Free Up Your Context Window: Pass MCP Resources, Not Raw Data
How to avoid context window saturation in Copilot Studio by passing MCP resources between tools when the tool output is too huge to fit into an agent context window.

Note: This article assumes some familiarity with MCP resources. If you’re new to the concept, check out the general tutorial: MCP Tools & Resources.
One pretty common error encountered when dealing with tools producing in output a huge amount of data is the Token Limit Error, for example:
- A connector or a MCP tool returns a massive unfiltered payload
- The orchestrator faithfully feeds it into the LLM
- The context window explodes → the agent becomes very slow or fails with a Token Limit error
Sometimes, such tool token-heavy tool is outputting a lot of unwanted data, but other times you would actually need that data later in the plan, so you can’t just throw it away.
In this article we’ll look at a pattern that fixes this at the root: use MCP resources and pass resource IDs between tools instead of passing the whole text or JSON into the context window.
We’ll use a simple MCP sample with two tools (random characters generato + character counter) to illustrate the pattern, and then project it onto a more realistic scenario.
TL;DR: For token-heavy outputs, let your MCP server keep the data. Your agent should pass lightweight resource IDs between tools and only pull data into the context window when absolutely necessary.
The problem: tools that flood the context window
Every time a Copilot Studio agent calls a tool (connector action, MCP tool, etc.), the orchestrator needs to decide what to send to the tool (inputs), and it gets some tool-defined outputs that are fed in the LLM’s context for further reasoning.
If a tool returns small/medium data, no problem.
If a tool returns things like:
- A huge JSON with thousands of records
- A long text (logs, transcripts, documents, concatenated content)
…you will quickly hit the context window limit.
Result:
- Best case: the agent becomes slower and less smart in decision making due to a bloated context.
- Worst case: you hit an “input too long / too many tokens” error and the run fails.
 A run failing when the generate character tool returns 30,000 characters and the agent tries to keep them in context.
A run failing when the generate character tool returns 30,000 characters and the agent tries to keep them in context.
Sometimes, Copilot Studio doesn’t need every byte of that payload for reasoning, but you still need it downstream, for reporting, notifications, or other tools.
So how do we keep the agent smart and fast without losing the data, if you can’t edit the API itself?
Option 1 (the usual way): filter at the connector boundary with C# custom code
Before we get to MCP resources (the real focus of this post), there’s an important alternative worth mentioning.
If the tool that’s producing too much data is a “normal” HTTP API, or a Power Platform connector, you can:
- Create a custom connector.
- Add a bit of C# code that is executed after the API calls.
- In C#, filter / reshape / trim the response before returning it to Copilot Studio.
Example:
- The upstream API returns a full user profile:
- Name, surname, date of birth, address, phone, preferences, metadata, etc.
- Your Copilot Studio agent only needs:
- Name, surname, date of birth
You can write a few lines of C# in the custom connector that:
- After having called the original API
- Extracts only the three required fields
- Returns a tiny/cleaned JSON to Copilot Studio
This way:
- You don’t touch the original microservice
- You drastically reduce the token footprint
- You avoid polluting or saturating the context window
This pattern is great when you control the connector layer and can safely throw away fields the agent will never need.
However, sometimes:
- You need to keep the full data around for later tools
- You’re working with MCP servers and want to stay in that ecosystem
That’s where MCP resources shine.
Option 2 (the new MCP way): use MCP resources instead of raw text
With MCP servers, you don’t have to push every byte of data into the model’s context if not needed.
You can:
- Generate and store large outputs as resources on the MCP server
- Pass around resource identifiers between tools
- Only read and pull the data into the context window when absolutely required
Conceptually:
- A “resource” is a named, addressable piece of content managed by the MCP server
- e.g., a file, a JSON blob, a string, a document
- Tools can:
- Produce resources (create/store them)
- Consume resources as inputs (by ID)
- The Copilot Studio orchestrator only sees:
- Small metadata + resource IDs (a handful of tokens), not the entire raw payload.
- If the orchestrator thinks it’s useful, it can send a read request to the MCP server and put the resource in its context. But not always, only if necessary.
This pattern changes the game for tool-to-tool orchestration:
- Tool A: creates or updates a resource and returns an ID
- Copilot Studio: keeps just the ID in the plan
- Tool B: receives the resource ID as input, loads the content on the MCP side, processes it, and returns only the final summary / aggregated result to the LLM
No massive JSON in the context window and no token-heavy strings slowing everything down.
The sample scenario: random characters generator and counter
Let’s use the sample MCP server from this repo:
Github.com: Microsoft/CopilotStudioSamples
It exposes two tools:
-
generate_text- Generates a random string with a configurable number of characters.
-
count_characters- Counts the number of characters of a given input.
The naive approach (no resources used)
If we ignore MCP resources and just pass the text between the two tools:
- The agent calls
generate_text. - The tool returns a string of 100,000 characters.
- The orchestrator feeds those 100,000 characters into the LLM’s context.
- The agent calls
count_characters, passing the entire string as input. - The second tool counts the characters and returns a number.
In theory it could work. But in practice in case of heavy token inputs the context window is not sufficient to include the huge string, the run might become heavy, slow, and potentially fail. That’s exactly what you see in the failing screenshot above.
The resource-based approach
Now let’s do it the “MCP-native” way and use resources.
-
generate_textcreates a resource with the random string (server-side). - The tool returns a resource ID, not the raw string.
- e.g.,
resourceId: "random-string-12345"
- e.g.,
- Since the orchestrator knows there would be no advantage in reading the resource, it doesn’t send the read request. The agent only needs to count the characters, and instead of passing the full string, it passes the resource ID to
count_characters. -
count_characters:- Uses the resource ID to fetch the content from the MCP server
- Counts the characters server-side
- Returns just the count (a small integer) to Copilot Studio
From Copilot Studio’s point of view:
- The LLM never sees the 100,000 characters
- It only sees the ID and the final count
- The context window remains clean and small
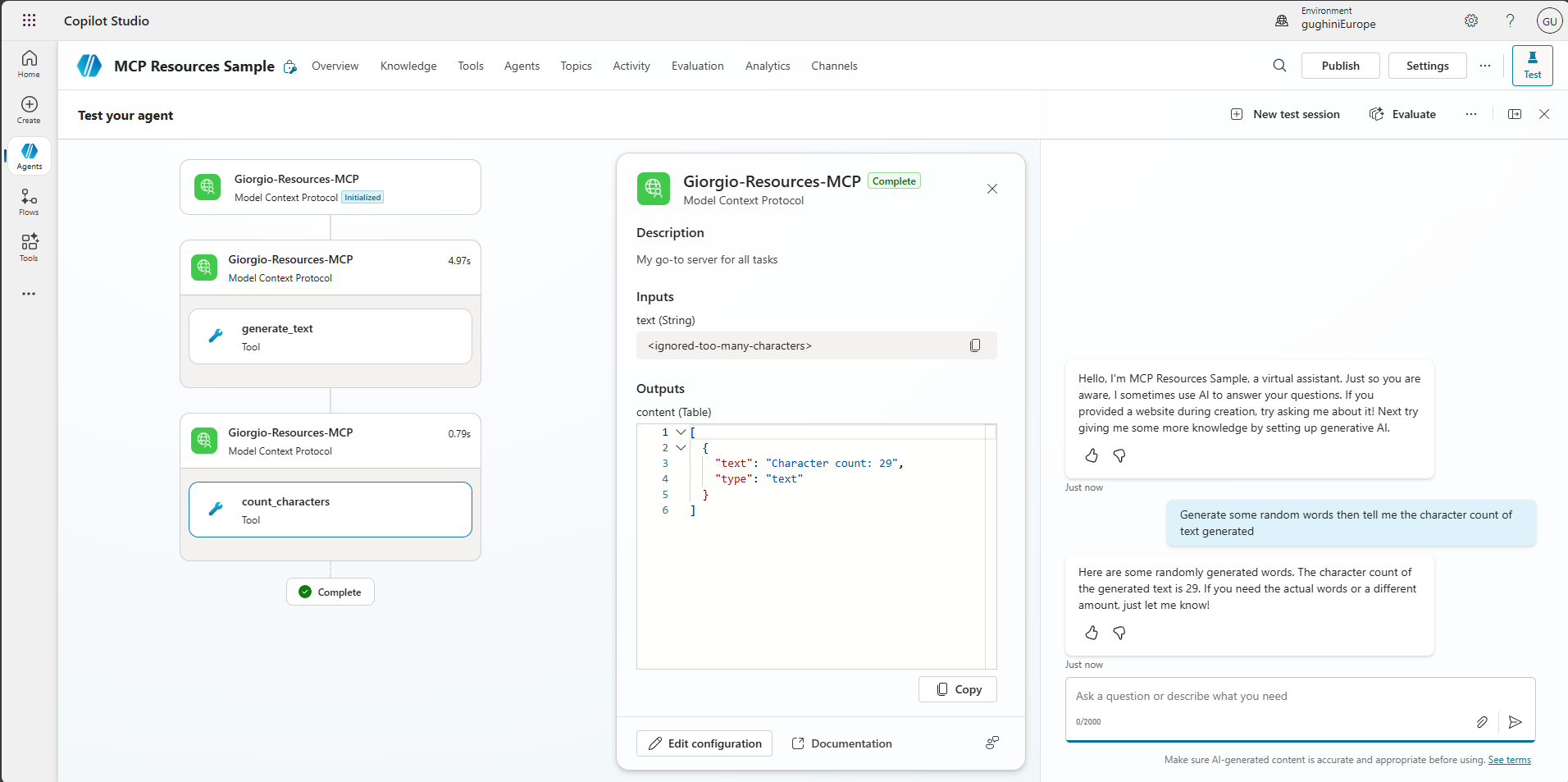
 A run where the agent calls the same tools, but uses MCP resources. The context stays tiny and the plan completes successfully.
A run where the agent calls the same tools, but uses MCP resources. The context stays tiny and the plan completes successfully.
The orchestrator can still decide to call
resource/readon that ID if it genuinely needs to reason over the full content. The key is: it doesn’t have to, and by default, it shouldn’t for purely mechanical tasks like counting.
How this looks in Copilot Studio
Assuming you’ve deployed the sample MCP server from the GitHub repo:
- In Copilot Studio, go to your agent and open the Tools / MCP section.
- Add the MCP server from the sample.
- Make sure both tools are enabled:
generate_textcount_characters
Now when you test:
- Prompt:
Generate a random string of 100,000 characters and then tell me how many characters it has.
Behind the scenes:
- The large string lives entirely on the MCP server
- Your Copilot Studio agent passes just one short ID between tools
- The LLM only sees small, structured inputs and outputs
A more realistic example: training completion for 200,000 employees
The character-count example is intentionally simple. Let’s apply the same pattern to something closer to a real-world scenario.
Imagine a nightly autonomous agent that:
- Calls a training system MCP tool to retrieve the training completion status for 200,000 employees.
- The tool returns a huge JSON: list of employees + courses completed / not completed.
- The agents passes that data into a report generation tool.
- Calls another tool to send reminders to people who are not compliant.
Naive approach:
- The first tool returns a massive JSON
- The agent tries to keep it in the context window to “think” about it
- You immediately hit context limits, or at least degrade performance heavily
Resource-based approach:
- The “get training status” tool writes the full JSON to a resource:
resourceId: "training-status-2025-11-25"
- The tool returns only that ID and maybe some small metadata (e.g., counts).
- The reporting tool receives the resource ID, loads the JSON from the MCP server, generates a compact summary or aggregated report, and returns just that summary to Copilot Studio.
- The reminder tool receives the another resource ID, maybe filtered by uncompliancy, loads the JSON server-side, identifies who needs reminders, and sends them—again returning only a small result object.
In the latter flow:
- Copilot Studio never sees the full 200,000-record JSON
- The MCP server does all the heavy lifting
- The LLM works with small, meaningful artifacts (summaries, counts, statuses) instead of raw bulk data
This is anoter scenario where MCP resources shine: you need to keep large data around and feed it through several tools, but the LLM doesn’t need to “read” every record.
When can you pass resources between tools?
This pattern works under a few conditions:
- The tools are part of the same MCP server and:
- The first tool can create or reference a resource
- The second (and subsequent) tools accept resource IDs as inputs and are configured to read it
- Or, otherwise, if you are using that resource in another agent, it should:
- Have access to the same MCP server
- Know how to consume that resource ID
In other words:
You’re not “teleporting” raw data between completely independent systems.
You’re passing handles (resource IDs) to a shared MCP backend that can resolve them.
Implementation details may vary by MCP server, but the idea is consistent:
- Define a convention for resource IDs
- Make sure your tool schemas expose inputs like “resourceId” (string) or match the MCP resource type
- In Copilot Studio, steer the orchestrator with instructions so it passes resource IDs instead of inlining content
Design guidelines and best practices
A few practical tips when applying this pattern:
Whenever you’re tempted to pass a big JSON or string between tools, ask:
“Is this too heavy? Can this be a resource instead?”- Minimize what enters the context window
- Only pull resources into the LLM when you truly need the model to reason over them (e.g., summarizing or analyzing content).
- For mechanical operations (counting, filtering, sending, moving), keep everything on the MCP side.
- Combine with connector-level filtering
- If you’re consuming APIs via Power Platform connectors, you can still use custom connectors + C# to pre-trim data.
- Then, for what remains large, use MCP resources to avoid flooding the LLM.
- Use clear agent instructions
- Explicitly tell the agent to pass resource IDs between specific tools.
- Add guardrails like:
Do not expand or print the full contents of large resources unless the user explicitly asks for it.
- Monitor and iterate
- Look at traces:
- Are you seeing huge tool outputs injected into the context?
- Can those be converted to resource-based flows instead?
- Look at traces:
Try it yourself with the sample MCP server
To see this pattern live:
- Clone the sample:
Github.com: Microsoft/CopilotStudioSamples - Deploy the MCP server as described in the repo.
- Connect it to your Copilot Studio agent.
- Run your tests
You’ll see immediately how much healthier your runs are when the heavy data stays on the MCP side.
Key takeaways
- Big tool outputs can silently kill your Copilot Studio agents by saturating the context window.
- A first mitigation could be to use custom connectors with C# to filter API responses before they ever reach the LLM.
- For MCP servers, or for situations in which you don’t want to filter since all the datas are used in subsequet tools, the better long-term pattern is to use resources:
- Tools write large outputs as resources
- Agents pass around resource IDs
- Other tools read and process those resources server-side
- This pattern scales from toy examples (like the 100,000 random characters used in this post) to serious workloads.
If you’re building serious agents with heavy data flows, resource-based orchestration might be an option for reliability and performance.
For more background on MCP resources in Copilot Studio, see the general tutorial here.