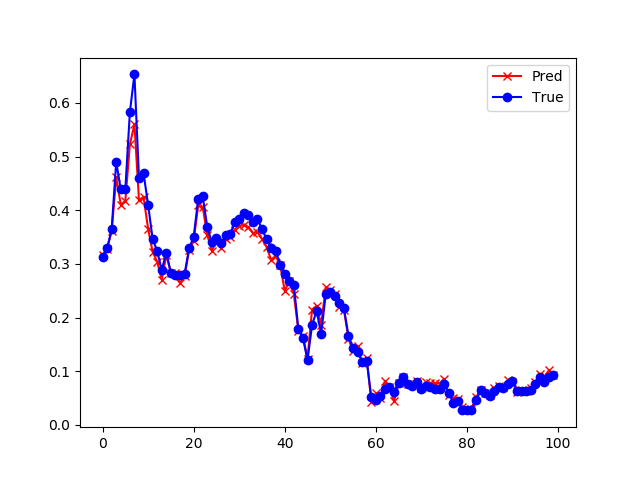 |
与单层循环神经网络的比较⚓︎
对于19.3节中的单层循环神经网络,参数配置如下:
U: 6x4+4=28
V: 4x1+1= 5
W: 4x4 =16
-----------
Total: 49
对于两层的循环神经网络来说,参数配置如下:
U: 6x2=12
Q: 2x2= 4
V: 2x1= 2
W1:2x2= 4
W2:2x2= 4
---------
Total: 26
表19-11 预测结果比较
| 单隐层循环神经网络 | 深度(双层)循环神经网络 | |
|---|---|---|
| 参数个数 | 49 | 26 |
| 损失函数值(8小时) | 0.001171 | 0.001157 |
| 损失函数值(4小时) | 0.000686 | 0.000644 |
| 损失函数值(2小时) | 0.000414 | 0.000377 |
| 损失函数值(1小时) | 0.000268 | 0.000239 |
| 准确率值(8小时) | 0.737769 | 0.740684 |
| 准确率值(4小时) | 0.846447 | 0.855700 |
| 准确率值(2小时) | 0.907291 | 0.915486 |
| 准确率值(1小时) | 0.940090 | 0.946411 |
从表19-11可以看到,双层的循环神经网络在参数少的情况下,取得了比单层循环神经网络好的效果。
代码位置⚓︎
ch19, Level6