Paper
Paper
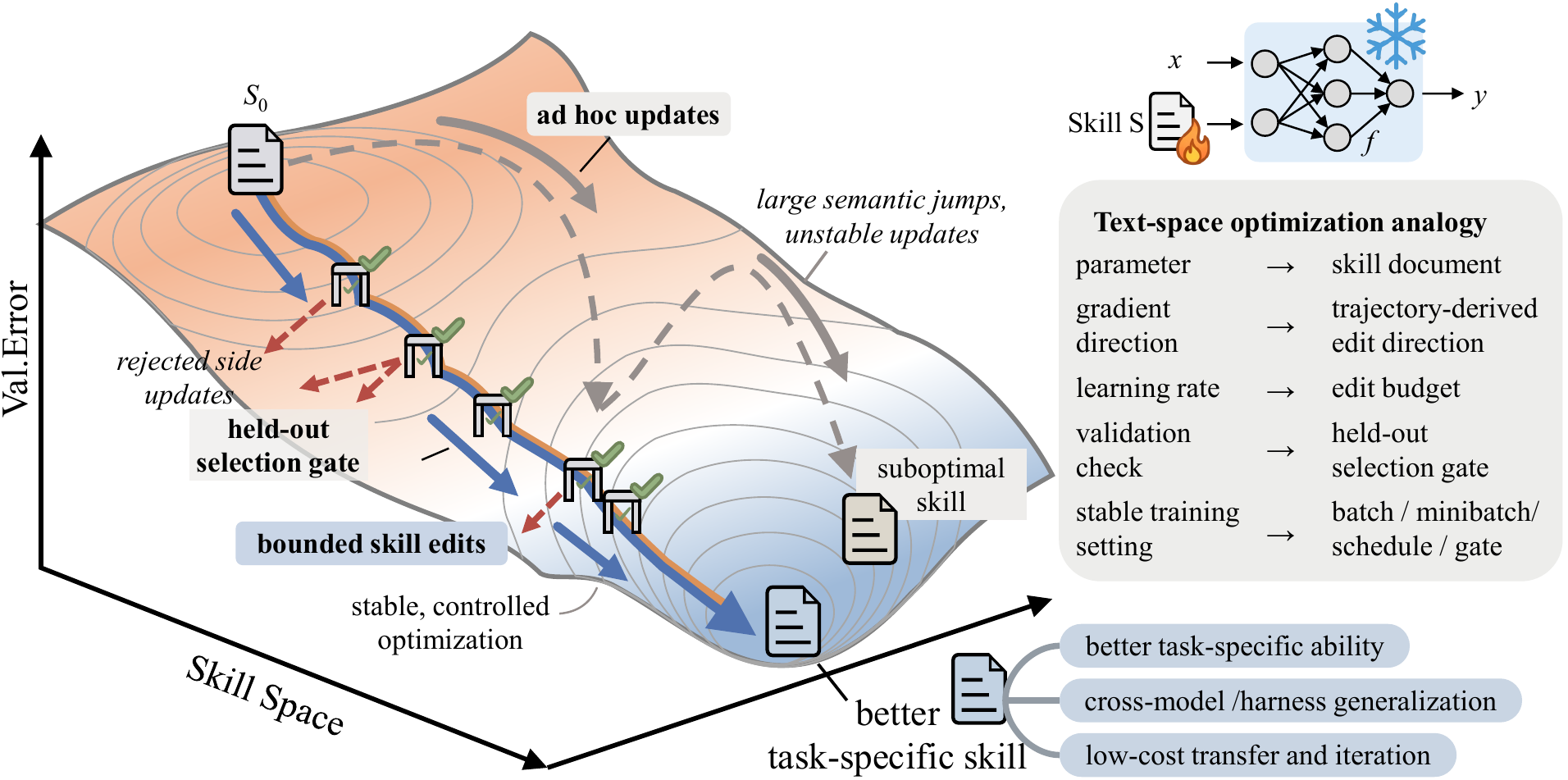
A skill is external state for an agent.
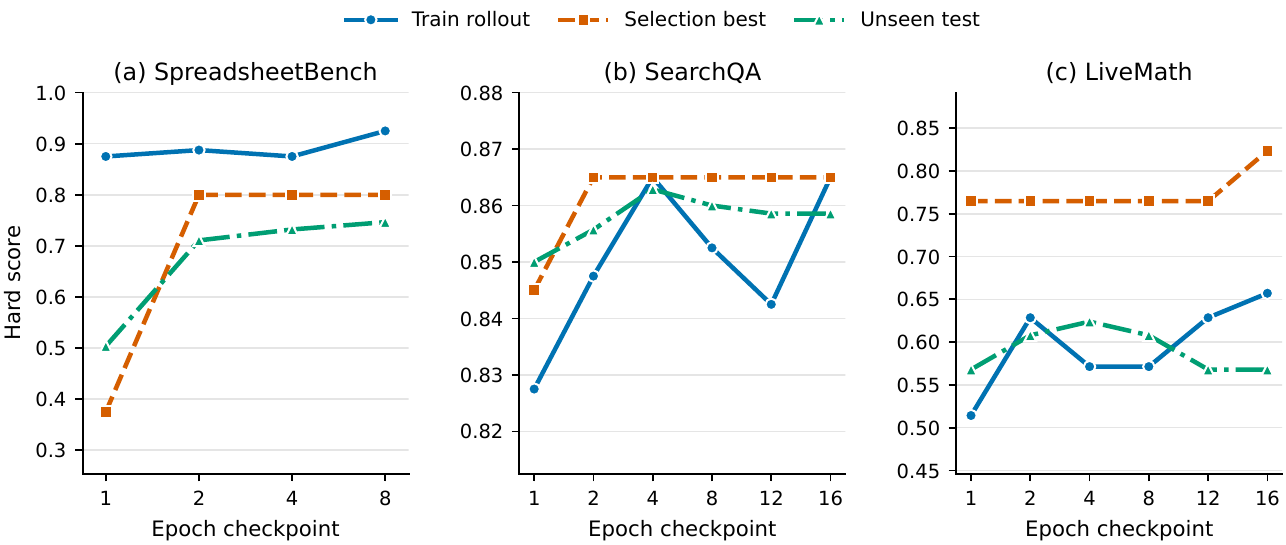
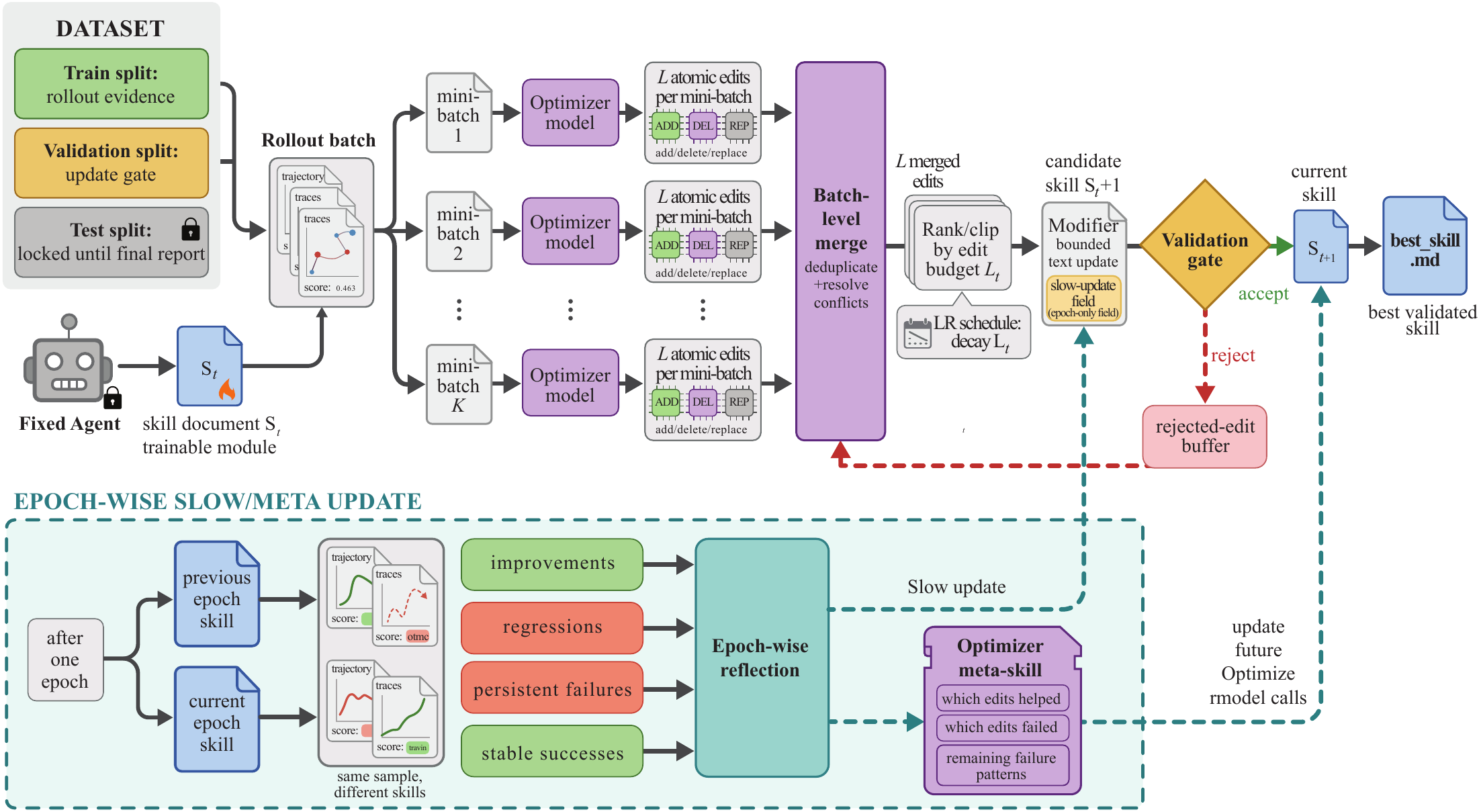
Instead of fine-tuning a model or hand-maintaining prompts, SkillOpt runs the frozen agent on scored batches, asks an optimizer model to propose structured edits, and accepts a candidate only when validation performance improves.
Frozen target model
Optimizer model
Add / delete / replace edits
Held-out gate
 GPT-5.5
GPT-5.5 Qwen3.5-4B
Qwen3.5-4B