Model Splitting#
With the advent of Small Language Models (SLM) such Microsoft’s Phi family of models, it has become possible to deploy powerful language models on edge devices. However, these models are still a few gigabytes in size even after model optimization and compressions techniques like quantization. These sizes might be too large to load in a single session on the edge device, whether it is due to memory or runtime limitations.
Therefore, we need to split the model into multiple components and run inference on them in a cascade. This raises several questions: How to split the model? How many splits to make? and where to make the splits? In existing implementations that we have seen, users load the model graph and take note of the connections between different sections of the model. These connections are then used to modify the model graph and create the split graphs. However, this requires an understanding of the model architecture in the exported graph and is not a scalable approach.
Approach#
Olive automates this process by using the rich model structure available in the PyTorch model to make the split decisions to produce optimized ONNX model splits.
Olive provides multiple ways to guide split decisions:
For transformers like models, if the user already knows the number of splits to make, Olive can split transformer layers into equal splits. Such a split decision is made at a higher level of the model architecture.
The user can provide a cost model (a CSV containing the cost per module in the model in terms of memory, FLOPs and parameter counts). Olive currently uses the memory requirements of each layer to determine split assignments. However, we intend to improve splitting algorithm considering layers’ arithmetic intensity.
CLI#
Olive provides command line tools that make it easy for the user to optimize and split models. Olive provides utility to generate cost model for LLMs from HuggingFace hub. Olive also includes pre-generated cost models for popular models.
auto-opt#
Olive provides auto-opt command to convert, optimize and quantize the ONNX model. t now also provides options to split the model.
num-splits
Let’s split the model using a user defined number of splits.
olive auto-opt -m microsoft/Phi-3.5-mini-instruct --precision fp16 --provider CUDAExecutionProvider --num-splits 2 -o models/phi-nsplit
Olive uses the model_type for the HuggingFace model and divides the transformers layers equally among the splits. microsoft/Phi-3.5-mini-instruct has 32 such layers so each split gets assigned 16 layers each in this example. The first layer also includes the embedding layer and attention subgraphs while the final layer includes the language modeling head.
The following shows the final split models:
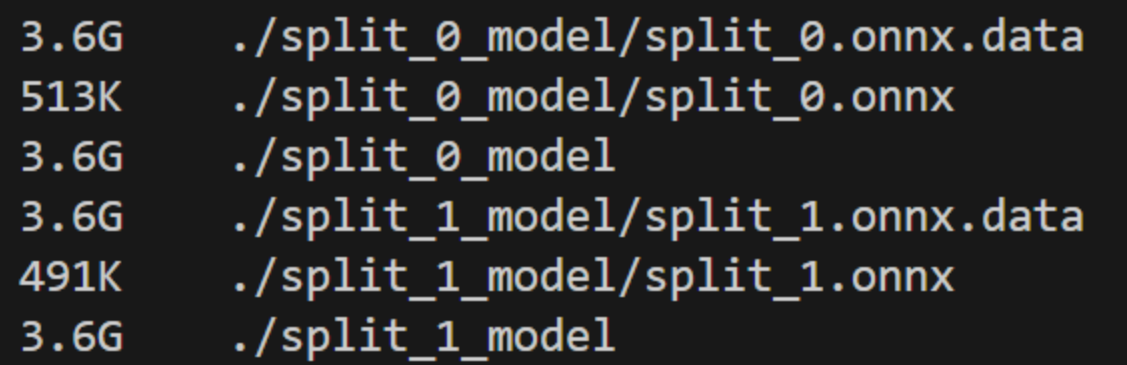
Number splits#
cost-model
Let’s now split the model using a cost model. Please refer to the pre-generated cost models in the Olive repository for an example a cost model csv.
olive auto-opt -m microsoft/Phi-3.5-mini-instruct --precision fp16 --provider CUDAExecutionProvider --memory 2GB --cost-model phi-3.5-cost.csv -o models/phi-costsplit
Olive uses the memory specs of the device and the cost model to automatically choose the required number of splits and make split assignments for each module.
The following shows the final split models:
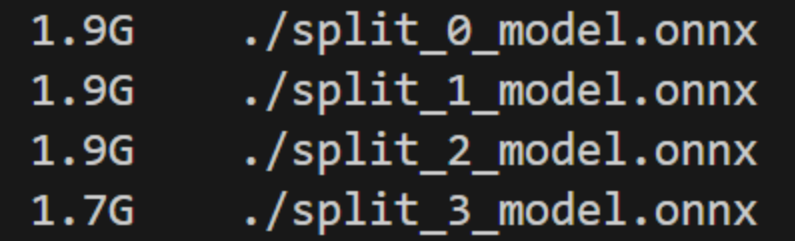
Cost model#
In this example, Olive split the model into four components each with size less than the max target memory of 2GB specified by the user.
generate-cost-model#
This tool can generate cost model for HuggingFace transformers models.
olive generate-cost-model -m microsoft/Phi-3.5-mini-instruct -p fp16 -o phi-3.5-cost.csv
Conclusion#
In this blog post, we introduced how one can use Olive to split models.