Leaderboard
We showcase the key results on the leaderboard. If you'd like your results to appear, please email us at
AIOpsLab@microsoft.com.
In the table, AVERAGE represents the average accuracy across all tasks. TIME indicates the average runtime for the agents.
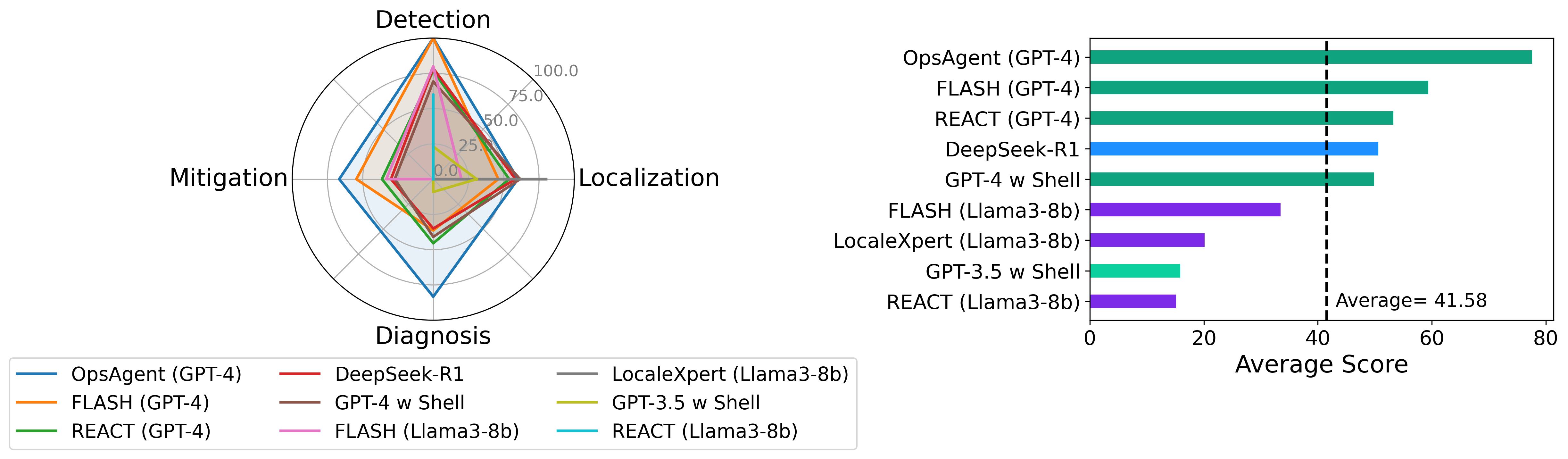
| Agent Name | Average | Detection | Localization | Diagnosis | Mitigation | Time | Organization | Link |
|---|---|---|---|---|---|---|---|---|
| OpsAgent (GPT-4) | 78.75 | 100 | 60 | 83.34 | 66.67 | 27.6 | AIOpsLab & NKU | 🔗 |
| FLASH (GPT-4) | 59.27 | 100 | 46.15 | 36.36 | 54.55 | 102.57 | AIOpsLab | 🔗 |
| REACT (GPT-4) | 53.15 | 76.92 | 53.85 | 45.45 | 36.36 | 44.25 | AIOpsLab | 🔗 |
| DeepSeek-R1 | 50.47 | 78.57 | 58.33 | 35 | 30 | 343.39 | THU | 🔗 |
| GPT-4 w Shell | 49.74 | 69.23 | 61.54 | 40.9 | 27.27 | 30.57 | AIOpsLab | 🔗 |
| FLASH (Llama3-8b) | 33.34 | 80 | 20 | 0 | 33.34 | 63.16 | THU | 🔗 |
| GPT-3.5 w Shell | 15.73 | 23.07 | 30.77 | 9.09 | 0 | 12.79 | AIOpsLab | 🔗 |
| REACT (Llama3-8b) | 15 | 60 | 0 | 0 | 0 | 230.74 | THU | 🔗 |
| LocaleXpert (Llama3-8b) | - | - | 80 | - | - | 102.08 | AIOpsLab & NKU | 🔗 |