
TL;DR:
- Just by tuning the inference parameters like model, number of responses, temperature etc. without changing any model weights or prompt, the baseline accuracy of untuned gpt-4 can be improved by 20% in high school math competition problems.
- For easy problems, the tuned gpt-3.5-turbo model vastly outperformed untuned gpt-4 in accuracy (e.g., 90% vs. 70%) and cost efficiency. For hard problems, the tuned gpt-4 is much more accurate (e.g., 35% vs. 20%) and less expensive than untuned gpt-4.
- FLAML can help with model selection, parameter tuning, and cost-saving in LLM applications.
Large language models (LLMs) are powerful tools that can generate natural language texts for various applications, such as chatbots, summarization, translation, and more. GPT-4 is currently the state of the art LLM in the world. Is model selection irrelevant? What about inference parameters?
In this blog post, we will explore how model and inference parameter matter in LLM applications, using a case study for MATH, a benchmark for evaluating LLMs on advanced mathematical problem solving. MATH consists of 12K math competition problems from AMC-10, AMC-12 and AIME. Each problem is accompanied by a step-by-step solution.
We will use the new subpackage flaml.autogen to automatically find the best model and inference parameter for LLMs on a given task and dataset given an inference budget, using a novel low-cost search & pruning strategy. FLAML currently supports all the LLMs from OpenAI, such as GPT-3.5 and GPT-4.
We will use FLAML to perform model selection and inference parameter tuning. Then we compare the performance and inference cost on solving algebra problems with the untuned gpt-4. We will also analyze how different difficulty levels affect the results.
Experiment Setup
We use FLAML to select between the following models with a target inference budget $0.02 per instance:
- gpt-3.5-turbo, a relatively cheap model that powers the popular ChatGPT app
- gpt-4, the state of the art LLM that costs more than 10 times of gpt-3.5-turbo
We adapt the models using 20 examples in the train set, using the problem statement as the input and generating the solution as the output. We use the following inference parameters:
- temperature: The parameter that controls the randomness of the output text. A higher temperature means more diversity but less coherence. We search for the optimal temperature in the range of [0, 1].
- top_p: The parameter that controls the probability mass of the output tokens. Only tokens with a cumulative probability less than or equal to top-p are considered. A lower top-p means more diversity but less coherence. We search for the optimal top-p in the range of [0, 1].
- max_tokens: The maximum number of tokens that can be generated for each output. We search for the optimal max length in the range of [50, 1000].
- n: The number of responses to generate. We search for the optimal n in the range of [1, 100].
- prompt: We use the template: "{problem} Solve the problem carefully. Simplify your answer as much as possible. Put the final answer in \boxed{{}}." where {problem} will be replaced by the math problem instance.
In this experiment, when n > 1, we find the answer with highest votes among all the responses and then select it as the final answer to compare with the ground truth. For example, if n = 5 and 3 of the responses contain a final answer 301 while 2 of the responses contain a final answer 159, we choose 301 as the final answer. This can help with resolving potential errors due to randomness. We use the average accuracy and average inference cost as the metric to evaluate the performance over a dataset. The inference cost of a particular instance is measured by the price per 1K tokens and the number of tokens consumed.
Experiment Results
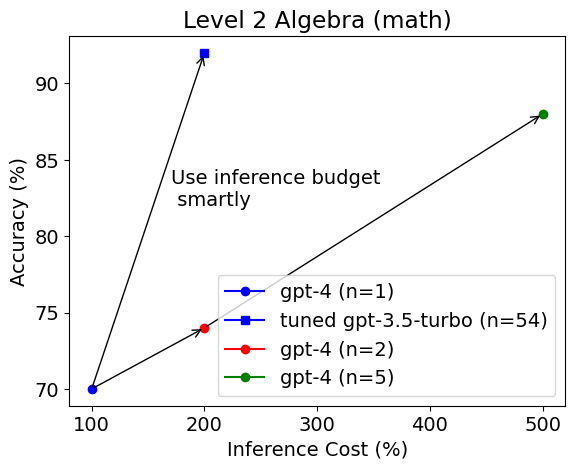
The first figure in this blog post shows the average accuracy and average inference cost of each configuration on the level 2 Algebra test set.
Surprisingly, the tuned gpt-3.5-turbo model is selected as a better model and it vastly outperforms untuned gpt-4 in accuracy (92% vs. 70%) with equal or 2.5 times higher inference budget. The same observation can be obtained on the level 3 Algebra test set.
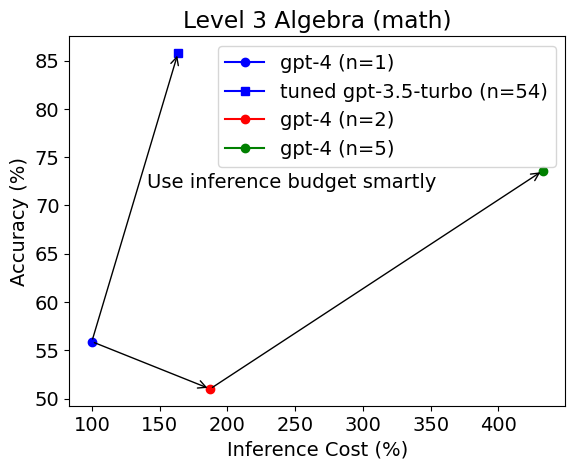
However, the selected model changes on level 4 Algebra.
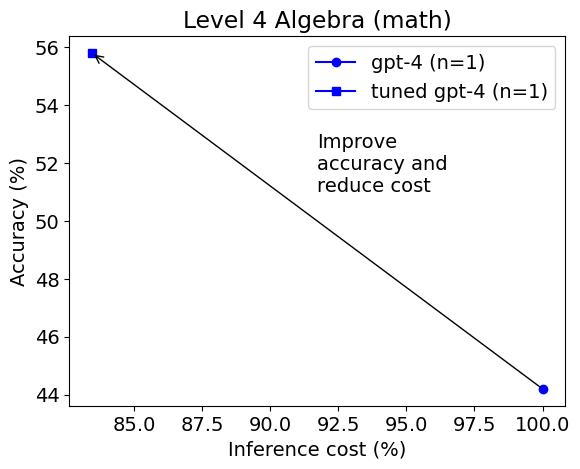
This time gpt-4 is selected as the best model. The tuned gpt-4 achieves much higher accuracy (56% vs. 44%) and lower cost than the untuned gpt-4. On level 5 the result is similar.
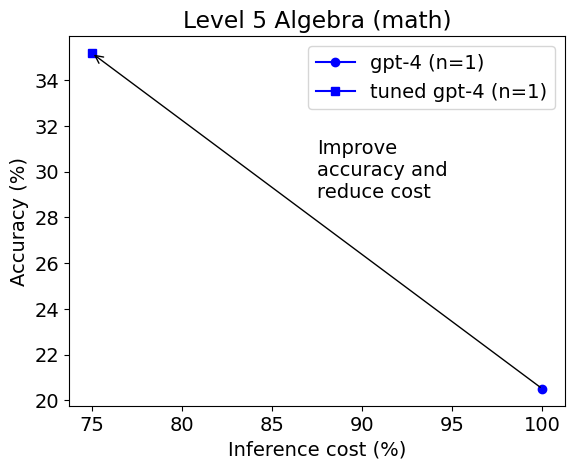
We can see that FLAML has found different optimal model and inference parameters for each subset of a particular level, which shows that these parameters matter in cost-sensitive LLM applications and need to be carefully tuned or adapted.
An example notebook to run these experiments can be found at: https://github.com/microsoft/FLAML/blob/v1.2.1/notebook/autogen_chatgpt.ipynb
Analysis and Discussion
While gpt-3.5-turbo demonstrates competitive accuracy with voted answers in relatively easy algebra problems under the same inference budget, gpt-4 is a better choice for the most difficult problems. In general, through parameter tuning and model selection, we can identify the opportunity to save the expensive model for more challenging tasks, and improve the overall effectiveness of a budget-constrained system.
There are many other alternative ways of solving math problems, which we have not covered in this blog post. When there are choices beyond the inference parameters, they can be generally tuned via flaml.tune.
The need for model selection, parameter tuning and cost saving is not specific to the math problems. The Auto-GPT project is an example where high cost can easily prevent a generic complex task to be accomplished as it needs many LLM inference calls.
For Further Reading
Do you have any experience to share about LLM applications? Do you like to see more support or research of LLM optimization or automation? Please join our Discord server for discussion.