ai-agents-for-beginners

(برای مشاهده ویدئوی این درس، روی تصویر بالا کلیک کنید)
فراشناخت در عاملهای هوش مصنوعی
مقدمه
به درس فراشناخت در عاملهای هوش مصنوعی خوش آمدید! این فصل برای افراد مبتدی طراحی شده است که کنجکاوند بدانند عاملهای هوش مصنوعی چگونه میتوانند درباره فرایندهای فکری خود فکر کنند. در پایان این درس، مفاهیم کلیدی را درک خواهید کرد و با مثالهای عملی برای به کارگیری فراشناخت در طراحی عاملهای هوش مصنوعی مجهز خواهید شد.
اهداف آموزشی
پس از اتمام این درس، قادر خواهید بود:
- پیامدهای حلقههای استدلالی در تعاریف عامل را درک کنید.
- با استفاده از تکنیکهای برنامهریزی و ارزیابی به عاملهای خوداصلاحگر کمک کنید.
- عاملهای خود را بسازید که قادر به دستکاری کد برای انجام وظایف باشند.
معرفی فراشناخت
فراشناخت به فرایندهای شناختی مرتبه بالا اشاره دارد که شامل تفکر درباره تفکر خود میشود. برای عاملهای هوش مصنوعی، این یعنی توانایی ارزیابی و تنظیم اقدامات خود بر اساس خودآگاهی و تجربیات گذشته. فراشناخت، یا «تفکر درباره تفکر»، مفهومی مهم در توسعه سیستمهای عامل هوشمند است. این شامل آگاهی سیستمهای هوش مصنوعی از فرایندهای درونی خود و توانایی نظارت، تنظیم و انطباق رفتارشان به تناسب میشود. درست مانند وقتی که ما شرایط را ارزیابی میکنیم یا به مسئلهای نگاه میاندازیم. این خودآگاهی میتواند به سیستمهای هوش مصنوعی کمک کند تصمیمات بهتری بگیرند، خطاها را شناسایی کنند و کارایی خود را در طول زمان بهبود بخشند — که دوباره به آزمون تورینگ و بحث درباره این که آیا هوش مصنوعی قرار است کنترل را در دست بگیرد، مرتبط است.
در زمینه سیستمهای عامل هوش مصنوعی، فراشناخت میتواند به رفع چندین چالش کمک کند، مثل:
- شفافیت: تضمین اینکه سیستمهای هوش مصنوعی بتوانند استدلالها و تصمیمات خود را توضیح دهند.
- استدلال: افزایش توانایی سیستمهای هوش مصنوعی در ترکیب اطلاعات و گرفتن تصمیمات منطقی.
- انطباقپذیری: اجازه دادن به سیستمهای هوش مصنوعی برای سازگاری با محیطهای جدید و شرایط متغیر.
- درک: بهبود دقت سیستمهای هوش مصنوعی در شناخت و تفسیر دادهها از محیط خود.
فراشناخت چیست؟
فراشناخت، یا «تفکر درباره تفکر»، فرایند شناختی مرتبه بالایی است که شامل خودآگاهی و خودتنظیمی فرایندهای شناختی فرد میشود. در حوزه هوش مصنوعی، فراشناخت به عاملها این امکان را میدهد که استراتژیها و اقدامات خود را ارزیابی و تعدیل کنند که منجر به بهبود قابلیت حل مسئله و تصمیمگیری میشود. با فهم فراشناخت، میتوانید عاملهای هوش مصنوعی طراحی کنید که نه تنها هوشمندتر، بلکه سازگارتر و کارآمدتر نیز باشند. در فراشناخت واقعی، هوش مصنوعی به طور صریح درباره استدلال خود استدلال میکند.
مثال: «اولویت پروازهای ارزانتر را دادم چون… ممکن است پروازهای مستقیم را از دست بدهم، پس اجازه بده دوباره بررسی کنم.» ردیابی چگونگی یا دلیل انتخاب مسیر خاص.
- توجه به این که اشتباه کرده چون بیش از حد به ترجیحات کاربر از دفعه قبل تکیه کرده، بنابراین استراتژی تصمیمگیری خود را نه فقط توصیه نهایی را تغییر میدهد.
- تشخیص الگوهایی مانند «هر وقت دیدم کاربر از شلوغی زیاد شکایت میکند، نباید فقط برخی جاذبهها را حذف کنم بلکه باید بازتاب دهم که روش من در انتخاب ‘برترین جاذبهها’ اشتباه است اگر همیشه بر اساس محبوبیت رتبهبندی کنم.»
اهمیت فراشناخت در عاملهای هوش مصنوعی
فراشناخت نقش مهمی در طراحی عاملهای هوش مصنوعی دارد به دلایل متعدد:

- خودبازتابی: عاملها میتوانند عملکرد خود را ارزیابی کرده و نقاط قابل بهبود را شناسایی کنند.
- سازگاری: عاملها میتوانند استراتژیهای خود را بر اساس تجربیات گذشته و شرایط متغیر تغییر دهند.
- اصلاح خطا: عاملها میتوانند به صورت خودکار خطاها را شناسایی و تصحیح کنند که منجر به نتایج دقیقتر میشود.
- مدیریت منابع: عاملها میتوانند مصرف منابع مانند زمان و توان محاسباتی را با برنامهریزی و ارزیابی فعالیتهایشان بهینه کنند.
اجزای یک عامل هوش مصنوعی
قبل از ورود به فرایندهای فراشناختی، ضروری است که اجزای پایه یک عامل هوش مصنوعی را بشناسید. یک عامل هوش مصنوعی معمولاً شامل موارد زیر است:
- شخصیت: شخصیت و ویژگیهای عامل که نحوه تعامل آن با کاربران را تعریف میکند.
- ابزارها: قابلیتها و عملکردهایی که عامل میتواند انجام دهد.
- مهارتها: دانش و تخصصی که عامل دارد.
این اجزا با هم کار میکنند تا یک «واحد تخصصی» بسازند که بتواند وظایف خاصی را انجام دهد.
مثال: یک آژانس مسافرتی را در نظر بگیرید، خدمات عاملی که نه تنها تعطیلات شما را برنامهریزی میکند بلکه مسیر خود را بر اساس دادههای بهروز و تجربیات سفر مشتریان قبلی تنظیم میکند.
مثال: فراشناخت در سرویس آژانس مسافرتی
تصور کنید در حال طراحی سرویس آژانس مسافرتی مبتنی بر هوش مصنوعی هستید. این عامل، «آژانس مسافرتی»، به کاربران در برنامهریزی تعطیلات کمک میکند. برای به کارگیری فراشناخت، آژانس مسافرتی باید اقدامات خود را بر اساس خودآگاهی و تجربیات گذشته ارزیابی و تنظیم کند. در اینجا نقش فراشناخت میتواند به شرح زیر باشد:
وظیفه فعلی
وظیفه فعلی کمک به کاربر در برنامهریزی سفری به پاریس است.
مراحل انجام وظیفه
- جمعآوری ترجیحات کاربر: پرسیدن درباره تاریخ سفر، بودجه، علایق (مثلاً موزهها، غذا، خرید) و هر نیاز خاصی.
- بازیابی اطلاعات: جستجو برای گزینههای پرواز، محل اقامت، جاذبهها و رستورانها که با ترجیحات کاربر مطابقت دارند.
- تولید پیشنهادات: ارائه برنامه سفر شخصیسازی شده با جزئیات پرواز، رزرو هتل و فعالیتهای پیشنهادی.
- تنظیم بر اساس بازخورد: گرفتن بازخورد کاربر درباره پیشنهادات و ایجاد تغییرات لازم.
منابع مورد نیاز
- دسترسی به پایگاههای داده پرواز و رزرو هتل.
- اطلاعات در مورد جاذبهها و رستورانهای پاریس.
- دادههای بازخورد کاربر از تعاملات قبلی.
تجربه و خودبازتابی
آژانس مسافرتی از فراشناخت برای ارزیابی عملکرد و یادگیری از تجربیات گذشته استفاده میکند. به عنوان مثال:
- تحلیل بازخورد کاربر: آژانس بازخورد کاربر را بررسی میکند تا ببیند کدام پیشنهادها مورد پسند قرار گرفته و کدام نه. سپس پیشنهادات آیندهاش را متناسب تنظیم میکند.
- سازگاری: اگر کاربر قبلاً از مکانهای شلوغ خوشش نیامده، آژانس مسافرتی در آینده از پیشنهاد مکانهای توریستی محبوب در ساعات اوج خودداری خواهد کرد.
- اصلاح خطا: اگر آژانس مسافرتی در رزرو قبلی اشتباهی کرده باشد، مثل پیشنهاد هتلی که کامل بوده، یاد میگیرد که قبل از ارائه پیشنهادات، در دسترس بودن را دقیقتر بررسی کند.
مثال عملی برای توسعهدهنده
در اینجا نمونه کدی سادهشده از چگونگی بهکارگیری فراشناخت در کد آژانس مسافرتی آمده است:
class Travel_Agent:
def __init__(self):
self.user_preferences = {}
self.experience_data = []
def gather_preferences(self, preferences):
self.user_preferences = preferences
def retrieve_information(self):
# جستجوی پروازها، هتلها و دیدنیها بر اساس ترجیحات
flights = search_flights(self.user_preferences)
hotels = search_hotels(self.user_preferences)
attractions = search_attractions(self.user_preferences)
return flights, hotels, attractions
def generate_recommendations(self):
flights, hotels, attractions = self.retrieve_information()
itinerary = create_itinerary(flights, hotels, attractions)
return itinerary
def adjust_based_on_feedback(self, feedback):
self.experience_data.append(feedback)
# تحلیل بازخورد و تنظیم توصیههای آینده
self.user_preferences = adjust_preferences(self.user_preferences, feedback)
# نمونه استفاده
travel_agent = Travel_Agent()
preferences = {
"destination": "Paris",
"dates": "2025-04-01 to 2025-04-10",
"budget": "moderate",
"interests": ["museums", "cuisine"]
}
travel_agent.gather_preferences(preferences)
itinerary = travel_agent.generate_recommendations()
print("Suggested Itinerary:", itinerary)
feedback = {"liked": ["Louvre Museum"], "disliked": ["Eiffel Tower (too crowded)"]}
travel_agent.adjust_based_on_feedback(feedback)
چرا فراشناخت مهم است
- خودبازتابی: عاملها میتوانند عملکرد خود را تحلیل کرده و نقاط قابل بهبود را شناسایی کنند.
- سازگاری: عاملها میتوانند استراتژیها را بر اساس بازخورد و شرایط متغیر تغییر دهند.
- اصلاح خطا: عاملها میتوانند به طور خودکار خطاها را شناسایی و اصلاح کنند.
- مدیریت منابع: عاملها میتوانند استفاده از منابع مانند زمان و توان محاسباتی را بهینه کنند.
با بهکارگیری فراشناخت، آژانس مسافرتی میتواند پیشنهادهای سفر شخصیتر و دقیقتری ارائه دهد و تجربه کلی کاربر را بهبود بخشد.
۲. برنامهریزی در عاملها
برنامهریزی جزء حیاتی رفتار عامل هوش مصنوعی است. این امر شامل تعیین مراحل لازم برای رسیدن به هدف، در نظر گرفتن وضعیت فعلی، منابع و موانع ممکن است.
عناصر برنامهریزی
- وظیفه فعلی: تعریف دقیق وظیفه.
- مراحل انجام وظیفه: شکستن وظیفه به مراحل قابل مدیریت.
- منابع مورد نیاز: شناسایی منابع ضروری.
- تجربه: استفاده از تجربیات گذشته برای اطلاعرسانی به برنامهریزی.
مثال: در اینجا مراحل مورد نیاز آژانس مسافرتی برای کمک به کاربر در برنامهریزی سفر آمده است:
مراحل آژانس مسافرتی
- جمعآوری ترجیحات کاربر
- از کاربر پرسشهایی درباره تاریخ سفر، بودجه، علاقهمندیها و هر نیاز خاص بپرسید.
- مثال: «چه زمانی قصد سفر دارید؟» «بودجه شما چقدر است؟» «چه فعالیتهایی در تعطیلات دوست دارید؟»
- بازیابی اطلاعات
- جستجوی گزینههای سفر مرتبط بر اساس ترجیحات کاربر.
- پروازها: جستجو برای پروازهای موجود در محدوده بودجه و تاریخ مورد نظر.
- محل اقامت: یافتن هتل یا اقامتگاههایی که با ترجیحات کاربر درباره مکان، قیمت و امکانات مطابقت دارد.
- جاذبهها و رستورانها: شناسایی جاذبهها، فعالیتها و گزینههای غذایی محبوب که مطابق با علاقهمندیهای کاربر باشد.
- تولید پیشنهادات
- اطلاعات بازیابیشده را به یک برنامه سفر شخصیشده تبدیل کنید.
- ارائه جزئیاتی مانند گزینههای پرواز، رزرو هتل و فعالیتهای پیشنهادی، با توجه به ترجیحات کاربر.
- ارائه برنامه سفر به کاربر
- برنامه پیشنهادی را برای بازبینی به کاربر ارائه دهید.
- مثال: «این یک برنامه پیشنهادی برای سفر شما به پاریس است. شامل جزئیات پرواز، رزرو هتل و فهرستی از فعالیتها و رستورانهای پیشنهادی است. نظرتان چیست؟»
- جمعآوری بازخورد
- از کاربر بازخورد درباره برنامه پیشنهادی درخواست کنید.
- مثال: «آیا پروازهای پیشنهادی را میپسندید؟» «آیا هتل برای نیازهای شما مناسب است؟» «آیا فعالیتهایی هست که بخواهید به برنامه اضافه یا حذف شود؟»
- تنظیم برنامه بر اساس بازخورد
- برنامه را بر اساس نظرات کاربر اصلاح کنید.
- تغییرات لازم در پرواز، محل اقامت و فعالیتها را اعمال کنید تا بهتر با ترجیحات کاربر مطابقت داشته باشد.
- تأیید نهایی
- برنامه بهروز شده را برای تأیید نهایی به کاربر ارائه دهید.
- مثال: «بر اساس بازخورد شما تغییرات را اعمال کردم. این برنامه بهروزشده است. همه چیز مورد قبول است؟»
- رزرو و تأیید
- پس از تأیید کاربر، پروازها، محل اقامت و فعالیتهای پیشبرنامهریزیشده را رزرو کنید.
- جزئیات تأیید را به کاربر ارسال کنید.
- ارائه پشتیبانی مداوم
- در طول سفر و قبل از آن برای کمک به هر گونه تغییر یا درخواست اضافه در دسترس باشید.
- مثال: «اگر در طول سفر نیاز به کمک بیشتری داشتید، هر زمان میتوانید با من تماس بگیرید!»
نمونه تعامل
class Travel_Agent:
def __init__(self):
self.user_preferences = {}
self.experience_data = []
def gather_preferences(self, preferences):
self.user_preferences = preferences
def retrieve_information(self):
flights = search_flights(self.user_preferences)
hotels = search_hotels(self.user_preferences)
attractions = search_attractions(self.user_preferences)
return flights, hotels, attractions
def generate_recommendations(self):
flights, hotels, attractions = self.retrieve_information()
itinerary = create_itinerary(flights, hotels, attractions)
return itinerary
def adjust_based_on_feedback(self, feedback):
self.experience_data.append(feedback)
self.user_preferences = adjust_preferences(self.user_preferences, feedback)
# استفاده نمونه در یک درخواست بوکینگ
travel_agent = Travel_Agent()
preferences = {
"destination": "Paris",
"dates": "2025-04-01 to 2025-04-10",
"budget": "moderate",
"interests": ["museums", "cuisine"]
}
travel_agent.gather_preferences(preferences)
itinerary = travel_agent.generate_recommendations()
print("Suggested Itinerary:", itinerary)
feedback = {"liked": ["Louvre Museum"], "disliked": ["Eiffel Tower (too crowded)"]}
travel_agent.adjust_based_on_feedback(feedback)
۳. سیستم تصحیحی RAG
ابتدا بیایید تفاوت بین ابزار RAG و بارگذاری پیشگیرانه زمینه را درک کنیم.
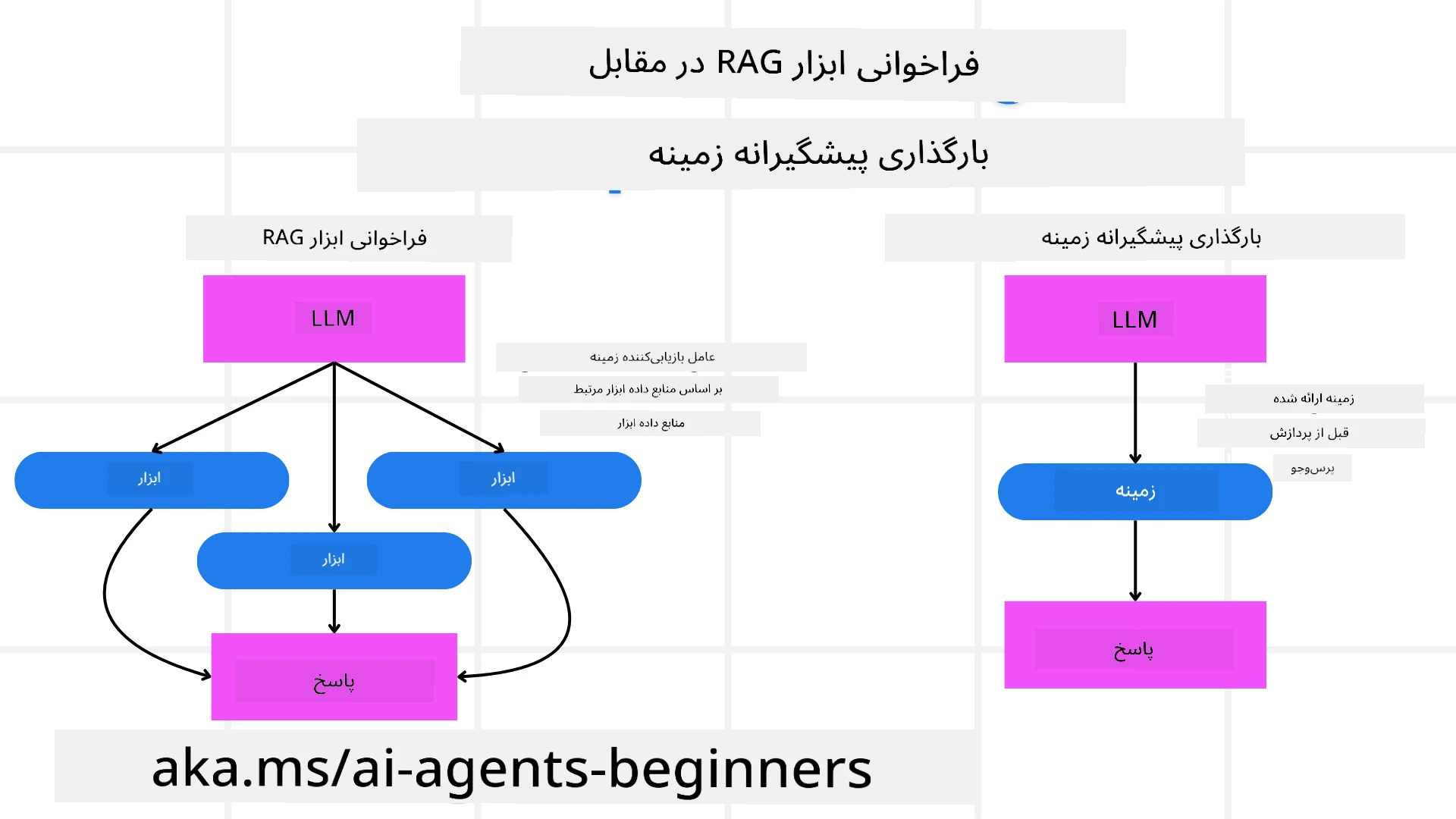
تولید افزوده شده با بازیابی (RAG)
RAG ترکیبی از سیستم بازیابی و مدل مولد است. وقتی پرسشی مطرح میشود، سیستم بازیابی مدارک یا دادههای مرتبط را از منبع خارجی دریافت میکند و این اطلاعات بازیابیشده به ورودی مدل مولد افزوده میشود. این به مدل کمک میکند تا پاسخهای دقیقتر و مرتبطتر با زمینه تولید کند.
در یک سیستم RAG، عامل اطلاعات مرتبط را از یک پایگاه دانش بازیابی کرده و از آن برای تولید پاسخها یا اقدامات مناسب استفاده میکند.
رویکرد اصلاحی RAG
رویکرد اصلاحی RAG بر استفاده از تکنیکهای RAG برای اصلاح خطاها و بهبود دقت عاملهای هوش مصنوعی تمرکز دارد. این شامل:
- تکنیک تحریک: استفاده از فرمانهای خاص برای هدایت عامل در بازیابی اطلاعات مرتبط.
- ابزار: پیادهسازی الگوریتمها و مکانیزمهایی که به عامل امکان ارزیابی مرتبط بودن اطلاعات بازیابی شده و تولید پاسخهای دقیق را میدهد.
- ارزیابی: ارزیابی مداوم عملکرد عامل و ایجاد تنظیمات برای بهبود دقت و کارایی آن.
مثال: RAG اصلاحی در عامل جستجو
عامل جستجویی را فرض کنید که اطلاعات را از وب برای پاسخ به پرسشهای کاربران بازیابی میکند. رویکرد اصلاحی RAG ممکن است شامل:
- تکنیک تحریک: فرموله کردن پرسشهای جستجو براساس ورودی کاربر.
- ابزار: استفاده از پردازش زبان طبیعی و الگوریتمهای یادگیری ماشینی برای رتبهبندی و فیلتر کردن نتایج جستجو.
- ارزیابی: تحلیل بازخورد کاربر برای شناسایی و اصلاح عدم دقتهای اطلاعات بازیابی شده.
RAG اصلاحی در آژانس مسافرتی
RAG اصلاحی (تولید افزوده شده با بازیابی) توانایی هوش مصنوعی را در بازیابی و تولید اطلاعات افزایش میدهد و خطاها را اصلاح میکند. بیایید ببینیم آژانس مسافرتی چگونه میتواند از رویکرد RAG اصلاحی برای ارائه پیشنهادهای سفر دقیقتر و مرتبطتر استفاده کند.
این شامل:
- تکنیک تحریک: استفاده از فرمانهای خاص برای هدایت عامل در بازیابی اطلاعات مرتبط.
- ابزار: پیادهسازی الگوریتمها و مکانیزمهایی که امکان ارزیابی مرتبط بودن اطلاعات بازیابی شده و تولید پاسخهای دقیق را به عامل میدهد.
- ارزیابی: ارزیابی مداوم عملکرد عامل و ایجاد تنظیمات برای ارتقاء دقت و کارایی.
مراحل پیادهسازی RAG اصلاحی در آژانس مسافرتی
- تعامل اولیه با کاربر
- آژانس مسافرتی ترجیحات اولیه کاربر مانند مقصد، تاریخ سفر، بودجه و علاقهمندیها را جمعآوری میکند.
-
مثال:
preferences = { "destination": "Paris", "dates": "2025-04-01 to 2025-04-10", "budget": "moderate", "interests": ["museums", "cuisine"] }
- بازیابی اطلاعات
- آژانس مسافرتی اطلاعات پرواز، اقامت، جاذبهها و رستورانها را بر اساس ترجیحات کاربر بازیابی میکند.
-
مثال:
flights = search_flights(preferences) hotels = search_hotels(preferences) attractions = search_attractions(preferences)
- تولید پیشنهادات اولیه
- آژانس مسافرتی از اطلاعات بازیابی شده برای ایجاد یک برنامه سفر شخصیسازی شده استفاده میکند.
-
مثال:
itinerary = create_itinerary(flights, hotels, attractions) print("Suggested Itinerary:", itinerary)
- جمعآوری بازخورد کاربر
- آژانس مسافرتی بازخورد کاربر درباره پیشنهادات اولیه را دریافت میکند.
-
مثال:
feedback = { "liked": ["Louvre Museum"], "disliked": ["Eiffel Tower (too crowded)"] }
- فرایند RAG اصلاحی
- تکنیک تحریک: آژانس مسافرتی پرسشهای جستجوی جدید را بر اساس بازخورد کاربر فرموله میکند.
-
مثال:
if "disliked" in feedback: preferences["avoid"] = feedback["disliked"]
-
- ابزار: آژانس مسافرتی از الگوریتمها برای رتبهبندی و فیلتر کردن نتایج جستجوی جدید استفاده میکند و مرتبط بودن را بر اساس بازخورد کاربر تأکید میکند.
-
مثال:
new_attractions = search_attractions(preferences) new_itinerary = create_itinerary(flights, hotels, new_attractions) print("Updated Itinerary:", new_itinerary)
-
- ارزیابی: آژانس مسافرتی به طور مداوم مرتبط بودن و دقت پیشنهادات خود را با تحلیل بازخورد کاربر ارزیابی کرده و تنظیمات لازم را انجام میدهد.
-
مثال:
def adjust_preferences(preferences, feedback): if "liked" in feedback: preferences["favorites"] = feedback["liked"] if "disliked" in feedback: preferences["avoid"] = feedback["disliked"] return preferences preferences = adjust_preferences(preferences, feedback)
-
- تکنیک تحریک: آژانس مسافرتی پرسشهای جستجوی جدید را بر اساس بازخورد کاربر فرموله میکند.
مثال عملی
در اینجا نمونه کد سادهای از پایتون که رویکرد RAG اصلاحی را در آژانس مسافرتی پیادهسازی میکند آمده است:
class Travel_Agent:
def __init__(self):
self.user_preferences = {}
self.experience_data = []
def gather_preferences(self, preferences):
self.user_preferences = preferences
def retrieve_information(self):
flights = search_flights(self.user_preferences)
hotels = search_hotels(self.user_preferences)
attractions = search_attractions(self.user_preferences)
return flights, hotels, attractions
def generate_recommendations(self):
flights, hotels, attractions = self.retrieve_information()
itinerary = create_itinerary(flights, hotels, attractions)
return itinerary
def adjust_based_on_feedback(self, feedback):
self.experience_data.append(feedback)
self.user_preferences = adjust_preferences(self.user_preferences, feedback)
new_itinerary = self.generate_recommendations()
return new_itinerary
# نمونه استفاده
travel_agent = Travel_Agent()
preferences = {
"destination": "Paris",
"dates": "2025-04-01 to 2025-04-10",
"budget": "moderate",
"interests": ["museums", "cuisine"]
}
travel_agent.gather_preferences(preferences)
itinerary = travel_agent.generate_recommendations()
print("Suggested Itinerary:", itinerary)
feedback = {"liked": ["Louvre Museum"], "disliked": ["Eiffel Tower (too crowded)"]}
new_itinerary = travel_agent.adjust_based_on_feedback(feedback)
print("Updated Itinerary:", new_itinerary)
بارگذاری پیشگیرانه زمینه
بارگذاری پیشدستانهٔ زمینه شامل بارگذاری اطلاعات مرتبط یا اطلاعات پسزمینه در مدل پیش از پردازش یک پرسش است. این به این معنی است که مدل از ابتدا به این اطلاعات دسترسی دارد، که میتواند به آن کمک کند تا پاسخهای آگاهانهتری تولید کند بدون نیاز به واکشی دادههای اضافی در طول فرایند.
مثالی سادهشده از چگونگی بارگذاری پیشدستانهٔ زمینه برای یک برنامهٔ کارگزار سفر به زبان پایتون:
class TravelAgent:
def __init__(self):
# بارگذاری پیشفرض مقاصد محبوب و اطلاعات آنها
self.context = {
"Paris": {"country": "France", "currency": "Euro", "language": "French", "attractions": ["Eiffel Tower", "Louvre Museum"]},
"Tokyo": {"country": "Japan", "currency": "Yen", "language": "Japanese", "attractions": ["Tokyo Tower", "Shibuya Crossing"]},
"New York": {"country": "USA", "currency": "Dollar", "language": "English", "attractions": ["Statue of Liberty", "Times Square"]},
"Sydney": {"country": "Australia", "currency": "Dollar", "language": "English", "attractions": ["Sydney Opera House", "Bondi Beach"]}
}
def get_destination_info(self, destination):
# واکشی اطلاعات مقصد از زمینه بارگذاری شده قبلی
info = self.context.get(destination)
if info:
return f"{destination}:\nCountry: {info['country']}\nCurrency: {info['currency']}\nLanguage: {info['language']}\nAttractions: {', '.join(info['attractions'])}"
else:
return f"Sorry, we don't have information on {destination}."
# مثال استفاده
travel_agent = TravelAgent()
print(travel_agent.get_destination_info("Paris"))
print(travel_agent.get_destination_info("Tokyo"))
توضیح
-
مقدارسازی اولیه (متد
__init__): کلاسTravelAgentیک دیکشنری شامل اطلاعات مقصدهای محبوب مانند پاریس، توکیو، نیویورک و سیدنی را پیشبارگذاری میکند. این دیکشنری شامل جزئیاتی مانند کشور، ارز، زبان و جاذبههای اصلی برای هر مقصد است. -
بازیابی اطلاعات (متد
get_destination_info): هنگام پرسش کاربر دربارهٔ یک مقصد خاص، متدget_destination_infoاطلاعات مرتبط را از دیکشنری زمینهٔ پیشبارگذاریشده دریافت میکند.
با پیشبارگذاری زمینه، برنامهٔ کارگزار سفر میتواند سریعتر به پرسشهای کاربران پاسخ دهد بدون نیاز به واکشی اطلاعات از یک منبع خارجی در زمان واقعی. این باعث میشود برنامه کاراتر و پاسخگوتر باشد.
شروع برنامه با هدف پیش از تکرار
شروع برنامه با یک هدف یعنی داشتن یک هدف یا نتیجهٔ مشخص و واضح در ذهن. با تعریف این هدف از ابتدا، مدل میتواند آن را به عنوان اصل راهنما در کل فرایند تکراری به کار گیرد. این کمک میکند که هر تکرار به سمت رسیدن به نتیجهٔ مطلوب پیش برود و فرایند کاراتر و متمرکزتر شود.
مثالی از چگونگی شروع برنامه سفر با یک هدف پیش از تکرار برای یک کارگزار سفر به زبان پایتون:
سناریو
یک کارگزار سفر میخواهد تعطیلاتی سفارشی برای یک مشتری برنامهریزی کند. هدف ایجاد یک برنامه سفر است که رضایت مشتری را بر اساس ترجیحات و بودجهٔ او به حداکثر برساند.
مراحل
- تعریف ترجیحات و بودجهٔ مشتری.
- شروع برنامه اولیه بر اساس این ترجیحات.
- تکرار برای بهبود برنامه و بهینهسازی رضایت مشتری.
کد پایتون
class TravelAgent:
def __init__(self, destinations):
self.destinations = destinations
def bootstrap_plan(self, preferences, budget):
plan = []
total_cost = 0
for destination in self.destinations:
if total_cost + destination['cost'] <= budget and self.match_preferences(destination, preferences):
plan.append(destination)
total_cost += destination['cost']
return plan
def match_preferences(self, destination, preferences):
for key, value in preferences.items():
if destination.get(key) != value:
return False
return True
def iterate_plan(self, plan, preferences, budget):
for i in range(len(plan)):
for destination in self.destinations:
if destination not in plan and self.match_preferences(destination, preferences) and self.calculate_cost(plan, destination) <= budget:
plan[i] = destination
break
return plan
def calculate_cost(self, plan, new_destination):
return sum(destination['cost'] for destination in plan) + new_destination['cost']
# نمونه استفاده
destinations = [
{"name": "Paris", "cost": 1000, "activity": "sightseeing"},
{"name": "Tokyo", "cost": 1200, "activity": "shopping"},
{"name": "New York", "cost": 900, "activity": "sightseeing"},
{"name": "Sydney", "cost": 1100, "activity": "beach"},
]
preferences = {"activity": "sightseeing"}
budget = 2000
travel_agent = TravelAgent(destinations)
initial_plan = travel_agent.bootstrap_plan(preferences, budget)
print("Initial Plan:", initial_plan)
refined_plan = travel_agent.iterate_plan(initial_plan, preferences, budget)
print("Refined Plan:", refined_plan)
توضیح کد
-
مقدارسازی اولیه (متد
__init__): کلاسTravelAgentبا لیستی از مقصدهای بالقوه شامل ویژگیهایی مانند نام، هزینه و نوع فعالیت مقداردهی اولیه میشود. -
شروع برنامه (متد
bootstrap_plan): این متد برنامه شروع سفر را بر اساس ترجیحات و بودجهٔ مشتری میسازد. لیست مقصدها را پیمایش میکند و اگر مقصد با ترجیحات مشتری مطابق باشد و در بودجه بگنجد، آن را به برنامه اضافه میکند. -
مطابقت ترجیحات (متد
match_preferences): این متد بررسی میکند که آیا مقصد با ترجیحات مشتری منطبق است یا نه. -
تکرار برنامه (متد
iterate_plan): این متد برنامه اولیه را اصلاح میکند و با تلاش برای جایگزینی هر مقصد با گزینهای بهتر، با در نظر گرفتن ترجیحات مشتری و محدودیتهای بودجهای. -
محاسبه هزینه (متد
calculate_cost): این متد هزینه کل برنامه کنونی، شامل یک مقصد جدید احتمالی را محاسبه میکند.
کاربرد نمونه
- برنامه اولیه: کارگزار سفر یک برنامه اولیه بر اساس ترجیحات مشتری برای بازدید از جاذبهها و بودجه ۲۰۰۰ دلار ایجاد میکند.
- برنامه اصلاحشده: کارگزار سفر برنامه را بهینه میکند و بر اساس ترجیحات و بودجه مشتری آن را تکرار میکند.
با شروع برنامه با هدفی روشن (مثلاً به حداکثر رساندن رضایت مشتری) و تکرار برای بهبود برنامه، کارگزار سفر میتواند یک برنامه سفر سفارشی و بهینهشده برای مشتری ایجاد کند. این رویکرد تضمین میکند که برنامه سفر از ابتدا با ترجیحات و بودجه مشتری هماهنگ باشد و با هر تکرار بهبود یابد.
بهرهگیری از مدلهای زبانی بزرگ (LLM) برای رتبهبندی مجدد و امتیازدهی
مدلهای زبان بزرگ (LLM) میتوانند برای رتبهبندی مجدد و امتیازدهی با ارزیابی میزان ارتباط و کیفیت اسناد بازیابیشده یا پاسخهای تولیدشده استفاده شوند. عملکرد این روش به شرح زیر است:
بازیابی: مرحلهٔ اولیه واکشی، مجموعهای از اسناد یا پاسخهای نامزد را بر اساس پرسش دریافت میکند.
رتبهبندی مجدد: LLM این نامزدها را ارزیابی کرده و بر اساس ارتباط و کیفیتشان رتبهبندی مجدد انجام میدهد. این مرحله تضمین میکند که مرتبطترین و باکیفیتترین اطلاعات ابتدا ارائه شوند.
امتیازدهی: LLM به هر نامزد امتیاز میدهد که بازتابدهندهٔ ارتباط و کیفیت آن است. این به انتخاب بهترین پاسخ یا سند برای کاربر کمک میکند.
با استفاده از LLM برای رتبهبندی مجدد و امتیازدهی، سیستم میتواند اطلاعات دقیقتر و مرتبطتری ارائه دهد و تجربهٔ کلی کاربر را بهبود بخشد.
در اینجا مثالی از چگونگی استفادهٔ یک کارگزار سفر از مدل زبان بزرگ (LLM) برای رتبهبندی مجدد و امتیازدهی مقصدهای سفر بر اساس ترجیحات کاربر به زبان پایتون:
سناریو - سفر بر اساس ترجیحات
کارگزار سفر میخواهد بهترین مقصدهای سفر را بر اساس ترجیحات مشتری پیشنهاد دهد. LLM به رتبهبندی مجدد و امتیازدهی مقصدها کمک میکند تا مرتبطترین گزینهها ارائه شوند.
مراحل:
- جمعآوری ترجیحات کاربر.
- بازیابی فهرستی از مقصدهای سفر احتمالی.
- استفاده از LLM برای رتبهبندی مجدد و امتیازدهی مقصدها بر اساس ترجیحات کاربر.
در اینجا نحوه بهروزرسانی مثال قبلی برای استفاده از Azure OpenAI Services آمده است:
پیشنیازها
- داشتن اشتراک Azure.
- ایجاد منبع Azure OpenAI و دریافت کلید API.
مثال کد پایتون
import requests
import json
class TravelAgent:
def __init__(self, destinations):
self.destinations = destinations
def get_recommendations(self, preferences, api_key, endpoint):
# تولید یک درخواست برای Azure OpenAI
prompt = self.generate_prompt(preferences)
# تعریف هدرها و محتویات درخواست
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {api_key}'
}
payload = {
"prompt": prompt,
"max_tokens": 150,
"temperature": 0.7
}
# فراخوانی API Azure OpenAI برای دریافت مقصدهای رتبهبندی شده و امتیازدهی شده
response = requests.post(endpoint, headers=headers, json=payload)
response_data = response.json()
# استخراج و بازگرداندن پیشنهادها
recommendations = response_data['choices'][0]['text'].strip().split('\n')
return recommendations
def generate_prompt(self, preferences):
prompt = "Here are the travel destinations ranked and scored based on the following user preferences:\n"
for key, value in preferences.items():
prompt += f"{key}: {value}\n"
prompt += "\nDestinations:\n"
for destination in self.destinations:
prompt += f"- {destination['name']}: {destination['description']}\n"
return prompt
# نمونه استفاده
destinations = [
{"name": "Paris", "description": "City of lights, known for its art, fashion, and culture."},
{"name": "Tokyo", "description": "Vibrant city, famous for its modernity and traditional temples."},
{"name": "New York", "description": "The city that never sleeps, with iconic landmarks and diverse culture."},
{"name": "Sydney", "description": "Beautiful harbour city, known for its opera house and stunning beaches."},
]
preferences = {"activity": "sightseeing", "culture": "diverse"}
api_key = 'your_azure_openai_api_key'
endpoint = 'https://your-endpoint.com/openai/deployments/your-deployment-name/completions?api-version=2022-12-01'
travel_agent = TravelAgent(destinations)
recommendations = travel_agent.get_recommendations(preferences, api_key, endpoint)
print("Recommended Destinations:")
for rec in recommendations:
print(rec)
توضیح کد - رزروکننده ترجیحات
-
مقدارسازی اولیه: کلاس
TravelAgentبا لیستی از مقصدهای سفر احتمالی مقداردهی میشود که هر کدام ویژگیهایی مانند نام و توضیح دارند. -
دریافت توصیهها (متد
get_recommendations): این متد بر اساس ترجیحات کاربر پرامپتی برای سرویس Azure OpenAI تولید کرده و با ارسال درخواست HTTP POST به API Azure OpenAI، مقصدهای رتبهبندیشده و امتیازدهیشده را دریافت میکند. -
ایجاد پرامپت (متد
generate_prompt): این متد پرامپتی برای Azure OpenAI میسازد که شامل ترجیحات کاربر و فهرست مقصدهاست. پرامپت مدل را راهنمایی میکند تا مقصدها را بر اساس ترجیحات ارائهشده رتبهبندی و امتیازدهی کند. -
فراخوانی API: کتابخانهٔ
requestsبرای ارسال درخواست HTTP POST به نقطه پایانی API Azure OpenAI استفاده میشود. پاسخ شامل مقصدهای رتبهبندی و امتیازدهی شده است. -
مثال کاربردی: کارگزار سفر ترجیحات کاربر (مثلاً علاقه به بازدید از جاذبهها و فرهنگ متنوع) را جمعآوری کرده و با استفاده از سرویس Azure OpenAI، توصیههای رتبهبندیشده و امتیازدهیشده برای مقصدهای سفر میگیرد.
حتماً your_azure_openai_api_key را با کلید واقعی API Azure OpenAI خود و https://your-endpoint.com/... را با نشانی واقعی نقطه پایانی استقرار Azure OpenAI جایگزین کنید.
با بهرهگیری از LLM برای رتبهبندی مجدد و امتیازدهی، کارگزار سفر میتواند پیشنهادهای سفری شخصیسازی شده و مرتبطتر به مشتریان ارائه دهد و تجربه کلی آنها را بهبود بخشد.
RAG: تکنیک پرامپتینگ در مقابل ابزار
تولید بازیابیافزوده (Retrieval-Augmented Generation یا RAG) هم میتواند یک تکنیک پرامپتینگ و هم یک ابزار در توسعهٔ عاملهای هوش مصنوعی باشد. شناخت تفاوت این دو به شما کمک میکند RAG را مؤثرتر در پروژههای خود به کار برید.
RAG به عنوان تکنیک پرامپتینگ
چیست؟
- به عنوان تکنیک پرامپتینگ، RAG شامل فرمولبندی پرسشها یا پرامپتهای مشخص برای راهنمایی واکشی اطلاعات مرتبط از یک مجموعه بزرگ یا پایگاه داده است. این اطلاعات سپس برای تولید پاسخ یا اقدام به کار گرفته میشود.
چگونه کار میکند:
- فرمولبندی پرامپتها: ایجاد پرامپتها یا پرسشهای ساختارمند بر اساس وظیفه یا ورودی کاربر.
- واکنش اطلاعات: استفاده از پرامپتها برای جستجوی دادههای مرتبط از یک پایگاه دانش یا مجموعه داده موجود.
- تولید پاسخ: ترکیب اطلاعات بازیابیشده با مدلهای AI تولیدی برای ایجاد پاسخ جامع و منسجم.
مثال در کارگزار سفر:
- ورودی کاربر: «میخواهم از موزههای پاریس بازدید کنم.»
- پرامپت: «موزههای برتر پاریس را پیدا کن.»
- اطلاعات بازیابیشده: جزئیاتی درباره موزه لوور، موزه اورسی و غیره.
- پاسخ تولیدشده: «در اینجا چند موزه برتر در پاریس وجود دارد: موزه لوور، موزه اورسی و مرکز پمپیدو.»
RAG به عنوان ابزار
چیست؟
- به عنوان ابزار، RAG یک سیستم یکپارچه است که فرایند واکشی و تولید را به طور خودکار انجام میدهد و کار را برای توسعهدهندگان آسانتر میکند تا قابلیتهای پیچیده AI را بدون ساختن دستی پرامپت برای هر پرسش اجرا کنند.
چگونه کار میکند:
- یکپارچهسازی: تعبیه RAG در معماری عامل هوش مصنوعی که به صورت خودکار وظایف واکشی و تولید را انجام میدهد.
- خودکارسازی: ابزار کل فرایند، از دریافت ورودی کاربر تا تولید پاسخ نهایی را مدیریت میکند بدون نیاز به پرامپتهای صریح در هر مرحله.
- کارآمدی: عملکرد عامل را با سادهسازی فرایند واکشی و تولید بهبود میبخشد و پاسخهای سریعتر و دقیقتری ارائه میدهد.
مثال در کارگزار سفر:
- ورودی کاربر: «میخواهم از موزههای پاریس بازدید کنم.»
- ابزار RAG: به طور خودکار اطلاعات موزهها را واکشی میکند و پاسخ تولید میکند.
- پاسخ تولیدشده: «در اینجا چند موزه برتر در پاریس وجود دارد: موزه لوور، موزه اورسی و مرکز پمپیدو.»
مقایسه
| جنبه | تکنیک پرامپتینگ | ابزار |
|---|---|---|
| دستی در مقابل خودکار | فرمولبندی دستی پرامپت برای هر پرسش. | فرایند خودکار برای واکشی و تولید. |
| کنترل | کنترل بیشتر بر فرآیند واکشی. | سادهسازی و خودکارسازی واکشی و تولید. |
| انعطافپذیری | امکان پرامپتهای سفارشی بر اساس نیازهای خاص. | مؤثرتر برای پیادهسازیهای در مقیاس بزرگ. |
| پیچیدگی | نیاز به ساخت و تنظیم پرامپتها. | آسانتر برای یکپارچهسازی در معماری عامل هوش مصنوعی. |
مثالهای عملی
مثال تکنیک پرامپتینگ:
def search_museums_in_paris():
prompt = "Find top museums in Paris"
search_results = search_web(prompt)
return search_results
museums = search_museums_in_paris()
print("Top Museums in Paris:", museums)
مثال ابزار:
class Travel_Agent:
def __init__(self):
self.rag_tool = RAGTool()
def get_museums_in_paris(self):
user_input = "I want to visit museums in Paris."
response = self.rag_tool.retrieve_and_generate(user_input)
return response
travel_agent = Travel_Agent()
museums = travel_agent.get_museums_in_paris()
print("Top Museums in Paris:", museums)
ارزیابی ارتباط
ارزیابی ارتباط جزء مهم عملکرد عاملهای هوش مصنوعی است. این اطمینان حاصل میکند که اطلاعات بازیابی و تولیدشده توسط عامل مناسب، دقیق و مفید برای کاربر باشد. در ادامه به نحوه ارزیابی ارتباط در عاملهای هوش مصنوعی، شامل مثالها و تکنیکهای عملی میپردازیم.
مفاهیم کلیدی در ارزیابی ارتباط
- آگاهی از زمینه:
- عامل باید زمینهٔ پرسش کاربر را بفهمد تا اطلاعات مرتبط بازیابی و تولید کند.
- مثال: اگر کاربر درخواست «بهترین رستورانهای پاریس» را داشته باشد، عامل باید ترجیحات کاربر مانند نوع غذا و بودجه را در نظر بگیرد.
- دقت:
- اطلاعات ارائه شده توسط عامل باید واقعاً درست و بهروز باشد.
- مثال: توصیه رستورانهایی که در حال حاضر باز هستند و نظرات خوبی دارند، نه گزینههای قدیمی یا بسته.
- نیت کاربر:
- عامل باید نیت واقعی کاربر پشت پرسش را استنباط کند تا مرتبطترین اطلاعات را ارائه دهد.
- مثال: اگر کاربر «هتلهای اقتصادی» را بپرسد، عامل باید گزینههای مقرونبهصرفه را اولویت دهد.
- حلقه بازخورد:
- جمعآوری و تحلیل مداوم بازخورد کاربر به عامل کمک میکند فرایند ارزیابی ارتباط را بهبود ببخشد.
- مثال: استفاده از امتیازها و بازخوردهای کاربر درباره توصیههای قبلی برای بهبود پاسخهای آینده.
تکنیکهای عملی برای ارزیابی ارتباط
- امتیازدهی ارتباط:
- به هر آیتم بازیابیشده بر اساس تطابق آن با پرسش و ترجیحات کاربر، امتیاز ارتباط داده میشود.
-
مثال:
def relevance_score(item, query): score = 0 if item['category'] in query['interests']: score += 1 if item['price'] <= query['budget']: score += 1 if item['location'] == query['destination']: score += 1 return score
- فیلتر و رتبهبندی:
- آیتمهای نامرتبط حذف شده و بقیه بر اساس امتیاز ارتباط رتبهبندی میشوند.
-
مثال:
def filter_and_rank(items, query): ranked_items = sorted(items, key=lambda item: relevance_score(item, query), reverse=True) return ranked_items[:10] # بازگرداندن ۱۰ مورد مرتبط برتر
- پردازش زبان طبیعی (NLP):
- استفاده از تکنیکهای NLP برای فهم پرسش کاربر و بازیابی اطلاعات مرتبط.
-
مثال:
def process_query(query): # از پردازش زبان طبیعی برای استخراج اطلاعات کلیدی از پرسش کاربر استفاده کنید processed_query = nlp(query) return processed_query
- ادغام بازخورد کاربر:
- جمعآوری بازخورد کاربر درباره توصیههای ارائه شده و استفاده از آن برای تنظیم ارزیابیهای ارتباطی آینده.
-
مثال:
def adjust_based_on_feedback(feedback, items): for item in items: if item['name'] in feedback['liked']: item['relevance'] += 1 if item['name'] in feedback['disliked']: item['relevance'] -= 1 return items
مثال: ارزیابی ارتباط در کارگزار سفر
در اینجا مثالی عملی از چگونگی ارزیابی ارتباط توصیههای سفری توسط Travel Agent آمده است:
class Travel_Agent:
def __init__(self):
self.user_preferences = {}
self.experience_data = []
def gather_preferences(self, preferences):
self.user_preferences = preferences
def retrieve_information(self):
flights = search_flights(self.user_preferences)
hotels = search_hotels(self.user_preferences)
attractions = search_attractions(self.user_preferences)
return flights, hotels, attractions
def generate_recommendations(self):
flights, hotels, attractions = self.retrieve_information()
ranked_hotels = self.filter_and_rank(hotels, self.user_preferences)
itinerary = create_itinerary(flights, ranked_hotels, attractions)
return itinerary
def filter_and_rank(self, items, query):
ranked_items = sorted(items, key=lambda item: self.relevance_score(item, query), reverse=True)
return ranked_items[:10] # بازگرداندن ۱۰ مورد مرتبط برتر
def relevance_score(self, item, query):
score = 0
if item['category'] in query['interests']:
score += 1
if item['price'] <= query['budget']:
score += 1
if item['location'] == query['destination']:
score += 1
return score
def adjust_based_on_feedback(self, feedback, items):
for item in items:
if item['name'] in feedback['liked']:
item['relevance'] += 1
if item['name'] in feedback['disliked']:
item['relevance'] -= 1
return items
# نمونه استفاده
travel_agent = Travel_Agent()
preferences = {
"destination": "Paris",
"dates": "2025-04-01 to 2025-04-10",
"budget": "moderate",
"interests": ["museums", "cuisine"]
}
travel_agent.gather_preferences(preferences)
itinerary = travel_agent.generate_recommendations()
print("Suggested Itinerary:", itinerary)
feedback = {"liked": ["Louvre Museum"], "disliked": ["Eiffel Tower (too crowded)"]}
updated_items = travel_agent.adjust_based_on_feedback(feedback, itinerary['hotels'])
print("Updated Itinerary with Feedback:", updated_items)
جستجو با هدف
جستجو با هدف به معنای درک و تفسیر هدف یا انگیزهٔ پشت پرسش کاربر برای واکشی و تولید مرتبطترین و مفیدترین اطلاعات است. این رویکرد فراتر از تطبیق صرف کلمات کلیدی است و بر درک نیازها و زمینه واقعی کاربر تمرکز دارد.
مفاهیم کلیدی در جستجو با هدف
- درک نیت کاربر:
- نیت کاربر در سه دسته اصلی: اطلاعاتی، هدایتگر و تراکنشی تقسیم میشود.
- نیت اطلاعاتی: کاربر به دنبال اطلاعات درباره موضوعی است (مثلاً «بهترین موزههای پاریس»).
- نیت هدایتگر: کاربر میخواهد به وبسایت یا صفحه خاصی برود (مثلاً «وبسایت رسمی موزه لوور»).
- نیت تراکنشی: کاربر قصد انجام تراکنشی مانند رزرو یا خرید دارد (مثلاً «رزرو پرواز به پاریس»).
- نیت کاربر در سه دسته اصلی: اطلاعاتی، هدایتگر و تراکنشی تقسیم میشود.
- آگاهی از زمینه:
- تحلیل زمینهٔ پرسش کاربر به شناسایی دقیق نیت او کمک میکند. این شامل در نظر گرفتن تعاملات قبلی، ترجیحات کاربر و جزئیات پرسش جاری است.
- پردازش زبان طبیعی (NLP):
- استفاده از تکنیکهای NLP برای درک و تفسیر پرسشهای زبان طبیعی کاربران. این شامل وظایفی مانند تشخیص موجودیتها، تحلیل احساسات و پردازش پرسش است.
- شخصیسازی:
- شخصیسازی نتایج جستجو بر اساس تاریخچه، ترجیحات و بازخورد کاربر، ارتباط اطلاعات بازیابیشده را افزایش میدهد.
مثال عملی: جستجو با هدف در کارگزار سفر
بیایید Travel Agent را به عنوان نمونه ببینیم که چگونه جستجو با هدف پیادهسازی میشود.
-
جمعآوری ترجیحات کاربر
class Travel_Agent: def __init__(self): self.user_preferences = {} def gather_preferences(self, preferences): self.user_preferences = preferences -
درک نیت کاربر
def identify_intent(query): if "book" in query or "purchase" in query: return "transactional" elif "website" in query or "official" in query: return "navigational" else: return "informational" - آگاهی از زمینه
def analyze_context(query, user_history): # ترکیب پرسوجوی فعلی با سابقه کاربر برای درک زمینه context = { "current_query": query, "user_history": user_history } return context -
جستجو و شخصیسازی نتایج
def search_with_intent(query, preferences, user_history): intent = identify_intent(query) context = analyze_context(query, user_history) if intent == "informational": search_results = search_information(query, preferences) elif intent == "navigational": search_results = search_navigation(query) elif intent == "transactional": search_results = search_transaction(query, preferences) personalized_results = personalize_results(search_results, user_history) return personalized_results def search_information(query, preferences): # منطق جستجوی نمونه برای هدف اطلاعرسانی results = search_web(f"best {preferences['interests']} in {preferences['destination']}") return results def search_navigation(query): # منطق جستجوی نمونه برای هدف ناوبری results = search_web(query) return results def search_transaction(query, preferences): # منطق جستجوی نمونه برای هدف تراکنشی results = search_web(f"book {query} to {preferences['destination']}") return results def personalize_results(results, user_history): # منطق شخصیسازی نمونه personalized = [result for result in results if result not in user_history] return personalized[:10] # بازگرداندن ۱۰ نتیجه شخصیسازی شده برتر -
مثال استفاده
travel_agent = Travel_Agent() preferences = { "destination": "Paris", "interests": ["museums", "cuisine"] } travel_agent.gather_preferences(preferences) user_history = ["Louvre Museum website", "Book flight to Paris"] query = "best museums in Paris" results = search_with_intent(query, preferences, user_history) print("Search Results:", results)
4. تولید کد به عنوان ابزار
نمایندگان تولید کد از مدلهای هوش مصنوعی برای نوشتن و اجرای کد استفاده میکنند تا مسائل پیچیده را حل کنند و وظایف را خودکار کنند.
نمایندگان تولید کد
نمایندگان تولید کد از مدلهای تولیدی هوش مصنوعی برای نوشتن و اجرای کد استفاده میکنند. این نمایندگان میتوانند مسائل پیچیده را حل کنند، وظایف را خودکار کنند و از طریق تولید و اجرای کد در زبانهای برنامهنویسی مختلف، بینشهای ارزشمندی ارائه دهند.
کاربردهای عملی
- تولید خودکار کد: تولید تکههای کد برای وظایف خاص مانند تحلیل دادهها، اسکرپینگ وب یا یادگیری ماشین.
- SQL به عنوان یک RAG: استفاده از پرس و جوهای SQL برای بازیابی و دستکاری دادهها از پایگاههای داده.
- حل مسئله: ایجاد و اجرای کد برای حل مسائل خاص مانند بهینهسازی الگوریتمها یا تحلیل دادهها.
مثال: نماینده تولید کد برای تحلیل دادهها
تصور کنید که در حال طراحی یک نماینده تولید کد هستید. در اینجا نحوه عملکرد آن به شرح زیر است:
- وظیفه: تحلیل یک مجموعه داده برای شناسایی روندها و الگوها.
- مراحل:
- بارگذاری مجموعه دادهها در ابزار تحلیل داده.
- تولید پرس و جوهای SQL برای فیلتر و تجمیع دادهها.
- اجرای پرس و جوها و بازیابی نتایج.
- استفاده از نتایج برای تولید تجسمها و بینشها.
- منابع مورد نیاز: دسترسی به مجموعه دادهها، ابزارهای تحلیل داده و قابلیتهای SQL.
- تجربه: استفاده از نتایج تحلیلهای گذشته برای افزایش دقت و ارتباط تحلیلهای آینده.
مثال: نماینده تولید کد برای آژانس سفر
در این مثال، نماینده تولید کدی به نام آژانس سفر را طراحی میکنیم تا به کاربران در برنامهریزی سفرشان از طریق تولید و اجرای کد کمک کند. این نماینده میتواند وظایفی مانند دریافت گزینههای سفر، فیلتر کردن نتایج و تدوین برنامه سفر را با استفاده از هوش مصنوعی تولیدی انجام دهد.
مرور کلی بر نماینده تولید کد
- جمعآوری ترجیحات کاربر: دریافت ورودی کاربر مانند مقصد، تاریخ سفر، بودجه و علایق.
- تولید کد برای دریافت دادهها: تولید تکههای کد برای بازیابی دادهها درباره پروازها، هتلها و جاذبهها.
- اجرای کد تولید شده: اجرای کد تولید شده برای دریافت اطلاعات بلادرنگ.
- تولید برنامه سفر: جمعبندی دادههای بازیابی شده در یک برنامه سفر شخصیسازی شده.
- تنظیم بر اساس بازخورد: دریافت بازخورد کاربر و تولید مجدد کد در صورت نیاز برای بهبود نتایج.
پیادهسازی گام به گام
-
جمعآوری ترجیحات کاربر
class Travel_Agent: def __init__(self): self.user_preferences = {} def gather_preferences(self, preferences): self.user_preferences = preferences -
تولید کد برای دریافت دادهها
def generate_code_to_fetch_data(preferences): # مثال: تولید کد برای جستجوی پروازها بر اساس ترجیحات کاربر code = f""" def search_flights(): import requests response = requests.get('https://api.example.com/flights', params={preferences}) return response.json() """ return code def generate_code_to_fetch_hotels(preferences): # مثال: تولید کد برای جستجوی هتلها code = f""" def search_hotels(): import requests response = requests.get('https://api.example.com/hotels', params={preferences}) return response.json() """ return code -
اجرای کد تولید شده
def execute_code(code): # اجرای کد تولید شده با استفاده از exec exec(code) result = locals() return result travel_agent = Travel_Agent() preferences = { "destination": "Paris", "dates": "2025-04-01 to 2025-04-10", "budget": "moderate", "interests": ["museums", "cuisine"] } travel_agent.gather_preferences(preferences) flight_code = generate_code_to_fetch_data(preferences) hotel_code = generate_code_to_fetch_hotels(preferences) flights = execute_code(flight_code) hotels = execute_code(hotel_code) print("Flight Options:", flights) print("Hotel Options:", hotels) -
تولید برنامه سفر
def generate_itinerary(flights, hotels, attractions): itinerary = { "flights": flights, "hotels": hotels, "attractions": attractions } return itinerary attractions = search_attractions(preferences) itinerary = generate_itinerary(flights, hotels, attractions) print("Suggested Itinerary:", itinerary) -
تنظیم بر اساس بازخورد
def adjust_based_on_feedback(feedback, preferences): # تنظیم ترجیحات بر اساس بازخورد کاربر if "liked" in feedback: preferences["favorites"] = feedback["liked"] if "disliked" in feedback: preferences["avoid"] = feedback["disliked"] return preferences feedback = {"liked": ["Louvre Museum"], "disliked": ["Eiffel Tower (too crowded)"]} updated_preferences = adjust_based_on_feedback(feedback, preferences) # بازتولید و اجرای کد با ترجیحات بهروزشده updated_flight_code = generate_code_to_fetch_data(updated_preferences) updated_hotel_code = generate_code_to_fetch_hotels(updated_preferences) updated_flights = execute_code(updated_flight_code) updated_hotels = execute_code(updated_hotel_code) updated_itinerary = generate_itinerary(updated_flights, updated_hotels, attractions) print("Updated Itinerary:", updated_itinerary)
بهرهگیری از آگاهی محیطی و استدلال
بر اساس ساختار جدول، میتوان فرآیند تولید پرس و جو را با بهرهگیری از آگاهی محیطی و استدلال بهبود بخشید.
در اینجا مثالی از چگونگی انجام این کار آمده است:
- درک ساختار: سیستم ساختار جدول را درک میکند و از این اطلاعات برای پایهگذاری تولید پرس و جو استفاده میکند.
- تنظیم بر اساس بازخورد: سیستم ترجیحات کاربر را بر اساس بازخورد تنظیم کرده و درباره اینکه کدام فیلدهای ساختار نیاز به بهروزرسانی دارند، استدلال میکند.
- تولید و اجرای پرس و جوها: سیستم پرس و جوهایی تولید و اجرا میکند تا دادههای بهروزشده پرواز و هتل را بر اساس ترجیحات جدید بازیابی کند.
در اینجا نمونه کد پایتون بهروزشدهای است که این مفاهیم را در بر دارد:
def adjust_based_on_feedback(feedback, preferences, schema):
# تنظیم تنظیمات بر اساس بازخورد کاربر
if "liked" in feedback:
preferences["favorites"] = feedback["liked"]
if "disliked" in feedback:
preferences["avoid"] = feedback["disliked"]
# استدلال بر اساس طرح برای تنظیم تنظیمات مرتبط دیگر
for field in schema:
if field in preferences:
preferences[field] = adjust_based_on_environment(feedback, field, schema)
return preferences
def adjust_based_on_environment(feedback, field, schema):
# منطق سفارشی برای تنظیم تنظیمات بر اساس طرح و بازخورد
if field in feedback["liked"]:
return schema[field]["positive_adjustment"]
elif field in feedback["disliked"]:
return schema[field]["negative_adjustment"]
return schema[field]["default"]
def generate_code_to_fetch_data(preferences):
# تولید کد برای دریافت دادههای پرواز بر اساس تنظیمات بهروزشده
return f"fetch_flights(preferences={preferences})"
def generate_code_to_fetch_hotels(preferences):
# تولید کد برای دریافت دادههای هتل بر اساس تنظیمات بهروزشده
return f"fetch_hotels(preferences={preferences})"
def execute_code(code):
# شبیهسازی اجرای کد و بازگرداندن دادههای نمونه
return {"data": f"Executed: {code}"}
def generate_itinerary(flights, hotels, attractions):
# تولید برنامه سفر بر اساس پروازها، هتلها و جاذبهها
return {"flights": flights, "hotels": hotels, "attractions": attractions}
# مثال طرح
schema = {
"favorites": {"positive_adjustment": "increase", "negative_adjustment": "decrease", "default": "neutral"},
"avoid": {"positive_adjustment": "decrease", "negative_adjustment": "increase", "default": "neutral"}
}
# مثال استفاده
preferences = {"favorites": "sightseeing", "avoid": "crowded places"}
feedback = {"liked": ["Louvre Museum"], "disliked": ["Eiffel Tower (too crowded)"]}
updated_preferences = adjust_based_on_feedback(feedback, preferences, schema)
# بازتولید و اجرای کد با تنظیمات بهروزشده
updated_flight_code = generate_code_to_fetch_data(updated_preferences)
updated_hotel_code = generate_code_to_fetch_hotels(updated_preferences)
updated_flights = execute_code(updated_flight_code)
updated_hotels = execute_code(updated_hotel_code)
updated_itinerary = generate_itinerary(updated_flights, updated_hotels, feedback["liked"])
print("Updated Itinerary:", updated_itinerary)
توضیح - رزرو بر اساس بازخورد
- آگاهی از ساختار: دیکشنری
schemaتعیین میکند که چگونه ترجیحات بر اساس بازخورد تنظیم شوند. شامل فیلدهایی مثلfavoritesوavoidبا تنظیمات مربوطه است. - تنظیم ترجیحات (
adjust_based_on_feedbackmethod): این متد ترجیحات را بر اساس بازخورد کاربر و ساختار تنظیم میکند. - تنظیمات مبتنی بر محیط (
adjust_based_on_environmentmethod): این متد تنظیمات را بر اساس ساختار و بازخورد سفارشی میکند. - تولید و اجرای پرس و جوها: سیستم کدی تولید میکند تا دادههای بهروزشده پرواز و هتل را بر اساس ترجیحات تنظیمشده بازیابی کند و اجرای شبیهسازیشده این پرس و جوها را انجام میدهد.
- تولید برنامه سفر: سیستم برنامه بهروزشدهای بر اساس دادههای جدید پرواز، هتل و جاذبهها ایجاد میکند.
با مجهز کردن سیستم به آگاهی محیطی و استدلال بر اساس ساختار، میتوان پرس و جوهای دقیقتر و مرتبطتری تولید کرد که منجر به توصیههای بهتر سفر و تجربه کاربری شخصیتر میشود.
استفاده از SQL به عنوان تکنیک Retrieval-Augmented Generation (RAG)
SQL (زبان ساختیافته پرس و جو) ابزاری قدرتمند برای تعامل با پایگاههای داده است. هنگام استفاده به عنوان بخشی از رویکرد Retrieval-Augmented Generation (RAG)، SQL میتواند دادههای مرتبط را از پایگاههای داده برای اطلاعرسانی و تولید پاسخها یا اقدامات در نمایندگان هوش مصنوعی بازیابی کند. بیایید ببینیم چگونه SQL میتواند به عنوان یک تکنیک RAG در زمینه آژانس سفر استفاده شود.
مفاهیم کلیدی
- تعامل با پایگاه داده:
- SQL برای پرس و جوی پایگاههای داده، بازیابی اطلاعات مرتبط و دستکاری دادهها استفاده میشود.
- مثال: دریافت جزئیات پرواز، اطلاعات هتلها و جاذبهها از پایگاه داده سفر.
- یکپارچهسازی با RAG:
- پرس و جوهای SQL بر اساس ورودی و ترجیحات کاربر تولید میشوند.
- داده بازیابی شده سپس برای تولید توصیهها یا اقدامات شخصیسازی شده استفاده میشود.
- تولید دینامیک پرس و جو:
- نماینده هوش مصنوعی پرس و جوهای SQL دینامیک بر اساس زمینه و نیازهای کاربر تولید میکند.
- مثال: سفارشیسازی پرس و جوهای SQL برای فیلتر نتایج بر اساس بودجه، تاریخها و علایق.
کاربردها
- تولید خودکار کد: تولید تکههای کد برای وظایف خاص.
- SQL به عنوان RAG: استفاده از پرس و جوهای SQL برای دستکاری دادهها.
- حل مسئله: ایجاد و اجرای کد برای حل مسائل.
مثال: نماینده تحلیل داده:
- وظیفه: تحلیل یک مجموعه داده برای یافتن روندها.
- مراحل:
- بارگذاری مجموعه داده.
- تولید پرس و جوهای SQL برای فیلتر دادهها.
- اجرای پرس و جوها و بازیابی نتایج.
- تولید تجسمها و بینشها.
- منابع: دسترسی به مجموعه داده، قابلیتهای SQL.
- تجربه: استفاده از نتایج گذشته برای بهبود تحلیلهای آینده.
مثال عملی: استفاده از SQL در آژانس سفر
-
جمعآوری ترجیحات کاربر
class Travel_Agent: def __init__(self): self.user_preferences = {} def gather_preferences(self, preferences): self.user_preferences = preferences -
تولید پرس و جوهای SQL
def generate_sql_query(table, preferences): query = f"SELECT * FROM {table} WHERE " conditions = [] for key, value in preferences.items(): conditions.append(f"{key}='{value}'") query += " AND ".join(conditions) return query -
اجرای پرس و جوهای SQL
import sqlite3 def execute_sql_query(query, database="travel.db"): connection = sqlite3.connect(database) cursor = connection.cursor() cursor.execute(query) results = cursor.fetchall() connection.close() return results -
تولید توصیهها
def generate_recommendations(preferences): flight_query = generate_sql_query("flights", preferences) hotel_query = generate_sql_query("hotels", preferences) attraction_query = generate_sql_query("attractions", preferences) flights = execute_sql_query(flight_query) hotels = execute_sql_query(hotel_query) attractions = execute_sql_query(attraction_query) itinerary = { "flights": flights, "hotels": hotels, "attractions": attractions } return itinerary travel_agent = Travel_Agent() preferences = { "destination": "Paris", "dates": "2025-04-01 to 2025-04-10", "budget": "moderate", "interests": ["museums", "cuisine"] } travel_agent.gather_preferences(preferences) itinerary = generate_recommendations(preferences) print("Suggested Itinerary:", itinerary)
مثال پرس و جوهای SQL
-
پرس و جو پرواز
SELECT * FROM flights WHERE destination='Paris' AND dates='2025-04-01 to 2025-04-10' AND budget='moderate'; -
پرس و جو هتل
SELECT * FROM hotels WHERE destination='Paris' AND budget='moderate'; -
پرس و جو جاذبه
SELECT * FROM attractions WHERE destination='Paris' AND interests='museums, cuisine';
با استفاده از SQL به عنوان بخشی از تکنیک Retrieval-Augmented Generation (RAG)، نمایندگان هوش مصنوعی مانند آژانس سفر میتوانند دادههای مرتبط را به صورت دینامیک بازیابی و استفاده کنند تا توصیههای دقیق و شخصیسازی شده ارائه دهند.
مثال از فراشناخت
برای نشان دادن پیادهسازی فراشناخت، بیایید یک نماینده ساده ایجاد کنیم که بر فرآیند تصمیمگیری خود تامل میکند در حالی که مسئلهای را حل میکند. در این مثال، سیستمی میسازیم که نمایندهای را شبیهسازی میکند که انتخاب هتل را بهینه میکند، اما سپس استدلال خود را ارزیابی کرده و استراتژیاش را وقتی اشتباه یا انتخاب نامناسب انجام میدهد، تنظیم میکند.
این را با یک مثال پایهای شبیهسازی خواهیم کرد که نماینده هتلها را بر اساس ترکیب قیمت و کیفیت انتخاب میکند، اما تصمیمات خود را “بازتاب” داده و بر اساس آن تنظیم میکند.
این چطور فراشناخت را نشان میدهد:
- تصمیم اولیه: نماینده ارزانترین هتل را انتخاب میکند بدون اینکه تأثیر کیفیت را درک کند.
- تفکر و ارزیابی: پس از انتخاب اولیه، نماینده بررسی میکند که آیا هتل انتخاب شده “انتخاب بد” است با استفاده از بازخورد کاربر. اگر کیفیت هتل خیلی پایین باشد، نماینده درباره استدلال خود تأمل میکند.
- تنظیم استراتژی: نماینده استراتژی خود را بر اساس بازتاب خود تنظیم کرده، از “ارزانترین” به “بالاترین کیفیت” تغییر میدهد و بدین ترتیب فرآیند تصمیمگیری خود را در تکرارهای بعدی بهبود میبخشد.
در اینجا یک مثال است:
class HotelRecommendationAgent:
def __init__(self):
self.previous_choices = [] # هتلهایی که قبلاً انتخاب شدهاند را ذخیره میکند
self.corrected_choices = [] # انتخابهای اصلاحشده را ذخیره میکند
self.recommendation_strategies = ['cheapest', 'highest_quality'] # استراتژیهای موجود
def recommend_hotel(self, hotels, strategy):
"""
Recommend a hotel based on the chosen strategy.
The strategy can either be 'cheapest' or 'highest_quality'.
"""
if strategy == 'cheapest':
recommended = min(hotels, key=lambda x: x['price'])
elif strategy == 'highest_quality':
recommended = max(hotels, key=lambda x: x['quality'])
else:
recommended = None
self.previous_choices.append((strategy, recommended))
return recommended
def reflect_on_choice(self):
"""
Reflect on the last choice made and decide if the agent should adjust its strategy.
The agent considers if the previous choice led to a poor outcome.
"""
if not self.previous_choices:
return "No choices made yet."
last_choice_strategy, last_choice = self.previous_choices[-1]
# فرض کنیم که بازخورد کاربر داریم که به ما میگوید انتخاب قبلی خوب بوده یا نه
user_feedback = self.get_user_feedback(last_choice)
if user_feedback == "bad":
# اگر انتخاب قبلی رضایتبخش نبود، استراتژی را تنظیم میکند
new_strategy = 'highest_quality' if last_choice_strategy == 'cheapest' else 'cheapest'
self.corrected_choices.append((new_strategy, last_choice))
return f"Reflecting on choice. Adjusting strategy to {new_strategy}."
else:
return "The choice was good. No need to adjust."
def get_user_feedback(self, hotel):
"""
Simulate user feedback based on hotel attributes.
For simplicity, assume if the hotel is too cheap, the feedback is "bad".
If the hotel has quality less than 7, feedback is "bad".
"""
if hotel['price'] < 100 or hotel['quality'] < 7:
return "bad"
return "good"
# شبیهسازی یک لیست از هتلها (قیمت و کیفیت)
hotels = [
{'name': 'Budget Inn', 'price': 80, 'quality': 6},
{'name': 'Comfort Suites', 'price': 120, 'quality': 8},
{'name': 'Luxury Stay', 'price': 200, 'quality': 9}
]
# ایجاد یک عامل
agent = HotelRecommendationAgent()
# مرحله ۱: عامل با استفاده از استراتژی «ارزانترین» هتلی را پیشنهاد میدهد
recommended_hotel = agent.recommend_hotel(hotels, 'cheapest')
print(f"Recommended hotel (cheapest): {recommended_hotel['name']}")
# مرحله ۲: عامل درباره انتخاب فکر میکند و در صورت لزوم استراتژی را تنظیم میکند
reflection_result = agent.reflect_on_choice()
print(reflection_result)
# مرحله ۳: عامل دوباره پیشنهاد میدهد، این بار با استفاده از استراتژی تنظیمشده
adjusted_recommendation = agent.recommend_hotel(hotels, 'highest_quality')
print(f"Adjusted hotel recommendation (highest_quality): {adjusted_recommendation['name']}")
تواناییهای فراشناختی نمایندگان
نکته کلیدی در اینجا توانایی نماینده برای:
- ارزیابی انتخابها و فرآیند تصمیمگیری قبلی خود.
- تنظیم استراتژی بر اساس آن تفکر، یعنی فراشناخت در عمل.
این یک شکل ساده از فراشناخت است که سیستم قادر است بر اساس بازخورد داخلی، فرآیند استدلال خود را تنظیم کند.
نتیجهگیری
فراشناخت ابزاری قدرتمند است که میتواند به طور قابل توجهی تواناییهای نمایندگان هوش مصنوعی را افزایش دهد. با گنجاندن فرآیندهای فراشناختی، میتوانید نمایندگانی طراحی کنید که هوشمندتر، سازگارتر و کارآمدتر باشند. از منابع اضافی برای کاوش بیشتر در دنیای جذاب فراشناخت در نمایندگان هوش مصنوعی استفاده کنید.
سوالات بیشتری درباره الگوی طراحی فراشناخت دارید؟
به Microsoft Foundry Discord بپیوندید تا با دیگر یادگیرندهها ملاقات کنید، در ساعتهای اداری حضور یابید و سوالات خود درباره نمایندگان هوش مصنوعی را پاسخ بگیرید.
درس قبلی
درس بعدی
سلب مسئولیت:
این سند با استفاده از سرویس ترجمه ماشینی Co-op Translator ترجمه شده است. در حالی که تلاش ما بر دقت است، لطفاً توجه داشته باشید که ترجمههای خودکار ممکن است شامل خطاها یا نادرستیهایی باشند. سند اصلی به زبان بومی خود باید به عنوان منبع معتبر در نظر گرفته شود. برای اطلاعات حیاتی، ترجمه تخصصی انسانی توصیه میشود. ما مسئول هیچگونه سوءتفاهم یا برداشت نادرستی که ناشی از استفاده از این ترجمه باشد، نیستیم.