训练数据
~3,000
纯文本世界模拟提示词
已被ICML 2026接收
技术细节
1 Zhejiang University 2 Microsoft Research 3 Independent Researcher
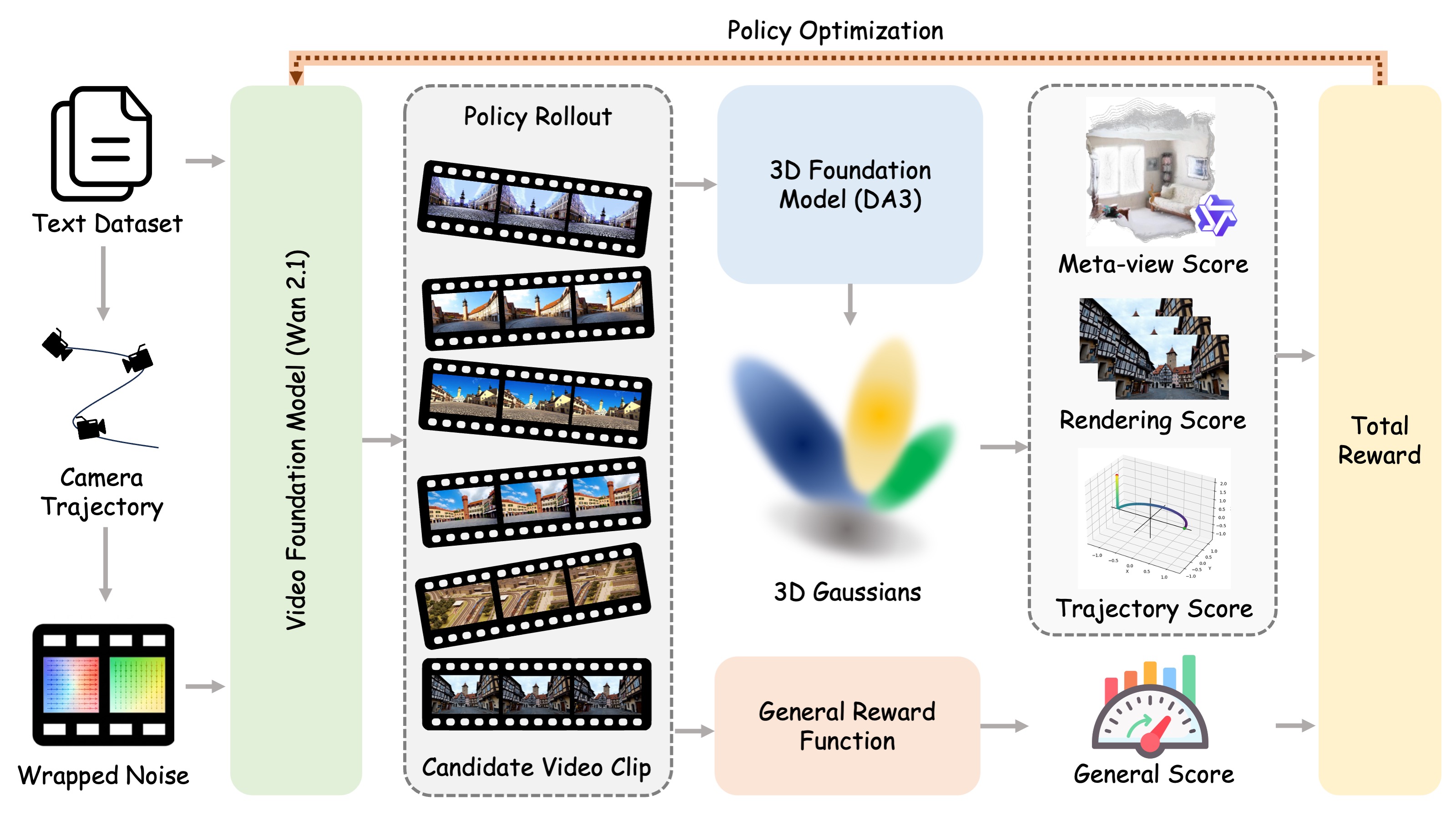
World-R1 通过强化学习将文本到视频生成与 3D 约束对齐,不改动基础架构,也不增加推理阶段的 3D 控制模块。
训练数据
~3,000
纯文本世界模拟提示词
动态子集
~500
高熵动态场景提示词
3D 一致性
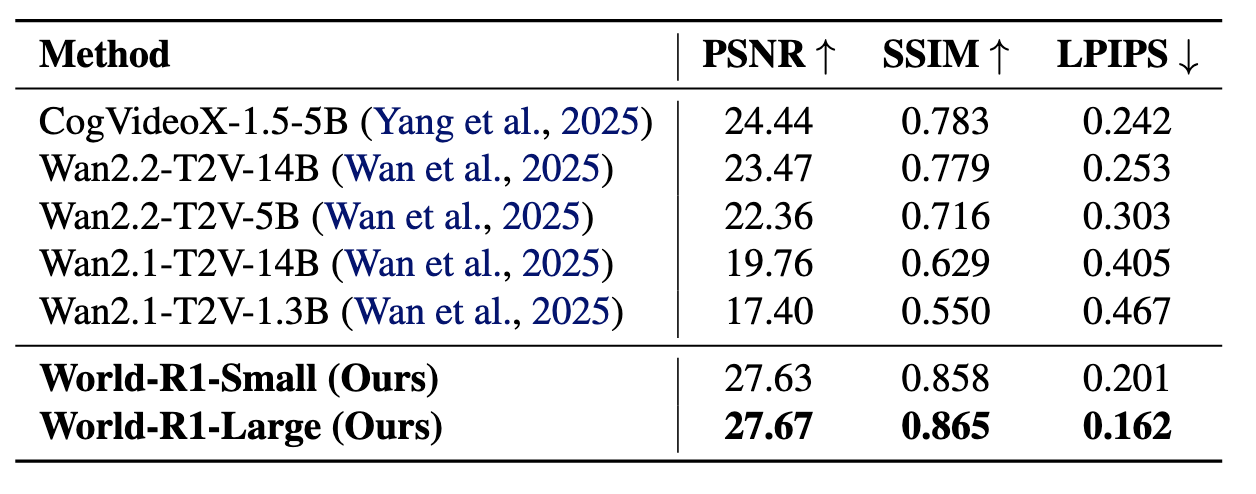
27.67
World-R1-Large 最佳 PSNR
MVCS
0.993
不依赖重建的一致性指标
用户偏好
86%
相对 Wan2.1 的整体胜率
基础模型
1.3B / 14B
Wan2.1 版本,分别使用 48 / 96 张 H200 训练
01
近期视频基础模型在视觉合成方面表现出色,但仍经常出现几何不一致问题。 现有方法通常通过架构改造注入 3D 先验,但代价较高且可扩展性受限。 我们提出 World-R1,通过强化学习将视频生成过程与 3D 约束对齐。 为支持该对齐过程,我们构建了面向世界模拟的专用纯文本数据集。 基于 Flow-GRPO,我们利用预训练 3D 基础模型与视觉语言模型的反馈进行优化,在不改动底层架构的前提下提升结构一致性。 同时,我们采用周期性解耦训练策略,在刚性几何一致性与动态场景流畅性之间取得平衡。 大量实验表明,该方法在保持原始视觉质量的同时显著提升 3D 一致性,有效弥合了视频生成与可扩展世界模拟之间的差距。
02
03
将文本中的 push、pull、pan、move、orbit 等运动指令转换为相机轨迹,并通过轨迹引导的 noise wrapping 写入初始噪声。
Depth Anything 3 将视频重建为 3DGS;Qwen3-VL 评估 meta-view,LPIPS 衡量重渲染保真度,轨迹得分检查相机控制。
HPSv3 对生成帧进行视觉质量评分,使强化学习对齐在提升几何结构的同时保持审美质量、主体一致性与运动流畅性。
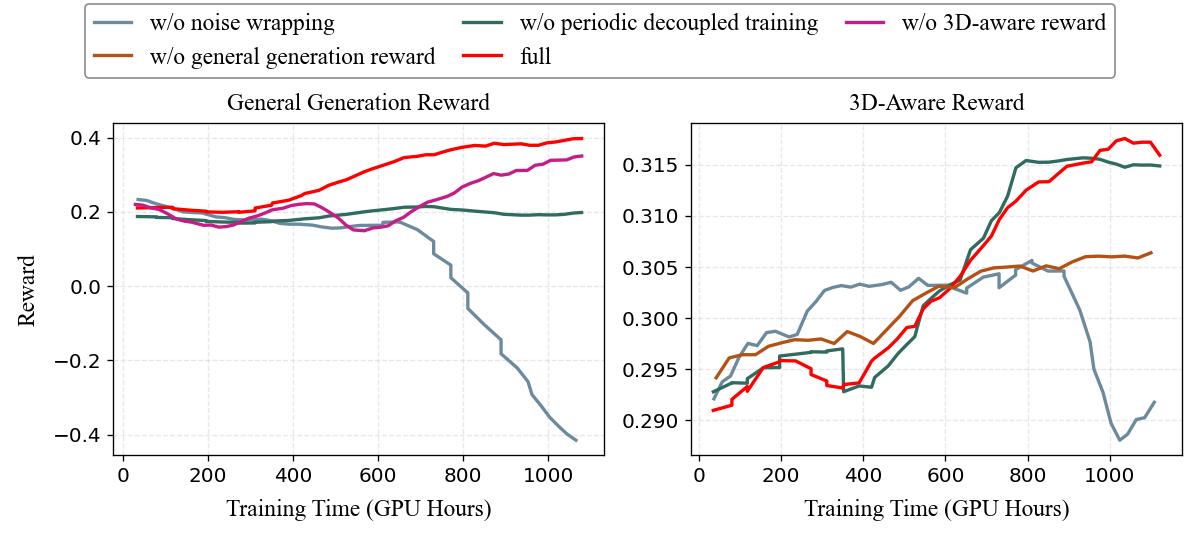
每 100 步临时关闭 3D 感知奖励,仅用通用奖励在约 500 条高熵动态提示词上优化,避免模型过度刚性化。
04



05
06
3D 重建
World-R1-Large 相比 Wan2.1-T2V-14B 显著提升几何一致性。
Small 版本
World-R1-Small 在 3D 一致性评测中达到 27.63 PSNR 与 0.858 SSIM。
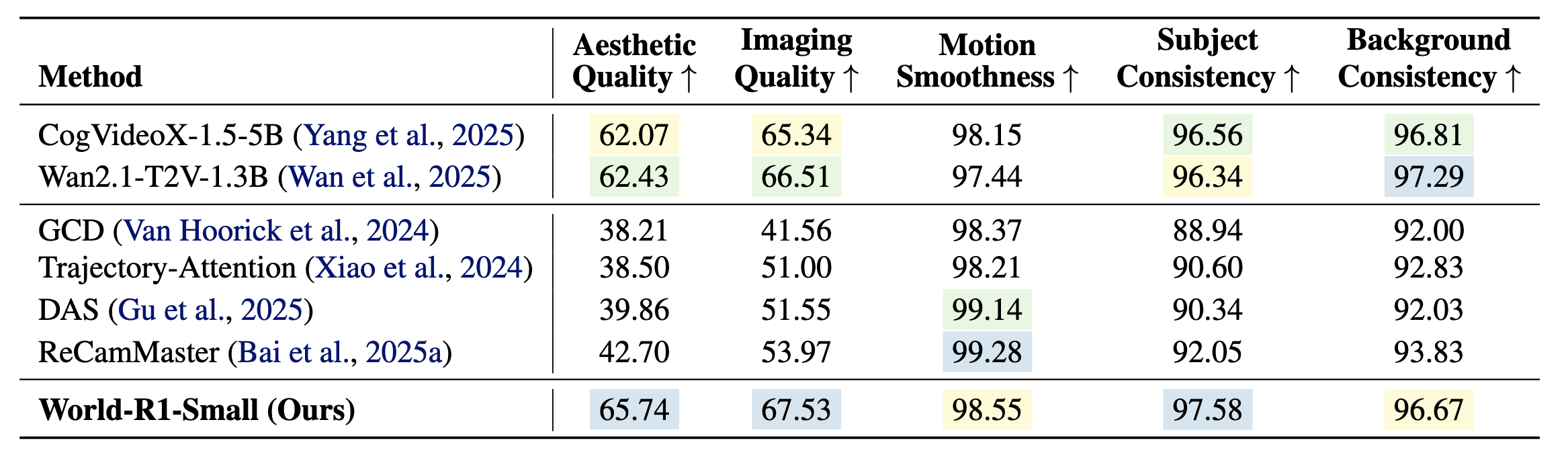
VBench
RL 对齐后仍保持通用视频质量,并将主体一致性提升到 97.58。
07
用户研究
25 名参与者在 30 条复杂提示词上,以盲测 2AFC 形式比较 World-R1 与 Wan2.1。
指标验证
20 名参与者和 30 组随机视频对显示,人工 3D 一致性偏好与自动指标排序高度一致。
长视频
相对 Wan2.1-T2V-14B,World-R1-Large 将长视频 PSNR 从 18.32 提升到 26.32。
08
World-R1 与基线模型在代表性提示词上的对比。