Bronze Layer
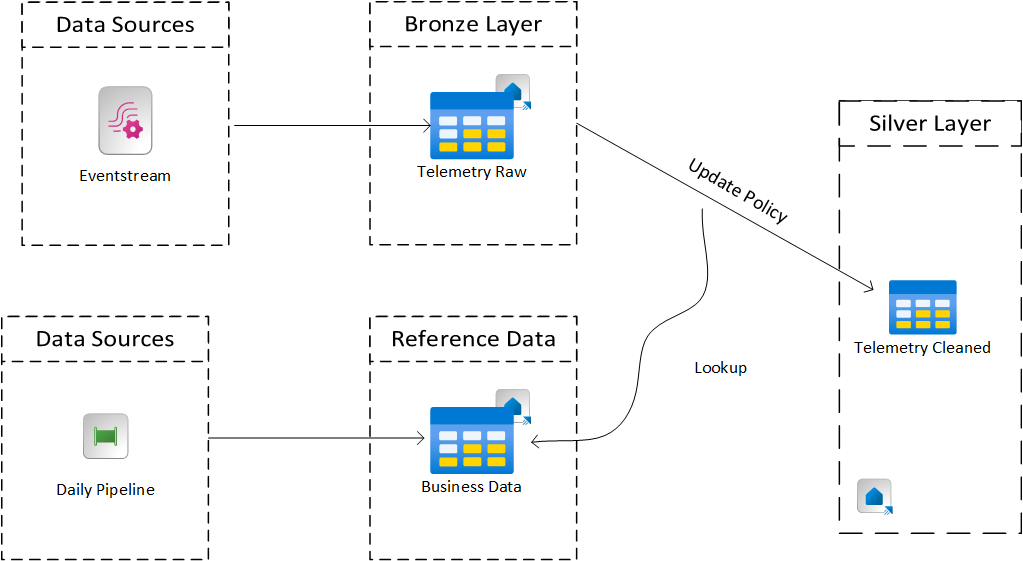
The bronze layer is where the rawest form of the telemetry lands. As shown in the architecture diagram this layer can either be Eventstream or a table in Eventhouse.
The decision is based on how you plan to do your transformation from the Bronze Layer to the Silver Layer
- Event Processor Transformation: if you plan to utilize the event processor built into Eventstream then your Bronze Layer will be Eventstream
- Eventhouse Update Policy: If you plan to utlize an update policy in Eventhouse then a KQL DB table will be your bronze layer.
Note that just because you utilize an update policy and thus an KQL DB table as your bronze layer doesn't mean Eventstream doesn't make sense in the architecture. For example:

Things to consider at Bronze Layer - Eventhouse
- Retention Settings: you can retain events in Eventstream up to 90 days
- Throughput Setting: Allows you to scale your Eventstream acccording to the expected incoming message rate. This can be configured betwen 1 MB/sec to 100 MB/sec.
Things to consider at the Bronze Layer - KQL DB Table
- Retention: Do you need to keep this data or is it just a landing table for your transformations. Utilize a retention policy in Eventhouse to set how long data is kept accordingly
- Update Policy: Will your update policy reference another table?
- There are two modes of ingestion for an KQL DB Table: Streaming Ingestion or Batch Ingestion.
- Streaming ingestion allows you to do transformations (flattening json, normalizing data, etc..) but does not let you reference additional table
- Batch ingestion allows you to do both and the rate of ingestion is controlled by the Ingestion Batchin Policy
- If you need to reference additonal tables in the update policy then disable streaming ingestion on the bronze table and configure the ingestion batching policy according to your latency needs.
- Are you going to enhance the data?
- Many scenarios you have reference data that complements the telemetry data. In you update policy you can connect to this reference data so it is pre-joined making the query more effecient. In order to do this you need to also bring that data into a table via some sorta batch process. For instance: