Image classification
Frequently asked questions
- General
- Data
- Training
- Troubleshooting
General
How does the technology work?
State-of-the-art image classification methods, such as used in this repository, are based on Convolutional Neural Networks (CNN), a special group of Deep Learning (DL) approaches shown to work well on image data.
One advantage of CNNs is the ability to reuse a CNN trained on millions of images (typically using the ImageNet data set) by fine-tuning it using a small data set to create a customized CNN. The transfer-learning approach easily outperforms “traditional” (non-DL) approaches in terms of accuracy, easy of implementation and often inference speed. This approach fundamentally changed the design Computer Vision systems with the AlexNet paper. Given the success of transfer-learning, the most time intensive part of building a CV solution is now collecting and annotating data.
The AlexNet DNN architecture (shown below) consists of 8 layers: 5 convolution layers followed by 3 fully connected layers. Early layers learn low-level features (e.g. lines or edges) which are combined in successive layers into ever more complex concepts (e.g. wheel or face). More recent architectures such as ResNet are much deeper than AlexNet and can consist of hundreds of layers, using more advanced techniques to help model convergence.
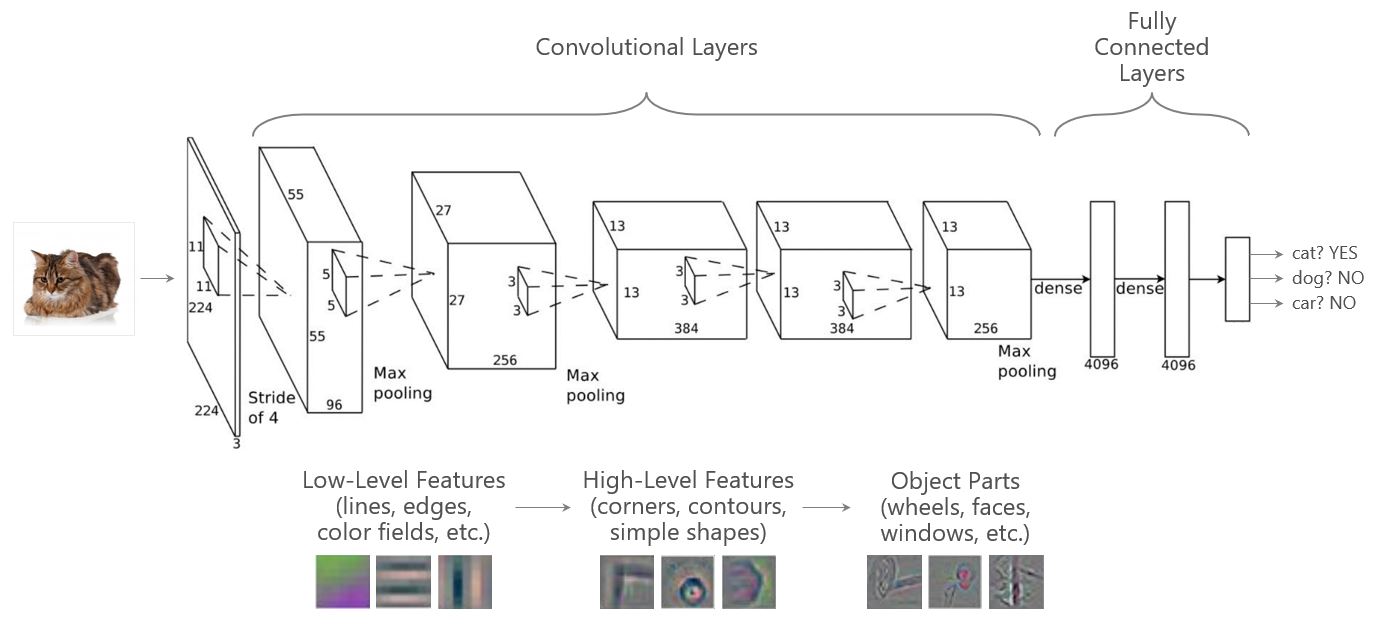
Transfer-learning is the current state-of-the-art approach for CV problems. To get started with these concepts we suggest the following references:
- CNN Features off-the-shelf: an Astounding Baseline for Recognition
- A Simple Introduction to Convolutional Neural Networks
- An Intuitive Explanation of Convnets
Which problems can be solved using image classification?
Image classification can be used if the object-of-interest is relatively large in the image (more than 20% image width/height). If the object is smaller, or if the location of the object is required, then object detection methods should be used instead.
Data
How many images are required to train a model?
This depends heavily on the complexity of the problem. For example, if the object-of-interest looks very different from image to image (viewing angle, lighting condition, etc) then more training images are required for the model to learn the appearance of the object.
We have seen instances where using ~100 images for each class has given good results. The best approach to finding the required training set size is to train the model with a small number of images and successively increase that number and observe the model accuracy improvements on a fixed test set. Once accuracy improvements stop changing (converges), more training images will not improve accuracy, and are not required.
How to collect a large set of images?
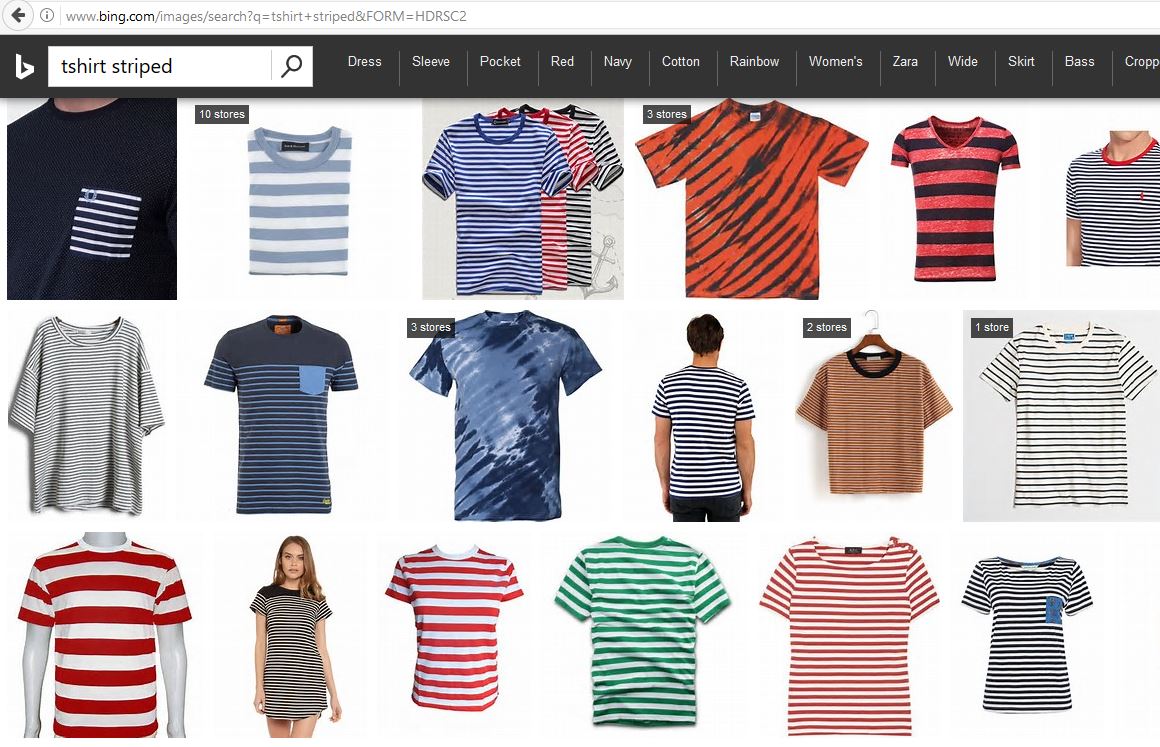
Collecting a sufficiently large number of annotated (labeled) images for training and testing can be difficult. For some problems, it may be possible to scrape additional images from the Internet. For example, we used Bing Image Search results for the query “t-shirt striped”. As expected, most images matched the query for striped t-shirts, and the few incorrect are easily identified and removed.
| Bing Image Search | Cognitive Services Image Search |
|---|---|
 |
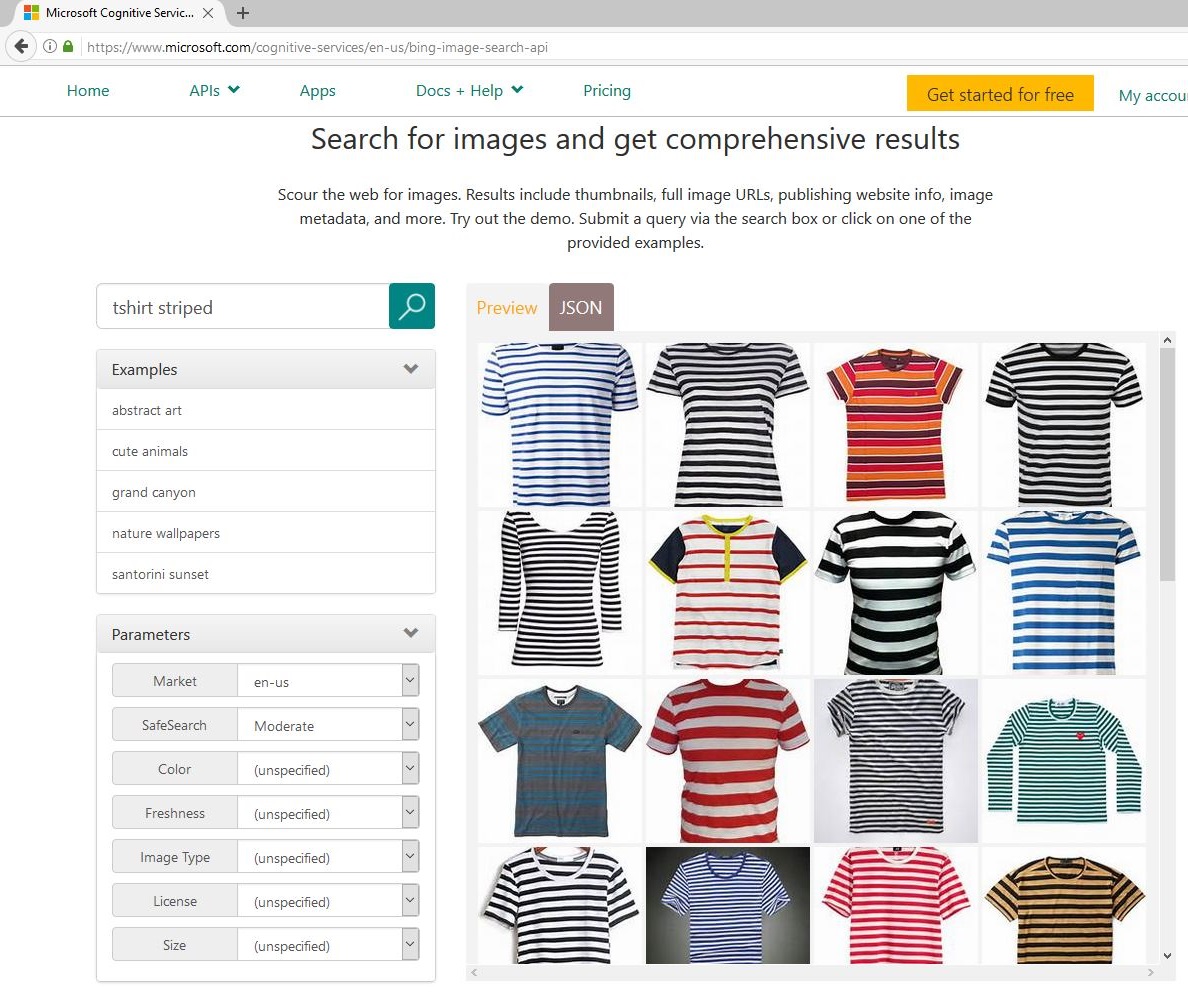 |
As an alternative to manually downloading images, the Cognitive Services Bing Image Search API (right image) can also be used for this process. To generate a large and diverse data set with Cognitive Services, multiple queries can be used. For example 7*3 = 21 queries can by synthesized using all combinations of 7 clothing items {blouse, hoodie, pullover, sweater, shirt, t-shirt, vest} and 3 attributes {striped, dotted, leopard}. Downloading the top 50 images per query leads to a maximum of 21*50=1050 images.
A caveat with automatically augmenting your training set is that some downloaded images may be exact or near duplicates (differing by image resolution or jpg artifacts). These images should be removed so that the training and test split do not contain the identical example images. A two step hashing-based approach can help steps:
- A hash string is computed for all images.
- Only images with a unique hash string are retained.
We found the dhash approach from the imagehash Python Library (blog) with a hash_size parameter set to 16 to be helpful.
How to augment image data?
Using more training data can make the model generalize better, but data collection is very expensive. Augmenting the training data with minor alterations has been proven to work well in these instances. This approach saves your having to collect more data and prevents the CV model from over fitting.
The method uses image transformations such as rotation, cropping, and adjusting brightness/contrast augmentation the training data. These do not necessarily work on all the problems but may be helpful if the transformed images are representative of the overall image population where the CV model will be applied. For example, in the figure below, flipping horizontally and vertically will hurt model performance in character recognition since these directions are informative for the model outcome. However, in the bottle image example, vertical flipping may not improving the model accuracy but horizontal flipping may. Both directions are helpful in the satellite image problem.
 Examples of different image transformations
(First row: MNIST, second row: Fridge Object, third row: Planet)
Examples of different image transformations
(First row: MNIST, second row: Fridge Object, third row: Planet)
How to annotate images?
Annotating images is complex and expensive. Consistency is key. Occluded objects should either be always annotated, or never. Ambiguous images should be removed, for example if it is unclear to a human if an image shows a lemon or a tennis ball. Ensuring consistency is difficult especially if multiple people are involved, and hence our recommendation is that only a single person annotates all images. If that person also trains the AI model, the annotation process assists in giving a better understanding of the images and of the complexity of the classification task.
Note that the test set should be of high annotation quality to ensure that model accuracy estimates are reliable.
How to split into training and test images?
Often a random split is fine but there are exceptions. For example, if the images are extracted from a movie, then having frame n in the training set and frame n+1 in the test set would result in accuracy estimates which are over-inflated since the two images are too similar. Additionally, if there is an inherent class imbalance in the data, there should be other controls to ensure that all classes are included in the training and test data sets.
How to design a good test set?
The test set should contain images which resemble the population the model will be used to score. For example, images taken under similar lighting conditions, similar angles, etc. This helps to ensure that the accuracy estimate reflects the real performance of the application which uses the trained model.
Training
How to speed up training?
- All images can be stored on a local SSD device, since HDD or network access times can dominate the training time.
- High-resolution images can slow down training due to JPEG decoding becoming the bottleneck (>10x performance penalty). See the 02_training_accuracy_vs_speed.ipynb notebook for more information.
- Very high-resolution images (>4 Mega Pixels) can be downsized before DNN training..
How to improve accuracy or inference speed?
See the 02_training_accuracy_vs_speed.ipynb notebook for a discussion around which parameters are important, and strategies to select a model optimized for faster inferencing speed.
How to monitor GPU usage during training?
Various tools for monitoring real-time GPU information (e.g. GPU or memory load) exist. This is an incomplete list of tools we’ve used:
- GPU-Z: Has an easy to install UI.
- nvidia-smi: Command line tool. Pre-installed on the Azure Data Science VM.
- GPU monitor: Python SDK for monitoring GPU on a single machine or across a cluster.
Troubleshooting
Widget is not showing
Jupyter widgets are quite unstable and might not render correctly on some systems, or often even not show at all. If that is the case, try:
- Using different browsers
- Upgrading the Jupyter notebook library using the commands below:
# Update jupyter notebook activate cv conda upgrade notebook # Run notebook server in activated 'cv' environment activate cv jupyter notebook