Framework
The Skill Lifecycle
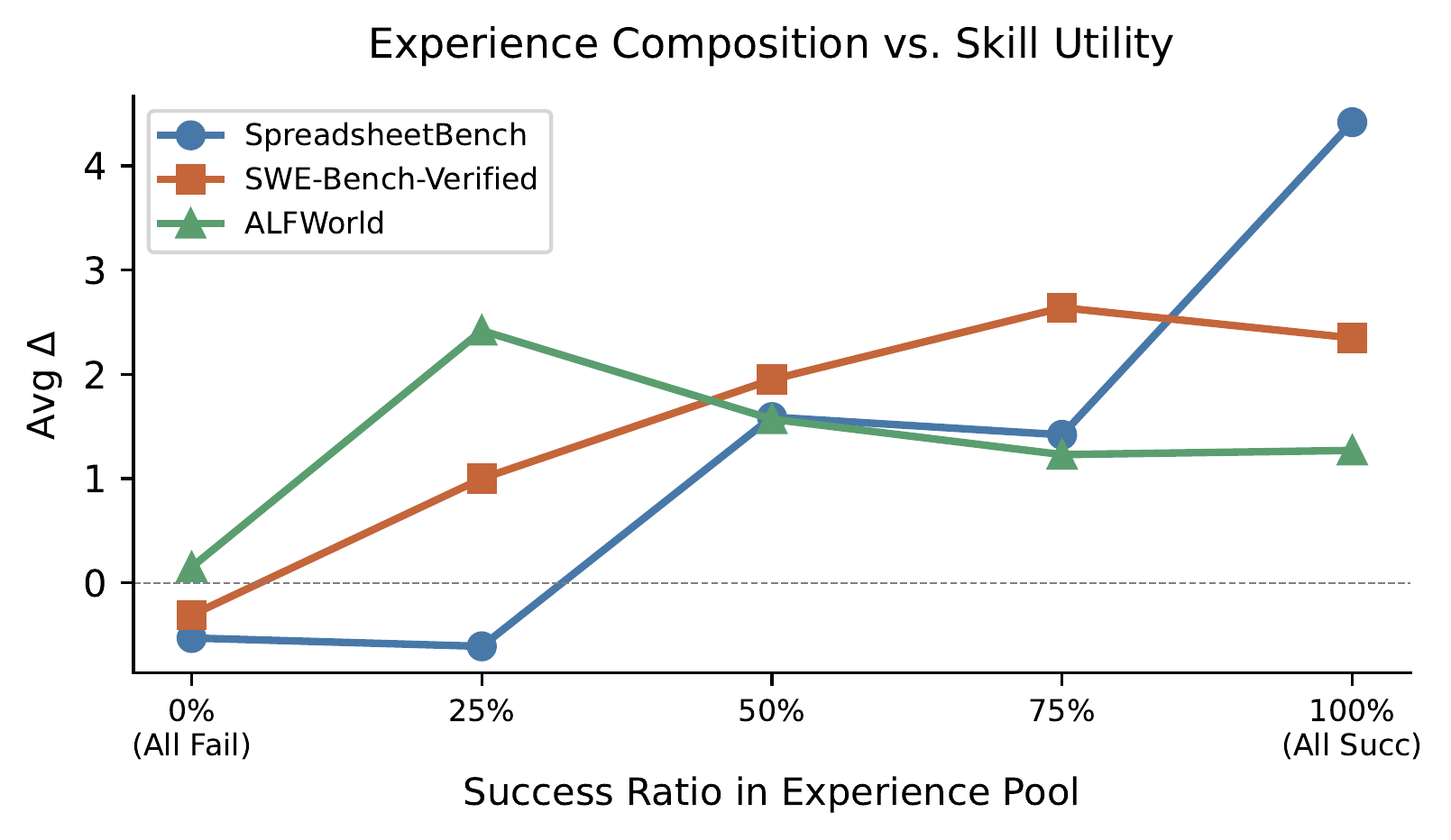
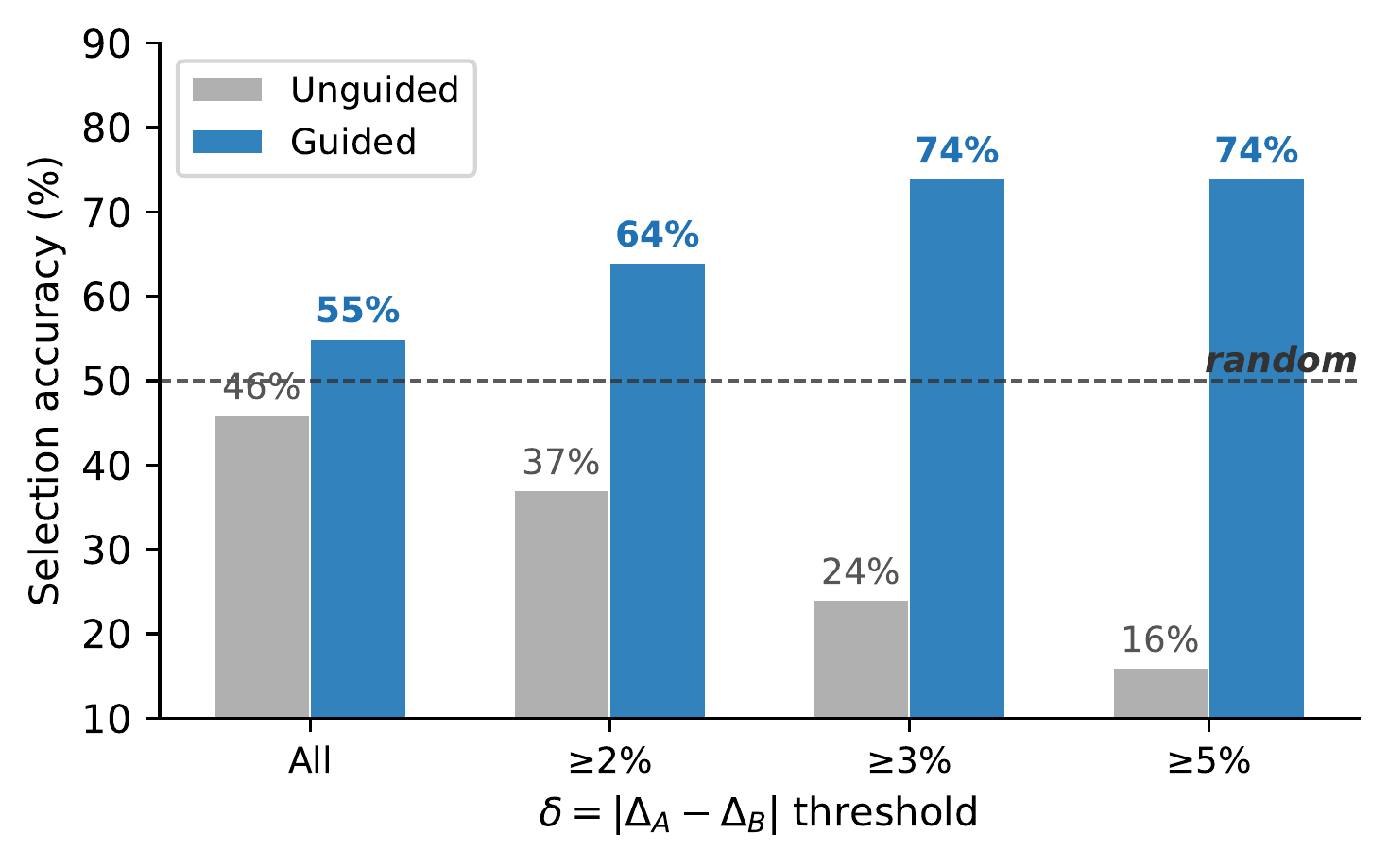
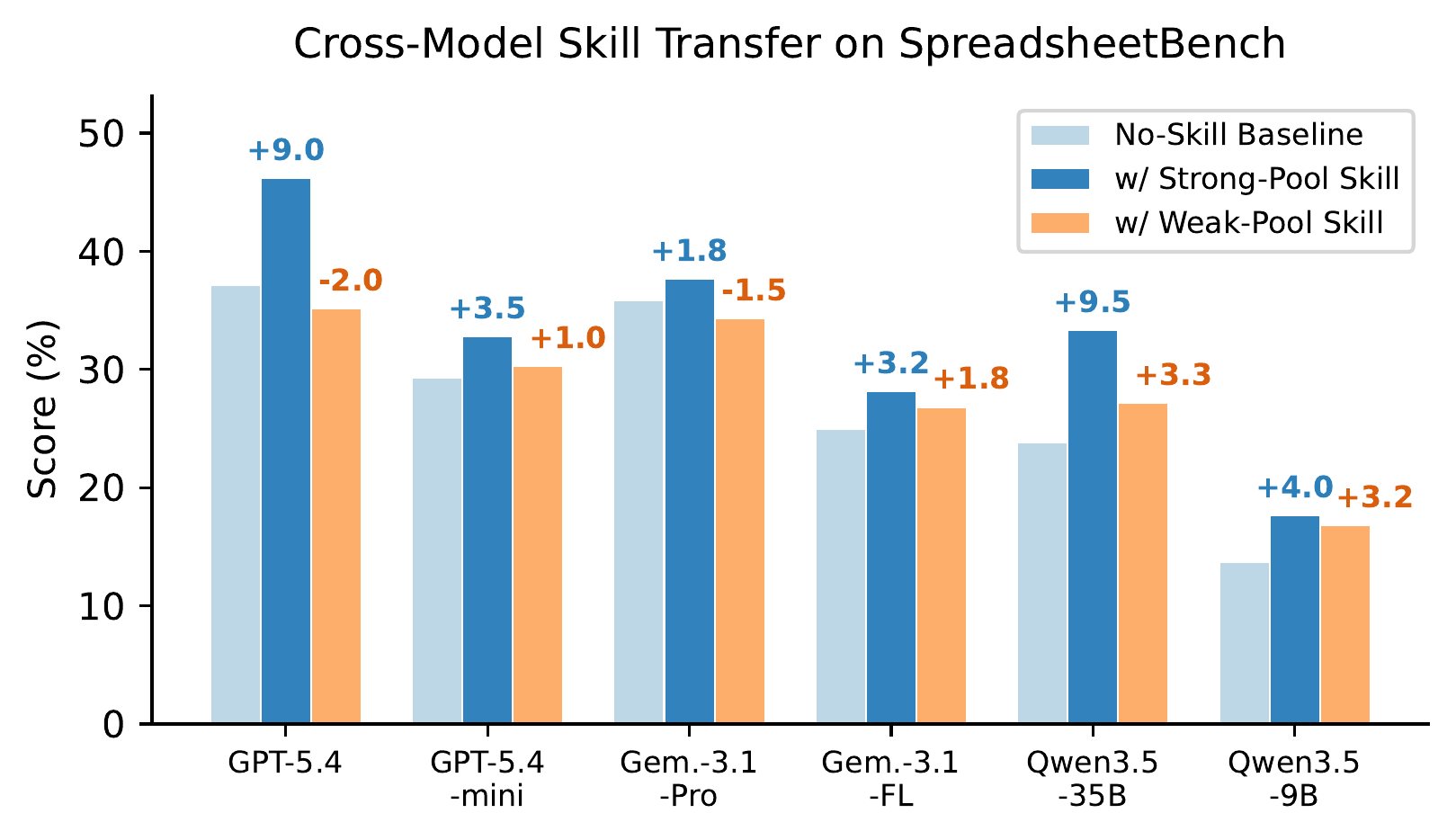
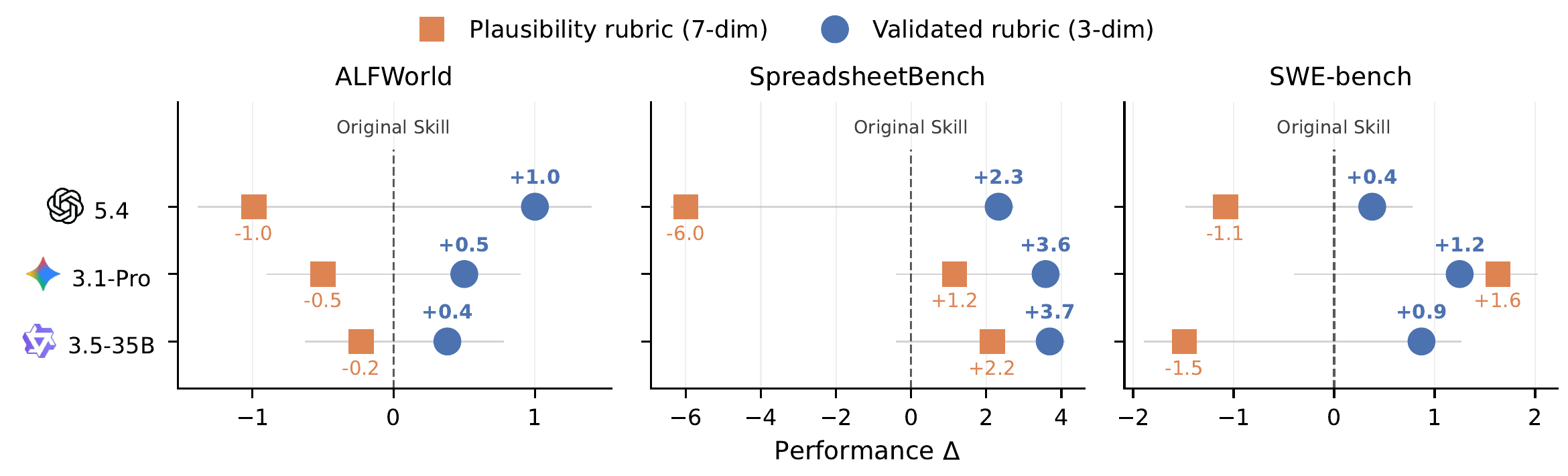
We evaluate the full experience-to-skill lifecycle across three stages, systematically varying extractor and target models across five diverse domains.
Experience Generation
Target agent rolls out tasks to form an experience pool.
→
Skill Extraction
Extractor distills the pool into a reusable domain-level skill.
→
Skill Consumption
Skill is loaded back into the target and evaluated.
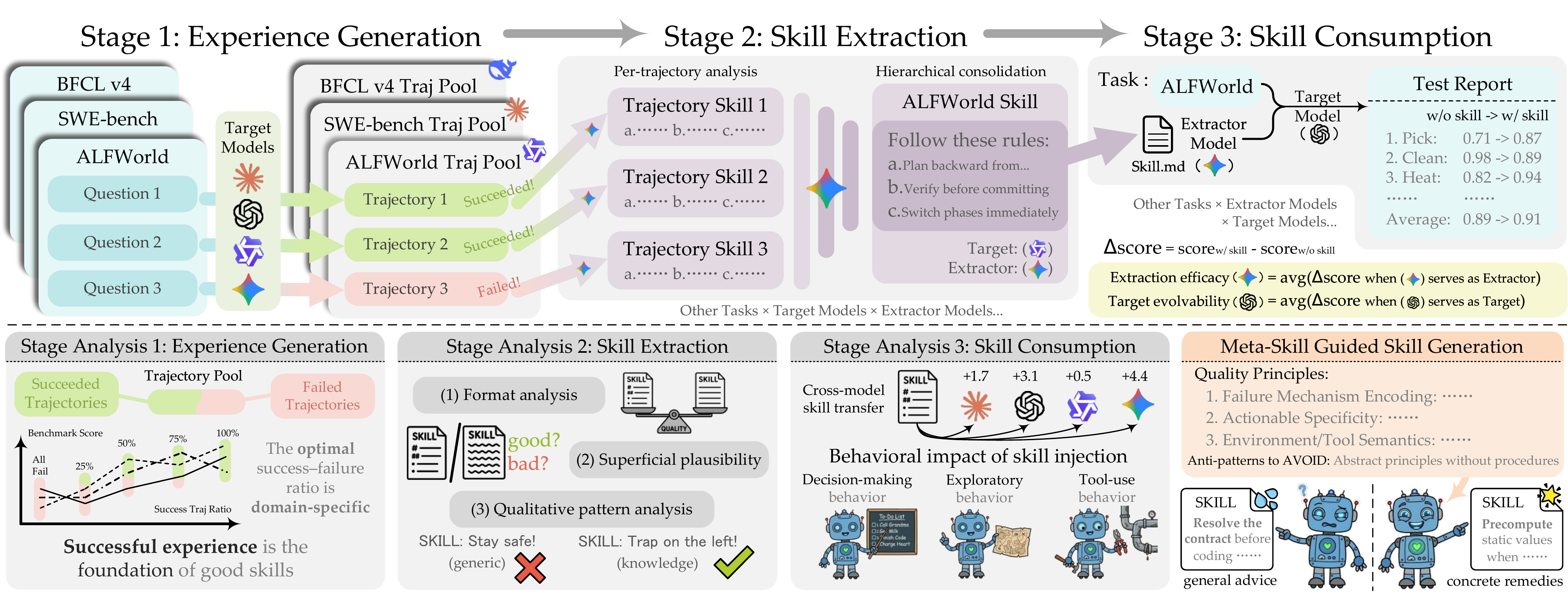
Figure 1. Overview of our study design across the three lifecycle stages.
 GPT-5.4
GPT-5.4 Gem-3.1-Pro
Gem-3.1-Pro Qwen3.5-35B
Qwen3.5-35B