Multi-Object Tracking
Frequently asked questions
This document includes answers and information relating to common questions and topics regarding multi-object tracking. For more general Machine Learning questions, such as “How many training examples do I need?” or “How to monitor GPU usage during training?”, see also the image classification FAQ.
- Data
- Training and Inference
- Evaluation
- State-of-the-Art(SoTA) Technology
- Popular MOT datasets
- What is the architecture of the FairMOT tracking algorithm?
- What object detectors are used in tracking-by-detection trackers?
- What feature extraction techniques are used in tracking-by-detection trackers?
- What affinity and association techniques are used in tracking-by-detection trackers?
- What is the difference between online and offline (batch) tracking algorithms?
- [Popular Publications and Datasets]
Data
How to annotate images?
For training we use the exact same annotation format as for object detection (see this FAQ). This also means that we train from individual frames, without taking temporal location of these frames into account.
For evaluation, we follow the py-motmetrics repository which requires the ground-truth data to be in MOT challenge format. The last 3 columns can be set to -1 by default, for the purpose of ground-truth annotation:
[frame number] [id number] [bbox left] [bbox top] [bbox width] [bbox height][confidence score][class][visibility]
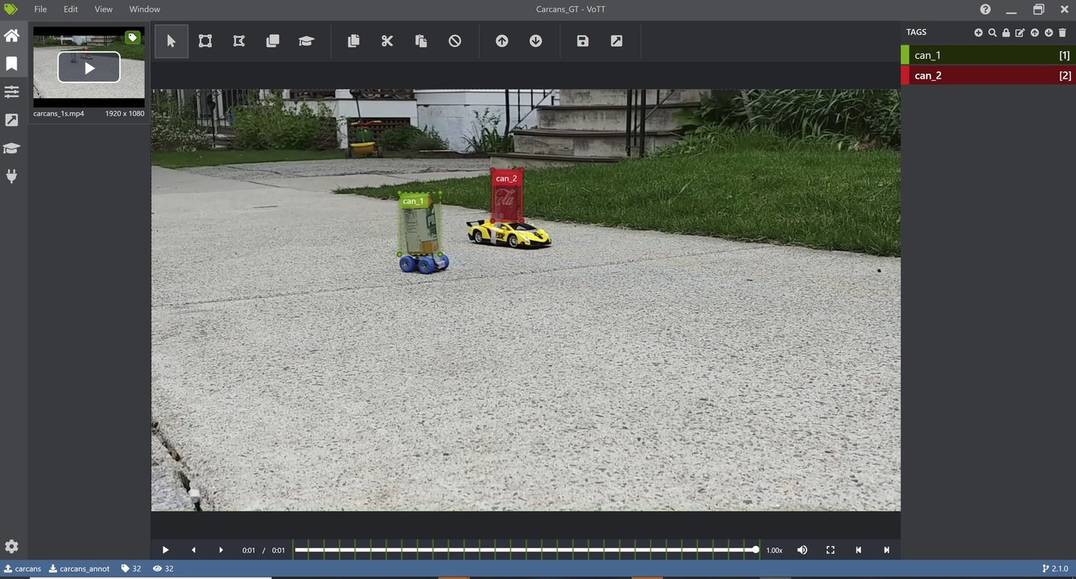
See below an example where we use VOTT to annotate the two cans in the image as can_1 and can_2 where can_1 refers to the white/yellow can and can_2 refers to the red can. Before annotating, it is important to correctly set the extraction rate to match that of the video. After annotation, you can export the annotation results into several forms, such as PASCAL VOC or .csv form. For the .csv format, VOTT would return the extracted frames, as well as a csv file containing the bounding box and id info:
[image] [xmin] [y_min] [x_max] [y_max] [label]
Under the hood (not exposed to the user) the FairMOT repository uses this annotation format for training where each line describes a bounding box as follows, as described in the Towards-Realtime-MOT repository:
[class] [identity] [x_center] [y_center] [width] [height]
The class field is set to 0, for all, as only single-class multi-object tracking is currently supported by the FairMOT repo (e.g. cans). The field identity is an integer from 0 to num_identities - 1 which maps class names to integers (e.g. coke can, coffee can, etc). The values of [x_center] [y_center] [width] [height] are normalized by the width/height of the image, and range from 0 to 1.
Training and inference
What are the training losses in FairMOT?
Losses generated by FairMOT include detection-specific losses (e.g. hm_loss, wh_loss, off_loss) and id-specific losses (id_loss). The overall loss (loss) is a weighted average of the detection-specific and id-specific losses, see the FairMOT paper.
What are the main inference parameters in FairMOT?
- input_w and input_h: image resolution of the dataset video frames
- conf_thres, nms_thres, min_box_area: these thresholds used to filter out detections that do not meet the confidence level, nms level and size as per the user requirement;
- track_buffer: if a lost track is not matched for some number of frames as determined by this threshold, it is deleted, i.e. the id is not reused.
Evaluation
What is the MOT Challenge?
The MOT Challenge website hosts the most common benchmarking datasets for pedestrian MOT. Different datasets exist: MOT15, MOT16/17, MOT 19/20. These datasets contain many video sequences, with different tracking difficulty levels, with annotated ground-truth. Detections are also provided for optional use by the participating tracking algorithms.
What are the commonly used evaluation metrics?
As multi-object-tracking is a complex CV task, there exists many different metrics to evaluate the tracking performance. Based on how they are computed, metrics can be event-based CLEARMOT metrics or id-based metrics. The main metrics used to gauge performance in the MOT benchmarking challenge include MOTA, IDF1, and ID-switch.
- MOTA (Multiple Object Tracking Accuracy) gauges overall accuracy performance using an event-based computation of how often mismatch occurs between the tracking results and ground-truth. MOTA contains the counts of FP (false-positive), FN (false negative), and id-switches (IDSW) normalized over the total number of ground-truth (GT) tracks.
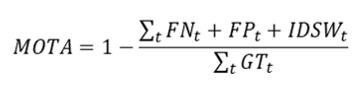
- IDF1 measures overall performance with id-based computation of how long the tracker correctly identifies the target. It is the harmonic mean of identification precision (IDP) and recall (IDR).

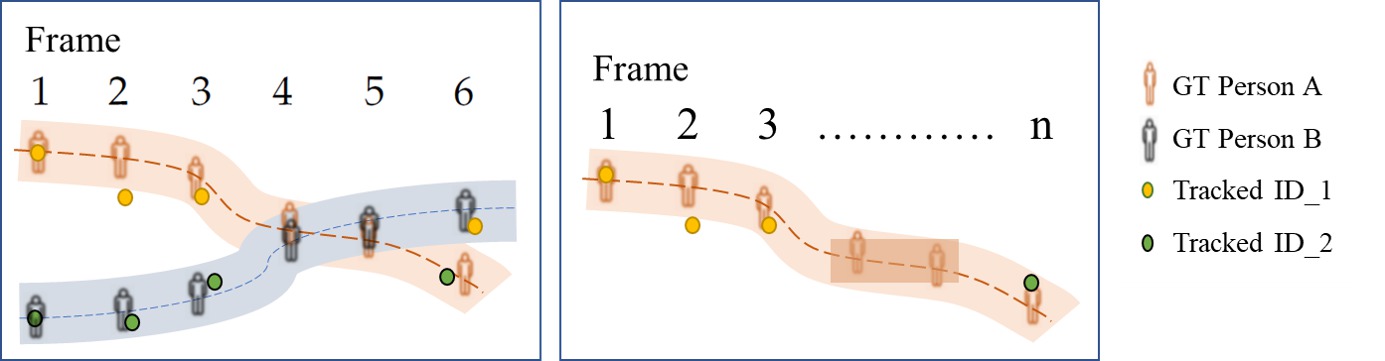
- ID-switch measures when the tracker incorrectly changes the ID of a trajectory. This is illustrated in the following figure: in the left box, person A and person B overlap and are not detected and tracked in frames 4-5. This results in an id-switch in frame 6, where person A is attributed the ID_2, which was previously tagged as person B. In another example in the right box, the tracker loses track of person A (initially identified as ID_1) after frame 3, and eventually identifies that person with a new ID (ID_2) in frame n, showing another instance of id-switch.
State-of-the-Art
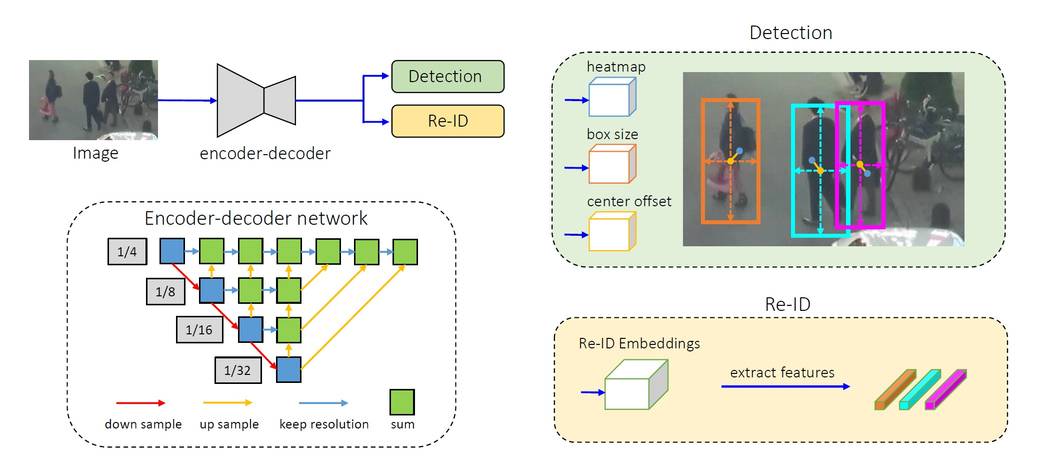
What is the architecture of the FairMOT tracking algorithm?
It consists of a single encoder-decoder neural network that extracts high resolution feature maps of the image frame. As a one-shot tracker, it feeds into two parallel heads for predicting bounding boxes and re-id features respectively, see source:
What object detectors are used in tracking-by-detection trackers?
The most popular object detectors used by SoTA tacking algorithms include: Faster R-CNN, SSD and YOLOv3. Please see our object detection FAQ page for more details.
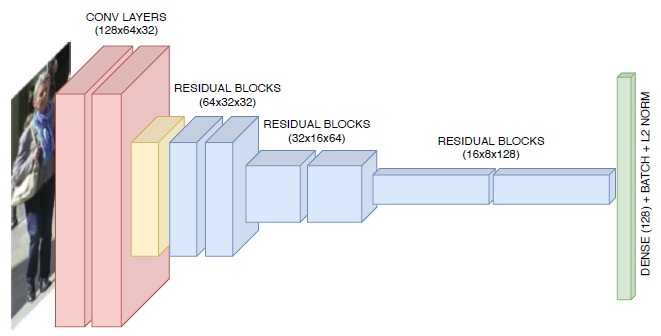
What feature extraction techniques are used in tracking-by-detection trackers?
While older algorithms used local features, such as optical flow or regional features (e.g. color histograms, gradient-based features or covariance matrix), newer algorithms have deep-learning based feature representations. The most common deep-learning approaches, typically trained on re-id datasets, use classical CNNs to extract visual features. One such dataset is the MARS dataset. The following figure is an example of a CNN used for MOT by the DeepSORT tracker:
<p align="center">
 </p>
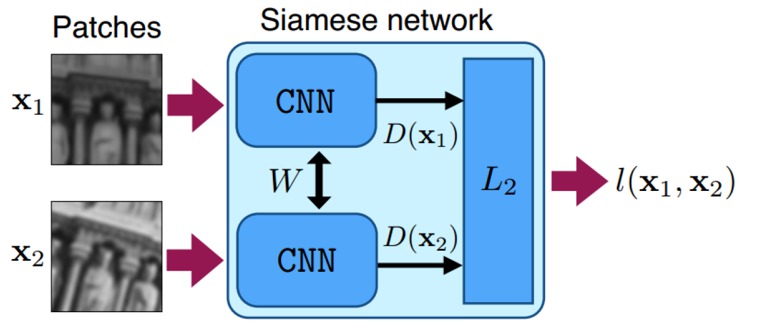
Newer deep-learning approaches include Siamese CNN networks, LSTM networks, or CNN with correlation filters. In Siamese CNN networks, a pair of identical CNN networks are used to measure similarity between two objects, and the CNNs are trained with loss functions that learn features that best differentiate them.
<p align="center">
</p>
Newer deep-learning approaches include Siamese CNN networks, LSTM networks, or CNN with correlation filters. In Siamese CNN networks, a pair of identical CNN networks are used to measure similarity between two objects, and the CNNs are trained with loss functions that learn features that best differentiate them.
<p align="center">
 </p>
</p>
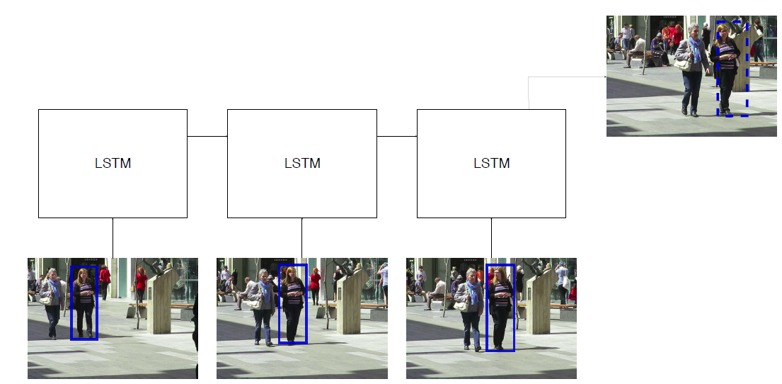
In an LSTM network, extracted features from different detections in different time frames are used as inputs. The network predicts the bounding box for the next frame based on the input history.
<p align="center">
 </p>
</p>
Correlation filters can also be convolved with feature maps from CNN network to generate a prediction of the target’s location in the next time frame. This was done by Ma et al as follows:
<p align="center">
 </p>
</p>
What affinity and association techniques are used in tracking-by-detection trackers?
Simple approaches use similarity/affinity scores calculated from distance measures over features extracted by the CNN to optimally match object detections/tracklets with established object tracks across successive frames. To do this matching, Hungarian (Huhn-Munkres) algorithm is often used for online data association, while K-partite graph global optimization techniques are used for offline data association.
In more complex deep-learning approaches, the affinity computation is often merged with feature extraction. For instance, Siamese CNNs and Siamese LSTMs directly output the affinity score.
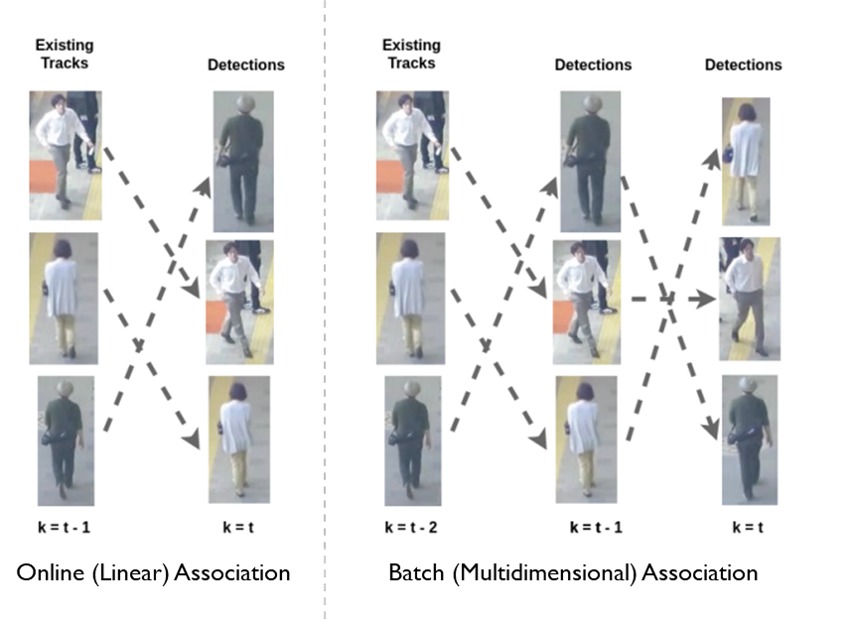
What is the difference between online and offline tracking algorithms?
Online and offline algorithms differ at their data association step. In online tracking, the detections in a new frame are associated with tracks generated previously from previous frames. Thus, existing tracks are extended or new tracks are created. In offline (batch) tracking, all observations in a batch of frames can be considered globally (see figure below), i.e. they are linked together into tracks by obtaining a global optimal solution. Offline tracking can perform better with tracking issues such as long-term occlusion, or similar targets that are spatially close. However, offline tracking tends to be slower and hence not suitable for tasks which require real-time processing such as autonomous driving.