PPT-Eval
A Benchmark for Computer-Use Agents on PowerPoint Tasks
* Equal contribution
1Carnegie Mellon University 2Microsoft 3UMass Amherst 4Work done at Microsoft internship 5Work done at Microsoft; now at Google 6Work done at Microsoft; now at Snowflake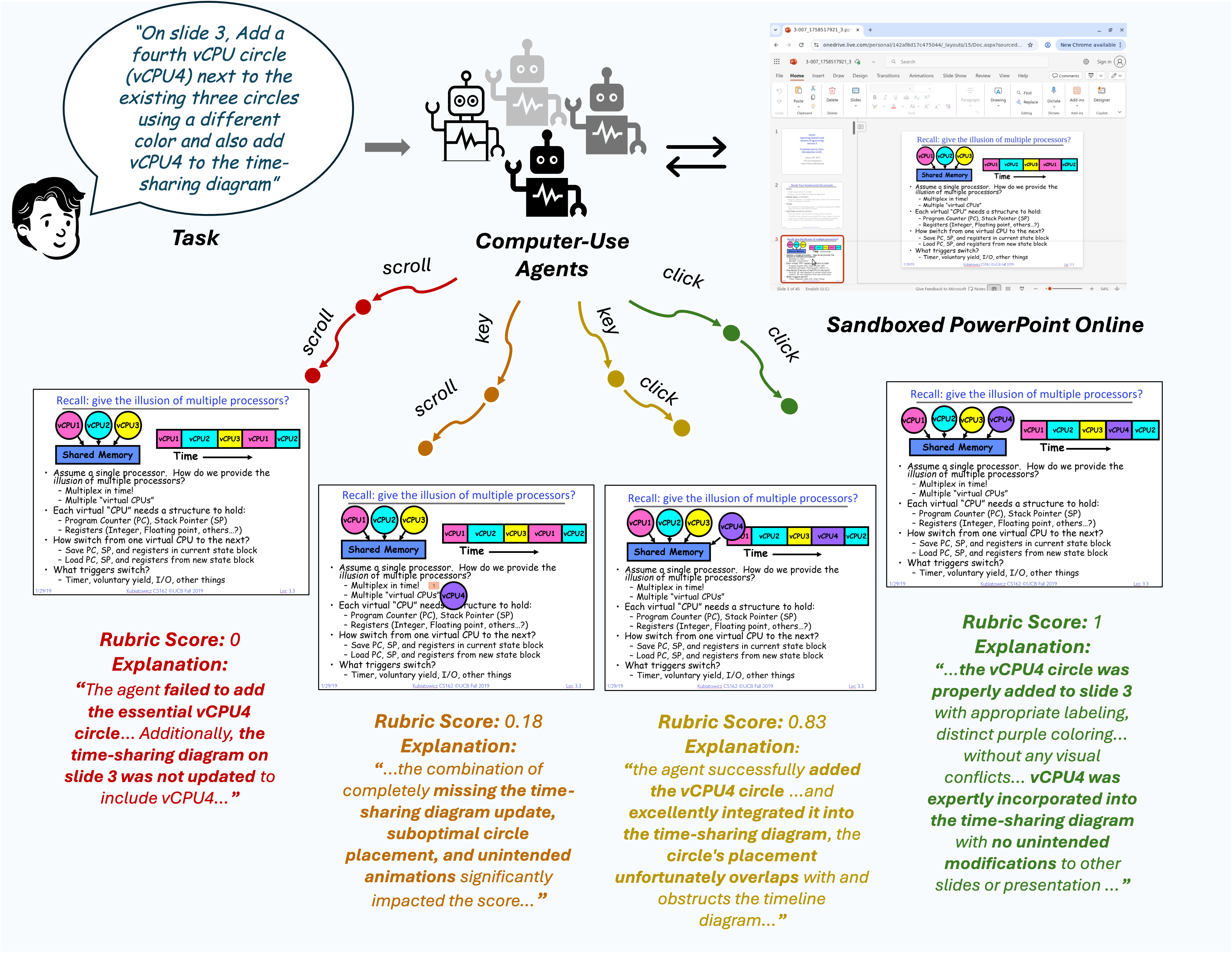
Abstract
Creating and editing slides is a rich, multimodal activity that is ubiquitous in professional and educational settings, making it an ideal testbed for real-world computer-use agents. Microsoft PowerPoint is among the most widely adopted and feature-rich environments for presentation creation. We introduce PPT-Eval, a benchmark of 120 PowerPoint tasks across 12 files that cover both content creation and presentation editing scenarios, organized by difficulty.
A central challenge in this domain is evaluation: tasks are complex, multimodal, and often admit many valid solutions. Moreover, today’s agents frequently make only partial progress, which binary success metrics fail to capture. To address this, we design a robust evaluation framework to help create task-specific rubrics for PowerPoint tasks. These rubrics award partial credit for intermediate steps, penalize unnecessary changes and poor aesthetics, and provide natural language feedback.
This nuanced approach proves highly effective, achieving a Kendall’s τb correlation of 0.77 with human judgments. We find that existing frontier agents still struggle with solving PowerPoint tasks, with strong models like Claude-4.5-Opus achieving only a 45% success rate and an average partial score of 57%.
Citation
@inproceedings{ppteval2026,
title = {PPT-Eval: A Benchmark for Computer-Use Agents on PowerPoint Tasks},
author = {Gandhi, Apurva and Suryanarayanan, Vishwas and Anwar, Raja Hasnain and Shaik, Firoz and Desai, Shubhang and Nguyen, Thong Q. and Raza, Muhammad Taqi and Chowdhary, Vishal and Neubig, Graham},
booktitle = {Forty-third International Conference on Machine Learning},
year = {2026}
}