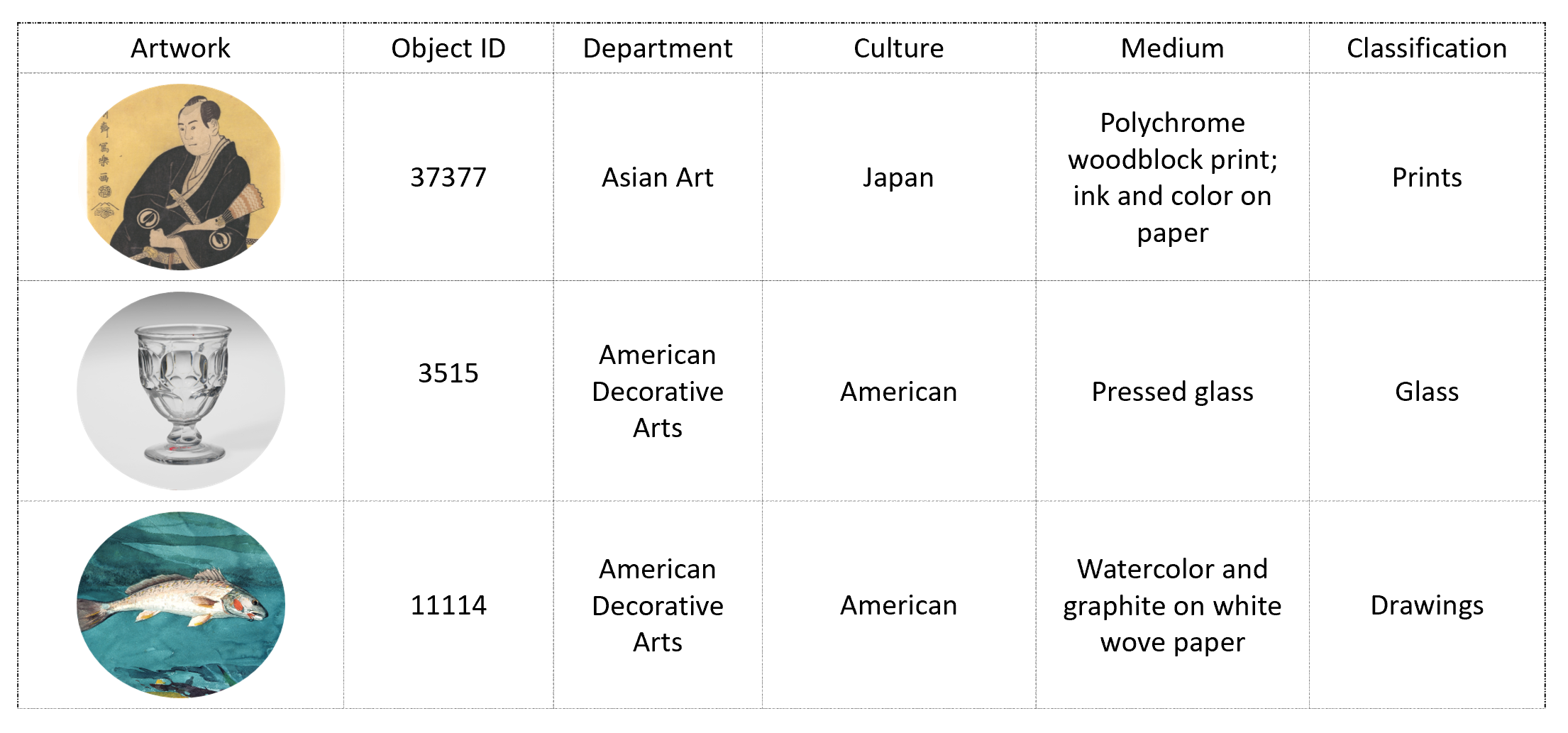
Creating a searchable Art Database with The MET's open-access collection
In this example, we show how you can enrich data using Cognitive Skills and write to an Azure Search Index using SynapseML. We use a subset of The MET's open-access collection and enrich it by passing it through 'Describe Image' and a custom 'Image Similarity' skill. The results are then written to a searchable index.
import os, sys, time, json, requests
from pyspark.sql.functions import lit, udf, col, split
from synapse.ml.core.platform import *
cognitive_key = find_secret("cognitive-api-key")
cognitive_loc = "eastus"
azure_search_key = find_secret("azure-search-key")
search_service = "mmlspark-azure-search"
search_index = "test"
data = (
spark.read.format("csv")
.option("header", True)
.load("wasbs://publicwasb@mmlspark.blob.core.windows.net/metartworks_sample.csv")
.withColumn("searchAction", lit("upload"))
.withColumn("Neighbors", split(col("Neighbors"), ",").cast("array<string>"))
.withColumn("Tags", split(col("Tags"), ",").cast("array<string>"))
.limit(25)
)
from synapse.ml.cognitive import AnalyzeImage
from synapse.ml.stages import SelectColumns
# define pipeline
describeImage = (
AnalyzeImage()
.setSubscriptionKey(cognitive_key)
.setLocation(cognitive_loc)
.setImageUrlCol("PrimaryImageUrl")
.setOutputCol("RawImageDescription")
.setErrorCol("Errors")
.setVisualFeatures(
["Categories", "Description", "Faces", "ImageType", "Color", "Adult"]
)
.setConcurrency(5)
)
df2 = (
describeImage.transform(data)
.select("*", "RawImageDescription.*")
.drop("Errors", "RawImageDescription")
)

Before writing the results to a Search Index, you must define a schema which must specify the name, type, and attributes of each field in your index. Refer Create a basic index in Azure Search for more information.
from synapse.ml.cognitive import *
df2.writeToAzureSearch(
subscriptionKey=azure_search_key,
actionCol="searchAction",
serviceName=search_service,
indexName=search_index,
keyCol="ObjectID",
)
The Search Index can be queried using the Azure Search REST API by sending GET or POST requests and specifying query parameters that give the criteria for selecting matching documents. For more information on querying refer Query your Azure Search index using the REST API
url = "https://{}.search.windows.net/indexes/{}/docs/search?api-version=2019-05-06".format(
search_service, search_index
)
requests.post(
url, json={"search": "Glass"}, headers={"api-key": azure_search_key}
).json()