TL;DR
💭 High quality bug generation is key to training the next iteration of language model based software engineering (SWE) agents
💭 Current synthetic bug pipelines (e.g. SWE-Smith) involve intentionally perturbing the code to cause issues, introducing an out-of-distribution effect from real world bug generation
💡 We introduce a method where LLM agents try to create new features, thereby breaking existing tests unintentionally. We find through a qualitative analysis that these bugs are more similar to those generated by humans.
🎯 Training on these bugs results in FrogBoss a SoTA 32B model and FrogMini, a SoTA 14B model with 54.6% pass@1 accuracy and 45.27% pass@1 accuracy respectively averaged over 3 seeds on SWE-Bench-Verified
ℹ️ Note: The scores correspond to the FrogBoss-32B-2510 and FrogMini-14B-2510 on the SWE-bench-Verified official leaderboard. In this blog post and in the paper we report the pass@1, i.e., averaged scores over 3 seeds; in the leaderboard (which expects a single run) we submitted the run that got the median score. This accounts for any differences between our reported scores and those on the leaderboard.
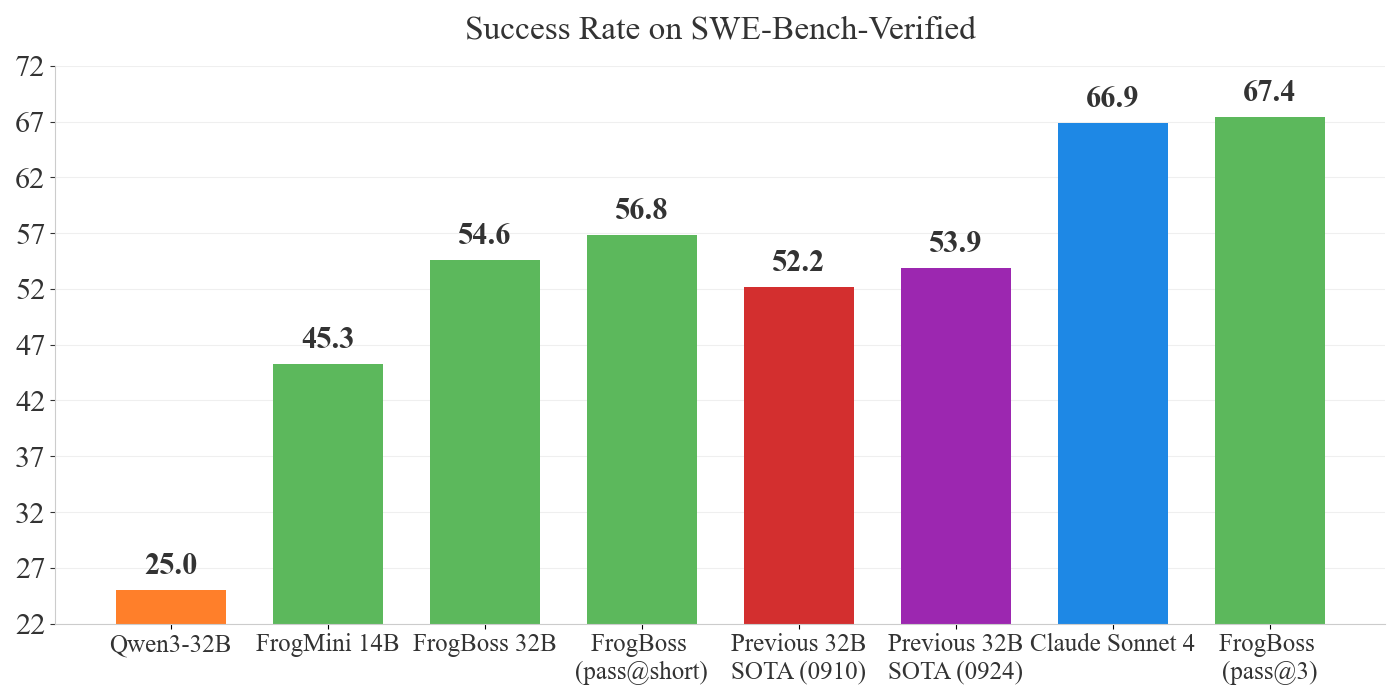
Training on our more difficult bugs results in higher results than the existing 32B models on SWE-Bench-Verified. With pass@3 we are able to outperform Claude Sonnet 4, indicating what performance improvements could be achieved with good test-time scaling or a good test-time verifier. Pass@Short refers to a simple test-time scaling approach where we select the shortest run from an existing set of runs.
We call our model FrogBoss, because it loves to eat bugs… like a boss
1. Why is the synthetic generation of difficult bugs important?
💡 Synthetic bugs allow us to generate examples for training without relying on existing repositories with pull requests and GitHub issues. Using this we can easily generalize to new languages and codebases
Many approaches to curating bug datasets rely on the expensive curation of pull requests and GitHub issues from open-source datasets. This approach has two downsides:
- It limits the choice of repositories to those found in open-source datasets, not allowing users to create bug examples on less popular languages or repositories
- The complexity of the bugs solved by open-source developers may not reflect the challenges involved when something goes wrong within the SWE development process
Current approaches for synthetic bug generation, such as SWE-Smith involve the injection of code perturbations into function thereby breaking the codebase intentionally. In contrast, we introduce an approach whereby an agent introduces features to a codebase (nicknamed FeatAdd), reflecting real-world software development practices and thereby breaks the codebase unintentionally.
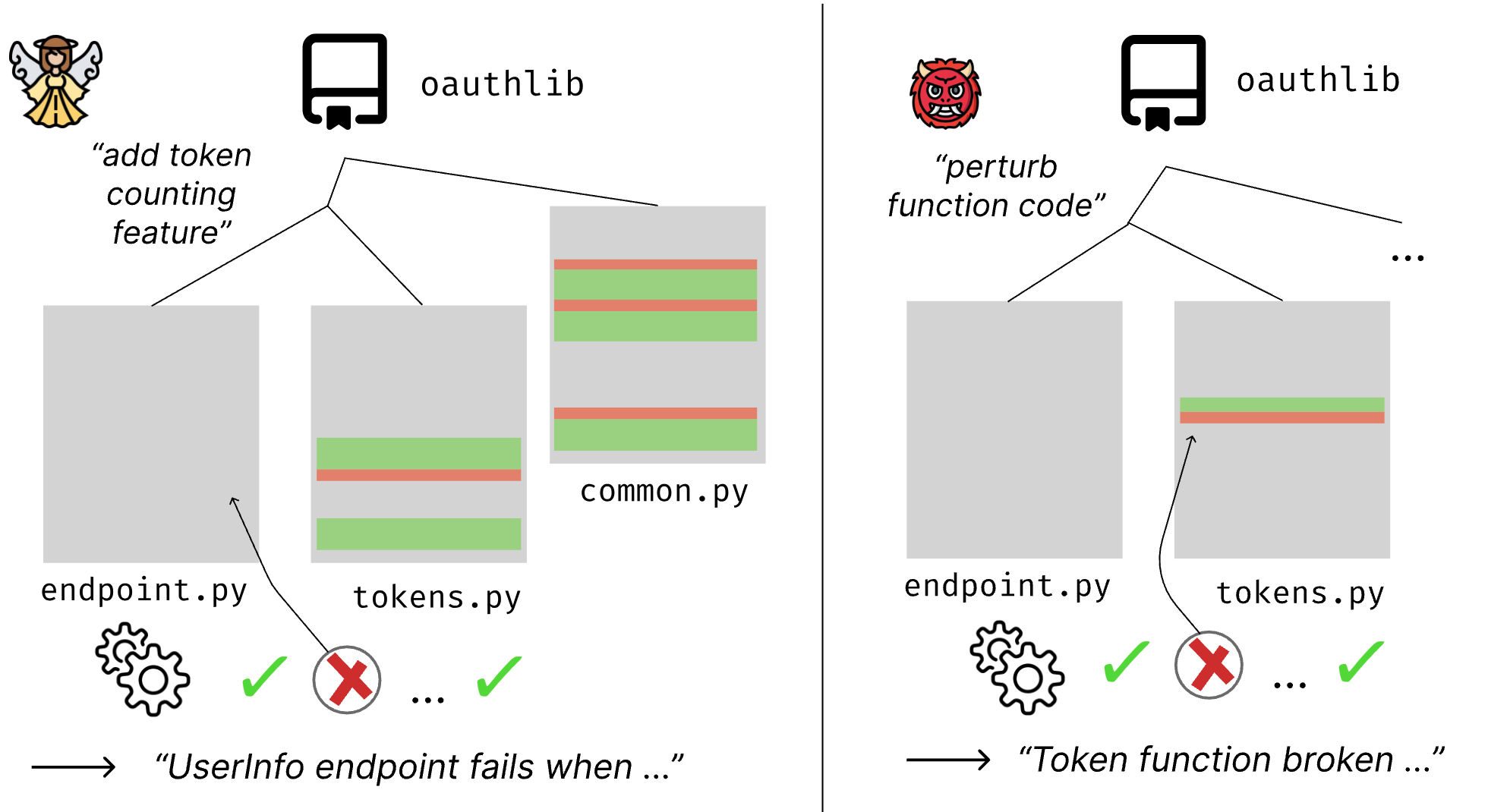 Illustration of the difference between our feature addition (FeatAdd) bug generation and intentional bug generation (e.g. SWE-Smith and an agentic approach that intentionally introduces hard bugs).
Illustration of the difference between our feature addition (FeatAdd) bug generation and intentional bug generation (e.g. SWE-Smith and an agentic approach that intentionally introduces hard bugs).
2. FeatAdd & BugInstruct: Agentic Bug Generation
💡 By prompting an agent to introduce a feature and thereby unintentionally create bugs, we can create a bug dataset that is more natural and more difficult than existing bug datasets
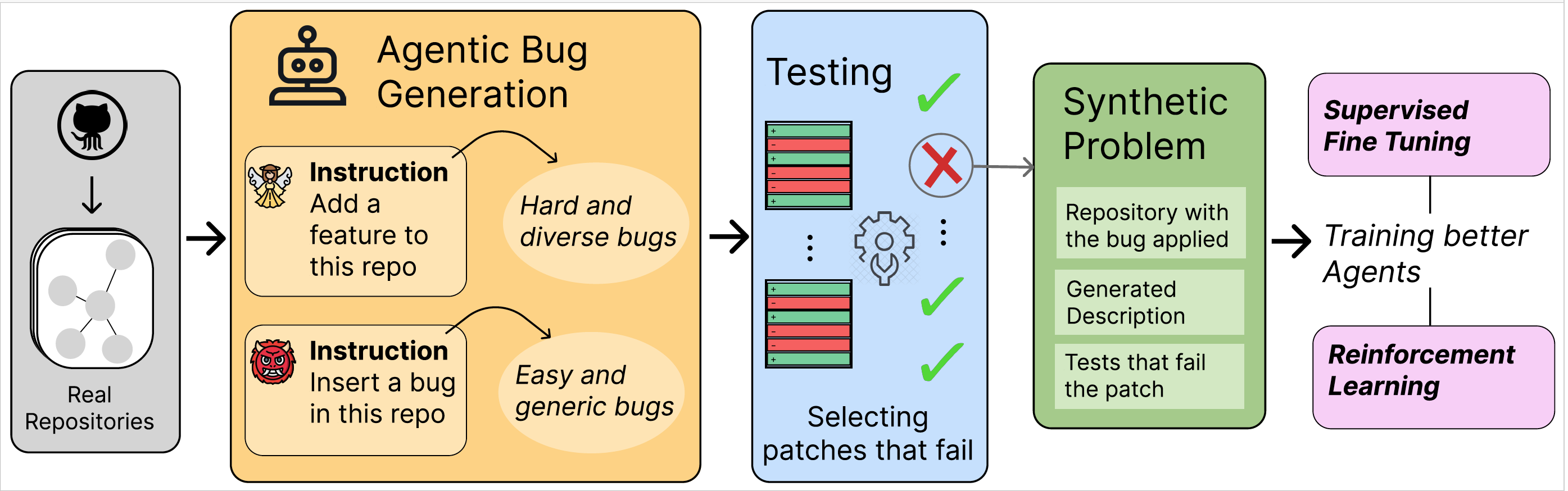
Our pipeline works as follows:
- We prompt SWE-Agent to introduce a feature on one of the SWE-Smith repositories
- We test the generated feature patch to see if it made any of the existing tests fail
- We generate a synthetic problem statement from this
- We use these problems as examples for supervised fine-tuning and RL fine-tuning
To reflect the process of real-world software engineering (SWE), we introduce an approach where we prompt a SWE agent to introduce a feature. By introducing this feature, the agent thereby unintentionally breaks the existing test cases. To isolate the effect of unintentional bug generation from agentic bug generation we also ablate with an agent adding bugs intentionally. In our quantitative results, we find that these intentionally generated bugs are far less useful for training and qualitatively quite dissimilar from realistic bugs.
3. Bug Analysis: qualitative similarity and difficulty
💡 We show that our unintentionally generated bugs are more qualitatively similar to human-authored edits, through a qualitative analysis using LLMs
💡 Our bugs are more difficult and more complicated than existing bug datasets, with Claude 4 Sonnet solving 25% fewer of our synthetically generated bugs than SWE-Smith
We hypothesize that the unintentional nature of our bug generation approach would lead to bugs being more similar to those authored by humans. Moreover, we hypothesize that these types of bugs that are more reflective of real-world software development practices would be more complicated than other approaches from scraping problems from existing repositories or intentionally perturbing codebases.
Qualitative Analysis
We perform a qualitative analysis on our synthetic bugs, using an LLM (o3) to first summarize the bugs, and then cluster the bugs into 10 distinct categories.
We analyze five different datasets for our qualitative analysis and find that unintentionally generated bugs more closely reflect the problems in SWE-Bench-Verified and R2E-Gym, which are human-authored edits and are generally more diverse across different problem types.
Bug Datasets
SWE-Bench-Verified: a dataset of 500 human-authored edits curated from real-world pull requests and issues.
R2E-Gym: A set of bugs curated from human-authored commits, where the authors rollback commits until the test suite breaks.
SWE-Smith: A synthetic bug generation approach whereby the authors introduce small perturbations to the codebase to introduce bugs.
BugInstruct (ours): An agentic bug generation approach, where the agent is instructed to intentionally break the existing tests
FeatAdd (ours): An agent is instructed to introduce a feature to the codebase, during which it unintentionally breaks the existing test cases.
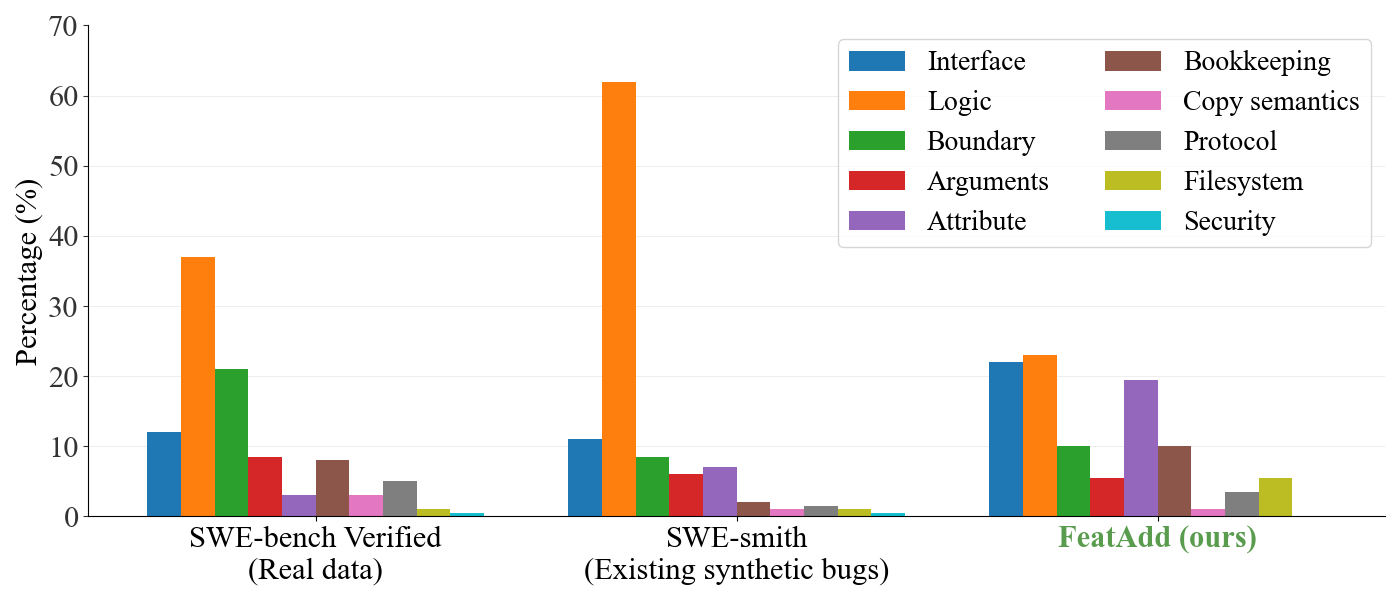
We can see that unintentionally generated bugs more closely reflect the problems in SWE-Bench-Verified and R2E-Gym, which are human-authored edits and are generally more diverse across different problem types.
Quantitative Analysis
FeatAdd Bugs are more complicated
We find that our bugs are more complicated than existing bug generation techniques, illustrated by a larger number of lines and files edited in the bug patch. We compare our FeatAdd bugs to other bug datasets along the quantitative axes of the number of files modified and the number of lines changed.
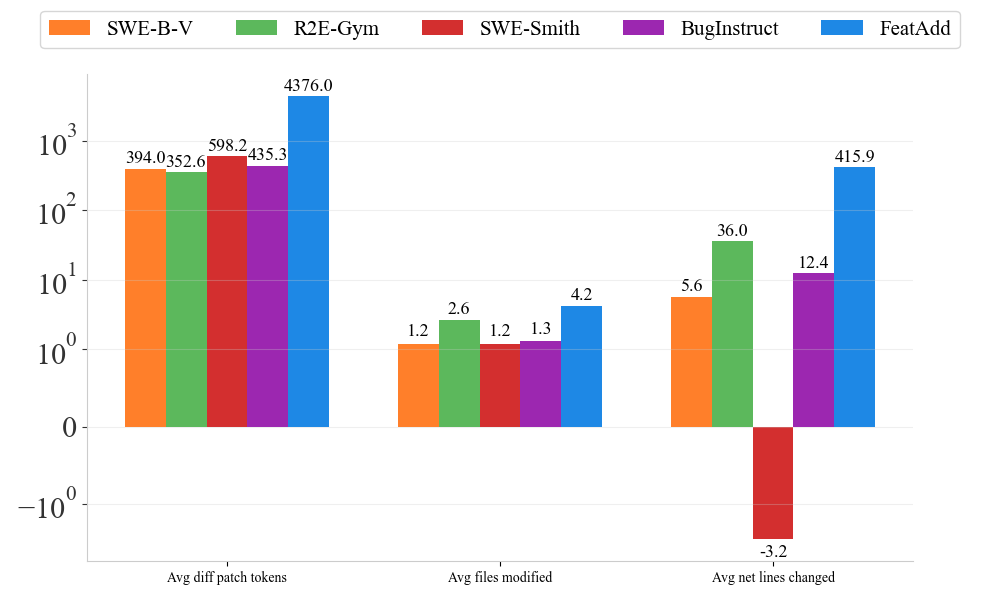
A quantitative analysis of our bugs showing that our bugs are more complex along standard metrics
FeatAdd bugs are more difficult
Claude 4 Sonnet has a 25% drop in performance on FeatAdd bugs compared to SWE-Smith, indicating that FeatAdd bugs are significantly more difficult than existing synthetic bugs (e.g. SWE-Smith). Moreover, FeatAdd bugs take on average 5 more steps to solve than SWE-Smith tasks.
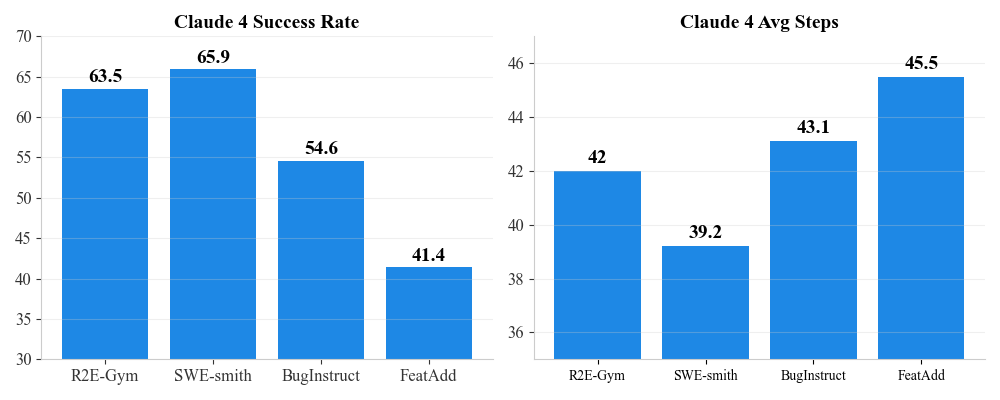
4. Results from Training on Our Tasks
🎯 We fine-tune on a combined dataset of all of our bugs to get FrogBoss a SoTA 32B model on SWE-Bench-Verified with 54.6% pass@1 averaged over three seeds before test-time scaling.
🎯 Using the same recipe we introduce FrogMini a SoTA 14B model on SWE-Bench-Verified with 45.3% pass@1 averaged over three seeds.
Our RL-trained model establishes a new state-of-the-art on SWE-Bench-Verified, achieving 52.4% Pass@1 (averaged over three seeds). Notably, in the supervised fine-tuning setting, BaseMix+ FeatAdd reaches nearly identical performance at 51.9% while being substantially more data-efficient than concurrent work—using 40% fewer trajectories and only 5% as many bugs in the SFT dataset compared to SWE-Mirror. Building on these results, we trained our best-performing model, FrogBoss, using the full trajectory set: 2k bugs each from R2E-Gym, SWE-Smith, and FeatAdd. Despite using a 25% smaller dataset than previous work (9k vs. 12k bugs), this configuration achieves 54.6% Pass@1, our highest result. We follow this same recipe to get a SoTA 14B model FrogMini with 45.3% pass@1 averaged over three seeds on SWE Bench Verified. These findings demonstrate that FeatAdd, our high-quality synthetic dataset, enables both superior performance and greater data efficiency in training software engineering agents.
Comparison to different training strategies
First we prepare a dataset by sampling from Claude Sonnet 4, because we find that this has significantly better performance than training on GPT-5 and GPT-4o generated trajectories.
BaseMix: We prepare a set of 1000 tasks from R2E-Gym and 1000 tasks from SWE-Smith and collect trajectories from these tasks.
To isolate the effect of training on FeatAdd bugs versus fine-tuning on more tasks from R2E-Gym and SWE-Smith we create new datasets of 1k tasks each from FeatAdd, SWE-Smith, BugInstruct, and R2E-Gym and test the results for further fine-tuning on these.
For the different data mixtures, we find that using our FeatAdd bugs performs 2.5% better than training on the basemix and 1.5% better than training on other synthetic datasets (e.g. SWE-Smith and BugInstruct) for further fine-tuning. Moreover, we find that finetuning with RL on the other datasets (e.g. R2E-Gym or SWE-Smith) does not result in good performance. Note that the more challenging FeatAdd problems have fewer examples in the dataset, so they are thereby learning more efficiently.
Finally, when we train on all of our bugs, we can train FrogBoss a SoTA 32B model and FrogMini a SoTA 14B model.
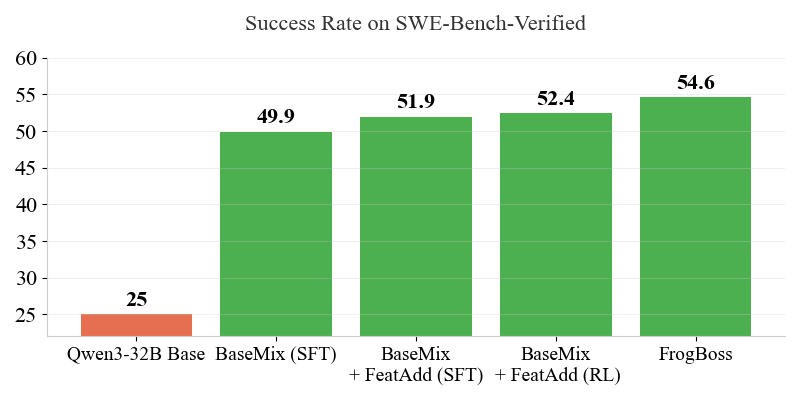
Reinforcement Learning
To fine-tune with reinforcement learning, we start with the model trained with the BaseMix model and fine-tune for only 25 steps with RL, where each step has 64 problems and 8 rollouts each. We find that fine-tuning with RL on other datasets is not as effective as finetuning on the FeatAdd bugs.
We do not get significant gains from RL fine-tuning on the BaseMix bugs, but we see substantial improvement when using our FeatAdd bugs for RL fine-tuning.
5. References
Previous SOTA:
(1) Wang, Junhao, et al. “SWE-Mirror: Scaling Issue-Resolving Datasets by Mirroring Issues Across Repositories.” arXiv preprint arXiv:2509.08724 (2025).
(2) Carbonneaux, Quentin, et al. “Cwm: An open-weights llm for research on code generation with world models.” arXiv preprint arXiv:2510.02387 (2025).
Previous Datasets:
(3) Jain, Naman, et al. “R2e-gym: Procedural environments and hybrid verifiers for scaling open-weights swe agents.” arXiv preprint arXiv:2504.07164 (2025).
(4) Yang, John, et al. “Swe-smith: Scaling data for software engineering agents.” arXiv preprint arXiv:2504.21798 (2025).
SWE Bench and SWE Agent:
(5) Jimenez, Carlos E., et al. “Swe-bench: Can language models resolve real-world github issues?.” arXiv preprint arXiv:2310.06770 (2023).
(6) Yang, John, et al. “Swe-agent: Agent-computer interfaces enable automated software engineering.” Advances in Neural Information Processing Systems 37 (2024): 50528-50652.