ai-agents-for-beginners

(Klicken Sie auf das obige Bild, um das Video zu dieser Lektion anzusehen)
Tool Use Design Pattern
Werkzeuge sind interessant, weil sie KI-Agenten eine breitere Palette von Fähigkeiten ermöglichen. Anstatt dass der Agent über eine begrenzte Menge von Aktionen verfügt, die er ausführen kann, kann der Agent durch Hinzufügen eines Werkzeugs nun eine Vielzahl von Aktionen ausführen. In diesem Kapitel betrachten wir das Tool Use Design Pattern, das beschreibt, wie KI-Agenten bestimmte Werkzeuge nutzen können, um ihre Ziele zu erreichen.
Einführung
In dieser Lektion wollen wir folgende Fragen beantworten:
- Was ist das Tool Use Design Pattern?
- Für welche Anwendungsfälle kann es eingesetzt werden?
- Welche Elemente/Bausteine werden benötigt, um das Design Pattern umzusetzen?
- Welche besonderen Überlegungen sind bei der Verwendung des Tool Use Design Pattern zur Erstellung von vertrauenswürdigen KI-Agenten zu beachten?
Lernziele
Nach Abschluss dieser Lektion werden Sie in der Lage sein:
- Das Tool Use Design Pattern und dessen Zweck zu definieren.
- Anwendungsfälle zu identifizieren, in denen das Tool Use Design Pattern angewendet werden kann.
- Die Schlüsselelemente zu verstehen, die zur Implementierung des Design Patterns erforderlich sind.
- Überlegungen zu erkennen, um Vertrauenswürdigkeit bei KI-Agenten zu gewährleisten, die dieses Design Pattern nutzen.
Was ist das Tool Use Design Pattern?
Das Tool Use Design Pattern konzentriert sich darauf, LLMs die Fähigkeit zu geben, mit externen Werkzeugen zu interagieren, um bestimmte Ziele zu erreichen. Werkzeuge sind Code, der von einem Agenten ausgeführt werden kann, um Aktionen durchzuführen. Ein Werkzeug kann eine einfache Funktion wie ein Taschenrechner oder ein API-Aufruf an einen Drittanbieterdienst wie die Abfrage von Aktienkursen oder Wettervorhersagen sein. Im Kontext von KI-Agenten sind Werkzeuge so konzipiert, dass sie von Agenten als Antwort auf modellgenerierte Funktionsaufrufe ausgeführt werden.
Für welche Anwendungsfälle kann es eingesetzt werden?
KI-Agenten können Werkzeuge nutzen, um komplexe Aufgaben zu erledigen, Informationen abzurufen oder Entscheidungen zu treffen. Das Tool Use Design Pattern wird häufig in Szenarien verwendet, die eine dynamische Interaktion mit externen Systemen erfordern, wie Datenbanken, Webdienste oder Code-Interpreter. Diese Fähigkeit ist nützlich für eine Reihe verschiedener Anwendungsfälle, einschließlich:
- Dynamische Informationsbeschaffung: Agenten können externe APIs oder Datenbanken abfragen, um aktuelle Daten zu erhalten (z. B. Abfragen einer SQLite-Datenbank für Datenanalysen, Abrufen von Aktienkursen oder Wetterinformationen).
- Code-Ausführung und Interpretation: Agenten können Code oder Skripte ausführen, um mathematische Probleme zu lösen, Berichte zu erstellen oder Simulationen durchzuführen.
- Automatisierung von Workflows: Automatisierung sich wiederholender oder mehrstufiger Workflows durch Integration von Werkzeugen wie Aufgabenplanern, E-Mail-Diensten oder Datenpipelines.
- Kundensupport: Agenten können mit CRM-Systemen, Ticketplattformen oder Wissensdatenbanken interagieren, um Benutzeranfragen zu lösen.
- Inhaltserstellung und -bearbeitung: Agenten können Werkzeuge wie Grammatikprüfer, Textzusammenfasser oder Bewertungstools für Inhaltsicherheit nutzen, um bei der Inhaltserstellung zu helfen.
Welche Elemente/Bausteine werden benötigt, um das Tool Use Design Pattern umzusetzen?
Diese Bausteine ermöglichen es dem KI-Agenten, eine breite Palette von Aufgaben auszuführen. Schauen wir uns die Schlüsselelemente an, die zur Implementierung des Tool Use Design Pattern benötigt werden:
-
Funktions-/Werkzeugschemata: Detaillierte Definitionen der verfügbaren Werkzeuge, einschließlich Funktionsname, Zweck, erforderliche Parameter und erwartete Ausgaben. Diese Schemata ermöglichen es dem LLM zu verstehen, welche Werkzeuge verfügbar sind und wie gültige Anfragen konstruiert werden.
-
Logik zur Funktionsausführung: Steuert, wie und wann Werkzeuge basierend auf der Absicht des Nutzers und dem Gesprächskontext aufgerufen werden. Dies kann Planermodule, Weiterleitungsmechanismen oder bedingte Abläufe umfassen, die die Werkzeugnutzung dynamisch festlegen.
-
Nachrichtenverwaltungssystem: Komponenten, die den Gesprächsfluss zwischen Benutzereingaben, LLM-Antworten, Werkzeugaufrufen und Werkzeugausgaben verwalten.
-
Werkzeugintegrationsframework: Infrastruktur, die den Agenten mit verschiedenen Werkzeugen verbindet, sei es einfache Funktionen oder komplexe externe Dienste.
-
Fehlerbehandlung & Validierung: Mechanismen zur Handhabung von Fehlern bei der Ausführung von Werkzeugen, Validierung von Parametern und Umgang mit unerwarteten Antworten.
-
Zustandsverwaltung: Verfolgt den Gesprächskontext, vorherige Werkzeuginteraktionen und persistente Daten, um Konsistenz über mehrere Interaktionsrunden hinweg sicherzustellen.
Im Folgenden betrachten wir den Funktions-/Werkzeugaufruf im Detail.
Funktions-/Werkzeugaufruf
Der Funktionsaufruf ist die primäre Methode, mit der wir Large Language Models (LLMs) die Interaktion mit Werkzeugen ermöglichen. Oft werden „Funktion“ und „Werkzeug“ austauschbar verwendet, weil „Funktionen“ (Blöcke wiederverwendbaren Codes) die „Werkzeuge“ sind, die Agenten zur Ausführung von Aufgaben verwenden. Damit der Code einer Funktion aufgerufen werden kann, muss ein LLM die Benutzeranfrage mit der Beschreibung der Funktion abgleichen. Dazu wird ein Schema, das die Beschreibungen aller verfügbaren Funktionen enthält, an das LLM gesendet. Das LLM wählt dann die am besten geeignete Funktion für die Aufgabe aus und gibt deren Namen sowie Argumente zurück. Die ausgewählte Funktion wird aufgerufen, ihre Antwort wird an das LLM zurückgesendet, welches die Informationen nutzt, um auf die Benutzeranfrage zu antworten.
Damit Entwickler den Funktionsaufruf für Agenten implementieren können, benötigen sie:
- Ein LLM-Modell, das Funktionsaufrufe unterstützt
- Ein Schema mit Funktionsbeschreibungen
- Den Code für jede beschriebene Funktion
Nutzen wir das Beispiel, um die aktuelle Uhrzeit in einer Stadt zu ermitteln, um dies zu veranschaulichen:
-
Initialisieren eines LLM, das Funktionsaufrufe unterstützt:
Nicht alle Modelle unterstützen Funktionsaufrufe, daher ist es wichtig zu prüfen, ob das verwendete LLM dies tut. Azure OpenAI unterstützt Funktionsaufrufe. Wir beginnen, indem wir den Azure OpenAI Client initialisieren.
# Initialisieren Sie den Azure OpenAI-Client client = AzureOpenAI( azure_endpoint = os.getenv("AZURE_AI_PROJECT_ENDPOINT"), api_key=os.getenv("AZURE_OPENAI_API_KEY"), api_version="2024-05-01-preview" ) -
Erstellen eines Funktionsschemas:
Als Nächstes definieren wir ein JSON-Schema, das den Funktionsnamen, eine Beschreibung dessen, was die Funktion tut, sowie die Namen und Beschreibungen der Funktionsparameter enthält.
Dieses Schema übergeben wir dann zusammen mit der Benutzeranfrage, die die Uhrzeit in San Francisco abfragt, an den zuvor erstellten Client. Wichtig ist, dass ein Werkzeugaufruf zurückgegeben wird, nicht die finale Antwort auf die Frage. Wie oben erwähnt, gibt das LLM den Namen der Funktion zurück, die es für die Aufgabe ausgewählt hat, und die Argumente, die übergeben werden.# Funktionsbeschreibung für das Modell zum Lesen tools = [ { "type": "function", "function": { "name": "get_current_time", "description": "Get the current time in a given location", "parameters": { "type": "object", "properties": { "location": { "type": "string", "description": "The city name, e.g. San Francisco", }, }, "required": ["location"], }, } } ]# Initiale Benutzeranfrage messages = [{"role": "user", "content": "What's the current time in San Francisco"}] # Erster API-Aufruf: Das Modell auffordern, die Funktion zu verwenden response = client.chat.completions.create( model=deployment_name, messages=messages, tools=tools, tool_choice="auto", ) # Die Antwort des Modells verarbeiten response_message = response.choices[0].message messages.append(response_message) print("Model's response:") print(response_message)Model's response: ChatCompletionMessage(content=None, role='assistant', function_call=None, tool_calls=[ChatCompletionMessageToolCall(id='call_pOsKdUlqvdyttYB67MOj434b', function=Function(arguments='{"location":"San Francisco"}', name='get_current_time'), type='function')]) -
Der erforderliche Funktionscode zur Durchführung der Aufgabe:
Nun, da das LLM entschieden hat, welche Funktion ausgeführt wird, muss der Code, der die Aufgabe durchführt, implementiert und ausgeführt werden.
Wir können den Code zur Ermittlung der aktuellen Uhrzeit in Python implementieren. Außerdem müssen wir den Code schreiben, der aus der response_message den Namen und die Argumente extrahiert, um das Endergebnis zu erhalten.def get_current_time(location): """Get the current time for a given location""" print(f"get_current_time called with location: {location}") location_lower = location.lower() for key, timezone in TIMEZONE_DATA.items(): if key in location_lower: print(f"Timezone found for {key}") current_time = datetime.now(ZoneInfo(timezone)).strftime("%I:%M %p") return json.dumps({ "location": location, "current_time": current_time }) print(f"No timezone data found for {location_lower}") return json.dumps({"location": location, "current_time": "unknown"})# Funktionsaufrufe verarbeiten if response_message.tool_calls: for tool_call in response_message.tool_calls: if tool_call.function.name == "get_current_time": function_args = json.loads(tool_call.function.arguments) time_response = get_current_time( location=function_args.get("location") ) messages.append({ "tool_call_id": tool_call.id, "role": "tool", "name": "get_current_time", "content": time_response, }) else: print("No tool calls were made by the model.") # Zweiter API-Aufruf: Die endgültige Antwort vom Modell erhalten final_response = client.chat.completions.create( model=deployment_name, messages=messages, ) return final_response.choices[0].message.contentget_current_time called with location: San Francisco Timezone found for san francisco The current time in San Francisco is 09:24 AM.
Funktionsaufrufe stehen im Zentrum der meisten, wenn nicht aller Agenten-Werkzeug-Nutzungsdesigns. Die Implementierung von Grund auf kann jedoch manchmal herausfordernd sein.
Wie wir in Lesson 2 gelernt haben, bieten agentische Frameworks vorgefertigte Bausteine zur Implementierung von Werkzeugnutzung.
Beispiele für die Werkzeugnutzung mit agentischen Frameworks
Hier sind einige Beispiele, wie Sie das Tool Use Design Pattern mit verschiedenen agentischen Frameworks implementieren können:
Microsoft Agent Framework
Microsoft Agent Framework ist ein Open-Source-KI-Framework zum Erstellen von KI-Agenten. Es vereinfacht den Prozess der Funktionsaufrufe, indem es erlaubt, Werkzeuge als Python-Funktionen mit dem @tool Dekorator zu definieren. Das Framework übernimmt die hin- und herlaufende Kommunikation zwischen dem Modell und Ihrem Code. Es bietet auch Zugriff auf vorgefertigte Werkzeuge wie Dateisuche und Code Interpreter über den AzureAIProjectAgentProvider.
Das folgende Diagramm veranschaulicht den Ablauf von Funktionsaufrufen mit dem Microsoft Agent Framework:
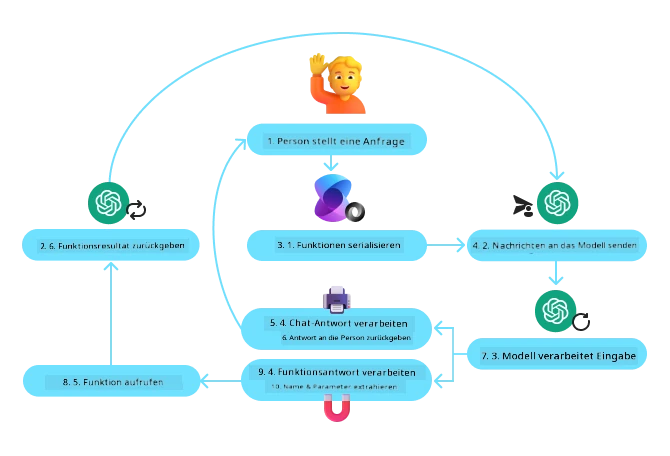
Im Microsoft Agent Framework werden Werkzeuge als dekorierte Funktionen definiert. Die zuvor dargestellte Funktion get_current_time kann in ein Werkzeug umgewandelt werden, indem der @tool Dekorator verwendet wird. Das Framework serialisiert die Funktion und deren Parameter automatisch und erzeugt das Schema, das an das LLM gesendet wird.
from agent_framework import tool
from agent_framework.azure import AzureAIProjectAgentProvider
from azure.identity import AzureCliCredential
@tool
def get_current_time(location: str) -> str:
"""Get the current time for a given location"""
...
# Erstelle den Client
provider = AzureAIProjectAgentProvider(credential=AzureCliCredential())
# Erstelle einen Agenten und führe ihn mit dem Tool aus
agent = await provider.create_agent(name="TimeAgent", instructions="Use available tools to answer questions.", tools=get_current_time)
response = await agent.run("What time is it?")
Azure AI Agent Service
Azure AI Agent Service ist ein neueres agentisches Framework, das Entwicklern ermöglicht, sicher hochwertige und erweiterbare KI-Agenten zu erstellen, bereitzustellen und zu skalieren, ohne die zugrunde liegenden Compute- und Speicherressourcen verwalten zu müssen. Es ist besonders nützlich für Unternehmensanwendungen, da es sich um einen vollständig verwalteten Dienst mit Enterprise-Grade-Sicherheit handelt.
Im Vergleich zur direkten Entwicklung mit der LLM-API bietet der Azure AI Agent Service einige Vorteile, darunter:
- Automatisches Tool-Calling – kein Parsen eines Werkzeugaufrufs, Aufrufen des Werkzeugs und Handhaben der Antwort mehr erforderlich; all das geschieht jetzt serverseitig
- Sicher verwaltete Daten – statt eigene Gesprächszustände zu verwalten, können Threads genutzt werden, um alle benötigten Informationen zu speichern
- Out-of-the-box-Werkzeuge – Werkzeuge, mit denen Sie mit Ihren Datenquellen interagieren können, wie Bing, Azure AI Search und Azure Functions.
Die im Azure AI Agent Service verfügbaren Werkzeuge lassen sich in zwei Kategorien unterteilen:
- Wissenswerkzeuge:
- Aktionswerkzeuge:
Der Agent Service ermöglicht es uns, diese Werkzeuge als toolset gemeinsam zu verwenden. Außerdem nutzt er threads, die den Nachrichtenverlauf eines bestimmten Gesprächs verfolgen.
Stellen Sie sich vor, Sie sind Vertriebsmitarbeiter bei einem Unternehmen namens Contoso. Sie möchten einen Konversationsagenten entwickeln, der Fragen zu Ihren Verkaufsdaten beantworten kann.
Das folgende Bild zeigt, wie Sie den Azure AI Agent Service nutzen könnten, um Ihre Verkaufsdaten zu analysieren:
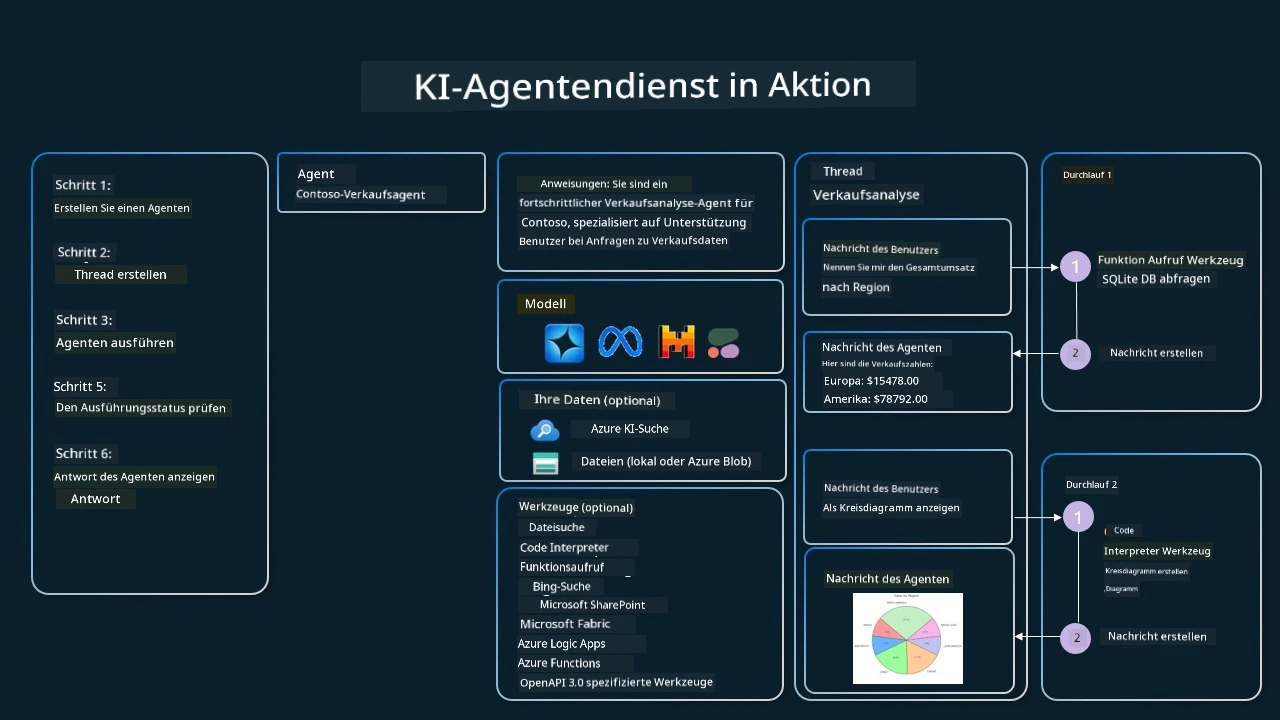
Um eines dieser Werkzeuge mit dem Service zu verwenden, können wir einen Client erstellen und ein Werkzeug oder Werkzeugset definieren. Praktisch können wir dafür den folgenden Python-Code verwenden. Das LLM kann das Werkzeugset betrachten und entscheiden, ob die benutzerdefinierte Funktion fetch_sales_data_using_sqlite_query oder der vorgefertigte Code Interpreter abhängig von der Benutzeranfrage verwendet wird.
import os
from azure.ai.projects import AIProjectClient
from azure.identity import DefaultAzureCredential
from fetch_sales_data_functions import fetch_sales_data_using_sqlite_query # Funktion fetch_sales_data_using_sqlite_query, die in einer Datei fetch_sales_data_functions.py zu finden ist.
from azure.ai.projects.models import ToolSet, FunctionTool, CodeInterpreterTool
project_client = AIProjectClient.from_connection_string(
credential=DefaultAzureCredential(),
conn_str=os.environ["PROJECT_CONNECTION_STRING"],
)
# Toolset initialisieren
toolset = ToolSet()
# Funktionsaufruf-Agent mit der Funktion fetch_sales_data_using_sqlite_query initialisieren und zum Toolset hinzufügen
fetch_data_function = FunctionTool(fetch_sales_data_using_sqlite_query)
toolset.add(fetch_data_function)
# Code Interpreter Tool initialisieren und zum Toolset hinzufügen.
code_interpreter = code_interpreter = CodeInterpreterTool()
toolset.add(code_interpreter)
agent = project_client.agents.create_agent(
model="gpt-4o-mini", name="my-agent", instructions="You are helpful agent",
toolset=toolset
)
Welche besonderen Überlegungen gibt es bei der Verwendung des Tool Use Design Pattern zur Erstellung vertrauenswürdiger KI-Agenten?
Ein häufiges Anliegen bei dynamisch von LLMs generiertem SQL ist die Sicherheit, insbesondere das Risiko von SQL-Injektionen oder böswilligen Aktionen wie dem Löschen oder Manipulieren der Datenbank. Obwohl diese Bedenken berechtigt sind, können sie durch ordnungsgemäße Konfiguration der Datenbankzugriffsrechte effektiv gemindert werden. Für die meisten Datenbanken bedeutet dies, die Datenbank als schreibgeschützt zu konfigurieren. Für Datenbankdienste wie PostgreSQL oder Azure SQL sollte der Anwendung eine schreibgeschützte (SELECT) Rolle zugewiesen werden.
Das Ausführen der Anwendung in einer sicheren Umgebung erhöht den Schutz zusätzlich. In Unternehmensszenarien werden Daten typischerweise aus operativen Systemen extrahiert und in einer schreibgeschützten Datenbank oder einem Data Warehouse mit einem benutzerfreundlichen Schema transformiert. Dieser Ansatz stellt sicher, dass die Daten sicher, für Leistung und Zugänglichkeit optimiert sind und die Anwendung nur eingeschränkten, schreibgeschützten Zugriff hat.
Beispielcodes
- Python: Agent Framework
- .NET: Agent Framework
Noch Fragen zum Tool Use Design Pattern?
Treten Sie dem Microsoft Foundry Discord bei, um andere Lernende zu treffen, an Office Hours teilzunehmen und Ihre Fragen zu KI-Agenten beantwortet zu bekommen.
Zusätzliche Ressourcen
- Azure AI Agents Service Workshop
- Contoso Creative Writer Multi-Agent Workshop
- Microsoft Agent Framework Übersicht
Vorherige Lektion
Verstehen agentischer Design Patterns
Nächste Lektion
Haftungsausschluss:
Dieses Dokument wurde mit dem KI-Übersetzungsdienst Co-op Translator übersetzt. Obwohl wir uns um Genauigkeit bemühen, weisen wir darauf hin, dass maschinelle Übersetzungen Fehler oder Ungenauigkeiten enthalten können. Das Originaldokument in seiner Ausgangssprache ist als maßgebliche Quelle zu betrachten. Für wichtige Informationen wird eine professionelle menschliche Übersetzung empfohlen. Wir übernehmen keine Haftung für Missverständnisse oder Fehlinterpretationen, die aus der Nutzung dieser Übersetzung entstehen.