Getting Started
AutoGen is an open-source programming framework for building AI agents and facilitating cooperation among multiple agents to solve tasks. AutoGen aims to provide an easy-to-use and flexible framework for accelerating development and research on agentic AI, like PyTorch for Deep Learning. It offers features such as agents that can converse with other agents, LLM and tool use support, autonomous and human-in-the-loop workflows, and multi-agent conversation patterns.
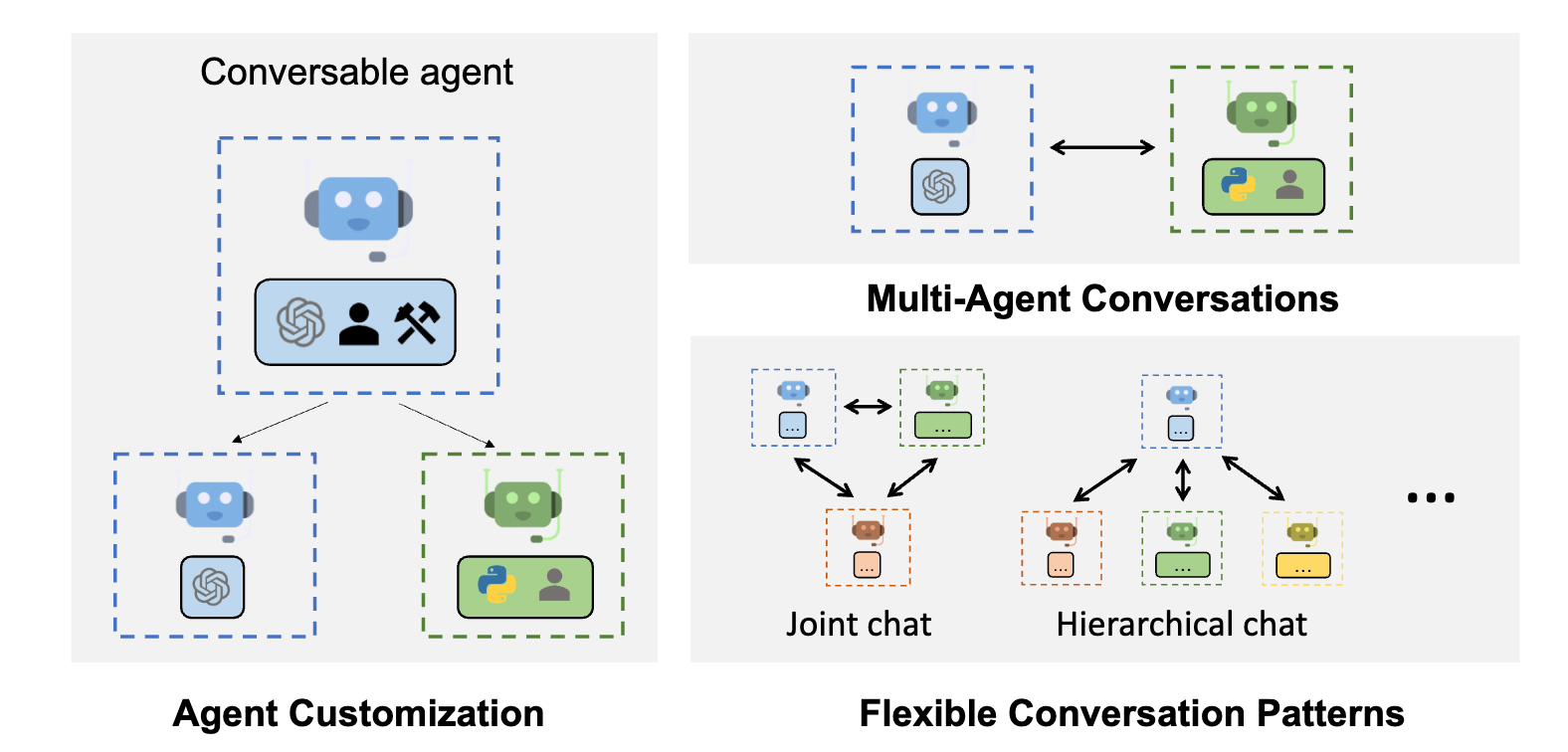
Main Features
- AutoGen enables building next-gen LLM applications based on multi-agent conversations with minimal effort. It simplifies the orchestration, automation, and optimization of a complex LLM workflow. It maximizes the performance of LLM models and overcomes their weaknesses.
- It supports diverse conversation patterns for complex workflows. With customizable and conversable agents, developers can use AutoGen to build a wide range of conversation patterns concerning conversation autonomy, the number of agents, and agent conversation topology.
- It provides a collection of working systems with different complexities. These systems span a wide range of applications from various domains and complexities. This demonstrates how AutoGen can easily support diverse conversation patterns.
AutoGen is powered by collaborative research studies from Microsoft, Penn State University, and University of Washington.
Quickstart
pip install pyautogen
- No code execution
- Local execution
- Docker execution
import os
from autogen import AssistantAgent, UserProxyAgent
llm_config = {"model": "gpt-4", "api_key": os.environ["OPENAI_API_KEY"]}
assistant = AssistantAgent("assistant", llm_config=llm_config)
user_proxy = UserProxyAgent("user_proxy", code_execution_config=False)
# Start the chat
user_proxy.initiate_chat(
assistant,
message="Tell me a joke about NVDA and TESLA stock prices.",
)
When asked, be sure to check the generated code before continuing to ensure it is safe to run.
import os
import autogen
from autogen import AssistantAgent, UserProxyAgent
llm_config = {"model": "gpt-4", "api_key": os.environ["OPENAI_API_KEY"]}
assistant = AssistantAgent("assistant", llm_config=llm_config)
user_proxy = UserProxyAgent(
"user_proxy", code_execution_config={"executor": autogen.coding.LocalCommandLineCodeExecutor(work_dir="coding")}
)
# Start the chat
user_proxy.initiate_chat(
assistant,
message="Plot a chart of NVDA and TESLA stock price change YTD.",
)
import os
import autogen
from autogen import AssistantAgent, UserProxyAgent
llm_config = {"model": "gpt-4", "api_key": os.environ["OPENAI_API_KEY"]}
with autogen.coding.DockerCommandLineCodeExecutor(work_dir="coding") as code_executor:
assistant = AssistantAgent("assistant", llm_config=llm_config)
user_proxy = UserProxyAgent(
"user_proxy", code_execution_config={"executor": code_executor}
)
# Start the chat
user_proxy.initiate_chat(
assistant,
message="Plot a chart of NVDA and TESLA stock price change YTD. Save the plot to a file called plot.png",
)
Open coding/plot.png to see the generated plot.
Learn more about configuring LLMs for agents here.
Multi-Agent Conversation Framework
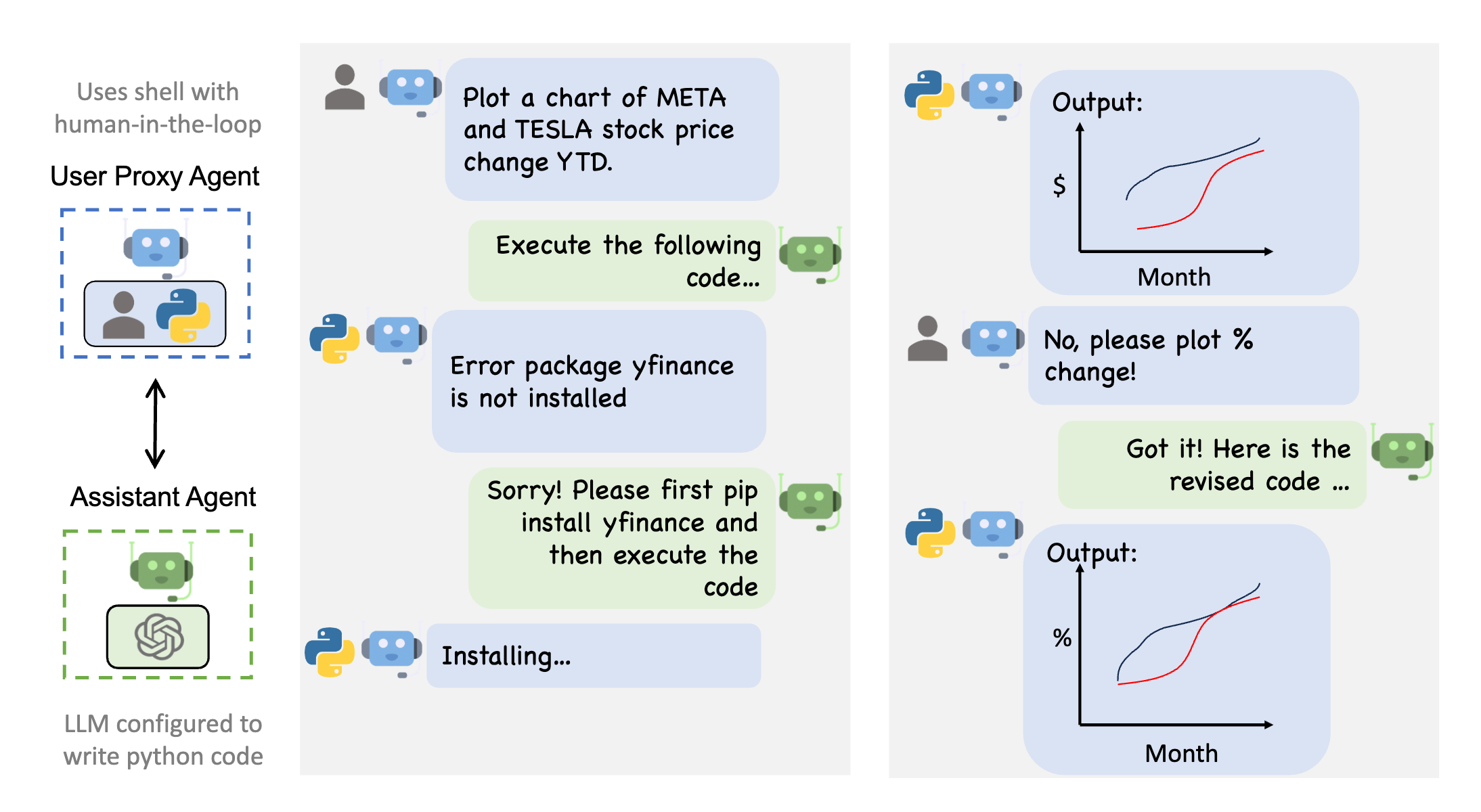
Autogen enables the next-gen LLM applications with a generic multi-agent conversation framework. It offers customizable and conversable agents which integrate LLMs, tools, and humans. By automating chat among multiple capable agents, one can easily make them collectively perform tasks autonomously or with human feedback, including tasks that require using tools via code. For example,
The figure below shows an example conversation flow with AutoGen.
Where to Go Next?
- Go through the tutorial to learn more about the core concepts in AutoGen
- Read the examples and guides in the notebooks section
- Understand the use cases for multi-agent conversation and enhanced LLM inference
- Read the API docs
- Learn about research around AutoGen
- Chat on Discord
- Follow on Twitter
- See our roadmaps
If you like our project, please give it a star on GitHub. If you are interested in contributing, please read Contributor's Guide.