TL;DR
⚡️ We introduce Gistify, a task that asks an agent to extract the gist of a repository: generate a single, executable, and self-contained file that faithfully reproduces the behavior of a given command (e.g., a test or entrypoint).
💡 Gistify evaluates an agent’s ability to reason over runtime execution, identify only the minimal required code, and avoid hallucinations.
🤯 Even strong LLMs/frameworks struggle, especially on long, multi-file traces; execution or global-context tools provide modest gains, and early success of preserving the original test/entrypoint is closely tied to correctly understanding the repository and an indicator of success.
Limitations of existing codebase-level understanding tasks
- Prior benchmarks often don’t require full runtime reasoning; many can be solved with heuristic shortcuts or localized patch retrieval.
- Many datasets are built from GitHub issues or pull requests, making them difficult to generalize to arbitrary repositories.
- As coding agents move into large, real-world codebases, we need automatically constructed, broadly applicable, and more challenging repository-level evaluations.
What is Gistify?
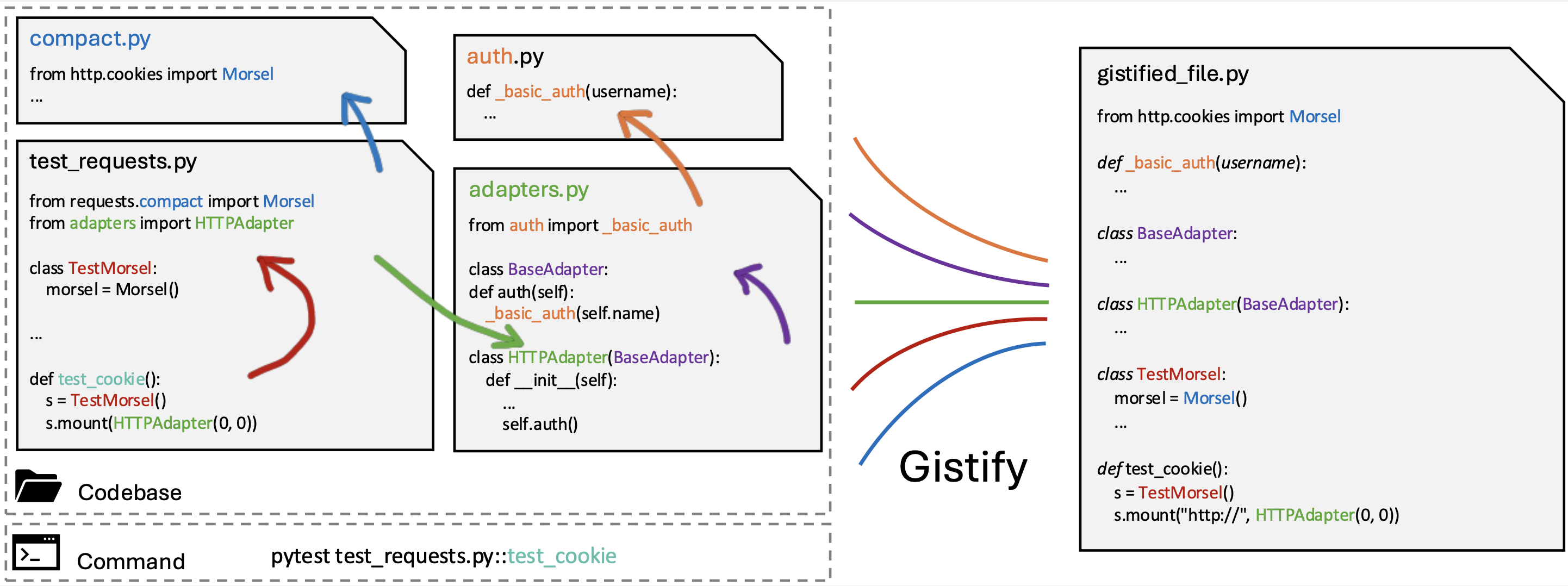
🔍 Given (1) a codebase (Dockerized for consistent eval) and (2) an entry command (e.g.,
pytest path::test_case), the agent must produce a single gistified file that:
- Self-contained: includes everything it needs and is executable independent of the original repo
- Execution fidelity: same outputs/behavior with original codebase under the given command
- Minimality: retain only the essential code required to execute
- Faithful preservation: every line is preserved from the repo (no hallucinated code)
Why does this matter?
- Gistify directly tests whether models can reason at the codebase level, including runtime behavior and cross-file execution.
- It enables a lightweight, broadly applicable evaluation that can automatically generate challenging tasks for any repository, including private ones.
- The resulting gistified files are valuable artifacts: by compressing a specific behavior into a minimal, standalone script, they can support downstream tasks such as automated debugging and error localization.
How the task is evaluated
We align metrics with the requirements of Gistify:
- Execution Fidelity: Is the generated file executable and produces the same output as the full codebase under the given command?
- Line Existence Rate: What fraction of lines in the generated file come from the original repository? (Measuring no hallucination)
- Line Execution Rate: What fraction of the lines in the generated file were actually executed under that command? (Measuring minimality)
In short:
Does it work? Does it reuse original code instead of inventing new logic? And is it as lean as possible?
Experiments
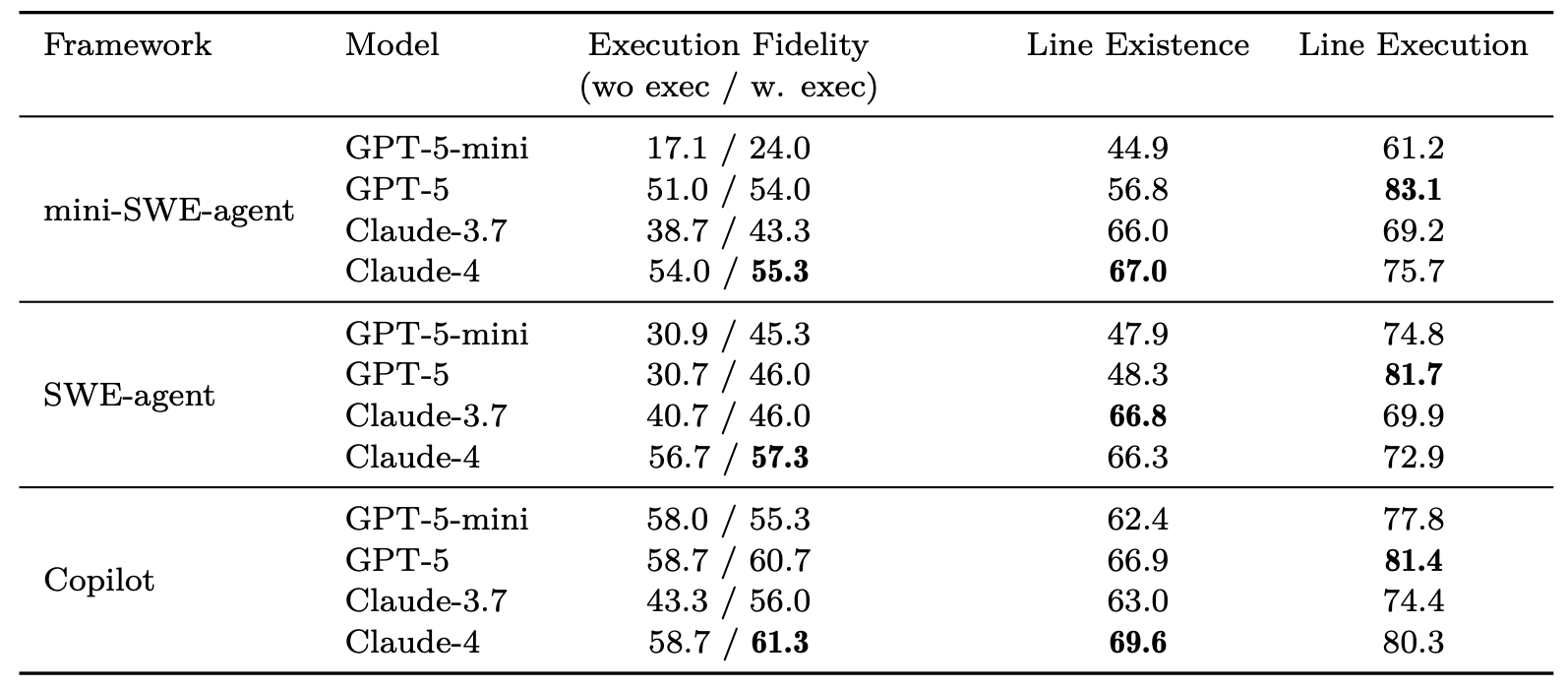
📈 We evaluate Gistify across multiple agent frameworks (Mini-SWE-Agent, SWE-Agent, Copilot) and model families (GPT-5-mini, GPT-5, Claude-3.7-Sonnet, Claude-4).
- Even with strong models and frameworks, success remains limited: reliably producing a correct gistified file is still difficult, with Claude-4 performing the most robustly overall.
- Model scale matters: smaller/earlier models perform worse, though scaffolding can partially help.
- Different model families exhibit distinct strengths: Claude-4 preserves original code (high line-existence), while GPT-5 produces more concise files (high line-execution).
- Execution tools offer limited improvement: adding execution tool access yields only modest gains—the core challenge remains tracing and extracting behavior spread across many files.
Effect of various strategies and Tools
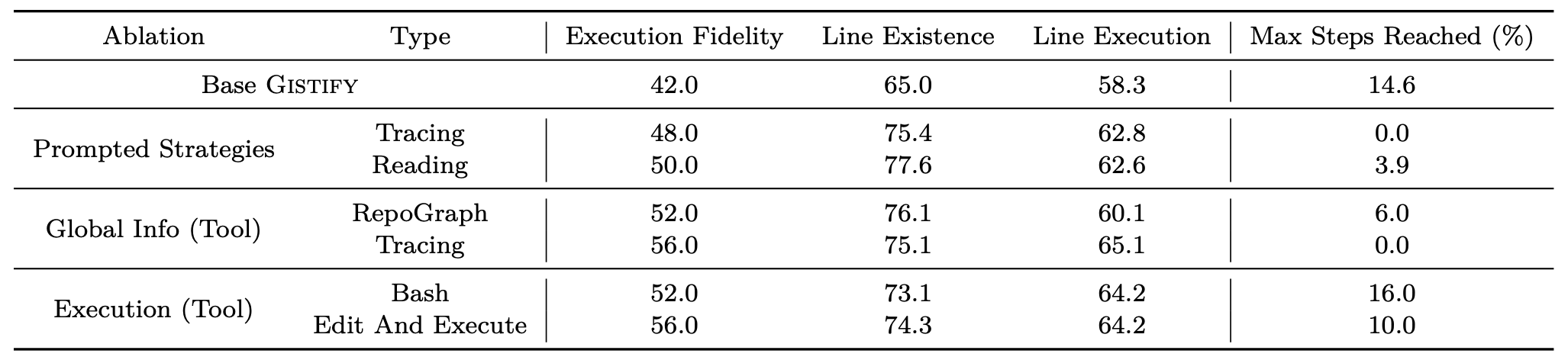
- Tool-assisted setups outperform prompt-only guidance: Global Info (Tool), Execution (Tool) tend to show higher performance than modifying prompt only (Prompted Strategies) generally.
- Tracing > RepoGraph: Access to global context, especially gold execution traces, greatly improves runtime reasoning by helping the model pinpoint which files matter.
- More freedom isn’t always better: Full terminal access can hurt performance. Broad exploration often hits step limits (Max Steps Reached) and still fails to produce a well-constructed gistified file.
What makes Gistify difficult?
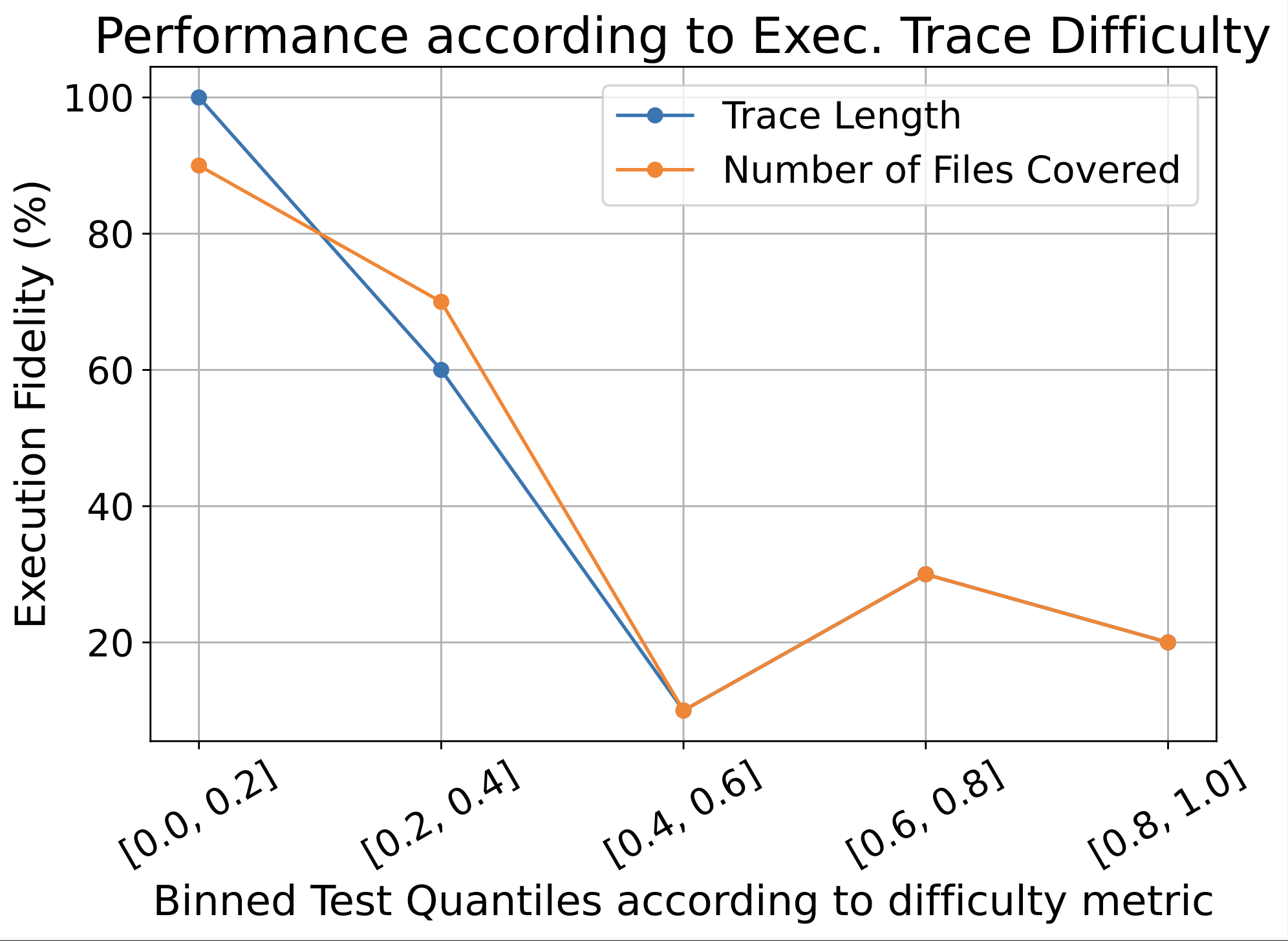
Two axes correlate with lower success:
- Trace length: deeper call chains mean more code to inline, more state to track
- File coverage: spreading logic across many files increases the risk of missed edges, mocks, or import errors
What about static coding LLM?
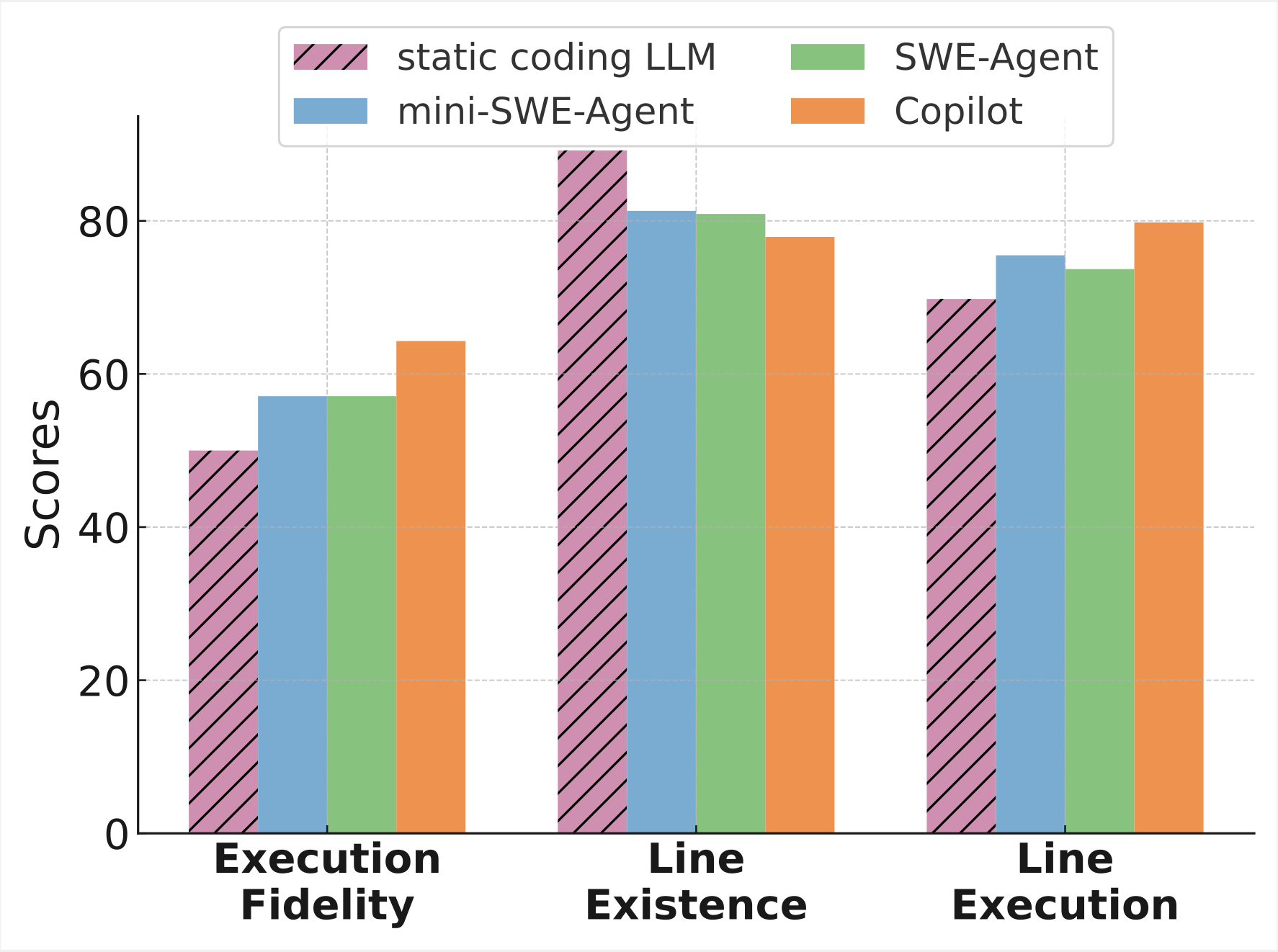
- Agentic > Static: iterative read-think-act workflows consistently outperform one-shot/static generation.
- Static models can still score well on Line Existence: when given the gold relevant code, since the task reduces to reorganizing known snippets rather than discovering them.
What’s next?
🚀 Enhance Gistify performance: Explore richer execution traces, smarter navigation tools, and dynamic file-reading to improve runtime understanding.
🛠️ Leverage gistified files downstream: Apply gistified outputs to tasks such as debugging, code review, and feature extraction.
References
(1) Yang, John, et al. “Swe-agent: Agent-computer interfaces enable automated software engineering.” Advances in Neural Information Processing Systems 37, 2024.
(2) Ouyang, Siru, et al. “Repograph: Enhancing ai software engineering with repository-level code graph” In Proceedings of ICLR 2025, 2025.