Results
This page presents performance benchmarks for collective communication algorithms implemented using the MSCCL++ DSL (Domain Specific Language).
Available Algorithms
The following reference implementations are provided:
Single-Node AllReduce on H100 (NVLS)
We evaluate a single-node AllReduce algorithm designed for NVIDIA H100 GPUs leveraging NVLink Switch (NVLS) technology. This algorithm demonstrates optimal performance for intra-node collective operations.
Source Code Location:
The algorithm implementation can be found at:
mscclpp/python/mscclpp/language/tests
Running the Benchmark:
Users can generate the corresponding JSON execution plan by following the steps described in the Quick Start section. Once the JSON file is generated, it can be executed using the executor_test.py tool to measure performance.
Performance Results:
The following figures show the achieved bandwidth for message sizes ranging from 1KB to 1GB:
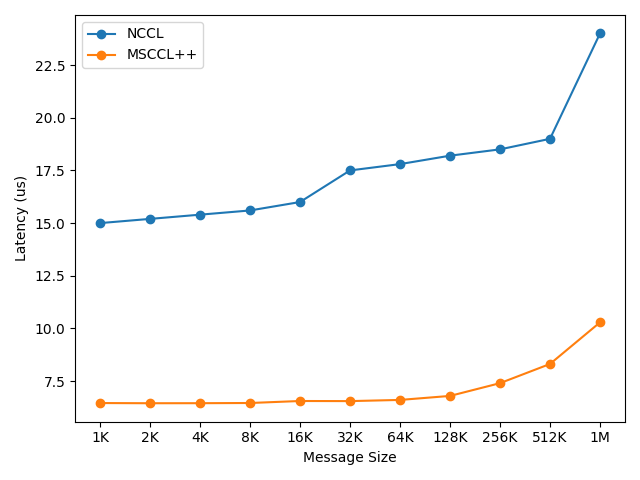
Single-node AllReduce performance on H100 with NVLS (1KB to 1MB message sizes)
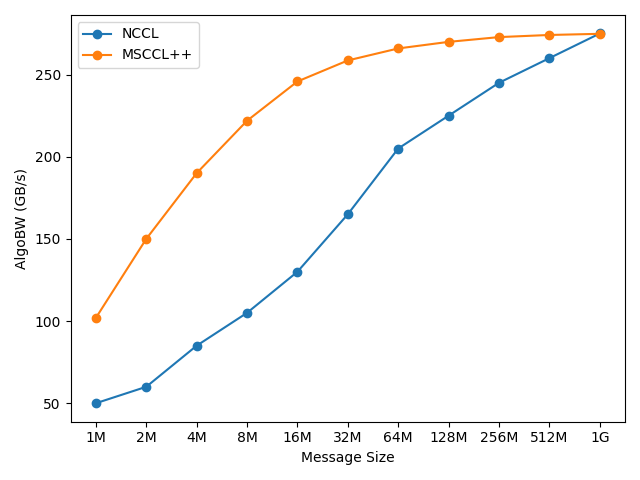
Single-node AllReduce performance on H100 with NVLS (1MB to 1GB message sizes)
Two-Node AllReduce on H100 (Small Message Sizes)
We also provide a two-node AllReduce algorithm for H100 GPUs, specifically optimized for small message sizes. This algorithm uses a non-zero-copy communication path to minimize latency for small data transfers.
Installation:
This algorithm is installed by default when running:
python3 -m mscclpp --install
Execution Plan Location:
After installation, the generated JSON execution plan can be found at:
~/.cache/mscclpp/default/
If MSCCLPP_CACHE_DIR is set, bundled default plans are installed under MSCCLPP_CACHE_DIR/default/.
MSCCLPP_CACHE_DIR specifies the cache root directory, so it should be set without default in the path.
Performance Results:
The figure below shows the performance characteristics for small message sizes in a two-node configuration:
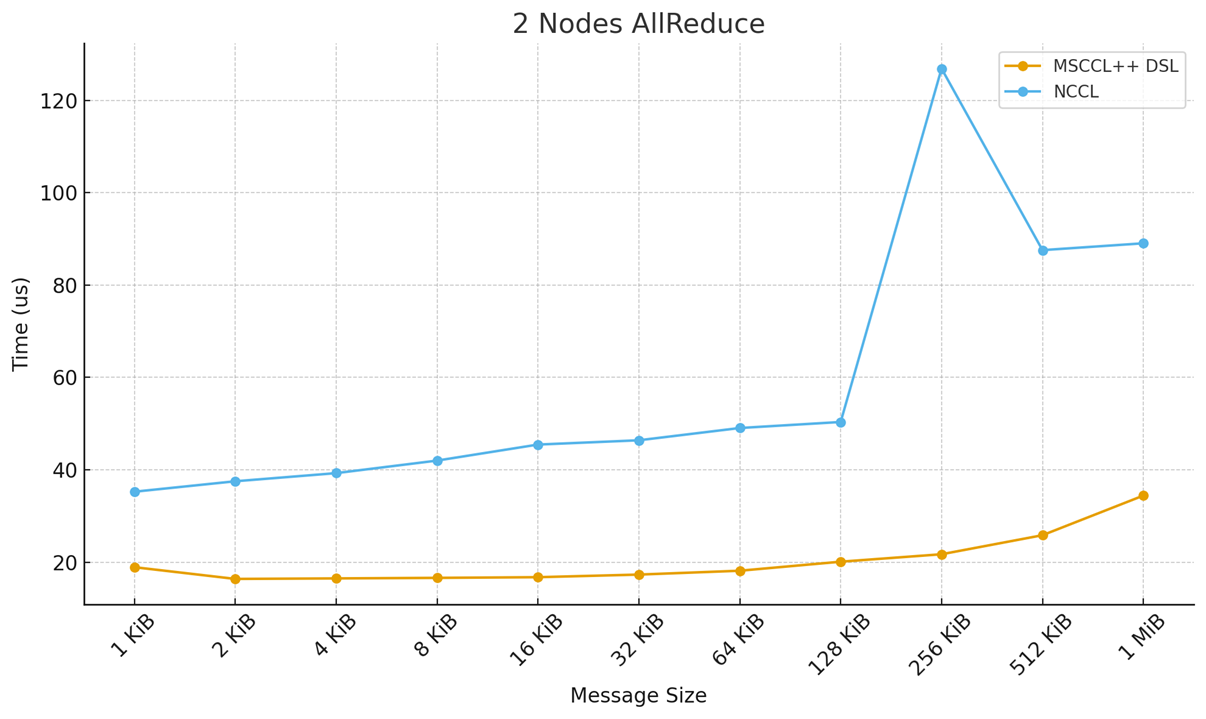
Two-node AllReduce performance on H100 for small message sizes