ai-agents-for-beginners

(上の画像をクリックすると、このレッスンの動画が視聴できます)
AIエージェントにおけるメタ認知
はじめに
AIエージェントにおけるメタ認知のレッスンへようこそ!この章は、自身の思考プロセスについてAIエージェントがどのように考えられるかに興味のある初心者向けに設計されています。このレッスンの終了時には、重要な概念を理解し、AIエージェント設計にメタ認知を適用する実践的な例を使いこなせるようになります。
学習目標
このレッスンを終えた後、あなたは以下のことができるようになります:
- エージェント定義における推論ループの意味を理解する。
- 計画と評価の手法を活用して自己修正するエージェントを支援する。
- タスク達成のためにコードを操作できる自分自身のエージェントを作成する。
メタ認知の紹介
メタ認知とは、自身の思考について考える高次の認知プロセスを指します。AIエージェントにとっては、自己認識や過去の経験に基づいて行動を評価・調整できることを意味します。「思考について考える」メタ認知は、エージェント型AIシステムの開発において重要な概念です。これは、AIシステムが自らの内部プロセスを認識し、それに基づいて行動を監視・調整・適応させる能力を持つことを含みます。私たちが場の空気を読み取ったり問題を見つめたりするのと同様です。この自己認識は、AIシステムがより良い意思決定を行い、エラーを特定し、時間とともに性能を向上させることに役立ちます—これはチューリングテストやAIが世界を支配するかどうかの議論とも関連しています。
エージェント型AIシステムの文脈では、メタ認知は次のような課題に対応するのに役立ちます:
- 透明性:AIシステムが自身の推論や意思決定を説明できることを保証する。
- 推論力:AIシステムが情報を統合し適切な意思決定を行う能力を高める。
- 適応力:AIシステムが新しい環境や変化する条件に対応できるようにする。
- 知覚力:AIシステムが環境からのデータを正確に認識・解釈する精度を向上させる。
メタ認知とは何か?
メタ認知、すなわち「思考について考える」とは、自身の認知プロセスの自己認識と自己調整を含む高次の認知過程です。AIの領域では、メタ認知はエージェントが自身の戦略や行動を評価・適応させることを可能にし、問題解決や意思決定能力の向上につながります。メタ認知を理解することで、より知的で適応性・効率性の高いAIエージェントを設計できます。真のメタ認知では、AIが自分の推論について明示的に考えている様子が見られます。
例:「安いフライトを優先しましたが…直行便を見逃しているかもしれません。再確認します。」 ある経路を選んだ理由を追跡する。
- 前回のユーザーの好みに過度に依存してミスをしたことを認識し、最終的な推奨だけでなく意思決定戦略自体を修正する。
- 「ユーザーが『混雑しすぎ』と述べたら、特定の観光地を除外するだけでなく、人気順で”トップアトラクション”を選ぶ方法自体が誤っている可能性がある」とパターンを診断する。
AIエージェントにおけるメタ認知の重要性
メタ認知はAIエージェント設計において多くの理由で重要な役割を果たします:
- 自己反省:エージェントが自身の性能を評価し、改善点を特定できる。
- 適応性:エージェントが過去の経験や変化する環境に基づいて戦略を変更できる。
- エラー修正:エージェントが自律的にエラーを検出・修正し、より正確な結果を導く。
- 資源管理:エージェントが時間や計算資源といったリソースの使用を最適化し、計画や評価によって効率化を図る。
AIエージェントの構成要素
メタ認知プロセスに入る前に、AIエージェントの基本的な構成要素を理解しておくことが重要です。AIエージェントは一般的に以下で構成されます:
- ペルソナ:ユーザーとのやり取り方法を定義するエージェントの性格や特徴。
- ツール:エージェントが実行可能な機能や能力。
- スキル:エージェントが持つ知識や専門性。
これらの要素は協力して特定のタスクを実行できる「専門ユニット」を形成します。
例: 旅行代理店を想定してください。リアルタイムデータや過去の顧客体験に基づいて計画を立て、旅程を調整するサービス型エージェントです。
例:旅行代理店サービスにおけるメタ認知
AIによる旅行代理店サービスを設計すると想像してください。このエージェント「Travel Agent」はユーザーの休暇計画を支援します。メタ認知を組み込むには、「Travel Agent」が自己認識や過去の経験に基づき行動を評価・調整する必要があります。次がメタ認知の役割です:
現在のタスク
パリへの旅行計画をユーザーのために立てる。
タスク達成の手順
- ユーザーの好みを集める:旅行日、予算、興味(例:博物館、料理、買い物)、特別な要望をユーザーに尋ねる。
- 情報の取得:ユーザーの好みに合うフライト、宿泊施設、観光地、レストランを探す。
- 提案作成:フライト情報、ホテル予約、推奨アクティビティを含む個別の旅程を提示する。
- フィードバックに基づく調整:ユーザーから提案に対する意見を聞き、必要に応じて修正する。
必要なリソース
- フライト・ホテル予約データベースへのアクセス。
- パリの観光地・レストラン情報。
- 過去のユーザーフィードバックデータ。
経験と自己反省
Travel Agentはメタ認知を利用し、自身のパフォーマンスを評価して過去の経験から学習します。例えば:
- ユーザーフィードバックの分析:Travel Agentはフィードバックを確認し、支持された提案とそうでないものを判別し、今後の提案を改善する。
- 適応力:ユーザーが混雑を嫌うと以前に伝えていた場合、ピーク時間の人気観光地の提案を避ける。
- エラー修正:仮に過去に満室のホテルを提案するミスがあれば、予約前により厳密な空室確認を行うよう学習する。
実践的な開発者向け例
以下はメタ認知を組み込んだTravel Agentコードの簡略例です:
class Travel_Agent:
def __init__(self):
self.user_preferences = {}
self.experience_data = []
def gather_preferences(self, preferences):
self.user_preferences = preferences
def retrieve_information(self):
# 好みに基づいてフライト、ホテル、アトラクションを検索する
flights = search_flights(self.user_preferences)
hotels = search_hotels(self.user_preferences)
attractions = search_attractions(self.user_preferences)
return flights, hotels, attractions
def generate_recommendations(self):
flights, hotels, attractions = self.retrieve_information()
itinerary = create_itinerary(flights, hotels, attractions)
return itinerary
def adjust_based_on_feedback(self, feedback):
self.experience_data.append(feedback)
# フィードバックを分析し、将来の推奨を調整する
self.user_preferences = adjust_preferences(self.user_preferences, feedback)
# 使用例
travel_agent = Travel_Agent()
preferences = {
"destination": "Paris",
"dates": "2025-04-01 to 2025-04-10",
"budget": "moderate",
"interests": ["museums", "cuisine"]
}
travel_agent.gather_preferences(preferences)
itinerary = travel_agent.generate_recommendations()
print("Suggested Itinerary:", itinerary)
feedback = {"liked": ["Louvre Museum"], "disliked": ["Eiffel Tower (too crowded)"]}
travel_agent.adjust_based_on_feedback(feedback)
メタ認知が重要な理由
- 自己反省:エージェントが自身のパフォーマンスを分析し改善点を見つける。
- 適応性:エージェントがフィードバックや変化に基づき戦略を修正する。
- エラー修正:自己修正能力でミスを検出し直す。
- 資源管理:時間や計算資源の効率的使用を最適化。
メタ認知を取り入れることで、Travel Agentはより個別化され正確な旅行提案を提供し、全体のユーザー体験を向上させます。
2. エージェントの計画
計画はAIエージェントの行動における重要な要素です。目標達成に必要なステップを、現在の状況やリソース、障害を考慮しながら概要化します。
計画の要素
- 現在のタスク:タスクを明確に定義する。
- タスク達成のステップ:タスクを管理可能な手順に分解する。
- 必要なリソース:必要な資源を把握する。
- 経験:過去の経験を計画に活用する。
例: Travel Agentがユーザーの旅行計画支援のために取るべきステップ:
Travel Agentのステップ
- ユーザーの好み収集
- 旅行日、予算、興味、特別な要望をユーザーに尋ねる。
- 例:「いつ旅行されますか?」「ご予算はどのくらいですか?」「休暇中に楽しみたいアクティビティは何ですか?」
- 情報取得
- ユーザー好みに基づき旅行オプションを検索。
- フライト:予算内、希望旅行日に合うフライトを探す。
- 宿泊:場所、価格、設備がユーザーの好みに合うホテルやレンタル物件を探す。
- 観光地・レストラン:ユーザー興味に沿う人気スポット、アクティビティ、飲食店を特定。
- 提案生成
- 取得情報をまとめ、個別の旅程を作成。
- フライト、ホテル予約、推奨アクティビティをユーザー好みに合わせて提供。
- 旅程の提示
- ユーザーに提案を提示して確認してもらう。
- 例:「パリ旅行のおすすめ旅程です。フライト情報やホテル予約、アクティビティやレストランのリストを含んでいます。ご意見を教えてください!」
- フィードバック収集
- ユーザーに旅程への感想を聞く。
- 例:「フライトは気に入りましたか?」「ホテルはご希望に合っていますか?」「加えたいまたは除外したいアクティビティはありますか?」
- フィードバックに基づく修正
- ユーザーの意見に応じて旅程を修正。
- 飛行機、宿泊、アクティビティの提案を調整しユーザーの好みに合うよう改善。
- 最終確認
- 修正後の旅程をユーザーに最終確認してもらう。
- 例:「ご意見を反映しました。更新した旅程はこちらです。問題なければ正式に予約手続きを進めます。」
- 予約確定
- ユーザーの承認後、フライト、宿泊、アクティビティの予約を確定。
- 確認情報をユーザーに送信。
- 継続的サポート提供
- 旅行前・旅行中の変更や追加リクエストに対応可能な状態を維持。
- 例:「旅行中に何かあればいつでもご連絡ください!」
例:対話シーン
class Travel_Agent:
def __init__(self):
self.user_preferences = {}
self.experience_data = []
def gather_preferences(self, preferences):
self.user_preferences = preferences
def retrieve_information(self):
flights = search_flights(self.user_preferences)
hotels = search_hotels(self.user_preferences)
attractions = search_attractions(self.user_preferences)
return flights, hotels, attractions
def generate_recommendations(self):
flights, hotels, attractions = self.retrieve_information()
itinerary = create_itinerary(flights, hotels, attractions)
return itinerary
def adjust_based_on_feedback(self, feedback):
self.experience_data.append(feedback)
self.user_preferences = adjust_preferences(self.user_preferences, feedback)
# ブーイングリクエスト内での使用例
travel_agent = Travel_Agent()
preferences = {
"destination": "Paris",
"dates": "2025-04-01 to 2025-04-10",
"budget": "moderate",
"interests": ["museums", "cuisine"]
}
travel_agent.gather_preferences(preferences)
itinerary = travel_agent.generate_recommendations()
print("Suggested Itinerary:", itinerary)
feedback = {"liked": ["Louvre Museum"], "disliked": ["Eiffel Tower (too crowded)"]}
travel_agent.adjust_based_on_feedback(feedback)
3. 修正型RAGシステム
まず、RAGツールと先読みコンテキストロードの違いを理解しましょう。
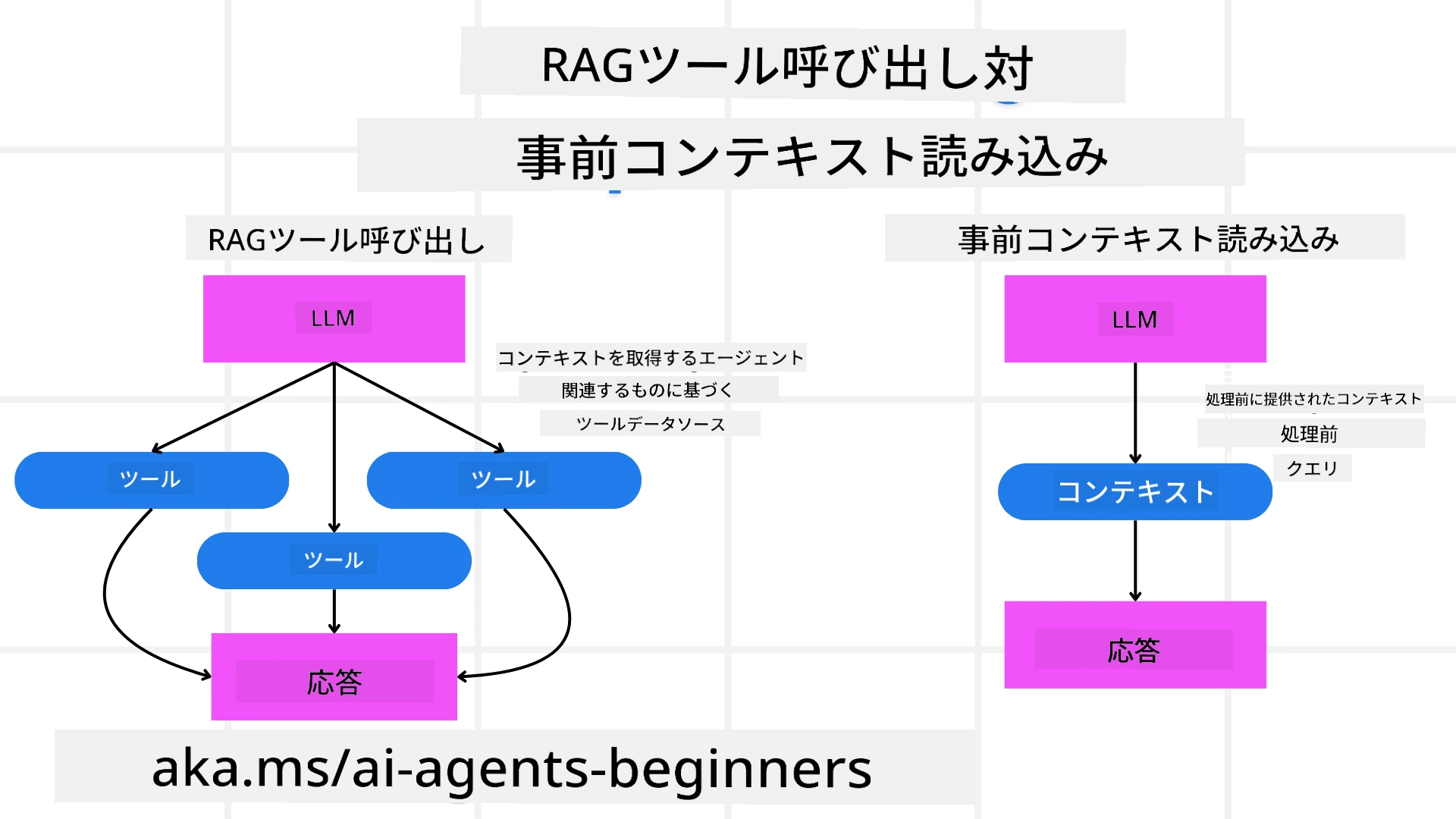
回収強化生成(RAG)
RAGは回収システムと生成モデルを組み合わせたものです。クエリが発行されると、回収システムは外部ソースから関連する文書やデータを取り出し、それらの情報を生成モデルへの入力に付加して、より正確で文脈に即した応答を生成します。
RAGシステムではエージェントが知識ベースから情報を回収し、その情報を使って適切な応答や行動を生成します。
修正型RAGアプローチ
修正型RAGはエラーを修正し、AIエージェントの精度を向上させるためにRAG技術を活用します。具体的には:
- プロンプト技術:関連情報を効果的に取得するための特定のプロンプトを用いる。
- ツール:回収した情報の関連度を評価し、正確な応答を生成するアルゴリズムや仕組みを実装する。
- 評価:継続的にエージェントの性能を評価し、精度や効率を改善するため調整を行う。
例:検索エージェントにおける修正型RAG
ウェブから情報を取得してユーザーの質問に答える検索エージェントの場合、修正型RAGは以下のように機能します:
- プロンプト技術:ユーザーの入力をもとに検索クエリを生成。
- ツール:自然言語処理と機械学習を用いて検索結果の順位付け・フィルタリングを行う。
- 評価:ユーザーフィードバックを分析し、誤りを特定し修正する。
旅行代理店における修正型RAG
修正型RAG(Retrieval-Augmented Generation)は、AIが情報を取得・生成しつつ誤りを修正する能力を強化します。Travel Agentがより正確で関連性の高い旅行提案を行うために修正型RAGを用いる方法を見てみましょう。
これには:
- プロンプト技術:特定のプロンプトを使い、関連情報を検索させる。
- ツール:回収情報の関連性を評価し、正確な応答を生成するアルゴリズムを実装。
- 評価:エージェントの性能を継続的に評価し、精度と効率を改良。
Travel Agentにおける修正型RAG実装手順
- 初期ユーザーインタラクション
- Travel Agentが目的地、旅行日、予算、興味などの初期情報をユーザーから集める。
-
例:
preferences = { "destination": "Paris", "dates": "2025-04-01 to 2025-04-10", "budget": "moderate", "interests": ["museums", "cuisine"] }
- 情報の回収
- Travel Agentがユーザー好みに基づきフライト、宿泊、観光地、飲食店情報を取得。
-
例:
flights = search_flights(preferences) hotels = search_hotels(preferences) attractions = search_attractions(preferences)
- 初期提案の生成
- 回収した情報を使い個別旅程を作成。
-
例:
itinerary = create_itinerary(flights, hotels, attractions) print("Suggested Itinerary:", itinerary)
- ユーザーフィードバックの収集
- 初期提案に関するユーザーの意見を聞く。
-
例:
feedback = { "liked": ["Louvre Museum"], "disliked": ["Eiffel Tower (too crowded)"] }
- 修正型RAGプロセス
- プロンプト技術:ユーザーフィードバックをもとに新たな検索クエリを生成。
-
例:
if "disliked" in feedback: preferences["avoid"] = feedback["disliked"]
-
- ツール:ユーザーフィードバックに基づき新検索結果を順位付け・フィルタリングするアルゴリズムを利用。
-
例:
new_attractions = search_attractions(preferences) new_itinerary = create_itinerary(flights, hotels, new_attractions) print("Updated Itinerary:", new_itinerary)
-
- 評価:ユーザーフィードバック分析により提案内容の関連性・正確性を継続的に評価・調整。
-
例:
def adjust_preferences(preferences, feedback): if "liked" in feedback: preferences["favorites"] = feedback["liked"] if "disliked" in feedback: preferences["avoid"] = feedback["disliked"] return preferences preferences = adjust_preferences(preferences, feedback)
-
- プロンプト技術:ユーザーフィードバックをもとに新たな検索クエリを生成。
実践的な例
以下は、Travel Agentに修正型RAGを組み込んだ簡易的なPythonコード例です:
class Travel_Agent:
def __init__(self):
self.user_preferences = {}
self.experience_data = []
def gather_preferences(self, preferences):
self.user_preferences = preferences
def retrieve_information(self):
flights = search_flights(self.user_preferences)
hotels = search_hotels(self.user_preferences)
attractions = search_attractions(self.user_preferences)
return flights, hotels, attractions
def generate_recommendations(self):
flights, hotels, attractions = self.retrieve_information()
itinerary = create_itinerary(flights, hotels, attractions)
return itinerary
def adjust_based_on_feedback(self, feedback):
self.experience_data.append(feedback)
self.user_preferences = adjust_preferences(self.user_preferences, feedback)
new_itinerary = self.generate_recommendations()
return new_itinerary
# 使用例
travel_agent = Travel_Agent()
preferences = {
"destination": "Paris",
"dates": "2025-04-01 to 2025-04-10",
"budget": "moderate",
"interests": ["museums", "cuisine"]
}
travel_agent.gather_preferences(preferences)
itinerary = travel_agent.generate_recommendations()
print("Suggested Itinerary:", itinerary)
feedback = {"liked": ["Louvre Museum"], "disliked": ["Eiffel Tower (too crowded)"]}
new_itinerary = travel_agent.adjust_based_on_feedback(feedback)
print("Updated Itinerary:", new_itinerary)
先読みコンテキストロード
事前コンテキストロードとは、クエリを処理する前にモデルに関連するコンテキストや背景情報を読み込むことを指します。これにより、モデルは最初からこの情報にアクセスできるため、処理中に追加のデータを取得する必要がなく、より情報に基づいた応答を生成しやすくなります。
以下は、Pythonでの旅行代理店アプリケーションにおける事前コンテキストロードの簡略化された例です。
class TravelAgent:
def __init__(self):
# 人気の目的地及びその情報を事前に読み込む
self.context = {
"Paris": {"country": "France", "currency": "Euro", "language": "French", "attractions": ["Eiffel Tower", "Louvre Museum"]},
"Tokyo": {"country": "Japan", "currency": "Yen", "language": "Japanese", "attractions": ["Tokyo Tower", "Shibuya Crossing"]},
"New York": {"country": "USA", "currency": "Dollar", "language": "English", "attractions": ["Statue of Liberty", "Times Square"]},
"Sydney": {"country": "Australia", "currency": "Dollar", "language": "English", "attractions": ["Sydney Opera House", "Bondi Beach"]}
}
def get_destination_info(self, destination):
# 事前に読み込まれたコンテキストから目的地情報を取得する
info = self.context.get(destination)
if info:
return f"{destination}:\nCountry: {info['country']}\nCurrency: {info['currency']}\nLanguage: {info['language']}\nAttractions: {', '.join(info['attractions'])}"
else:
return f"Sorry, we don't have information on {destination}."
# 使用例
travel_agent = TravelAgent()
print(travel_agent.get_destination_info("Paris"))
print(travel_agent.get_destination_info("Tokyo"))
説明
-
初期化(
__init__メソッド):TravelAgentクラスは、パリ、東京、ニューヨーク、シドニーなどの人気の旅行先に関する情報を含む辞書を事前にロードします。この辞書には、各目的地の国、通貨、言語、主要な観光スポットなどの詳細が含まれます。 -
情報取得(
get_destination_infoメソッド): ユーザーが特定の目的地について問い合わせると、get_destination_infoメソッドは事前にロードされたコンテキスト辞書から関連情報を取得します。
事前にコンテキストをロードすることで、旅行代理店アプリはリアルタイムに外部ソースから情報を取得することなくユーザーの問い合わせに迅速に対応でき、効率と応答性が向上します。
目標を設定してから計画をブートストラップし、反復する
目標を設定して計画をブートストラップするとは、明確な目的や目標結果を最初に定めることを指します。この目標を前もって定義することで、モデルは反復処理の間ずっとそれを指針として活用できます。これにより、各反復が望ましい結果の達成に近づくようになり、プロセスがより効率的で焦点を絞ったものになります。
以下は、Pythonで旅行代理店向けに目標を設定してから旅行計画をブートストラップし、反復する例です。
シナリオ
旅行代理店が顧客の好みや予算に基づいてカスタマイズされた休暇プランを計画したいと考えています。目標は、顧客満足度を最大化する旅行日程を作成することです。
手順
- 顧客の好みと予算を定義する。
- これらの好みに基づき初期計画をブートストラップする。
- 顧客満足を最適化するために計画を反復して洗練する。
Pythonコード
class TravelAgent:
def __init__(self, destinations):
self.destinations = destinations
def bootstrap_plan(self, preferences, budget):
plan = []
total_cost = 0
for destination in self.destinations:
if total_cost + destination['cost'] <= budget and self.match_preferences(destination, preferences):
plan.append(destination)
total_cost += destination['cost']
return plan
def match_preferences(self, destination, preferences):
for key, value in preferences.items():
if destination.get(key) != value:
return False
return True
def iterate_plan(self, plan, preferences, budget):
for i in range(len(plan)):
for destination in self.destinations:
if destination not in plan and self.match_preferences(destination, preferences) and self.calculate_cost(plan, destination) <= budget:
plan[i] = destination
break
return plan
def calculate_cost(self, plan, new_destination):
return sum(destination['cost'] for destination in plan) + new_destination['cost']
# 使用例
destinations = [
{"name": "Paris", "cost": 1000, "activity": "sightseeing"},
{"name": "Tokyo", "cost": 1200, "activity": "shopping"},
{"name": "New York", "cost": 900, "activity": "sightseeing"},
{"name": "Sydney", "cost": 1100, "activity": "beach"},
]
preferences = {"activity": "sightseeing"}
budget = 2000
travel_agent = TravelAgent(destinations)
initial_plan = travel_agent.bootstrap_plan(preferences, budget)
print("Initial Plan:", initial_plan)
refined_plan = travel_agent.iterate_plan(initial_plan, preferences, budget)
print("Refined Plan:", refined_plan)
コード説明
-
初期化(
__init__メソッド):TravelAgentクラスは、名前、費用、アクティビティタイプなどの属性を持つ潜在的な目的地のリストで初期化されます。 -
計画のブートストラップ(
bootstrap_planメソッド): このメソッドは、顧客の好みと予算に基づいて初期の旅行計画を作成します。目的地リストを反復し、顧客の好みに合致し予算内であれば計画に加えます。 -
好みのマッチング(
match_preferencesメソッド): このメソッドは、目的地が顧客の好みに合っているかをチェックします。 -
計画の反復(
iterate_planメソッド): このメソッドは、計画内の各目的地をより良い選択に置き換えられるか試して計画を洗練し、顧客の好みと予算制約を考慮します。 -
費用計算(
calculate_costメソッド): このメソッドは、現在の計画と追加の候補地を含めた場合の総費用を計算します。
利用例
- 初期計画: 旅行代理店は、観光を好む顧客と予算2000ドルに基づいて初期計画を作成します。
- 洗練された計画: 旅行代理店は、顧客の好みと予算に合わせて計画を反復して最適化します。
明確な目標(例:顧客満足度の最大化)を設定し、それに基づき計画をブートストラップして反復することで、旅行代理店は顧客に対してカスタマイズされ、最適化された旅行日程を作成できます。この方法により、旅行計画は最初から顧客の好みと予算に適合し、反復ごとに改善されます。
リランキングとスコアリングにLLMを活用する
大規模言語モデル(LLM)は、取得した文書や生成された応答の関連性や品質を評価してリランキングやスコアリングに利用できます。仕組みは以下の通りです。
検索: 最初の検索ステップで、クエリに基づいて候補文書または応答のセットを取得します。
リランキング: LLMがこれらの候補を評価し、関連性と品質に基づいて順位を付け直します。これにより、最も関連性が高く質の良い情報が優先して提示されます。
スコアリング: LLMは各候補に関連性と品質を反映したスコアを割り当て、最適な応答や文書の選択を支援します。
LLMを用いたリランキングやスコアリングにより、システムはより正確で文脈に合った情報を提供し、ユーザー体験を向上させます。
以下は、旅行代理店がユーザーの好みに基づいて大規模言語モデル(LLM)を使い、旅行先のリランキングとスコアリングを行うPythonの例です。
シナリオ - 好みに基づく旅行
旅行代理店はクライアントの好みに基づき、最適な旅行先を推奨したいと考えています。LLMは目的地のリランキングとスコアリングを支援し、最も関連性の高い選択肢を提示します。
手順:
- ユーザーの好みを収集する。
- 潜在的な旅行先リストを取得する。
- LLMを使って、ユーザーの好みに基づき旅行先をリランキングおよびスコアリングする。
以下は前の例をAzure OpenAIサービスを使うように更新したものです。
必要条件
- Azureサブスクリプションが必要です。
- Azure OpenAIリソースを作成し、APIキーを取得します。
Pythonコード例
import requests
import json
class TravelAgent:
def __init__(self, destinations):
self.destinations = destinations
def get_recommendations(self, preferences, api_key, endpoint):
# Azure OpenAI のプロンプトを生成する
prompt = self.generate_prompt(preferences)
# リクエストのヘッダーとペイロードを定義する
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {api_key}'
}
payload = {
"prompt": prompt,
"max_tokens": 150,
"temperature": 0.7
}
# 再ランク付けされ、スコア付けされた目的地を取得するために Azure OpenAI API を呼び出す
response = requests.post(endpoint, headers=headers, json=payload)
response_data = response.json()
# 推奨事項を抽出して返す
recommendations = response_data['choices'][0]['text'].strip().split('\n')
return recommendations
def generate_prompt(self, preferences):
prompt = "Here are the travel destinations ranked and scored based on the following user preferences:\n"
for key, value in preferences.items():
prompt += f"{key}: {value}\n"
prompt += "\nDestinations:\n"
for destination in self.destinations:
prompt += f"- {destination['name']}: {destination['description']}\n"
return prompt
# 使用例
destinations = [
{"name": "Paris", "description": "City of lights, known for its art, fashion, and culture."},
{"name": "Tokyo", "description": "Vibrant city, famous for its modernity and traditional temples."},
{"name": "New York", "description": "The city that never sleeps, with iconic landmarks and diverse culture."},
{"name": "Sydney", "description": "Beautiful harbour city, known for its opera house and stunning beaches."},
]
preferences = {"activity": "sightseeing", "culture": "diverse"}
api_key = 'your_azure_openai_api_key'
endpoint = 'https://your-endpoint.com/openai/deployments/your-deployment-name/completions?api-version=2022-12-01'
travel_agent = TravelAgent(destinations)
recommendations = travel_agent.get_recommendations(preferences, api_key, endpoint)
print("Recommended Destinations:")
for rec in recommendations:
print(rec)
コード説明 - Preference Booker
-
初期化:
TravelAgentクラスは、名前や説明などの属性を持つ潜在的な旅行先のリストで初期化されます。 -
推奨の取得(
get_recommendationsメソッド): このメソッドはユーザーの好みに基づくプロンプトをAzure OpenAIサービスに生成し、HTTP POSTリクエストを介してAzure OpenAI APIに送信し、リランキングおよびスコアリングされた旅行先を取得します。 -
プロンプトの生成(
generate_promptメソッド): このメソッドはユーザーの好みと旅行先のリストを含むAzure OpenAI用のプロンプトを構築します。このプロンプトにより、モデルは指定された好みに基づいて旅行先をリランキングしスコアリングします。 -
API呼び出し:
requestsライブラリを使ってAzure OpenAI APIエンドポイントにHTTP POSTリクエストを送信します。レスポンスにはリランキング・スコアリングされた旅行先が含まれます。 -
利用例: 旅行代理店はユーザーの好み(例:観光への興味、多様な文化体験)を収集し、Azure OpenAIサービスを使ってリランキング・スコアリングされた旅行先の推奨を得ます。
your_azure_openai_api_key は実際のAzure OpenAI APIキーに、https://your-endpoint.com/... はAzure OpenAIの実際のエンドポイントURLに置き換えてください。
LLMを活用したリランキング・スコアリングにより、旅行代理店はよりパーソナライズされ関連性の高い旅行の推奨を顧客に提供し、体験の質を高められます。
RAG:プロンプティング技術とツールの違い
Retrieval-Augmented Generation(RAG)は、AIエージェント開発においてプロンプティング技術としてもツールとしても利用可能です。両者の違いを理解することで、RAGをより効果的に活用できます。
プロンプティング技術としてのRAG
概要
- プロンプティング技術では、RAGは特定のクエリやプロンプトを作成して大規模コーパスやデータベースから関連情報を取得し、その情報を用いて応答やアクションを生成します。
仕組み
- プロンプトの作成: タスクやユーザー入力に基づいて構造化されたプロンプトやクエリを作成します。
- 情報の取得: プロンプトを使い、既存の知識ベースやデータセットから関連データを検索します。
- 応答の生成: 取得した情報と生成AIモデルを組み合わせて包括的で整合性のある応答を作成します。
旅行代理店の例:
- ユーザー入力: 「パリの博物館を訪れたい。」
- プロンプト: 「パリの主要な博物館を見つけてください。」
- 取得情報: ルーブル美術館、オルセー美術館などの詳細。
- 生成応答: 「パリの主要な博物館はこちらです:ルーブル美術館、オルセー美術館、ポンピドゥーセンター。」
ツールとしてのRAG
概要
- ツールとしてのRAGは、取得と生成プロセスを自動化する統合システムで、開発者がクエリごとに手動でプロンプトを作成することなく高度なAI機能を実現します。
仕組み
- 統合: RAGをAIエージェントのアーキテクチャに組み込み、取得と生成タスクを自動処理します。
- 自動化: 入力の受け取りから最終応答の生成までの一連の流れを自動で管理し、各ステップごとに明示的なプロンプトを必要としません。
- 効率化: 取得と生成の過程を効率化し、迅速かつ正確な応答を可能にします。
旅行代理店の例:
- ユーザー入力: 「パリの博物館を訪れたい。」
- RAGツール: 自動で博物館情報を取得し応答を生成。
- 生成応答: 「パリの主要な博物館はこちらです:ルーブル美術館、オルセー美術館、ポンピドゥーセンター。」
比較表
| 項目 | プロンプティング技術 | ツール |
|---|---|---|
| 手動 vs 自動 | クエリごとに手動でプロンプトを作成 | 取得と生成を自動化 |
| 制御 | 取得プロセスをより細かく制御可能 | 取得と生成を効率的に自動化 |
| 柔軟性 | 特定のニーズに合わせたカスタムプロンプトが可能 | 大規模実装に向けて効率的 |
| 複雑さ | プロンプトの作成・調整が必要 | AIエージェントのアーキテクチャに統合しやすい |
実践例
プロンプティング技術の例:
def search_museums_in_paris():
prompt = "Find top museums in Paris"
search_results = search_web(prompt)
return search_results
museums = search_museums_in_paris()
print("Top Museums in Paris:", museums)
ツールの例:
class Travel_Agent:
def __init__(self):
self.rag_tool = RAGTool()
def get_museums_in_paris(self):
user_input = "I want to visit museums in Paris."
response = self.rag_tool.retrieve_and_generate(user_input)
return response
travel_agent = Travel_Agent()
museums = travel_agent.get_museums_in_paris()
print("Top Museums in Paris:", museums)
関連性の評価
関連性の評価は、AIエージェントの性能において極めて重要です。取得および生成された情報が適切で正確かつユーザーに役立つものであることを保証します。ここでは、AIエージェントでの関連性評価方法について、実践例や技術を交えて解説します。
関連性評価の主要概念
- コンテキスト理解:
- エージェントはユーザーのクエリの文脈を理解し、関連情報の取得と生成を行う必要があります。
- 例:「パリのおすすめレストラン」であれば、ユーザーの好み(料理ジャンル、予算など)を考慮すべきです。
- 正確性:
- 提供される情報は事実に即しており、最新でなければなりません。
- 例:現在営業中で良い評価のレストランを推奨し、閉店や古い情報は避ける。
- ユーザー意図:
- エージェントはクエリの背後にあるユーザーの意図を推測し、最も関連性の高い情報を提供する必要があります。
- 例:「予算に優しいホテル」であれば、手ごろな価格帯を優先します。
- フィードバックループ:
- ユーザーの評価やフィードバックを継続的に収集・分析して関連性評価を改善します。
- 例:過去の推奨に対するユーザー評価を反映し、今後の応答を向上させる。
関連性評価の実践的技術
- 関連性スコアリング:
- 取得した各アイテムに対し、クエリやユーザー好みへの適合度に基づいて関連性スコアを割り当てます。
-
例:
def relevance_score(item, query): score = 0 if item['category'] in query['interests']: score += 1 if item['price'] <= query['budget']: score += 1 if item['location'] == query['destination']: score += 1 return score
- フィルタリングとランキング:
- 関連性の低い項目を除外し、残った項目を関連性スコア順に並べます。
-
例:
def filter_and_rank(items, query): ranked_items = sorted(items, key=lambda item: relevance_score(item, query), reverse=True) return ranked_items[:10] # 上位10件の関連アイテムを返します
- 自然言語処理(NLP):
- NLP手法を使い、ユーザーのクエリの意味を理解して関連情報を抽出します。
-
例:
def process_query(query): # ユーザーのクエリから主要な情報を抽出するためにNLPを使用する processed_query = nlp(query) return processed_query
- ユーザーフィードバック統合:
- 提供した推奨へのフィードバックを収集し、将来の関連性評価に反映させます。
-
例:
def adjust_based_on_feedback(feedback, items): for item in items: if item['name'] in feedback['liked']: item['relevance'] += 1 if item['name'] in feedback['disliked']: item['relevance'] -= 1 return items
例:旅行代理店における関連性評価
以下は、旅行代理店が旅行推奨の関連性を評価する実践例です。
class Travel_Agent:
def __init__(self):
self.user_preferences = {}
self.experience_data = []
def gather_preferences(self, preferences):
self.user_preferences = preferences
def retrieve_information(self):
flights = search_flights(self.user_preferences)
hotels = search_hotels(self.user_preferences)
attractions = search_attractions(self.user_preferences)
return flights, hotels, attractions
def generate_recommendations(self):
flights, hotels, attractions = self.retrieve_information()
ranked_hotels = self.filter_and_rank(hotels, self.user_preferences)
itinerary = create_itinerary(flights, ranked_hotels, attractions)
return itinerary
def filter_and_rank(self, items, query):
ranked_items = sorted(items, key=lambda item: self.relevance_score(item, query), reverse=True)
return ranked_items[:10] # 上位10件の関連アイテムを返します
def relevance_score(self, item, query):
score = 0
if item['category'] in query['interests']:
score += 1
if item['price'] <= query['budget']:
score += 1
if item['location'] == query['destination']:
score += 1
return score
def adjust_based_on_feedback(self, feedback, items):
for item in items:
if item['name'] in feedback['liked']:
item['relevance'] += 1
if item['name'] in feedback['disliked']:
item['relevance'] -= 1
return items
# 使用例
travel_agent = Travel_Agent()
preferences = {
"destination": "Paris",
"dates": "2025-04-01 to 2025-04-10",
"budget": "moderate",
"interests": ["museums", "cuisine"]
}
travel_agent.gather_preferences(preferences)
itinerary = travel_agent.generate_recommendations()
print("Suggested Itinerary:", itinerary)
feedback = {"liked": ["Louvre Museum"], "disliked": ["Eiffel Tower (too crowded)"]}
updated_items = travel_agent.adjust_based_on_feedback(feedback, itinerary['hotels'])
print("Updated Itinerary with Feedback:", updated_items)
意図に基づく検索
意図に基づく検索とは、ユーザーのクエリの背後にある目的や目標を理解・解釈して、最も関連性が高く有用な情報を取得・生成することを意味します。このアプローチは単にキーワードを一致させるだけでなく、ユーザーの真のニーズや文脈を把握することに注力します。
意図に基づく検索の主要概念
- ユーザー意図の理解:
- ユーザー意図は大きく情報取得意図、ナビゲーション意図、取引意図の3つに分類されます。
- 情報取得意図: トピックに関する情報を求めている(例:「パリのおすすめ博物館は?」)。
- ナビゲーション意図: 特定のウェブサイトやページへ移動したい(例:「ルーブル美術館公式サイト」)。
- 取引意図: 予約や購入などの取引を目的としている(例:「パリ行きの航空券を予約」)。
- ユーザー意図は大きく情報取得意図、ナビゲーション意図、取引意図の3つに分類されます。
- コンテキスト理解:
- クエリの文脈を分析し、過去のやり取り、ユーザーの好み、現在のクエリの詳細を考慮して正確に意図を識別します。
- 自然言語処理(NLP):
- ユーザーの自然言語クエリを理解・解釈するために、固有表現抽出、感情分析、クエリ解析などのNLP技術を活用します。
- パーソナライズ:
- ユーザーの履歴、好み、フィードバックを基に検索結果をパーソナライズし、情報の関連性を向上させます。
実践例:旅行代理店の意図に基づく検索
以下は、旅行代理店における意図に基づく検索の実装例です。
-
ユーザーの好み収集
class Travel_Agent: def __init__(self): self.user_preferences = {} def gather_preferences(self, preferences): self.user_preferences = preferences -
ユーザー意図の理解
def identify_intent(query): if "book" in query or "purchase" in query: return "transactional" elif "website" in query or "official" in query: return "navigational" else: return "informational" - コンテキスト理解
def analyze_context(query, user_history): # 現在のクエリをユーザーの履歴と組み合わせてコンテキストを理解する context = { "current_query": query, "user_history": user_history } return context -
検索と結果のパーソナライズ
def search_with_intent(query, preferences, user_history): intent = identify_intent(query) context = analyze_context(query, user_history) if intent == "informational": search_results = search_information(query, preferences) elif intent == "navigational": search_results = search_navigation(query) elif intent == "transactional": search_results = search_transaction(query, preferences) personalized_results = personalize_results(search_results, user_history) return personalized_results def search_information(query, preferences): # 情報取得意図のための検索ロジックの例 results = search_web(f"best {preferences['interests']} in {preferences['destination']}") return results def search_navigation(query): # ナビゲーション意図のための検索ロジックの例 results = search_web(query) return results def search_transaction(query, preferences): # トランザクション意図のための検索ロジックの例 results = search_web(f"book {query} to {preferences['destination']}") return results def personalize_results(results, user_history): # パーソナライズロジックの例 personalized = [result for result in results if result not in user_history] return personalized[:10] # トップ10のパーソナライズされた結果を返す -
使用例
travel_agent = Travel_Agent() preferences = { "destination": "Paris", "interests": ["museums", "cuisine"] } travel_agent.gather_preferences(preferences) user_history = ["Louvre Museum website", "Book flight to Paris"] query = "best museums in Paris" results = search_with_intent(query, preferences, user_history) print("Search Results:", results)
4. ツールとしてのコード生成
コード生成エージェントはAIモデルを使ってコードを書き、実行することで複雑な問題を解決し、タスクを自動化します。
コード生成エージェント
コード生成エージェントは生成的AIモデルを用いてコードを書き、実行します。これらのエージェントは、様々なプログラミング言語でコードを生成および実行することで、複雑な問題を解決し、タスクを自動化し、有益な洞察を提供します。
実践例
- 自動コード生成: データ分析、ウェブスクレイピング、機械学習など特定のタスク用のコードスニペットを生成します。
- RAGとしてのSQL: データベースからデータを取得・操作するためのSQLクエリを使用します。
- 問題解決: アルゴリズムの最適化やデータ解析など具体的な問題を解決するコードを作成し実行します。
例: データ分析用コード生成エージェント
コード生成エージェントを設計すると想定します。機能は以下の通りです:
- タスク: データセットを分析してトレンドやパターンを特定する。
- 手順:
- データセットをデータ分析ツールに読み込む。
- データをフィルタして集計するSQLクエリを生成する。
- クエリを実行して結果を取得する。
- 取得結果をもとに可視化や洞察を生成する。
- 必要なリソース: データセットへのアクセス、データ分析ツール、SQL機能。
- 経験: 過去の分析結果を利用して将来の分析の精度と関連性を向上させる。
例: 旅行代理店向けコード生成エージェント
この例では、コード生成エージェント Travel Agent を設計します。生成的AIを用いてコードを生成・実行し、旅行計画の補助を行います。このエージェントは、旅行オプションの取得、結果のフィルタリング、旅程の作成などを処理します。
コード生成エージェントの概要
- ユーザープリファレンスの収集: 行き先、旅行日程、予算、興味などユーザー入力を集めます。
- データ取得コードの生成: フライト、ホテル、観光地情報を取得するコードスニペットを生成します。
- 生成コードの実行: コードを実行してリアルタイム情報を取得します。
- 旅程の生成: 取得データをまとめてパーソナライズされた旅行計画を作成します。
- フィードバックに基づく調整: ユーザーのフィードバックを受けて必要ならコードを再生成し、結果を改善します。
実装ステップ
-
ユーザープリファレンスの収集
class Travel_Agent: def __init__(self): self.user_preferences = {} def gather_preferences(self, preferences): self.user_preferences = preferences -
データ取得コードの生成
def generate_code_to_fetch_data(preferences): # 例: ユーザーの好みに基づいてフライトを検索するコードを生成する code = f""" def search_flights(): import requests response = requests.get('https://api.example.com/flights', params={preferences}) return response.json() """ return code def generate_code_to_fetch_hotels(preferences): # 例: ホテルを検索するコードを生成する code = f""" def search_hotels(): import requests response = requests.get('https://api.example.com/hotels', params={preferences}) return response.json() """ return code -
生成コードの実行
def execute_code(code): # 生成されたコードをexecを使って実行する exec(code) result = locals() return result travel_agent = Travel_Agent() preferences = { "destination": "Paris", "dates": "2025-04-01 to 2025-04-10", "budget": "moderate", "interests": ["museums", "cuisine"] } travel_agent.gather_preferences(preferences) flight_code = generate_code_to_fetch_data(preferences) hotel_code = generate_code_to_fetch_hotels(preferences) flights = execute_code(flight_code) hotels = execute_code(hotel_code) print("Flight Options:", flights) print("Hotel Options:", hotels) -
旅程の生成
def generate_itinerary(flights, hotels, attractions): itinerary = { "flights": flights, "hotels": hotels, "attractions": attractions } return itinerary attractions = search_attractions(preferences) itinerary = generate_itinerary(flights, hotels, attractions) print("Suggested Itinerary:", itinerary) -
フィードバックに基づく調整
def adjust_based_on_feedback(feedback, preferences): # ユーザーフィードバックに基づいて設定を調整する if "liked" in feedback: preferences["favorites"] = feedback["liked"] if "disliked" in feedback: preferences["avoid"] = feedback["disliked"] return preferences feedback = {"liked": ["Louvre Museum"], "disliked": ["Eiffel Tower (too crowded)"]} updated_preferences = adjust_based_on_feedback(feedback, preferences) # 更新された設定でコードを再生成および実行する updated_flight_code = generate_code_to_fetch_data(updated_preferences) updated_hotel_code = generate_code_to_fetch_hotels(updated_preferences) updated_flights = execute_code(updated_flight_code) updated_hotels = execute_code(updated_hotel_code) updated_itinerary = generate_itinerary(updated_flights, updated_hotels, attractions) print("Updated Itinerary:", updated_itinerary)
環境認識と推論の活用
表のスキーマに基づく環境認識と推論を活用することで、クエリ生成プロセスの質を高めることができます。
例は以下の通りです:
- スキーマの理解: システムは表のスキーマを理解し、これを基盤にクエリ生成を行います。
- フィードバックに基づく調整: フィードバックをもとにユーザープリファレンスを調整し、スキーマのどのフィールドを更新すべきか推論します。
- クエリの生成と実行: 調整されたプリファレンスに基づき、最新のフライト・ホテルデータを取得するクエリを生成し実行します。
以下はこれらの概念を踏まえたPythonコード例です:
def adjust_based_on_feedback(feedback, preferences, schema):
# ユーザーのフィードバックに基づいて設定を調整する
if "liked" in feedback:
preferences["favorites"] = feedback["liked"]
if "disliked" in feedback:
preferences["avoid"] = feedback["disliked"]
# スキーマに基づいて他の関連する設定を調整するための推論
for field in schema:
if field in preferences:
preferences[field] = adjust_based_on_environment(feedback, field, schema)
return preferences
def adjust_based_on_environment(feedback, field, schema):
# スキーマとフィードバックに基づいて設定を調整するカスタムロジック
if field in feedback["liked"]:
return schema[field]["positive_adjustment"]
elif field in feedback["disliked"]:
return schema[field]["negative_adjustment"]
return schema[field]["default"]
def generate_code_to_fetch_data(preferences):
# 更新された設定に基づいてフライトデータを取得するコードを生成する
return f"fetch_flights(preferences={preferences})"
def generate_code_to_fetch_hotels(preferences):
# 更新された設定に基づいてホテルデータを取得するコードを生成する
return f"fetch_hotels(preferences={preferences})"
def execute_code(code):
# コードの実行をシミュレートし、モックデータを返す
return {"data": f"Executed: {code}"}
def generate_itinerary(flights, hotels, attractions):
# フライト、ホテル、観光地に基づいて旅程を生成する
return {"flights": flights, "hotels": hotels, "attractions": attractions}
# スキーマの例
schema = {
"favorites": {"positive_adjustment": "increase", "negative_adjustment": "decrease", "default": "neutral"},
"avoid": {"positive_adjustment": "decrease", "negative_adjustment": "increase", "default": "neutral"}
}
# 使用例
preferences = {"favorites": "sightseeing", "avoid": "crowded places"}
feedback = {"liked": ["Louvre Museum"], "disliked": ["Eiffel Tower (too crowded)"]}
updated_preferences = adjust_based_on_feedback(feedback, preferences, schema)
# 更新された設定でコードを再生成して実行する
updated_flight_code = generate_code_to_fetch_data(updated_preferences)
updated_hotel_code = generate_code_to_fetch_hotels(updated_preferences)
updated_flights = execute_code(updated_flight_code)
updated_hotels = execute_code(updated_hotel_code)
updated_itinerary = generate_itinerary(updated_flights, updated_hotels, feedback["liked"])
print("Updated Itinerary:", updated_itinerary)
説明 - フィードバックに基づく予約調整
- スキーマ認識:
schema辞書はフィードバックに基づきどのようにプリファレンスを調整するか定義しています。favoritesやavoidといったフィールドが含まれ、それぞれの調整内容が記述されています。 - プリファレンスの調整メソッド (
adjust_based_on_feedback): ユーザーフィードバックとスキーマに基づきプリファレンスを調整します。 - 環境ベースの調整メソッド (
adjust_based_on_environment): スキーマとフィードバックを用いて調整内容をカスタマイズします。 - クエリの生成と実行: 調整済みプリファレンスに基づき、更新されたフライトとホテルデータを取得するコードを生成、実行をシミュレートします。
- 旅程の生成: 新しいフライト、ホテル、観光地情報に基づき旅程を更新して作成します。
システムを環境認識かつスキーマに基づいた推論が可能にすることで、より正確かつ関連性の高いクエリを生成し、より良い旅行推奨と個別化されたユーザー体験を実現できます。
SQLをRetrieval-Augmented Generation (RAG)技術として活用する
SQL(Structured Query Language)はデータベースと対話する強力なツールです。RAGアプローチの一環として利用する場合、SQLはデータベースから関連データを取得し、AIエージェントの応答やアクション生成に役立てられます。ここではTravel AgentにおけるRAG技術としてのSQLの使い方を解説します。
主要コンセプト
- データベース操作:
- SQLはデータベースにクエリを送り、関連情報を取得し、データを操作します。
- 例: 旅行データベースからフライト情報、ホテル情報、観光地情報を取得。
- RAGとの統合:
- ユーザー入力やプリファレンスに基づきSQLクエリを生成します。
- 取得データはパーソナライズされた推奨やアクション生成に活用されます。
- 動的クエリ生成:
- AIエージェントは文脈やユーザー要望に応じて動的にSQLクエリを生成します。
- 例: 予算、日程、興味に合わせて結果をフィルタリングするSQLクエリ。
活用例
- 自動コード生成: 特定タスク用のコードスニペット生成。
- RAGとしてのSQL: データ操作にSQLクエリ使用。
- 問題解決: 問題解決コードの作成・実行。
例: データ分析エージェント
- タスク: データセット分析でトレンド検出。
- ステップ:
- データセットの読み込み。
- データフィルタリング用SQLクエリ生成。
- クエリ実行・結果取得。
- 可視化・洞察生成。
- リソース: データセットアクセス、SQL機能。
- 経験: 過去結果を利用し分析精度向上。
実例:Travel AgentでのSQL活用
-
ユーザープリファレンスの収集
class Travel_Agent: def __init__(self): self.user_preferences = {} def gather_preferences(self, preferences): self.user_preferences = preferences -
SQLクエリの生成
def generate_sql_query(table, preferences): query = f"SELECT * FROM {table} WHERE " conditions = [] for key, value in preferences.items(): conditions.append(f"{key}='{value}'") query += " AND ".join(conditions) return query -
SQLクエリの実行
import sqlite3 def execute_sql_query(query, database="travel.db"): connection = sqlite3.connect(database) cursor = connection.cursor() cursor.execute(query) results = cursor.fetchall() connection.close() return results -
推奨の生成
def generate_recommendations(preferences): flight_query = generate_sql_query("flights", preferences) hotel_query = generate_sql_query("hotels", preferences) attraction_query = generate_sql_query("attractions", preferences) flights = execute_sql_query(flight_query) hotels = execute_sql_query(hotel_query) attractions = execute_sql_query(attraction_query) itinerary = { "flights": flights, "hotels": hotels, "attractions": attractions } return itinerary travel_agent = Travel_Agent() preferences = { "destination": "Paris", "dates": "2025-04-01 to 2025-04-10", "budget": "moderate", "interests": ["museums", "cuisine"] } travel_agent.gather_preferences(preferences) itinerary = generate_recommendations(preferences) print("Suggested Itinerary:", itinerary)
SQLクエリ例
-
フライトクエリ
SELECT * FROM flights WHERE destination='Paris' AND dates='2025-04-01 to 2025-04-10' AND budget='moderate'; -
ホテルクエリ
SELECT * FROM hotels WHERE destination='Paris' AND budget='moderate'; -
観光地クエリ
SELECT * FROM attractions WHERE destination='Paris' AND interests='museums, cuisine';
RAG技術の一部としてSQLを活用することで、Travel AgentのようなAIエージェントは動的に関連データを取得し、正確でパーソナライズされた推奨が可能になります。
メタ認知の例
メタ認知の実装例を示すため、問題解決中に意思決定プロセスを振り返る単純なエージェントを作成します。この例では、価格と品質の組み合わせでホテルを選択した後、自己の推論を評価し、誤ったまたは最適でない選択に対して戦略を調整します。
簡単な例を用います:エージェントは価格が安いホテルを選択しますが、その後決定を振り返り、必要に応じて調整します。
メタ認知の説明
- 初期決定: 価格が最も安いホテルを選び、品質影響の理解はしません。
- 振り返りと評価: 初期選択後にユーザーフィードバックを見て、そのホテルが「悪い選択」かどうかを評価します。品質が十分ではないと判断した場合、推論を振り返ります。
- 戦略調整: 振り返りに基づき戦略を調整し、「最も安い」から「最高品質」に切り替え、今後の意思決定プロセスを改善します。
例示コード:
class HotelRecommendationAgent:
def __init__(self):
self.previous_choices = [] # 以前に選択されたホテルを保存します
self.corrected_choices = [] # 修正された選択肢を保存します
self.recommendation_strategies = ['cheapest', 'highest_quality'] # 利用可能な戦略
def recommend_hotel(self, hotels, strategy):
"""
Recommend a hotel based on the chosen strategy.
The strategy can either be 'cheapest' or 'highest_quality'.
"""
if strategy == 'cheapest':
recommended = min(hotels, key=lambda x: x['price'])
elif strategy == 'highest_quality':
recommended = max(hotels, key=lambda x: x['quality'])
else:
recommended = None
self.previous_choices.append((strategy, recommended))
return recommended
def reflect_on_choice(self):
"""
Reflect on the last choice made and decide if the agent should adjust its strategy.
The agent considers if the previous choice led to a poor outcome.
"""
if not self.previous_choices:
return "No choices made yet."
last_choice_strategy, last_choice = self.previous_choices[-1]
# 最後の選択が良かったかどうかを示すユーザーフィードバックがあると仮定します
user_feedback = self.get_user_feedback(last_choice)
if user_feedback == "bad":
# 前回の選択が満足できなかった場合に戦略を調整します
new_strategy = 'highest_quality' if last_choice_strategy == 'cheapest' else 'cheapest'
self.corrected_choices.append((new_strategy, last_choice))
return f"Reflecting on choice. Adjusting strategy to {new_strategy}."
else:
return "The choice was good. No need to adjust."
def get_user_feedback(self, hotel):
"""
Simulate user feedback based on hotel attributes.
For simplicity, assume if the hotel is too cheap, the feedback is "bad".
If the hotel has quality less than 7, feedback is "bad".
"""
if hotel['price'] < 100 or hotel['quality'] < 7:
return "bad"
return "good"
# ホテルのリスト(価格と品質)をシミュレートします
hotels = [
{'name': 'Budget Inn', 'price': 80, 'quality': 6},
{'name': 'Comfort Suites', 'price': 120, 'quality': 8},
{'name': 'Luxury Stay', 'price': 200, 'quality': 9}
]
# エージェントを作成します
agent = HotelRecommendationAgent()
# ステップ1: エージェントは「最安値」戦略を使ってホテルを推薦します
recommended_hotel = agent.recommend_hotel(hotels, 'cheapest')
print(f"Recommended hotel (cheapest): {recommended_hotel['name']}")
# ステップ2: エージェントは選択を振り返り、必要に応じて戦略を調整します
reflection_result = agent.reflect_on_choice()
print(reflection_result)
# ステップ3: エージェントは調整された戦略を使って再度推薦します
adjusted_recommendation = agent.recommend_hotel(hotels, 'highest_quality')
print(f"Adjusted hotel recommendation (highest_quality): {adjusted_recommendation['name']}")
エージェントのメタ認知能力
重要なのは、エージェントが以下を行えることです:
- 過去の選択や意思決定プロセスを評価する。
- その振り返りに基づいて戦略を調整する。つまり、メタ認知の実践。
これは内部フィードバックに基づいて推論過程を調整可能なシステムによる、単純なメタ認知の形態です。
結論
メタ認知はAIエージェントの能力を大幅に高める強力なツールです。メタ認知プロセスを組み込むことで、より賢く、適応的で効率的なエージェントを設計できます。追加リソースでAIエージェントにおけるメタ認知の魅力的な世界をさらに探求してください。
メタ認知デザインパターンについて質問はありますか?
Microsoft Foundry Discordに参加して他の学習者と交流し、オフィスアワーに参加してAIエージェントの質問を解決しましょう。
前のレッスン
次のレッスン
免責事項:
本書類はAI翻訳サービス「Co-op Translator」(https://github.com/Azure/co-op-translator)を使用して翻訳されています。正確性の向上に努めておりますが、自動翻訳には誤りや不正確な箇所が含まれる可能性があることをご了承ください。原文の言語による文書が正式な情報源となります。重要な情報については、専門の人間による翻訳を推奨いたします。本翻訳の使用に伴う誤解や誤訳について、当方は一切の責任を負いかねます。