How To use finetune Command#
The olive finetune command will finetune a PyTorch/Hugging Face model and output a Hugging Face PEFT adapter. If you want to convert the PEFT adapter into a format for the ONNX Runtime, you can execute the olive generate-adapter command after finetuning.
Quickstart#
The following example shows how to finetune Llama-3.2-1B-Instruct from Hugging Face either using your local computer (if you have a GPU device) or using remote compute via Azure AI integration with Olive.
Note
You’ll need a GPU device on your local machine to fine-tune a model.
olive finetune \
--model_name_or_path meta-llama/Llama-3.2-1B-Instruct \
--trust_remote_code \
--output_path models/llama/ft \
--data_name xxyyzzz/phrase_classification \
--text_template "<|start_header_id|>user<|end_header_id|>\n{phrase}<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n{tone}" \
--method lora \
--max_steps 100 \
--log_level 1
Find more details about how to configure data here.
Auto-Optimize the model and adapters#
If you would like your fine-tuned model to run on the ONNX Runtime, you’ll can execute the olive auto-opt command to produce an optimized ONNX model and adapter, using
olive auto-opt \
--model_name_or_path models/llama/ft/model \
--adapter_path models/llama/ft/adapter \
--device cpu \
--provider CPUExecutionProvider \
--use_ort_genai \
--output_path models/llama/onnx \
--log_level 1
Once the olive auto-opt command has successfully completed, you’ll have:
The base model in an optimized ONNX format.
The adapter weights in a format for ONNX Runtime.
Olive and the ONNX runtime support the multi-LoRA model serving pattern, which greatly reduces the compute footprint of serving many adapters:
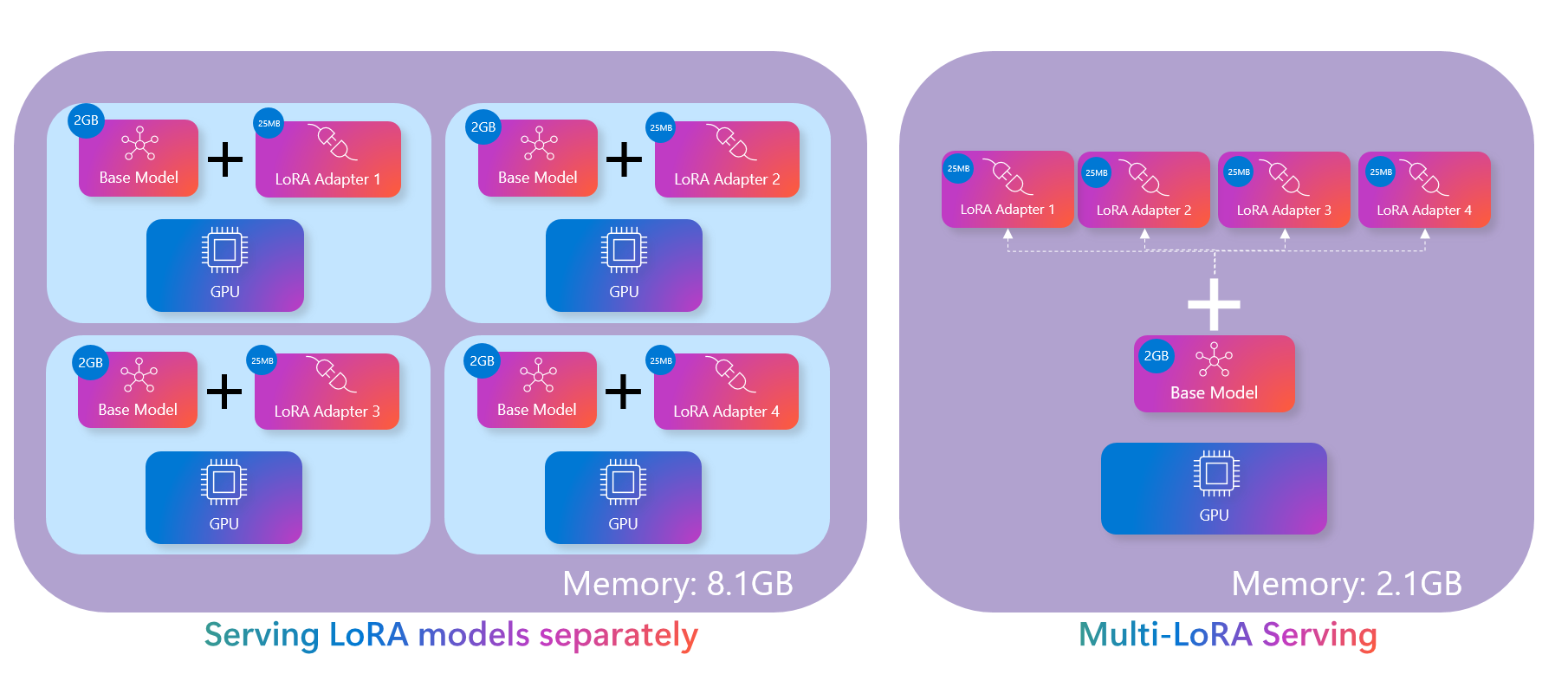
Multi-LoRA serving versus single-LoRA serving#