1. Write agent flexibly in Python. Declare the trainable parts and decorate the agent’s methods. Just like writing a neural network.
@trace.model
class Agent:
def __init__(self, system_prompt):
self.system_prompt = system_prompt
self.instruct1 = trace.node("Decide the language", trainable=True)
self.instruct2 = trace.node("Extract name", trainable=True)
def __call__(self, user_query):
# First LLM
response = call_llm(self.system_prompt, self.instruct1, user_query)
en_or_es = self.decide_lang(response)
# Second LLM
user_name = call_llm(self.system_prompt, self.instruct2, user_query)
greeting = self.greet(en_or_es, user_name)
return greeting
@trace.bundle(trainable=True)
def decide_lang(self, response):
"""Map the language into a variable"""
return
@trace.bundle(trainable=True)
def greet(self, lang, user_name):
"""Produce a greeting based on the language"""
greeting = "Hola"
return f"{greeting}, {user_name}!"2. Train agent using feedback. Trace back-propagates feedback to end-to-end update parameters (codes, prompts, etc.) in-place.
agent = Agent("You are a sales assistant.")
optimizer = OptoPrime(agent.parameters())
try:
greeting = agent("Hola, soy Juan.")
feedback = feedback_fn(greeting.data, 'es')
# feedback = "Correct" or "Incorrect"
except ExecutionError as e:
greeting = e.exception_node
feedback = greeting.data,
optimizer.zero_feedback()
optimizer.backward(greeting, feedback)
optimizer.step()
Trace in 5 Minutes
Trace is an open-source generative optimization framework for end-to-end training AI agents with general feedback (like scores, natural language, errors, etc.).
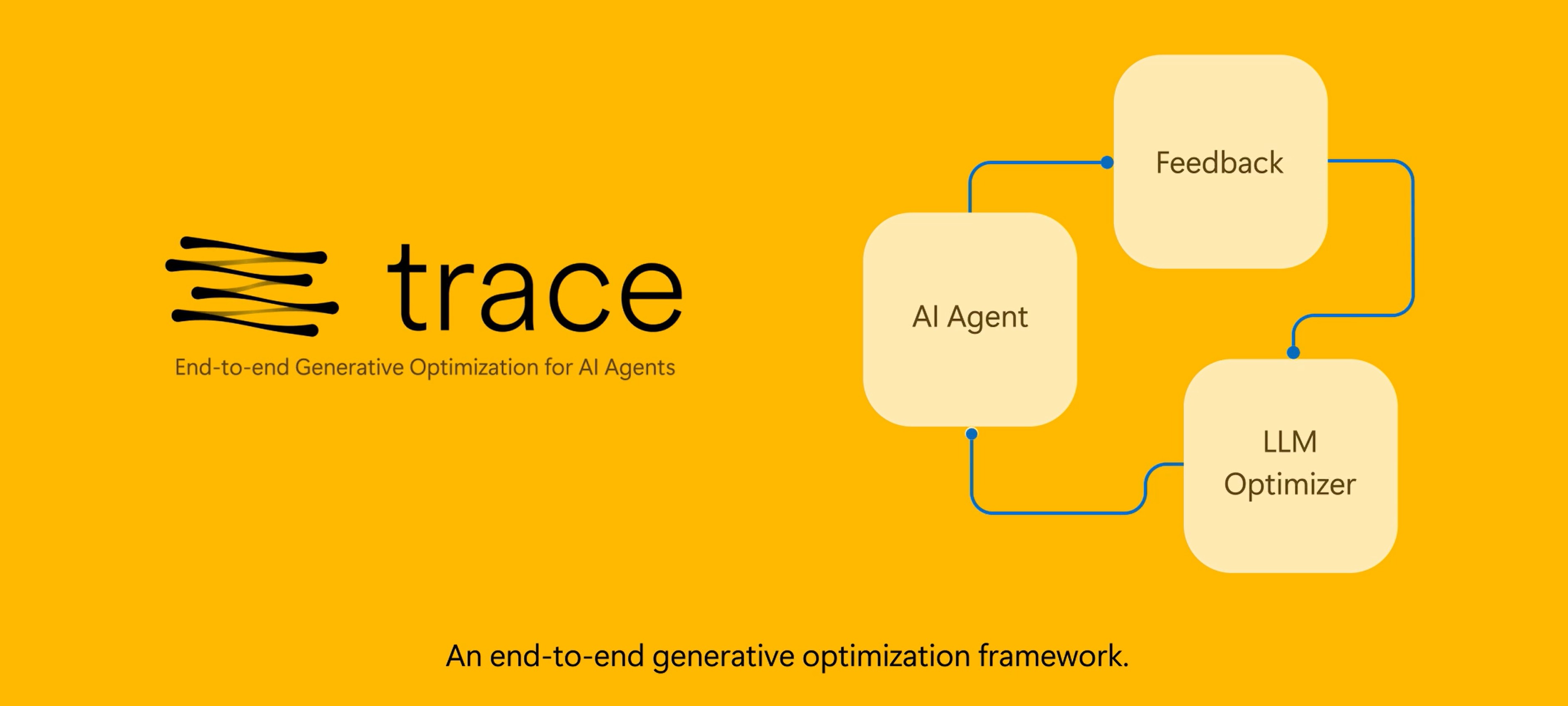
End-to-End Generative Optimization
An AI agent has many modules. Trace captures the system's underlying execution flow and represents it as a graph. Trace can then optimize the entire system with general feedback using LLM-based optimizers.
Native Python Support
Trace gives users full flexibility in programming AI agents. By using two primitives and to wrap over Python objects and functions, Trace is compatible with any Python program and capable of optimizing any mixture of code, string, numbers, and objects, etc.
Research Platform
Trace propagates execution traces as Minimal Subgraphs to optimizers. This common abstraction allows easy experimentation with different optimization algorithms (e.g., OPRO, TextGrad, OptoPrime) in Trace and gives researchers full freedom to design new techniques for AI agents.
Consider building an AI agent for the classic Battleship game. In Battleship, a player's goal to hit the ships on a hidden board as fast as possible. To this end, the player must devise strategies to cleverly locate the ships and attack them, instead of slowly enumerating the board. To build an AI agent with Trace, one simply needs to program the workflow of the agent and declare the parameters, just like programming a neural network architecture.

In this example, we will design an agent with two components: a reason function and an
act function. To do this, we provide just a basic description of what these two
functions should do (reason should analyze the board and act should select a target
coordinate). Then we leave the content to be blank and just set those two functions to
be trainable (by setting trainable=True). We highlight that, at this point,
the agent doesn't know how the Battleship API works. It must not only learn how to play
the game, but also learn how to use the unknown API.
from opto import trace
@trace.model
class Agent:
# this function is not changed by the optimizer
def __call__(self, map):
return self.select_coordinate(map).data
# this function is not changed by the optimizer
def select_coordinate(self, map):
plan = self.reason(map)
output = self.act(map, plan)
return output
@trace.bundle(trainable=True)
def act(self, map, plan):
"""
Given a map, select a target coordinate in a game.
X denotes hits, O denotes misses,
and . denotes unknown positions.
"""
return
@trace.bundle(trainable=True)
def reason(self, map):
"""
Given a map, analyze the board in a game.
X denotes hits, O denotes misses,
and . denotes unknown positions.
"""
returnWe iteratively train this AI agent to play the game through a simple for loop (see code below). In each iteration, the agent (i.e. policy) sees the board configuration and tries to shoot at a target location. The environment returns in text whether it’s a hit or a miss. Then we run Trace to propagate this environment feedback through agent’s decision logic end-to-end to update the parameters (i.e. the policy is like a two-layer network with a reason layer and an act layer).
These iterations mimic how a human programmer might approach the problem. They run the policy and change the code based on the observed feedback, try different heuristics to solve this problem, and they may rewrite the code a few times to fix any execution errors by using stack traces. The results of the learned policy evaluated on randomly generated held-out games can be found in the top figure of the page. We see the agent very quickly learns a sophisticated strategy to balance exploration and exploitation.
from opto import trace
from opto.optimizers import OptoPrime
from battleship import BattleshipBoard
GRAPH.clear()
board = BattleshipBoard(8, 8)
agent = Agent()
obs = node(board.get_shots(), trainable=False)
optimizer = OptoPrime(agent.parameters())
feedback, terminal, cum_reward = "", False, 0
iterations = 0
while not terminal:
try:
output = agent.act(obs)
obs, reward, terminal, feedback = user_fb_for_placing_shot(board, output.data)
except trace.ExecutionError as e:
output = e.exception_node
feedback, terminal, reward = output.data, False, 0
optimizer.zero_feedback()
optimizer.backward(output, feedback)
optimizer.step(verbose=False)Trace is based on the concept of computational graph. Trace primitive can be used to wrap over Python objects as nodes in the graph. The example below shows how different types of Python objects can be included in the Trace graph. Nodes can be marked as trainable, which allows the optimizer to change the content of the node. As convenience, basic Python operations can be performed on node objects, and these operations will be automatically traced in the graph.
from opto import trace
w = trace.node(3)
x = trace.node({"learning_rate": 1e-3})
z = trace.node([2, 5, 3])
y = trace.node("You are a helpful assistant.", trainable=True)Generally, we can use the Trace primitive to wrap over Python functions and present them as operators in the computational graph. By using , we can create arbitrary complex operations on nodes. creates an abstraction of the decorated function by summarizing it as its docstring. Optionally we can also let the optimizer to change the content of this function by setting the trainable flag. With Trace you don't need to wrap your Python function in a string to be optimized; it can be optimized in-place.
from opto import trace
import math
# this function is not changed by the optimizer
@trace.bundle()
def bar(x):
""" Return the cube root of x. """
return math.cbrt(x)
# this function will be changed
@trace.bundle(trainable=True)
def sort_numbers(x):
"""Sort the list x and return it"""
return xTrace dynamically constructs a computational graph of the user-defined workflow as the code runs. The graph is an abstraction of the workflow's execution, which might not be the same as the original program. The original program can have complicated logic, but the user can decide what necessary information the computational graph should contain for an optimizer to update the workflow. For an example program:
from opto import trace
import math
# this function is not changed by the optimizer
@trace.bundle()
def bar(x):
""" Return the cube root of x. """
return math.cbrt(x)
# this function will be changed
@trace.bundle(trainable=True)
def sort_numbers(x):
"""Sort the list x and return it"""
return xIf we visualize during the backward pass, Trace returns to the optimizer a partial graph (Minimal
Subgraph) of how the program is run.
In this program, we abstracted away all the operations on x inside function
bar and we don't trace what happens in some_function().
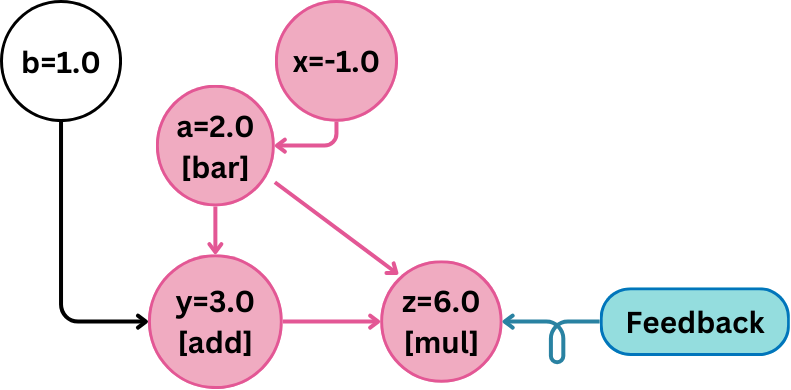
If we visualize during the backward pass, Trace returns to the optimizer a partial graph (Minimal
Subgraph) of how the program is run.
In this program, we abstracted away all the operations on x inside function
bar. However, we can still see how b
is generated in traced_function().
Trace allows user to design which part of the workflow they want to present to the LLM optimizer. Users can choose to present as much information (i.e., a complete picture of the workflow) or as little information (i.e., only the most crucial part of the workflow) as possible.
An optimizer works with this Trace graph presented by Trace (which is called the trace
feedback in the paper), which gives structural information of computation process. In the
paper, we present an initial design of a generative optimizer (OptoPrime) that represents the Trace
graph as a code debugging report, and ask an LLM to change part of the graph that is marked as
trainable=True according to feedback.
In addition to OptoPrime, Trace provides multiple generative optimizer like ORPO and TextGrad, which can be used interchangeably to optimize traced workflows.
from opto.optimizers import OptoPrime
from opto.optimizers import TextGrad
from opto.optimizers import OPRO
agent = Agent()
data = node(doc)
output = agent.act(data)
optimizer = OptoPrime(agent.parameters())
optimizer = TextGrad(agent.parameters())
optimizer = OPRO(agent.parameters())We provide a comparison to validate our implementation of TextGrad in Trace:

The design of Trace is based on a new mathematical setup of iterative optimization, which we call Optimization with Trace Oracle (OPTO). In OPTO, an optimizer selects parameters and receives a computational graph of execution trace as well as feedback on the computed output. This formulation is quite general and can describe many end-to-end optimization problems in AI systems, beyond neural networks. This key finding gives Trace the foundation to effectively optimize AI systems.
Definition of OPTO : An OPTO problem instance is defined by a tuple $(\Theta, \omega, T)$, where $\Theta$ is the parameter space, $\omega$ is the context of the problem, and $T$ is a Trace Oracle. In each iteration, the optimizer selects a parameter $\theta\in\Theta$, which can be heterogeneous. Then the Trace Oracle $T$ returns a trace feedback, denoted as $\tau = (f,g)$, where $g$ is the execution trace represented as a DAG (the parameter is contained in the root nodes of $g$), and $f$ is the feedback provided to exactly one of the output nodes of $g$. Finally, the optimizer uses the trace feedback $\tau$ to update the parameter according to the context $\omega$ and proceeds to the next iteration.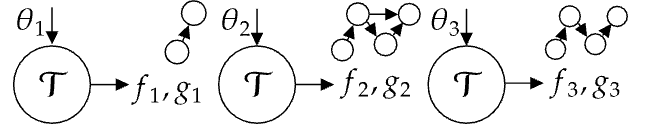
Here is how some existing problems can be framed as OPTO problems.
- Neural network with back-propagation: The parameters are the weights. $g$ is the neural computational graph and $f$ is the loss. An example context $\omega$ can be "Minimize loss". The back-propagation algorithm can be embedded in the OPTO optimizer, e.g., an OPTO optimizer can use $\tau$ to compute the propagated gradient at each parameter, and apply a gradient descent update.
- RL: The parameters are the policy. $g$ is the trajectory (of states, actions, rewards) resulting from running the policy in a Markov decision process; that is, $g$ documents the graphical model of how an action generated by the policy, applied to the transition dynamics which then returns the observation and reward, etc. $f$ can be the termination signal or a success flag. $\omega$ can be "Maximize return" or "Maximize success".
- Prompt Optimization of an LLM Agent: The parameters are the prompt of an LLM workflow. $g$ is the computational graph of the agent and $f$ is the feedback about the agent's behavior (which can be scores or natural language). $\omega$ can be "Maximize score" or "Follow the feedback".
We design Trace as a tool to efficiently convert the optimization of AI systems into OPTO problems. Trace acts as the Trace Oracle in OPTO, which is defined by the usage of Trace primitives in the user's program. Trace implements the trace feedback returned by the Trace Oracle as the Trace Graph, which defines a general API for AI system optimization. This formulation allows users to develop new optimization algorithms that can be applied to diverse AI systems.
Team
Trace includes contributions from the following people listed alphabetically. We are also thankful to the many people behind the scenes who provided support and feedback in the form of suggestions, GitHub issues, and reviews.

Ching-An Cheng
Principal Researcher
Microsoft Research

Allen Nie
PhD
Stanford University

Adith Swaminathan
Research Scientist
Netflix