RenderFormer
Transformer-based Neural Rendering of Triangle Meshes with Global Illumination

Introduction
We present RenderFormer, a neural rendering pipeline that directly renders an image from a triangle-based representation of a scene with full global illumination effects and that does not require per-scene training or fine-tuning.
Mesh to Image, End to End
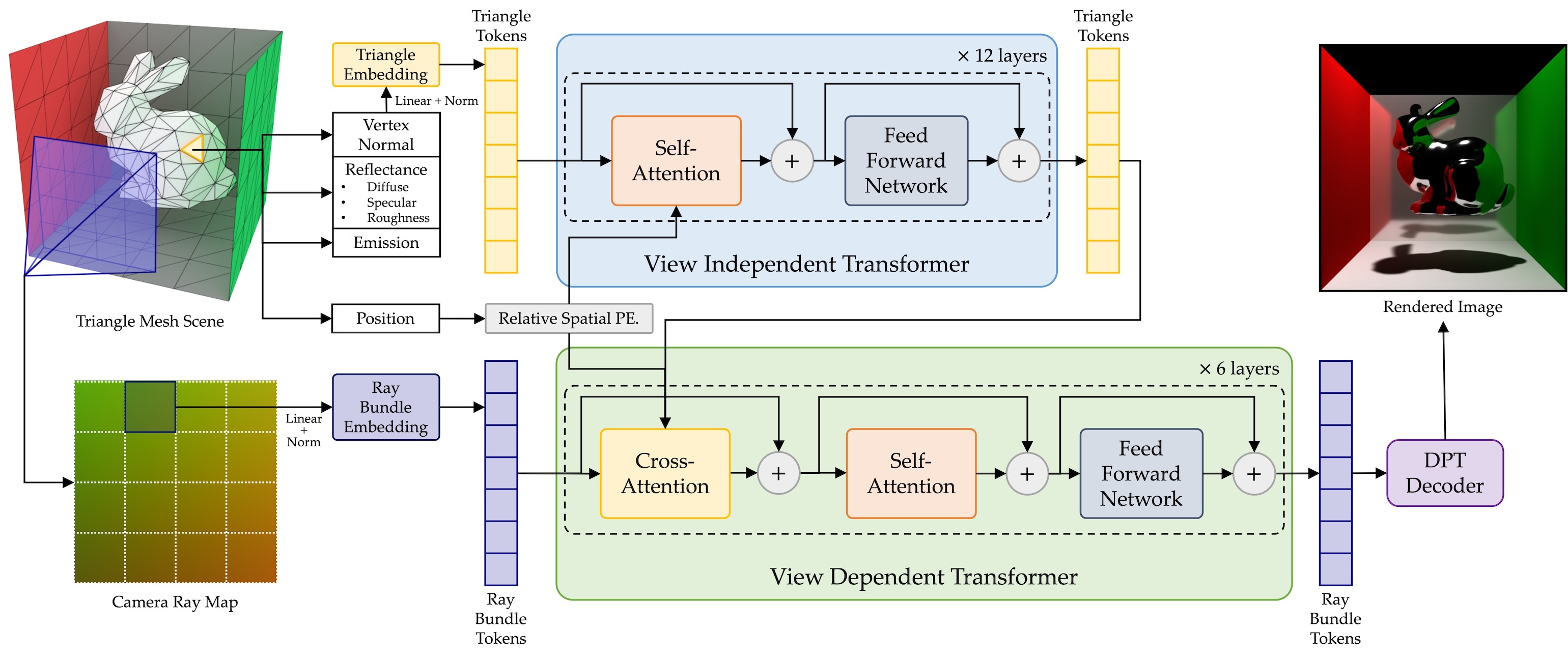
Instead of taking a physics-centric approach to rendering, we formulate rendering as a sequence-to-sequence transformation where a sequence of tokens representing triangles with reflectance properties is converted to a sequence of output tokens representing small patches of pixels.
Simple Transformer Architecture with Minimal Prior Constraints
RenderFormer follows a two stage pipeline: a view-independent stage that models triangle-to-triangle light transport, and a view-dependent stage that transforms a token representing a bundle of rays to the corresponding pixel values guided by the triangle-sequence from the the view-independent stage. Both stages are based on the transformer architecture and are learned with minimal prior constraints. No rasterization, no ray tracing.
Rendering Gallery
Examples of scenes rendered with RenderFormer demonstrating various lighting conditions, materials, and geometric complexity, without any per-scene training or fine-tuning. Check out the reference images for more details.













Videos
Check out extra video results including uncompressed videos and some reference videos.
Teaser Scenes
Dynamic demonstrations of RenderFormer's capabilities, showing object rotations, lighting changes, and material adjustments.
Animations
RenderFormer can render animations of scenes.
Physical-Based Simulations
RenderFormer can render physically simulated scenes with complex dynamics and interactions.
BibTeX
@inproceedings {zeng2025renderformer,
title = {RenderFormer: Transformer-based Neural Rendering of Triangle Meshes with Global Illumination},
author = {Chong Zeng and Yue Dong and Pieter Peers and Hongzhi Wu and Xin Tong},
booktitle = {ACM SIGGRAPH 2025 Conference Papers},
year = {2025}
}