Overview
What is MLflow
MLflow is a platform to streamline machine learning development, including tracking experiments, packaging code into reproducible runs, and sharing and deploying models. MLflow offers a set of lightweight APIs that can be used with any existing machine learning application or library, for instance TensorFlow, PyTorch, XGBoost, etc. It runs wherever you currently run ML code, for example, in notebooks, standalone applications or the cloud. MLflow's current components are:
- MLflow Tracking: An API to log parameters, code, and results in machine learning experiments and compare them using an interactive UI.
- MLflow Projects: A code packaging format for reproducible runs using Conda and Docker, so you can share your ML code with others.
- MLflow Models: A model packaging format and tools that let you easily deploy the same model from any ML library for both batch and real-time scoring. It supports platforms such as Docker, Apache Spark, Azure ML and AWS SageMaker.
- MLflow Model Registry: A centralized model store, set of APIs, and UI, to collaboratively manage the full lifecycle of MLflow Models.
Installation
Install MLflow from PyPI via pip install mlflow
MLflow requires conda to be on the PATH for the projects feature.
Learn more about MLflow on their GitHub page.
Install Mlflow on Databricks
If you're using Databricks, install Mlflow with this command:
# run this so that Mlflow is installed on workers besides driver
%pip install mlflow
Install Mlflow on Synapse
To log model with Mlflow, you need to create an Azure Machine Learning workspace and link it with your Synapse workspace.
Create Azure Machine Learning Workspace
Follow this document to create AML workspace. You don't need to create compute instance and compute clusters.
Create an Azure ML Linked Service
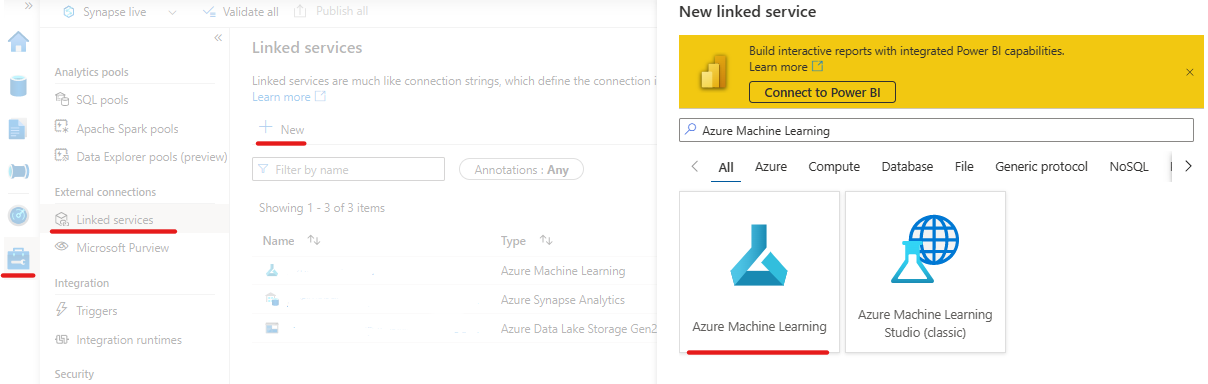
- In the Synapse workspace, go to Manage -> External connections -> Linked services, select + New
- Select the workspace you want to log the model in and create the linked service. You need the name of the linked service to set up connection.
Auth Synapse Workspace
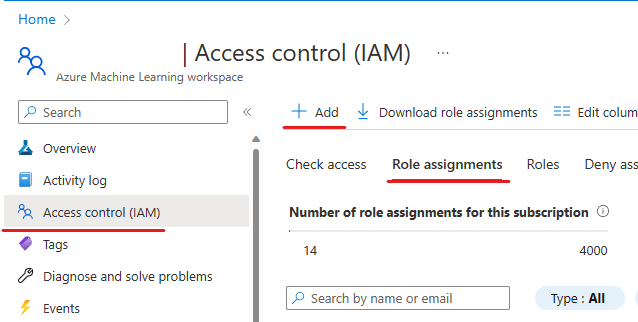
- Go to the Azure Machine Learning workspace resource -> access control (IAM) -> Role assignment, select + Add, choose Add role assignment
- Choose contributor, select next
- In members page, choose Managed identity, select + select members. Under managed identity, choose Synapse workspace. Under Select, choose the workspace you run your experiment on. Click Select, Review + assign.
Use MLFlow in Synapse with Linked Service
Set up connection
#AML workspace authentication using linked service
from notebookutils.mssparkutils import azureML
linked_service_name = "YourLinkedServiceName"
ws = azureML.getWorkspace(linked_service_name)
mlflow.set_tracking_uri(ws.get_mlflow_tracking_uri())
#Set MLflow experiment.
experiment_name = "synapse-mlflow-experiment"
mlflow.set_experiment(experiment_name)
Use MLFlow in Synapse without a Linked Service
Once you create an AML workspace, you can obtain the MLflow tracking URL directly. The AML start page is where you can locate the MLflow tracking URL.
MLFlow API Reference
Examples
LightGBMClassifier
import mlflow
from synapse.ml.featurize import Featurize
from synapse.ml.lightgbm import *
from synapse.ml.train import ComputeModelStatistics
with mlflow.start_run():
feature_columns = ["Number of times pregnant","Plasma glucose concentration a 2 hours in an oral glucose tolerance test",
"Diastolic blood pressure (mm Hg)","Triceps skin fold thickness (mm)","2-Hour serum insulin (mu U/ml)",
"Body mass index (weight in kg/(height in m)^2)","Diabetes pedigree function","Age (years)"]
df = spark.createDataFrame([
(0,131,66,40,0,34.3,0.196,22,1),
(7,194,68,28,0,35.9,0.745,41,1),
(3,139,54,0,0,25.6,0.402,22,1),
(6,134,70,23,130,35.4,0.542,29,1),
(9,124,70,33,402,35.4,0.282,34,0),
(0,93,100,39,72,43.4,1.021,35,0),
(4,110,76,20,100,28.4,0.118,27,0),
(2,127,58,24,275,27.7,1.6,25,0),
(0,104,64,37,64,33.6,0.51,22,1),
(2,120,54,0,0,26.8,0.455,27,0),
(7,178,84,0,0,39.9,0.331,41,1),
(2,88,58,26,16,28.4,0.766,22,0),
(1,91,64,24,0,29.2,0.192,21,0),
(10,101,76,48,180,32.9,0.171,63,0),
(5,73,60,0,0,26.8,0.268,27,0),
(3,158,70,30,328,35.5,0.344,35,1),
(2,105,75,0,0,23.3,0.56,53,0),
(12,84,72,31,0,29.7,0.297,46,1),
(9,119,80,35,0,29.0,0.263,29,1),
(6,93,50,30,64,28.7,0.356,23,0),
(1,126,60,0,0,30.1,0.349,47,1)
], feature_columns+["labels"]).repartition(2)
featurize = (Featurize()
.setOutputCol("features")
.setInputCols(feature_columns)
.setOneHotEncodeCategoricals(True)
.setNumFeatures(4096))
df_trans = featurize.fit(df).transform(df)
lightgbm_classifier = (LightGBMClassifier()
.setFeaturesCol("features")
.setRawPredictionCol("rawPrediction")
.setDefaultListenPort(12402)
.setNumLeaves(5)
.setNumIterations(10)
.setObjective("binary")
.setLabelCol("labels")
.setLeafPredictionCol("leafPrediction")
.setFeaturesShapCol("featuresShap"))
lightgbm_model = lightgbm_classifier.fit(df_trans)
# Use mlflow.spark.save_model to save the model to your path
mlflow.spark.save_model(lightgbm_model, "lightgbm_model")
# Use mlflow.spark.log_model to log the model if you have a connected mlflow service
mlflow.spark.log_model(lightgbm_model, "lightgbm_model")
# Use mlflow.pyfunc.load_model to load model back as PyFuncModel and apply predict
prediction = mlflow.pyfunc.load_model("lightgbm_model").predict(df_trans.toPandas())
prediction = list(map(str, prediction))
mlflow.log_param("prediction", ",".join(prediction))
# Use mlflow.spark.load_model to load model back as PipelineModel and apply transform
predictions = mlflow.spark.load_model("lightgbm_model").transform(df_trans)
metrics = ComputeModelStatistics(evaluationMetric="classification", labelCol='labels', scoredLabelsCol='prediction').transform(predictions).collect()
mlflow.log_metric("accuracy", metrics[0]['accuracy'])
Azure AI Services
import mlflow
from synapse.ml.services import *
with mlflow.start_run():
text_key = "YOUR_COG_SERVICE_SUBSCRIPTION_KEY"
df = spark.createDataFrame([
("I am so happy today, its sunny!", "en-US"),
("I am frustrated by this rush hour traffic", "en-US"),
("The cognitive services on spark aint bad", "en-US"),
], ["text", "language"])
sentiment_model = (TextSentiment()
.setSubscriptionKey(text_key)
.setLocation("eastus")
.setTextCol("text")
.setOutputCol("prediction")
.setErrorCol("error")
.setLanguageCol("language"))
display(sentiment_model.transform(df))
mlflow.spark.save_model(sentiment_model, "sentiment_model")
mlflow.spark.log_model(sentiment_model, "sentiment_model")
output_df = mlflow.spark.load_model("sentiment_model").transform(df)
display(output_df)
# In order to call the predict function successfully you need to specify the
# outputCol name as `prediction`
prediction = mlflow.pyfunc.load_model("sentiment_model").predict(df.toPandas())
prediction = list(map(str, prediction))
mlflow.log_param("prediction", ",".join(prediction))