robustlearn
DIVERSIFY: OUT-OF-DISTRIBUTION REPRESENTATION LEARNING FOR TIME SERIES CLASSIFICATION
This project implements our paper OUT-OF-DISTRIBUTION REPRESENTATION LEARNING FOR TIME SERIES CLASSIFICATION at ICLR 2023. Please refer to our paper [1] for the method and technical details. [Zhihu blog]
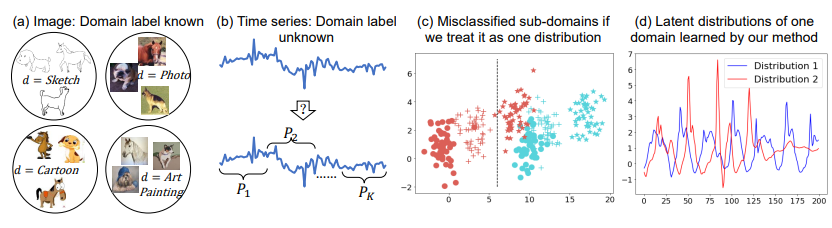
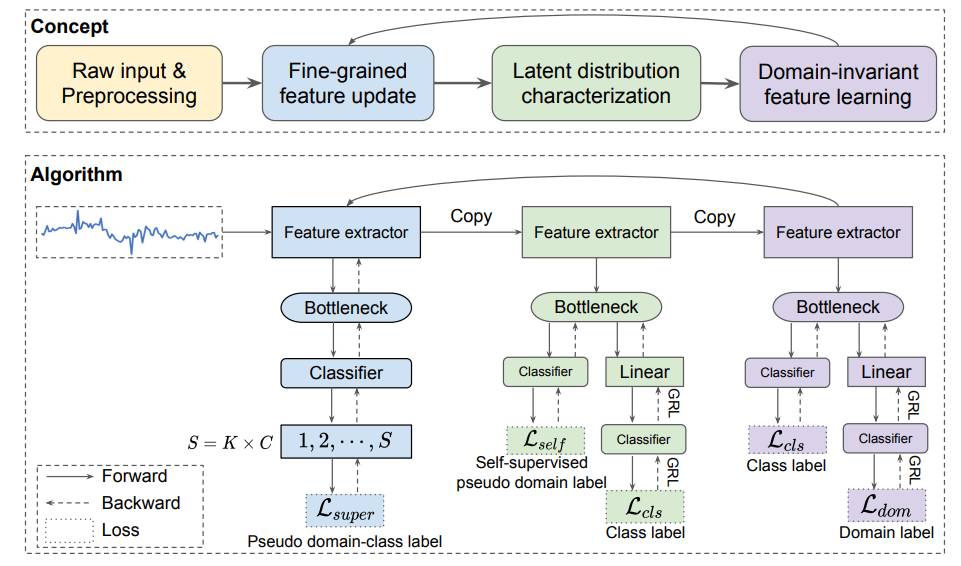
Abstract: Time series classification is an important problem in the real world. Due to its nonstationary property that the distribution changes over time, it remains challenging to build models for generalization to unseen distributions. In this paper, we propose to view time series classification from the distribution perspective. We argue that the temporal complexity of a time series dataset could attribute to unknown latent distributions that need characterize. To this end, we propose DIVERSIFY for out-of-distribution (OOD) representation learning on dynamic distributions of times series. DIVERSIFY takes an iterative process: it first obtains the ‘worst-case’ latent distribution scenario via adversarial training, then reduces the gap between these latent distributions. We then show that such an algorithm is theoretically supported. Extensive experiments are conducted on seven datasets with different OOD settings across gesture recognition, speech commands recognition, wearable stress and affect detection, and sensor-based human activity recognition. Qualitative and quantitative results demonstrate that DIVERSIFY significantly outperforms other baselines and effectively characterizes the latent distributions.
Requirement
The required packages are listed in requirements.txt for minimum requirement (Python 3.10.9):
pip install -r requirements.txt
If you want to create a new Conda environment, you can also run the following:
conda env create -f env.yml
Dataset
The original EMG dataset can be downloaded from EMG data for gestures Data Set. Electromyography (EMG) is a typical time-series data that is based on bioelectric signals. The dataset contains raw EMG data recorded by MYO Thalmic bracelet. The bracelet is equipped with eight sensors equally spaced around the forearm that simultaneously acquire myographic signals. Data of 36 subjects are collected while they performed series of static hand gestures and the number of instances is 40, 000 − 50, 000 recordings in each column. It contains 7 classes and we select 6 common classes for our experiments. We randomly divide 36 subjects into four domains (i.e., 0, 1, 2, 3) without overlapping and each domain contains data of 9 persons. The processed EMG dataset can be downloaded at dataset link:
wget https://wjdcloud.blob.core.windows.net/dataset/diversity_emg.zip
unzip diversity_emg.zip && mv emg data/
How to run
We provide the commands for four tasks in EMG to reproduce the results of Pytorch 1.13.1.
python train.py --data_dir ./data/ --task cross_people --test_envs 0 --dataset emg --algorithm diversify --latent_domain_num 10 --alpha1 1.0 --alpha 1.0 --lam 0.0 --local_epoch 3 --max_epoch 50 --lr 0.01 --output ./data/train_output/act/cross_people-emg-Diversify-0-10-1-1-0-3-50-0.01
python train.py --data_dir ./data/ --task cross_people --test_envs 1 --dataset emg --algorithm diversify --latent_domain_num 2 --alpha1 0.1 --alpha 10.0 --lam 0.0 --local_epoch 10 --max_epoch 15 --lr 0.01 --output ./data/train_output/act/cross_people-emg-Diversify-1-2-0.1-10-0-10-15-0.01
python train.py --data_dir ./data/ --task cross_people --test_envs 2 --dataset emg --algorithm diversify --latent_domain_num 20 --alpha1 0.5 --alpha 1.0 --lam 0.0 --local_epoch 1 --max_epoch 150 --lr 0.01 --output ./data/train_output/act/cross_people-emg-Diversify-2-20-0.5-1-0-1-150-0.01
python train.py --data_dir ./data/ --task cross_people --test_envs 3 --dataset emg --algorithm diversify --latent_domain_num 5 --alpha1 5.0 --alpha 0.1 --lam 0.0 --local_epoch 5 --max_epoch 30 --lr 0.01 --output ./data/train_output/act/cross_people-emg-Diversify-3-5-5-0.1-0-5-30-0.01
Results
EMG dataset
Please note that we report better results here compared to the results in the original paper. We choose the best models of the last round in the original paper while we choose the globally best models here.
Note: we open-sourced all the training logs on wandb.
| Target | 0 | 1 | 2 | 3 | AVG |
|---|---|---|---|---|---|
| ERM | 62.6 | 69.9 | 67.9 | 69.3 | 67.4 |
| DANN | 62.9 | 70.0 | 66.5 | 68.2 | 66.9 |
| CORAL | 66.4 | 74.6 | 71.4 | 74.2 | 71.7 |
| Mixup | 60.7 | 69.9 | 70.5 | 68.2 | 67.3 |
| GroupDRO | 67.6 | 77.4 | 73.7 | 72.5 | 72.8 |
| RSC | 70.1 | 74.6 | 72.4 | 71.9 | 72.2 |
| ANDMask | 66.5 | 69.1 | 71.4 | 68.9 | 69.0 |
| AdaRNN | 68.8 | 81.1 | 75.3 | 78.1 | 75.8 |
| DIVERSIFY (Table 1 in paper, Pytorch=1.7.1) | 71.7 | 82.4 | 76.9 | 77.3 | 77.1 |
| DIVERSIFY (This code, Pytorch=1.13.1) | 73.1 | 86.8 | 80.4 | 81.6 | 80.5 |
Statement: This work was completed in Sep. 2021 and then submitted to ICLR 2022. Yet it was rejected even if the scores are 866. So the main results in the paper are obtained using Pytorch 1.7.1. By the time of this year (2023), Pytorch 1.7.1 is too obsolete for most machines and may not be reproducible. So, we rerun the code using Pytorch 1.13.1 for better reproducibility. Thus, the results using different Pytorch versions may vary. To show our initial logs in the paper for integraty and reproducibility, interested readers can refer to this wandb to see our training logs. Note that the new results using Pytorch 1.13.1 are even better than those in the paper, haha. If you want to use Pytorch 1.7.1, you can refer to this docker.
Extensions
This algorithm is closely related to domain generalization and you can find more codes for domain generalization in this repo: [DeepDG].
Contact
- luwang@ict.ac.cn
- jindongwang@outlook.com
References
@inproceedings{lu2022out,
title={Out-of-distribution Representation Learning for Time Series Classification},
author={Lu, Wang and Wang, Jindong and Sun, Xinwei and Chen, Yiqiang and Xie, Xing},
booktitle={International Conference on Learning Representations},
year={2023}
}