dstoolkit-maiva
MAIVA - Data Strategy Table of Contents
- People
- Process
- Platform
- What to Consider when Establishing or Modernizing a Data Strategy
- Data Acumen
- Data Governance and Operations
- Federated Compute
- Shared Services
- Data Sources
- Enterprise Services
- Data Product Mindset
- Operationalize
- Logical architecture for modern data platform
- Business Outcomes and Use Cases
Data Strategy
A robust data management and governance capability is crucial for leveraging AI technologies and gaining a competitive edge through an AI-driven transformation. This capability spans people, process, and platform (technology). Therefore, an organization’s data strategy should reflect this comprehensive approach. In the context of AI, an organization’s data strategy should:
- Focus on clearly identified high-impact business outcomes and AI use cases.
- Iteratively enhance data handling across people, process, and platform (the three P’s to success) with a systems-thinking approach, focusing on holistic and progressive improvement.
- Keep in mind that AI transformation with a data-driven operation is a long-term process that requires patience, resilience, and sustained focus.
Data strategy is essential to successfully industrialize AI, bringing together People, Process and Platform to harness data’s full potential for innovation and growth, not as a byproduct of, but instead, the driving force for innovation and growth.
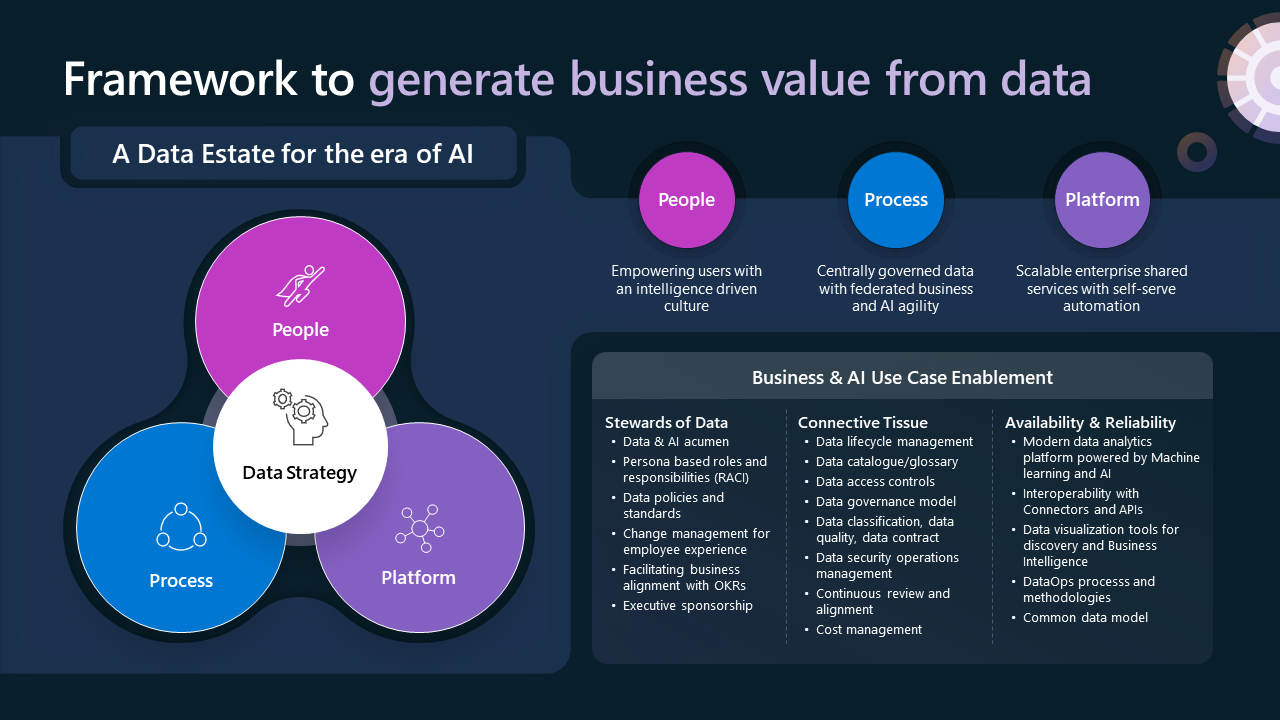
People
The People pillar of Data Strategy aims to create an environment where data and AI are not just tools but are central to the organization’s culture and a way of operating. It’s about creating a culture that values data, embraces AI, and prioritizes continuous learning and adaptation. An intelligence-driven culture leverages data and AI as core to operations, prizes data as a valuable resource, promotes making it widely accessible across the organization and actively utilizing it to inform decisions. It also promotes integration of AI technologies into various workflows, using AI to automate repetitive tasks, enhance human capabilities, and generate actionable insights.
An intelligence-driven culture is characterized by its emphasis on a data-centric approach. This approach prioritizes data collection, analysis, and utilization in decision and action taking. It ensures that data is not just considered valuable but is also made readily available to all levels within the organization. This availability of data is crucial to making informed decisions. By ingraining data-driven insights into decision-making processes, an organization can foster a culture that is truly intelligence-driven.
AI integration is another key aspect of an intelligence-driven culture. In such a culture, AI technologies are not standalone tools but are integrated seamlessly into various aspects of the organization’s operations. AI is used to automate tasks, augment human capabilities, and generate valuable insights. Through this approach, organizations can leverage AI to gain a competitive advantage, improve performance, and foster growth.
Another critical aspect of an intelligence-driven culture is its focus on continuous learning and adaptation. Such a culture encourages experimentation, learning from failures, and iterative improvement based on data-driven feedback. An intelligence-driven culture understands that transformation is not a one-time event but an ongoing journey. By fostering a culture of continuous learning, organizations can become more resilient and adaptable, thriving in an environment that is increasingly data-driven and intelligence-centric.
Process
The Process pillar of Data Strategy should focus on the objective of centrally governing data but with federated aspects for business and AI agility. The design should aim to remove bottlenecks with data lifecycle management and enabling appropriate data access. Several critical processes need to be considered in this context, these include data lifecycle management, which oversees data from collection to disposal; data lineage, ensuring traceability and transparency; data classification, data quality, and data product ownership - to maintain data integrity and reliability; Data Security Operations management, protecting data from threats; continuous review and alignment, ensuring data strategies remain relevant and aligned with business goals; and cost management, tracking and managing the costs associated with data. Collectively, these processes support the creation of an intelligence-driven culture where data and AI are integral to the organization’s operational fabric, driving business outcomes.
Platform
The Platform pillar of a successful Data Strategy should prioritize scalability and the provisioning of shared enterprise services that support self-service automation. This requires a robust technology solution that integrates a data analytics platform with Machine Learning and AI. A fundamental quality of this pillar is flexibility, particularly in terms of interoperability with various data sources and connectors. This allows for easy integration with a wide array of data systems, both common and bespoke. It’s essential that the platform enables data visualization, discovery, and business intelligence, and is compatible with DevOps and associated automation processes. The platform should scale with the growth of the organization and workloads, managing increasing data volumes and complexity without compromising performance, functionality, or security. The platform should enable a federated data product approach to mitigate challenges around resourcing and team capacity.
What to Consider when Establishing or Modernizing a Data Strategy
This section will explore the main elements of a data strategy as they manifest within each of the three essential pillars: People, Process, and Platform. The goal is to provide some insights on how to develop organizational capacity with Data and AI. These elements are data acumen, data governance and operations, federated compute, shared services, data sources and enterprise services.
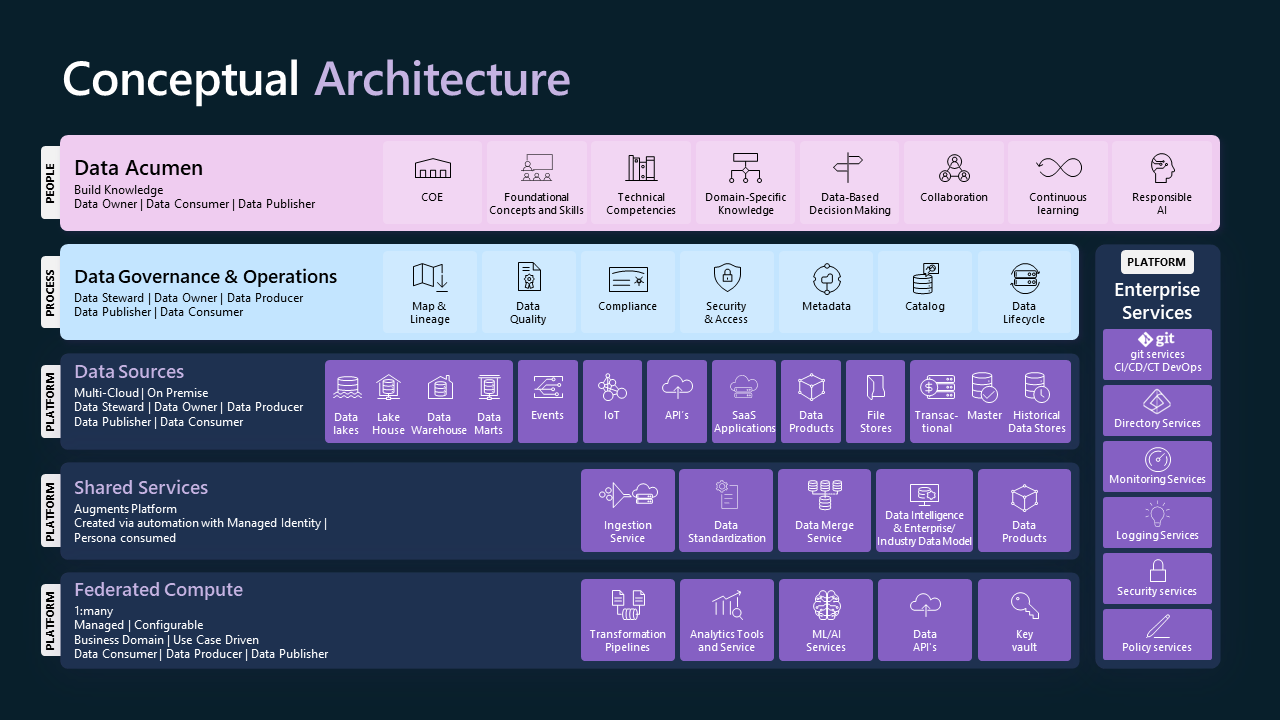
Data Acumen
Data acumen is a crucial skill set for any organization aspiring to leverage Artificial Intelligence for business growth and innovation. It is the collective proficiency in understanding and applying data-related concepts and skills, spanning from foundational knowledge to domain-specific insights. Developing a robust data acumen within an organization involves multiple facets, each contributing to the overall capacity to harness data effectively. It’s not just about understanding the technical aspects of data management; it’s about how data can influence business decisions and drive organizational growth.
Building data acumen within an organization requires a strategic and comprehensive approach. Here are some key initiatives to build data acumen:
- To build Foundational Concepts and Skills ensure team members understand data terminology, structures, and formats. Teach them fundamental statistical concepts and ethical considerations related to data and AI usage.
- Advanced Technical Competencies to equip teams with the tools and skills they need to manipulate and visualize data effectively. This may involve technical training for data extraction, transformation, and loading (ETL) as well as for creating meaningful data visualizations. Familiarize them with cloud platforms for data storage, processing, and analytics.
- Foster Domain-Specific Knowledge for your industry, the business processes, and the role data plays in decision making.
- Promote a culture that values Data-Based Decision Making. Teach team members how to formulate hypotheses, design experiments, and analyse results.
- Encourage cross-functional communication and collaboration to break down silos and ensure that data insights are shared and acted upon across the organization.
- Foster Continuous Learning and curiosity about emerging technologies, tools, and best practices.
- As AI becomes more prevalent, it’s important to understand its ethical implications. Embed Responsible AI, considering factors like fairness, transparency, and bias.
Data Governance and Operations
Data governance and operations play a pivotal role in managing the availability, usability, integrity, and security of the data used in an organization. This comprises of establishing standards, policies, and processes to ensure data is managed in a consistent, secure, and compliant manner. the “data product” is a trusted, reusable data asset, registered and catalogued. A Data Product mindset involves defining clear roles such as data product owners (Data Publishers), data owning teams (Data Producers), and data consumers. By treating data as a product, businesses can focus on high-impact business use cases, package data for easy comprehension and usage, reduce compliance and user access risks, control data sprawl and costs, and maintain trust with stakeholders. To build a strong data governance and operations capability, the following key areas need to be addressed:
- Data mapping tools offer a visual representation of the data landscape, showing the flow from source to target systems. Lineage tools track data from its origin through transformations, helping identify dependencies and impacts of changes in the data structure.
- Tools to ensure Data Quality: accuracy, completeness, and consistency of data are crucial. These provide capabilities like data profiling, cleansing, validation, matching, and monitoring.
- Compliance tools to ensure alignment with legal, contractual, and business rules automate the process of compliance checking and reporting.
- Tools enforcing access and security controls, ensuring data privacy, and protection against data breaches are integral. These may include encryption tools, intrusion detection systems, and identity and access management solutions.
- Tools to collect, organize, and display data about data (metadata) help make data more understandable and usable.
- A searchable repository (Data Catalog) of data products makes it easier to find and understand data. These tools typically provide metadata, usage information, and data samples.
- Tools to manage the flow of data through its lifecycle (Data Lifecycle (DLM)), from creation and initial storage to obsolescence and deletion. These tools provide capabilities like data classification, retention, archiving, and deletion.
Federated Compute
Federated Compute is a computational capacity that enables data distribution and processing across various systems or locations while retaining centralized control. It achieves this by bringing computation to the data, a significant shift from the traditional model of moving data to computation. This method proves advantageous in big data applications, such as Machine Learning and Analytics, where data transfer can be expensive and time-consuming. Data APIs facilitate this process, serving as connectors between various data sources and computing nodes, thus enabling efficient access, processing, and utilization of data across different systems and locations. Designing or modernising a data platform with federated compute involves several key considerations:
- With federated compute, data remains at its source, which can help in meeting data privacy regulations. However, it’s critical to ensure that any computations or transformations performed don’t inadvertently compromise data privacy. Security measures should be in place to protect the data during computation.
- Organization needs a robust and reliable network infrastructure to facilitate efficient data communication between different nodes in a federated computing setup. Any network latency or downtime can significantly impact the performance of transformation pipelines, analytical tools, and ML/AI services.
- A well-defined data governance policy is essential to manage data access, usage, and quality. This is especially important in a federated environment where data is distributed across multiple locations.
- The system should be designed to handle growth in data volume, velocity, and variety.
- The components of the federated compute system should be interoperable, meaning they can work together seamlessly. This includes transformation pipelines, analytical tools, and ML/AI services, which need to be able to access and process data from various sources.
- The organization needs to possess or develop the necessary skillsets to implement and manage federated compute environments. This includes understanding of distributed computing, data privacy and security, and the specific tools and platforms being used.
- The selection of tools and platforms for transformation pipelines, analytical services, and ML/AI services is important. These tools should support federated computing, be scalable, and be easy to integrate with existing systems.
- The performance of the Federated Compute system should be monitored and optimized regularly.
Shared Services
Shared Services are key data estate services that are managed centrally and assist with creating, launching, and administering applications and data in a data platform setting. They help organizations simplify data management processes, eliminate duplication, and make data use more efficient and effective by providing common tasks and services, leveraging best practices and methods. The key Shared Services that should be considered when establishing or modernising a data platform are listed below:
- Self-Service Metadata-Driven Ingestion to enable automated, metadata-driven data ingestion, reducing the need for manual coding and simplifying the process of data ingestion for data engineers and other users.
- Data Standardization to ensure that data is converted into a common format, making it easier to leverage across the organization. This may involve operations like converting data to common units, standardizing number of decimal places etc.
- Data Merging to combine data from different sources into a single, unified view, providing a more complete and accurate picture of the data.
- Data Intelligence as a way of using AI and machine learning to enrich the data and provide insights.
- Enterprise data models to provide high-level representations of an organization’s data in 3nf, helping to facilitate data management tasks such as data integration, data governance, and data quality.
- Data Products to provide trusted, curated data assets that are built within the data platform, such as datasets, tables, reports, predictive models, and AI-powered applications. These data products will be cataloged for easy discovery and re-use.
Data Sources
Data Sources are the repositories of information that feed into the AI-driven data strategy. These repositories, whether they exist on-premises or in the cloud, provide diverse types of data ranging from transactional, historical, or master data, which can be harnessed for AI applications. They can be structured in various formats such as Data Lakes, Data Warehouses, Data Marts, Lake Houses or File Shares, each offering different data storage and processing capabilities. Data sources may also be exposed through REST API (often used for SaaS applications), or via message-oriented sources (such as Message Queues or Publish-Subscribe Systems) for near/real-time data streaming applications. Careful consideration of what data should be ingested into the datalake should be taken, landing only the data that will help solve the use case.
Enterprise Services
Enterprise Services are the operations and infrastructure within any organization aiming to leverage data for AI-based innovation and growth. These services include DevOps, a practice that combines development and operations to shorten the system development life cycle and provide continuous delivery with high software quality. CI/CD/CT, or Continuous Integration, Continuous Delivery, and Continuous Testing, which are practices designed to improve and expedite the software delivery process. Identity Services, which ensure secure and efficient user access management across the organization. Operational Monitoring and Logging, to oversee system performance, identify issues, and maintain a comprehensive record of system activities for troubleshooting and analysis. Security Services, to protect sensitive information and systems from cyber threats, ensuring data integrity and availability. Enterprise Services underpin not only the Data Platform, but also other technical platforms within an enterprise, they are fundamentally important for data-driven innovation.
Data Product Mindset
Adopting a data product mindset is key. Adopting a product mindset is important to the success of an enterprise data strategy because it helps accelerate the adoption and scale of AI. A data product is a trusted, reusable data asset that empowers users with an intelligence-driven culture.
It requires data product owners (Data Publishers) who are responsible for defining objectives and key results for the product. It requires data owning team(s), producers that execute on the plan with an agile approach and lastly data consumers who use these data products to create business value. By treating data as a product, businesses can focus their data initiatives on clearly identified high-impact business use cases, and organize, structure, and package data in a way that makes it easy to understand, analyse, and use. This helps to reduce clutter and compliance risk, promote data engineering reuse, control data sprawl and cost, and maintain trust with customers, partners, and employees.
One example of a data product is a customer analytics report that provides insights into customer behaviour and preferences. This data product would be a logical entity that draws relationships to data and other metadata, is made available for broad consumption, and is aligned to the domain of business functions and goals. It is optimized for readability, decoupled from the operational/transactional application, and adheres to central interoperability standards. A data product mindset is essential in building a strong foundation for data-driven decision making and innovation.
Operationalize
In this era of AI, companies need to change the way they operate and have systems thinking underpinning the culture. They need to have data and AI acumen and become stewards of the data. They need a data strategy to generate business value from their data. They need to make data & analytics a permanent discipline that sits in the business and, as is the case with their AI strategy, they need strong leadership with a clear mandate on how we will succeed. It’s not just about collecting data but having a plan to fully harness its potential. As we navigate this transformative era, remember that data is not just a resource, but a strategic imperative in the realm of AI. A clear data strategy that is centered on business use case enablement is crucial for companies to become data driven in this AI-driven world.
Logical architecture for modern data platform
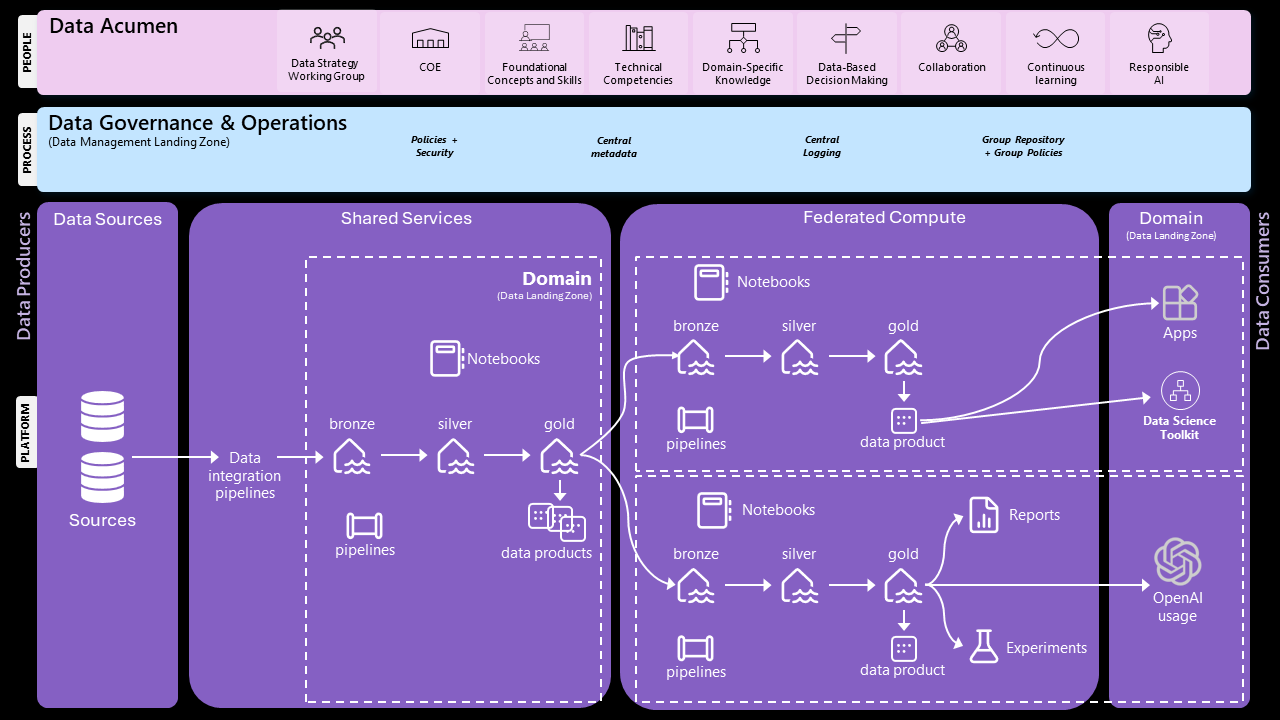
This architecture is designed to be federated, meaning that each Data Landing Zone operates semi-autonomously, yet under a common set of governance and operational principles. To ensure quality and reliability, each zone follows a medallion (bronze, silver, and gold) architecture, with each level signifying a higher degree of data maturity and trustworthiness. In this model, the Shared Services Data Landing Zone acts as the central hub for integration with primary data sources. In contrast, Domain Landing Zones consume data products from the Shared Services Zone and transform or enrich these products according to specific domain requirements. This approach allows each domain to produce its own derivative data products, including experiments, reports, models, and more. It’s important to note that the logical architecture described here is technology-agnostic. The aim is to provide a flexible framework that can be realized using a variety of technologies, depending on the unique needs and existing infrastructure of each organization.
Business Outcomes and Use Cases
Start with well-defined business problem and then identify the AI use cases that will solution the problem and measure their impact. Use Objectives and Key Results (OKRs) to define the vision, success factors, and stakeholders for each use case. Assess the current and desired data estate and identify the people, process, and platform capabilities needed to enable the use cases. This shows the gaps and opportunities to develop a roadmap for the capability plan that supports the company’s strategy. Use a data strategy framework to guide the data capabilities design. Focus on the use case-specific needs rather than generic solutions to avoid scope and cost mismatches. For example, address data quality issues within the use case context rather than broadly. Create a data strategy working group to coordinate data activities across the organization. This group should include experts, stakeholders, and representatives from relevant business units and teams who work together and have clear responsibilities and outcomes. Instead of a data Center of Excellence (COE), be a center of enablement. Learn from each use case and apply the lessons to the next one. Representatives from the MAIVA Governance Council should be present in this working group, at a minimum the Chief Data Scientist. Likewise, representatives from this group should be present on the MAIVA Governance Council to drive the development and execution of data-related activities and initiatives, being the champions for common programs which focus on shaping and implementing strategies related to data management, usage, and governance.
A data strategy needs to be a gradual and flexible journey that prioritizes outcomes over perfection, and aligns people, process and platforms to unleash the power of data for innovation and growth.
AI is a major transformation that depends on showing the business value of not only AI but also the data that powers it. To scale up AI, you need to build value from the data that drives it.