ai-agents-for-beginners

(ഈ പാഠത്തിന്റെ വീഡിയോ കാണുന്നതിനായി മുകളിലുള്ള ചിത്രം ക്ലിക്ക് ചെയ്യുക)
എഐ ഏജന്റുകളിലെ മെറ്റാകോഗ്നിഷൻ
പരിചയം
എഐ ഏജന്റുകളിൽ മെറ്റാകോഗ്നിഷൻ സംബന്ധിച്ച പാഠത്തിലേക്ക് സ്വാഗതം! ഇതിനുള്ള അധ്യായം, സ്വന്തം ചിന്താപ്രക്രിയകൾതന്നെ കുറിച്ചാണ് ഏജന്റുകൾ എങ്ങനെ ചിന്തിക്കാം എന്നതിൽ കൗതുകമുള്ള തുടങ്ങിയവർക്കാണ് രൂപകൽപ്പന ചെയ്തിരിക്കുന്നത്. ഈ പാഠം പൂർത്തിയാക്കിയപ്പോൾ, നിങ്ങൾ മുഖ്യ ആശയങ്ങൾ മനസിലാക്കി മെറ്റാകോഗ്നിഷൻ എഐ ഏജന്റ് രൂപകൽപ്പനയിൽ പ്രായോഗിക ഉദാഹരണങ്ങൾ ഉപയോഗിച്ച് പ്രയോഗിക്കാൻ സാധിക്കുമെന്ന് ഉറപ്പാണ്.
പഠന ലക്ഷ്യങ്ങൾ
ഈ പാഠം പൂർത്തിയാക്കിയശേഷം, നിങ്ങൾക്ക് കഴിയും:
- ഏജന്റ് നിർവചനങ്ങളിൽ റീസണിംഗ് ലूपുകളുടെ പ്രത്യാഘാതങ്ങൾ മനസ്സിലാക്കാൻ.
- സ്വയം തിരുത്താനുള്ള ഏജന്റുകൾക്ക് സഹായിക്കുന്നതിനായി പദ്ധതിയിടൽ (planning)യും മൂല്യനിർണയ (evaluation) സാങ്കേതികതകളും ഉപയോഗിക്കാൻ.
- ടാസ്കുകൾ പൂർത്തിയാക്കാൻ കോഡ് മനുഷ്യമാർഗ്ഗമായി കൈകാര്യം ചെയ്യുന്ന നിങ്ങളുടെ സ്വന്തം ഏജന്റുകൾ സൃഷ്ടിക്കാൻ.
മെറ്റാകോഗ്നിഷനിലേക്ക് പരിചയം
മെറ്റാകോഗ്നിഷൻ എന്ന് പറയുന്നത് സ്വന്തം ചിന്തയെക്കുറിച്ചുള്ള ചിന്ത എന്നിവയുമായി ബന്ധപ്പെട്ട ഉയർന്ന ക്രമത്തിലുള്ള സംഘട്ടനാത്മക പ്രക്രിയകളെയാണ് സൂചിപ്പിക്കുന്നത്. എഐ ഏജന്റുകൾക്കായി, ഇതിന്റെ അർത്ഥം അവരുടെ പ്രവൃത്തികളെ സ്വയം ബോധ്യമായി വിലയിരുത്താനും പഴയ അനുഭവങ്ങളെ അടിസ്ഥാനമാക്കി അവ പുരോഗമിപ്പിച്ചും മാറ്റം വരുത്താനുമായി ഉള്ള കഴിവാണ്. “ചിന്തയെപ്പറ്റി ചിന്തിക്കുന്നത്” എന്നത് ഏജന്റ് വാസ്തവത്തിൽ അവരുടെ ആഭ്യന്തര പ്രക്രിയകൾ അറിയുകയും അവ നിരീക്ഷിക്കുകയും നിയന്ത്രിക്കുകയും കൂട്ടിച്ചേർക്കുകയും ചെയ്യാൻ ശേഷിയുള്ളതിനെ ഉൾക്കൊള്ളുന്നു. നാം ഏതെങ്കിലും ოთახം വായിക്കുമ്പോൾ അല്ലെങ്കിൽ ഒരു പ്രശ്നം പരിശോധിക്കുമ്പോൾ ചെയ്യുന്നത് പോലെ തന്നെ. ഈ സ്വയംബോധം എഐ സിസ്റ്റങ്ങൾക്ക് നല്ല തീരുമാനങ്ങൾ എടുക്കാൻ, പിഴവുകൾ കണ്ടെത്താൻ, കഴിഞ്ഞ കാലക്രമത്തിൽ പ്രകടനം മെച്ചപ്പെടുത്താൻ സഹായിക്കുന്നു — വീണ്ടും ട്യൂറിങ് പരിശോധനയിലേക്കും എഐ takeover ചെയ്യുമോ എന്ന ചർച്ചയിലേക്കും തിരിച്ചുള്ള ബന്ധം.
ഏജന്റിക് എഐ സിസ്റ്റങ്ങളുടെ സാഹചര്യത്തിൽ, മെറ്റാകോഗ്നിഷൻ നിരവധി വെല്ലുവിളികൾ പരിഹരിക്കാൻ സഹായിക്കാം, ഉദാഹരണത്തിന്:
- ഗൗരവത്വം (Transparency): എഐ സിസ്റ്റങ്ങൾ അവരുടെ ഉത്തരവാദിത്വവും തീരുമാനം എടുക്കൽ രീതികളും വിശദീകരിക്കാൻ സാധിക്കുന്നുണ്ടാകണം.
- റീസണിംഗ് (Reasoning): വിവരങ്ങൾ സംയോജിപ്പിക്കുകയും ശാസ്ത്രീയമായ തീരുമാനം എടുക്കുകയും ചെയ്യാനുള്ള കഴിവ് മെച്ചപ്പെടുത്തൽ.
- അനുയോജ്യാക്കൽ (Adaptation): പുതിയ പരിസരങ്ങളിലേക്കും മാറ്റമുണ്ടായ സാഹചര്യങ്ങളിലേക്കും എഐ സിസ്റ്റങ്ങൾ തഖ്സീമാകാൻ അനുവദിക്കുക.
- അനുഭവവൽക്കരണം (Perception): പരിസ്ഥിതി നിന്നുള്ള ഡാറ്റ തിരിച്ചറിയാനും വ്യാഖ്യാനിക്കാനുമുള്ള കൃത്യത മെച്ചപ്പെടുത്തൽ.
മെറ്റാകോഗ്നിഷൻ എന്താണ്?
മെറ്റാകോഗ്നിഷൻ, അല്ലെങ്കിൽ “ചിന്തയെക്കുറിച്ചുള്ള ചിന്ത”, الذاتാവബോധത്തെയും ഓർമ്മാന്വേഷണത്തെയും ഉൾക്കൊള്ളുന്ന ഉയർന്ന ക്രമത്തിലുള്ള സാങ്കേതിക പ്രക്രിയയാണ്. എഐ രംഗത്ത്, മെറ്റാകോഗ്നിഷൻ ഏജന്റുകൾക്ക് അവരുടെ തന്ത്രങ്ങളും പ്രവർത്തികളും വിലയിരുത്തുകയും അനുകൂലമാക്കുകയും ചെയ്യാൻ ശക്തി നൽകുന്നു, जिससे പ്രശ്നപരിഹാരത്തിലും തീരുമാനം എടുക്കൽ കഴിവിലും മെച്ചമുണ്ടാകും. മെറ്റാകോഗ്നിഷൻ മനസ്സിലാക്കിയാൽ, നിങ്ങൾ സൃഷ്ടിക്കുന്ന എഐ ഏജന്റുകൾ കൂടുതൽ ബുദ്ധിമുട്ടുള്ളതും, കൂടുതൽ അനുയോജ്യവുമും, കാര്യക്ഷമവുമാകാം. യഥാർത്ഥ മെഡ്ടാകോഗ്നിഷനിൽ, എഐത് വ്യക്തമായി അതിന്റെ സ്വന്തം റീസണിങ്ങിനെക്കുറിച്ച് ചിന്തിക്കുകയും ചെയ്യും.
Example: “I prioritized cheaper flights because… I might be missing out on direct flights, so let me re-check.”. ചില രീതികൾ എങ്ങനെ അല്ലെങ്കിൽ എന്തിന് определിച്ചിട്ടെന്നുള്ള കാര്യങ്ങൾ നിരീക്ഷിക്കുക.
- മുൻപ് ഉപയോക്തൃpräതിരുചികൾക്ക്过度 ആശ്രയിച്ചതിനാൽ പിശക് സംഭവിച്ചതെന്ന് ശ്രദ്ധിച്ച്, അത് വെറും അന്തിമ ശിപാർശ മാത്രമല്ല അതിന്റെ തീരുമാനം എടുക്കൽ തന്ത്രം മാറ്റി.
- “ഉപയോക്താവ് ‘വളരെ തിരക്കുള്ളത്’ എന്ന് പറയുമ്പോൾ, നാന് ചില ആകർഷണങ്ങൾ ഒഴിവാക്കണം എന്നാണ് മാത്രമല്ല, ഞാൻ എപ്പോഴും ജനപ്രിയത അടിസ്ഥാനമാക്കി ‘ടോപ്പ് ആകർഷണങ്ങൾ’ തിരഞ്ഞെടുക്കുന്ന രീതിയാണ് മൂടിയിരിക്കുന്നതെന്ന് പ്രതിഫലിപ്പിക്കണം” എന്നപോലുള്ള മാതൃകകൾ നിര്ണയിക്കൽ.
എഐ ഏജന്റുകളിൽ മെറ്റാകോഗ്നിഷന്റെ പ്രാധാന്യം
എഐ ഏജന്റ് രൂപകൽപ്പനയിൽ മെറ്റാകോഗ്നിഷന് ആവശ്യമുണ്ട് നിരവധി കാരണങ്ങൾക്കായി:
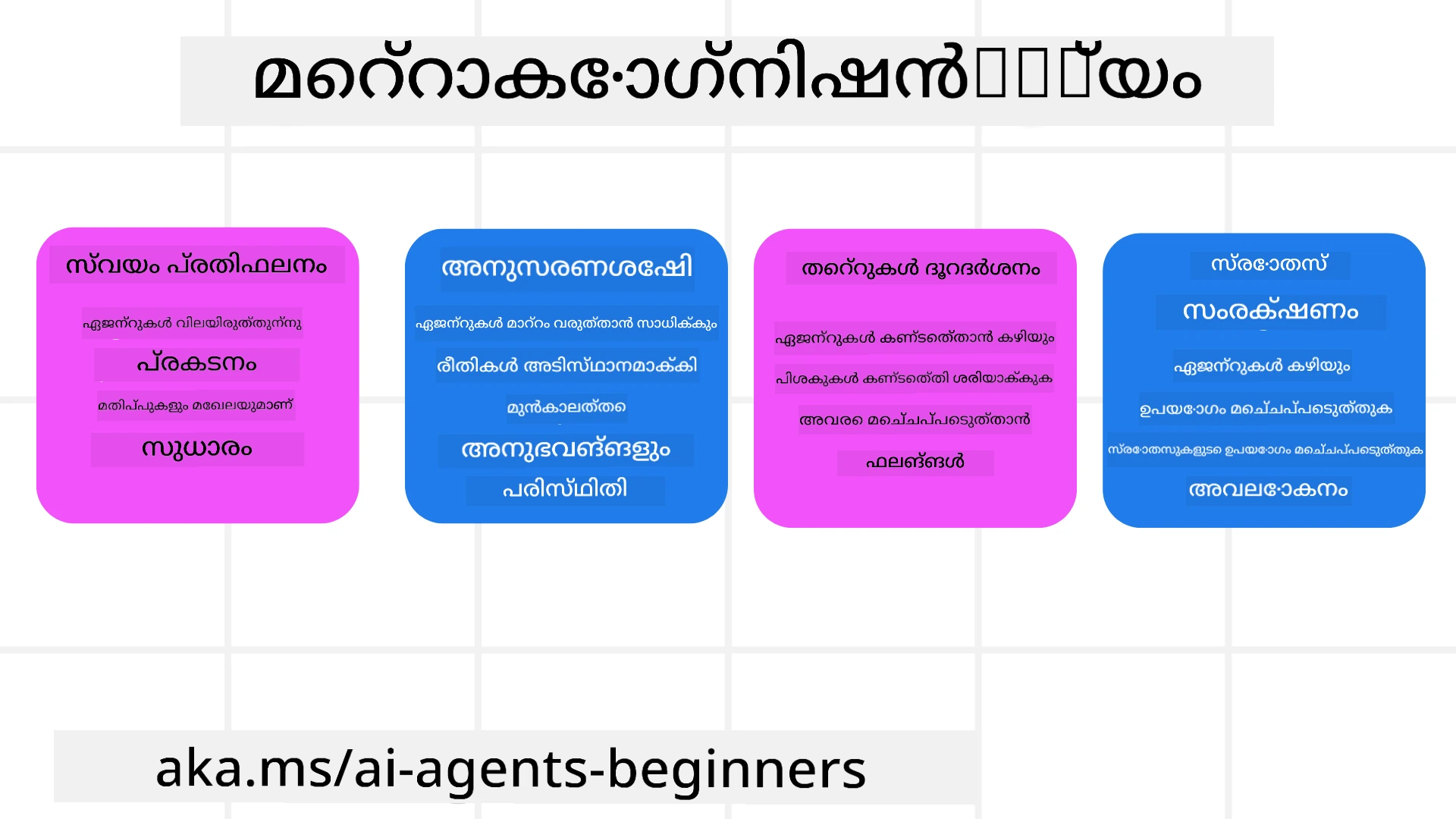
- സ്വയം-പരിശോധന (Self-Reflection): ഏജന്റുകൾ അവരുടെ പ്രകടനം വിലയിരുത്തുകയും മെച്ചപ്പെടുത്താനുള്ള ഭാഗങ്ങൾ കണ്ടെത്തുകയും ചെയ്യാം.
- അനുയോജ്യത (Adaptability): പാശ്ചാത്യാനുഭവങ്ങളും മാറുന്ന പരിതസ്ഥിതികളും അടിസ്ഥാനമാക്കി തന്ത്രങ്ങൾ പരിഷ്കരിക്കാൻ ഏജന്റുകൾക്ക് കഴിയും.
- പിശക് ശരിയാക്കൽ (Error Correction): ഏജന്റുകൾ സ്വയം പിശകുകൾ കണ്ടെത്തി ശരിയാക്കാൻ കഴിയും, ഫലമായി കൂടുതൽ കൃത്യമായ ഫലങ്ങൾ ലഭിക്കും.
- ഉറവിടിഗ്രഹണം (Resource Management): സമയവും കണക്ക് ശേഷിയുമുള്ള വിഭവങ്ങളുടെ ഉപയോഗം ആപ്റ്റിമൈസ് ചെയ്യുന്നതിനായി പദ്ധതിയിടലും മൂല്യനിർണയവും നടത്താം.
എഐ ഏജന്റിന്റെ ഘടകങ്ങൾ
മെറ്റാകോഗ്നിറ്റീവ് പ്രക്രിയകളിലേക്ക് ചാടുന്നതിന് മുമ്പ്, ഒരു എഐ ഏജന്റിന്റെ അടിസ്ഥാന ഘടകങ്ങൾ മനസ്സിലാക്കുന്നത് അനിവാര്യമാണ്. ഒരു എഐ ഏജന്റ് സാധാരണയായി താഴെപ്പറയുന്നവയിൽ നിന്നാണ് ഗഠിതമാകുന്നത്:
- Persona: ഏജന്റിന്റെ വ്യക്തിത്വവും സ്വഭാവലക്ഷണങ്ങളും, ഉപയോക്താക്കളുമായി അത് എങ്ങനെ ഇടപഴകുന്നു എന്നത് നിർണ്ണയിക്കുന്നു.
- Tools: ഏജന്റ് ചെയ്യാൻ കഴിയുന്ന ശേഷികളും പ്രവർത്തനങ്ങളും.
- Skills: ഏജന്റിന്റെ അറിവും വിദഗ്ധതയും.
ഈ ഘടകങ്ങൾ ഒരുമിച്ച് പ്രവർത്തിച്ച് പ്രത്യേക താത്പര്യമുള്ള “അറിയുമതൃക യൂണിറ്റ്” ഉണ്ടാക്കുന്നു, അത് നിശ്ചിത ടാസ്ക്കുകൾ നിർവഹിക്കാനാകും.
ഉദാഹരണം: ഒരു ട്രാവൽ ഏജന്റിനെ പരിഗണിക്കുക — നിങ്ങളുടെ ഹോളിഡേ നീട്ടատակപ്പിക്കുന്നതുമായ മാത്രമല്ല, റിയൽ-ടൈം ഡാറ്റയും കഴിഞ്ഞ ഉപഭോക്തൃ യാത്രാനുഭവങ്ങളും അടിസ്ഥാനമാക്കി തന്റെ മാർഗം ചേരുപ്പിക്കുന്ന සේവകൾ.
ഉദാഹരണം: ഒരു ട്രാവൽ ഏജന്റ് സർവീസിൽ മെറ്റാകോഗ്നിഷൻ
നിങ്ങൾ ഒരു എഐ-ചാലിത ട്രാവൽ ഏജന്റ് സേവനം രൂപകൽപ്പന ചെയ്യുകയാണെന്ന് تصورിക്കുക. ഈ ഏജന്റ്, “യാത്രാ ഏജന്റ്”, ഉപയോക്താക്കൾക്ക് അവർക്കുള്ള അവധിക്കാല പദ്ധതികൾ തയ്യാറാക്കാൻ സഹായിക്കുന്നു. മെറ്റാകോഗ്നിഷൻ ഉൾപ്പെടുത്താൻ, യാത്രാ ഏജന്റ് സ്വയം ബോധ്യത്തോടെ പഴയ അനുഭവങ്ങളെ അടിസ്ഥാനമാക്കി തന്റെ പ്രവർത്തനങ്ങൾ വിലയിരുത്തുകയും പരിഷ്കരിക്കുകയും ചെയ്യേണ്ടതുണ്ട്. മെറ്റാകോഗ്നിഷൻ എങ്ങനെ പങ്കുവഹിക്കുമെന്ന് ഇതാ:
നിലവിലെ ടാസ്ക്
നിലവിലെ ടാസ്ക് ഒരു ഉപയോക്താവിന് പരിസ് സന്ദർശനത്തിനുള്ള യാത്ര പദ്ധതിയിടാൻ സഹായിക്കുകയാണ്.
ടാസ്ക് പൂർത്തിയാക്കാനുള്ള ഘടകങ്ങൾ
- ഉപയോക്തൃ പ്രാധാന്യങ്ങൾ ശേഖരിക്കുക: ഉപയോക്താവിന്റെ യാത്രാ തീയതികൾ, ബഡ്ജറ്റ്, താല്പര്യങ്ങൾ (ഉദാ., മ്യൂസിയങ്ങൾ, ഭക്ഷണം, ഷോപ്പിംഗ്) എന്നിവയും ഏതെങ്കിലും പ്രത്യേക ആവശ്യങ്ങളും ചോദിക്കുക.
- വിവരം എടുക്കുക: ഉപയോക്തൃ പ്രാധാന്യങ്ങൾക്ക് അനുയോജ്യമായി ഫ്ലൈറ്റ് ഓപ്ഷനുകൾ, താമസവൈകൽ, ആകർഷണങ്ങൾ, റസ്റ്റോറന്റുകൾ എന്നിവ തിരയുക.
- ശിപാർശകൾ സൃഷ്ടിക്കുക: ചെറിയ വ്യക്തിഗത ഇറ്റിനററി ഫ്ലൈറ്റ് വിശദാംശങ്ങൾ, ഹോട്ടൽ ബുക്കിംഗുകൾ, നിർദ്ദേശിച്ച പ്രവർത്തനങ്ങൾ എന്നിവ സഹിതം നൽകുക.
- ഫീഡ്ബാക്ക് അടിസ്ഥാനമാക്കി ക്രമീകരിക്കുക: ശിപാർശകൾക്കുള്ള ഉപഭോക്തൃ ഫീഡ്ബാക്ക് ചോദിച്ച് ആവശ്യമായ മാറ്റങ്ങൾ ചേര്ക്കുക.
ആവശ്യമായ വിഭവങ്ങൾ
- ഫ്ലൈറ്റ്, ഹോട്ടൽ ബുക്കിംഗ് ഡാറ്റാബേസുകൾക്ക് പ്രവേശനം.
- പരിസിൽ ആകർഷണങ്ങൾക്കും റസ്റ്റോറന്റുകൾക്കും ഉള്ള വിവരങ്ങൾ.
- മുമ്പത്തെ ഇടപെടലുകളിൽ നിന്നുള്ള ഉപയോക്തൃ ഫീഡ്بാക്ക് ഡാറ്റ.
അനുഭവവും സ്വയം-പരിശോധനയും
യാത്രാ ഏജന്റ് അതിന്റെ പ്രകടനം വിലയിരുത്തുന്നതിനും കഴിഞ്ഞ അനുഭവങ്ങളിൽ നിന്നു പഠിക്കാനായി മെറ്റാകോഗ്നിഷൻ ഉപയോഗിക്കുന്നു. ഉദാഹരണങ്ങൾ:
- ഉപയോക്തൃ ഫീഡ്بാക്ക് വിശകലനം: ഏജന്റ് ശുപാർശകൾ വിവരിച്ചുകൊണ്ട് ഏത് ശുപാർശകൾ ഉപയോക്തൃമനസിലാക്കിയവയും ഏത് അല്ലാത്തവയെന്നു പരിശോധിച്ചു, ഭാവിയിലെ ശുപാർശകൾ അതനുസരിച്ച് ക്രമീകരിക്കുന്നു.
- അനുയോജ്യത: ഉപയോക്താവ് മുൻപ് തിരക്കുള്ള ഇടങ്ങൾ ഇഷ്ടപ്പെടാത്തതായി പറഞ്ഞിട്ടുണ്ടെങ്കിൽ, യാത്രാ ഏജന്റ് ഭാവിയിൽ തീവ്ര സമയങ്ങളിൽ ജനപ്രിയ ടൂറിസ്റ്റ് സ്ഥലങ്ങൾ ശുപാർശ ചെയ്യരുതെന്ന് ശ്രദ്ധിക്കും.
- പിശക് ശരിയാക്കൽ: ഒരു പഴയ ബുക്കിംഗിൽ പിശക് സംഭവിച്ചിട്ടുണ്ടെങ്കിൽ (ഉദാ., വശീകരിച്ച ഹോട്ടൽ മുൻപ് geo fully booked ആയിരുന്നെങ്കിൽ), ശുപാർശകൾ നൽകുന്നതിന് മുമ്പെ ലഭ്യത കൂടുതൽ കൃത്യമായി പരിശോധിക്കാൻ പഠിക്കും.
പ്രായോഗിക ഡെവലപ്പർ ഉദാഹരണം
മെറ്റാകോഗ്നിഷൻ ഉൾപ്പെടുത്തുന്ന വിധം യാത്രാ ഏജന്റിന്റെ കോഡ് എങ്ങനെ ലളിതീകരിക്കാവുന്നതാണെന്ന് ഇവിടെ കാണിക്കുന്നു:
class Travel_Agent:
def __init__(self):
self.user_preferences = {}
self.experience_data = []
def gather_preferences(self, preferences):
self.user_preferences = preferences
def retrieve_information(self):
# ഇഷ്ടാനുസരിച്ച് ഫ്ലൈറ്റുകൾ, ഹിപ്പോറ്റലുകൾ, ആകർഷണങ്ങൾ തിരയുക
flights = search_flights(self.user_preferences)
hotels = search_hotels(self.user_preferences)
attractions = search_attractions(self.user_preferences)
return flights, hotels, attractions
def generate_recommendations(self):
flights, hotels, attractions = self.retrieve_information()
itinerary = create_itinerary(flights, hotels, attractions)
return itinerary
def adjust_based_on_feedback(self, feedback):
self.experience_data.append(feedback)
# പ്രതികരണങ്ങൾ വിശകലനം ചെയ്ത് ഭാവിയിലെ ശുപാർശകൾ ക്രമീകരിക്കുക
self.user_preferences = adjust_preferences(self.user_preferences, feedback)
# ഉദാഹരണ ഉപയോഗം
travel_agent = Travel_Agent()
preferences = {
"destination": "Paris",
"dates": "2025-04-01 to 2025-04-10",
"budget": "moderate",
"interests": ["museums", "cuisine"]
}
travel_agent.gather_preferences(preferences)
itinerary = travel_agent.generate_recommendations()
print("Suggested Itinerary:", itinerary)
feedback = {"liked": ["Louvre Museum"], "disliked": ["Eiffel Tower (too crowded)"]}
travel_agent.adjust_based_on_feedback(feedback)
മെറ്റാകോഗ്നിഷൻ എന്തുകൊണ്ട് പ്രധാനമാണ്
- സ്വയം-പരിശോധന: ഏജന്റുകൾ അവരുടെ പ്രകടനം വിശകലനം ചെയ്ത് മെച്ചപ്പെടുത്താനുള്ള ഭാഗങ്ങൾ കണ്ടെത്താം.
- അനുയോജ്യത: ഫീഡ്بാക്കും മാറ്റങ്ങൾ സംഭവിക്കുന്ന സാഹചര്യങ്ങളോടും അടിസ്ഥാനമാക്കി ഏജന്റുകൾ തന്ത്രങ്ങൾ മാറ്റാൻ കഴിയും.
- പിശക് ശരിയാക്കൽ: ഏജന്റുകൾ സ്വയം പിശകുകൾ കണ്ടെത്തി ശരിയാക്കാൻ കഴിയും.
- ഉറവിടം മാനേജ്മെന്റ്: സമയം, കംപ്യൂട്ടേഷണൽ ശക്തി പോലുള്ള വിഭവങ്ങൾ കാര്യക്ഷമമായി ഉപയോഗിക്കാൻ ഏജന്റുകൾ ആപ്റ്റിമൈസ് ചെയ്യാം.
മെറ്റാകോഗ്നിഷൻ ഉൾപ്പെടുത്തിക്കൊണ്ടും, യാത്രാ ഏജന്റ് കൂടുതൽ വ്യക്തിഗതതയും കൃത്യവുമുള്ള യാത്ര ശിപാർശകൾ നൽകാൻ കഴിയും, മൊത്തത്തിലുള്ള ഉപയോക്തൃ അനുഭവം മെച്ചപ്പെടുത്തുന്നു.
2. ഏജന്റുകളിൽ പദ്ധതിയിടൽ (Planning)
പ്ലാനിങ്ങ് എഐ ഏജന്റ് പെരുമാറ്റത്തിന്റെ ഒരു നിർണായക ഘടകമാണ്. ഇത് ലക്ഷ്യം നേടുന്നതിനുള്ള ആവശ്യമായ കാര്യങ്ങൾ, നിലവിലുള്ള അവസ്ഥ, വിഭവങ്ങൾ, സാധ്യതയുള്ള തടസം എന്നിവ പരിഗണിച്ച് പാദങ്ങൾ രേഖപ്പെടുത്തുന്നതാണ്.
പദ്ധതിയിടലിന്റെ ഘടകങ്ങൾ
- നിലവിലെ ടാസ്ക്: ടാസ്ക് വ്യക്തമാക്കുക.
- ടാസ്ക് പൂർത്തിയാക്കാനുള്ള ഘടകങ്ങൾ: ടാസ്കിനെ കൈകാര്യം ചെയ്യാവുന്ന ഘടകങ്ങളാക്കി വിഭജിക്കുക.
- ആവശ്യമായ വിഭവങ്ങൾ: ആവശ്യമുള്ള വിഭവങ്ങൾ തിരിച്ചറിയുക.
- അനുഭവം: പദ്ധതിയിടലിനെ നയിക്കാൻ കഴിഞ്ഞ അനുഭവങ്ങൾ ഉപയോഗിക്കുക.
ഉദാഹരണം: താഴെ യാത്രാ ഏജന്റ് ഒരു ഉപയോക്താവിന്റെ യാത്ര ഫലപ്രദമായി പദ്ധതിയിടാൻ സ്വീകരിക്കേണ്ട ഘടകങ്ങൾ ആണ്:
യാത്രാ ഏജന്റിനു വേണ്ട ഘടങ്ങൾ
- ഉപയോക്തൃ പ്രാധാന്യങ്ങൾ ശേഖരിക്കുക
- ഉപയോക്താവിന് അവരുടെ യാത്ര തീയതികൾ, ബഡ്ജറ്റ്, താല്പര്യങ്ങൾ, ഏതെങ്കിലും പ്രത്യേക ആവശ്യങ്ങൾ എന്നിവ വിവരം ചോദിക്കുക.
- ഉദാഹരണങ്ങൾ: “When are you planning to travel?” “What is your budget range?” “What activities do you enjoy on vacation?”
- വിവരം തിരയുക
- ഉപയോക്തൃ പ്രാധാന്യങ്ങളുടെ അടിസ്ഥാനത്തിൽ ബന്ധപ്പെട്ട യാത്രാ ഓപ്ഷനുകൾ തിരയുക.
- ഫ്ലൈറ്റുകൾ: ഉപയോക്താവിന്റെ ബഡ്ജറ്റിനും ഇഷ്ടപ്പെട്ട യാത്രാ തീയതികൾക്കും അനുയോജ്യമായ ലഭ്യമായ ഫ്ലൈറ്റുകൾ നോക്കുക.
- താമസസ്ഥലങ്ങള്: ലൊക്കേഷൻ, വില, സൗകര്യങ്ങൾ എന്നിവയുടെ അടിസ്ഥാനത്തിൽ ഹോട്ടലുകൾ അല്ലെങ്കിൽ വാടകസ്ഥലങ്ങൾ കണ്ടെത്തുക.
- ആകർഷണങ്ങളും റസ്റ്റോറന്റുകളും: ഉപയോക്താവിന്റെ താല്പര്യങ്ങൾക്ക് അനുയോജ്യമായ ജനപ്രിയ ആകർഷണങ്ങൾ, പ്രവർത്തനങ്ങൾ, ഭക്ഷണോത്സവങ്ങൾ കണ്ടെത്തുക.
- ശിപാർശകൾ സൃഷ്ടിക്കുക
- തിരഞ്ഞെടുത്ത വിവരങ്ങൾ വ്യക്തിഗത ഇറ്റിനററിയായി സംকলനം ചെയ്യുക.
- ഫ്ലൈറ്റ് ഓപ്ഷനുകൾ, ഹോട്ടൽ റിസർവേഷനുകൾ, നിർദ്ദേശിച്ച പ്രവർത്തനങ്ങൾ എന്നിവ എന്നിവയുടെ വിശദാംശങ്ങൾ ഉൾപ്പെടുത്തി ഉപയോക്താവിന്റെ പ്രാധാന്യങ്ങൾക്കനുസരിച്ച് ശിപാർശകൾ തയാറാക്കുക.
- യാത്രാ പദ്ധതിയെ ഉപയോക്താവിന് അവതരിപ്പിക്കുക
- നിർദ്ദേശിച്ച ഇറ്റിനററി ഉപയോക്താവിന് അവലോകനത്തിനായി പങ്കിടുക.
- ഉദാഹരണം: “Here’s a suggested itinerary for your trip to Paris. It includes flight details, hotel bookings, and a list of recommended activities and restaurants. Let me know your thoughts!”
- ഫീഡ്بാക്ക് ശേഖരിക്കുക
- നിർദ്ദേശിച്ച ഇറ്റിനററിയിൽ ഉപയോക്താവിന്റെ അഭിപ്രായം ചോദിക്കുക.
- ഉദാഹരണങ്ങൾ: “Do you like the flight options?” “Is the hotel suitable for your needs?” “Are there any activities you would like to add or remove?”
- ഫീഡ്بാക്കിന്റെ അടിസ്ഥാനത്തിൽ ക്രമീകരിക്കുക
- ഉപയോക്തൃ ഫീഡ്بാക്ക് അടിസ്ഥാനമാക്കി ഇറ്റിനററി മാറ്റുക.
- ഉപയോക്താവിന്റെ പ്രാധാന്യങ്ങളെ കൂടുതൽ അനുയോജ്യമായ നിലയിലേക്ക് ഫ്ലൈറ്റ്, താമസം, പ്രവർത്തന ശിപാർശകൾ змായിക്കുക.
- ഇടക്ക് സ്ഥിരീകരണം
- അപ്ഡേറ്റ് ചെയ്ത ഇറ്റിനററി ഉപയോക്താവിന് അന്തിമ സ്ഥിരീകരണത്തിന് അവതരിപ്പിക്കുക.
- ഉദാഹരണം: “I’ve made the adjustments based on your feedback. Here’s the updated itinerary. Does everything look good to you?”
- റിസർവേഷൻ ചെയ്തിരിക്കുകയും സ്ഥിരീകരിക്കുക
- ഉപയോക്താവ് ഇറ്റിനററി അംഗീകരിച്ചതിനെത്തുടർന്ന്, ഫ്ലൈറ്റുകൾ, താമസസ്ഥലങ്ങൾ, മുൻകൂർ പദ്ധതികളായ പ്രവർത്തനങ്ങൾ ബുക്ക് ചെയ്ത് മുന്നോട്ട് പോകുക.
- ഉപയോക്താവിന് സ്ഥിരീകരണ വിശദാംശങ്ങൾ അയയ്ക്കുക.
- തുടർന്നു സഹായം നൽകുക
- യാത്രയ്ക്ക് മുംബൈക്കും വഴിത്തിരിവുകളിലുമുള്ള മാറ്റങ്ങൾക്കോ അധിക ടോക്കുകൾക്കോ ഉപയോക്താവിന് സഹായിക്കാൻ ലഭ്യമായി തുടരുക.
- ഉദാഹരണം: “If you need any further assistance during your trip, feel free to reach out to me anytime!”
സംവാദ ഉദാഹരണം
class Travel_Agent:
def __init__(self):
self.user_preferences = {}
self.experience_data = []
def gather_preferences(self, preferences):
self.user_preferences = preferences
def retrieve_information(self):
flights = search_flights(self.user_preferences)
hotels = search_hotels(self.user_preferences)
attractions = search_attractions(self.user_preferences)
return flights, hotels, attractions
def generate_recommendations(self):
flights, hotels, attractions = self.retrieve_information()
itinerary = create_itinerary(flights, hotels, attractions)
return itinerary
def adjust_based_on_feedback(self, feedback):
self.experience_data.append(feedback)
self.user_preferences = adjust_preferences(self.user_preferences, feedback)
# ഒരു ബൂയിംഗ് അഭ്യർത്ഥനയിലെ ഉദാഹരണ ഉപയോഗം
travel_agent = Travel_Agent()
preferences = {
"destination": "Paris",
"dates": "2025-04-01 to 2025-04-10",
"budget": "moderate",
"interests": ["museums", "cuisine"]
}
travel_agent.gather_preferences(preferences)
itinerary = travel_agent.generate_recommendations()
print("Suggested Itinerary:", itinerary)
feedback = {"liked": ["Louvre Museum"], "disliked": ["Eiffel Tower (too crowded)"]}
travel_agent.adjust_based_on_feedback(feedback)
3. Corrective RAG System
Firstly let’s start by understanding the difference between RAG Tool and Pre-emptive Context Load
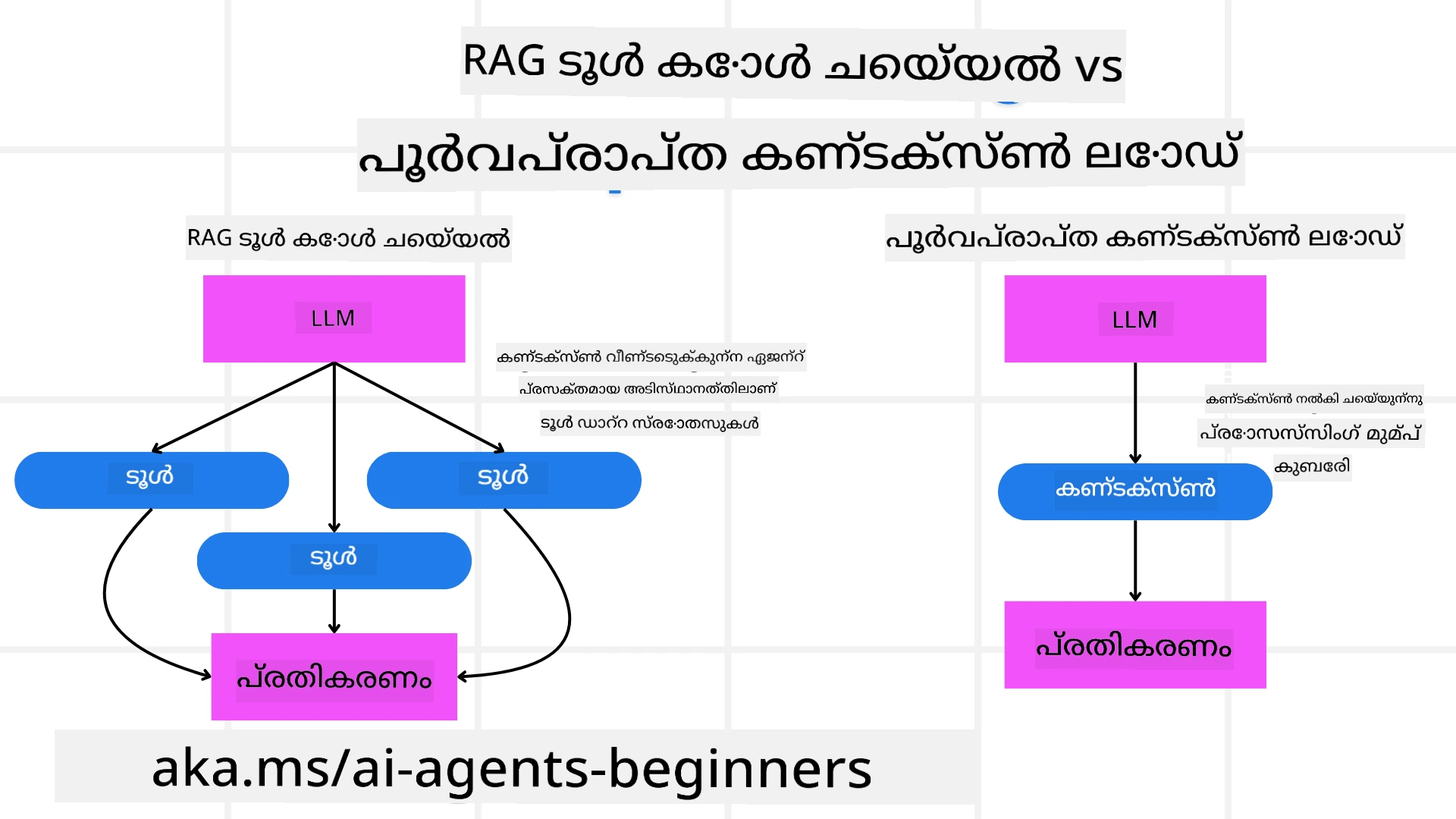
Retrieval-Augmented Generation (RAG)
RAG combines a retrieval system with a generative model. When a query is made, the retrieval system fetches relevant documents or data from an external source, and this retrieved information is used to augment the input to the generative model. This helps the model generate more accurate and contextually relevant responses.
In a RAG system, the agent retrieves relevant information from a knowledge base and uses it to generate appropriate responses or actions.
Corrective RAG Approach
The Corrective RAG approach focuses on using RAG techniques to correct errors and improve the accuracy of AI agents. This involves:
- Prompting Technique: Using specific prompts to guide the agent in retrieving relevant information.
- Tool: Implementing algorithms and mechanisms that enable the agent to evaluate the relevance of the retrieved information and generate accurate responses.
- Evaluation: Continuously assessing the agent’s performance and making adjustments to improve its accuracy and efficiency.
Example: Corrective RAG in a Search Agent
Consider a search agent that retrieves information from the web to answer user queries. The Corrective RAG approach might involve:
- Prompting Technique: Formulating search queries based on the user’s input.
- Tool: Using natural language processing and machine learning algorithms to rank and filter search results.
- Evaluation: Analyzing user feedback to identify and correct inaccuracies in the retrieved information.
Corrective RAG in Travel Agent
Corrective RAG (Retrieval-Augmented Generation) enhances an AI’s ability to retrieve and generate information while correcting any inaccuracies. Let’s see how Travel Agent can use the Corrective RAG approach to provide more accurate and relevant travel recommendations.
This involves:
- Prompting Technique: Using specific prompts to guide the agent in retrieving relevant information.
- Tool: Implementing algorithms and mechanisms that enable the agent to evaluate the relevance of the retrieved information and generate accurate responses.
- Evaluation: Continuously assessing the agent’s performance and making adjustments to improve its accuracy and efficiency.
Steps for Implementing Corrective RAG in Travel Agent
- Initial User Interaction
- Travel Agent gathers initial preferences from the user, such as destination, travel dates, budget, and interests.
-
Example:
preferences = { "destination": "Paris", "dates": "2025-04-01 to 2025-04-10", "budget": "moderate", "interests": ["museums", "cuisine"] }
- Retrieval of Information
- Travel Agent retrieves information about flights, accommodations, attractions, and restaurants based on user preferences.
-
Example:
flights = search_flights(preferences) hotels = search_hotels(preferences) attractions = search_attractions(preferences)
- Generating Initial Recommendations
- Travel Agent uses the retrieved information to generate a personalized itinerary.
-
Example:
itinerary = create_itinerary(flights, hotels, attractions) print("Suggested Itinerary:", itinerary)
- Collecting User Feedback
- Travel Agent asks the user for feedback on the initial recommendations.
-
Example:
feedback = { "liked": ["Louvre Museum"], "disliked": ["Eiffel Tower (too crowded)"] }
- Corrective RAG Process
- Prompting Technique: Travel Agent formulates new search queries based on user feedback.
-
Example:
if "disliked" in feedback: preferences["avoid"] = feedback["disliked"]
-
- Tool: Travel Agent uses algorithms to rank and filter new search results, emphasizing the relevance based on user feedback.
-
Example:
new_attractions = search_attractions(preferences) new_itinerary = create_itinerary(flights, hotels, new_attractions) print("Updated Itinerary:", new_itinerary)
-
- Evaluation: Travel Agent continuously assesses the relevance and accuracy of its recommendations by analyzing user feedback and making necessary adjustments.
-
Example:
def adjust_preferences(preferences, feedback): if "liked" in feedback: preferences["favorites"] = feedback["liked"] if "disliked" in feedback: preferences["avoid"] = feedback["disliked"] return preferences preferences = adjust_preferences(preferences, feedback)
-
- Prompting Technique: Travel Agent formulates new search queries based on user feedback.
Practical Example
Here’s a simplified Python code example incorporating the Corrective RAG approach in Travel Agent:
class Travel_Agent:
def __init__(self):
self.user_preferences = {}
self.experience_data = []
def gather_preferences(self, preferences):
self.user_preferences = preferences
def retrieve_information(self):
flights = search_flights(self.user_preferences)
hotels = search_hotels(self.user_preferences)
attractions = search_attractions(self.user_preferences)
return flights, hotels, attractions
def generate_recommendations(self):
flights, hotels, attractions = self.retrieve_information()
itinerary = create_itinerary(flights, hotels, attractions)
return itinerary
def adjust_based_on_feedback(self, feedback):
self.experience_data.append(feedback)
self.user_preferences = adjust_preferences(self.user_preferences, feedback)
new_itinerary = self.generate_recommendations()
return new_itinerary
# ഉദാഹരണ ഉപയോഗം
travel_agent = Travel_Agent()
preferences = {
"destination": "Paris",
"dates": "2025-04-01 to 2025-04-10",
"budget": "moderate",
"interests": ["museums", "cuisine"]
}
travel_agent.gather_preferences(preferences)
itinerary = travel_agent.generate_recommendations()
print("Suggested Itinerary:", itinerary)
feedback = {"liked": ["Louvre Museum"], "disliked": ["Eiffel Tower (too crowded)"]}
new_itinerary = travel_agent.adjust_based_on_feedback(feedback)
print("Updated Itinerary:", new_itinerary)
Pre-emptive Context Load
മുൻകൂട്ടി പശ്ചാത്തല معلومات ലോഡ് ചെയ്യൽ (Pre-emptive Context Load) എന്നു പറയുന്നത് ഒരു ചോദ്യം പ്രോസസ് ചെയ്യുന്നതിന് മുൻപ് മാതൃകയിൽ അനുയോജ്യമായ പശ്ചാത്തല വിവരങ്ങൾ ലോഡ് ചെയ്യുന്നതിനെ കുറിച്ചാണ്. ഇതിന്റെ ഫലമായി മാതൃകയ്ക്ക് തുടങ്ങുമ്പോൾ തന്നെ ഈ വിവരങ്ങൾ ലഭ്യമായിരിക്കും, അത് പ്രക്രിയയ്ക്ക് ഇടയിൽ അധിക ഡേറ്റ തിരയേണ്ടതില്ലാതെ കൂടുതൽ ശക്തമായ മറുപടികൾ ഉത്പാദിപ്പിക്കാൻ സഹായിക്കും.
Here’s a simplified example of how a pre-emptive context load might look for a travel agent application in Python:
class TravelAgent:
def __init__(self):
# പ്രസിദ്ധ ഗമ്യസ്ഥാനങ്ങളും അവയുടെ വിവരങ്ങളും മുൻകൂട്ടി ലോഡ് ചെയ്യുക
self.context = {
"Paris": {"country": "France", "currency": "Euro", "language": "French", "attractions": ["Eiffel Tower", "Louvre Museum"]},
"Tokyo": {"country": "Japan", "currency": "Yen", "language": "Japanese", "attractions": ["Tokyo Tower", "Shibuya Crossing"]},
"New York": {"country": "USA", "currency": "Dollar", "language": "English", "attractions": ["Statue of Liberty", "Times Square"]},
"Sydney": {"country": "Australia", "currency": "Dollar", "language": "English", "attractions": ["Sydney Opera House", "Bondi Beach"]}
}
def get_destination_info(self, destination):
# മുൻകൂട്ടി ലോഡ് ചെയ്ത സന്ദർഭത്തിൽ നിന്ന് ഗമ്യസ്ഥല വിവരങ്ങൾ നേടുക
info = self.context.get(destination)
if info:
return f"{destination}:\nCountry: {info['country']}\nCurrency: {info['currency']}\nLanguage: {info['language']}\nAttractions: {', '.join(info['attractions'])}"
else:
return f"Sorry, we don't have information on {destination}."
# ഉദാഹരണ ഉപയോഗം
travel_agent = TravelAgent()
print(travel_agent.get_destination_info("Paris"))
print(travel_agent.get_destination_info("Tokyo"))
വ്യാഖ്യാനം
-
Initialization (
__init__method):TravelAgentക്ലാസ് Paris, Tokyo, New York, Sydney എന്നിവ പോലുള്ള പ്രശസ്ത ഗമ്യസ്ഥാനങ്ങളേക്കുറിച്ചുള്ള വിവരങ്ങൾ അടങ്ങിയ ഒരു ഡിക്ഷണറി മുൻകൂട്ടി ലോഡ് ചെയ്യുന്നു. ഈ ഡിക്ഷണറിയിൽ ഓരോ ഗമ്യസ്ഥാനത്തിന്റെയും രാജ്യം, കറൻസി, ഭാഷ, പ്രധാന ആകർഷണങ്ങൾ എന്നിവ പോലുള്ള വിശദാംശങ്ങൾ ഉൾക്കൊള്ളുന്നു. -
Retrieving Information (
get_destination_infomethod): ഒരു ഉപയോക്താവ് പ്രത്യേക ഗമ്യസ്ഥലത്തെക്കുറിച്ച് ചോദിക്കുമ്പോൾ,get_destination_infoമെത്തഡ് മുൻകൂട്ടി ലോഡ് ചെയ്ത കോൺടെക്സ്റ്റ് ഡിക്ഷണറിയിൽ നിന്ന് അനുയോജ്യമായ വിവരങ്ങൾ നിന്ന് എടുക്കുന്നു.
പശ്ചാത്തലം മുൻകൂട്ടി ലോഡ് ചെയ്യുന്നതിലൂടെ, ട്രാവൽ ഏജന്റ് ആപ്ലിക്കേഷൻ ഉപയോക്തൃ ചോദ്യങ്ങൾക്ക് ദ്രുതഗതിയിൽ പ്രതികരിക്കാൻ കഴിയും, യഥാർത്ഥ സമയത്ത് ഈ വിവരങ്ങൾ പുറത്തുനിന്ന് പിടിച്ചെടുക്കേണ്ട ആവശ്യം ഇല്ലാതാക്കുന്നുവെന്ന് കൊണ്ട് ആപ്ലിക്കേഷൻ കൂടുതൽ കാര്യക്ഷമവും പ്രതികരണക്ഷമവുമാണ്.
ആവർത്തനം തുടങ്ങുന്നതിന് മുമ്പായി ഒരു ലക്ഷ്യത്തോടെ പദ്ധതി ബൂട്ട്സ്ട്രാപ്പ് ചെയ്യൽ
ലക്ഷ്യത്തോടെ ഒരു പദ്ധതി ബൂട്ട്സ്ട്രാപ്പ് ചെയ്യൽ എന്നത് ഒരു വ്യക്തമായ ലക്ഷ്യം അല്ലെങ്കിൽ ലക്ഷ്യപര്യന്തം മുൻപോടിച്ചു തുടങ്ങുക എന്നത് ഉൾക്കൊള്ളുന്നു. ഈ ലക്ഷ്യം തുടക്കത്തിൽ നിർവചിച്ചതിലൂടെ, മാതൃകക്കു അത് iterative പ്രക്രിയ മുഴുവൻ മാർഗനിർദേശമായിരിക്കാം. ഇതിലൂടെ ഓരോ ആവർത്തനവും ലക്ഷ്യത്തിലേക്ക് അടുത്തു നയിക്കുന്നവിധം ഉറപ്പാക്കപ്പെടുന്നു, പ്രക്രിയ കൂടുതൽ കാര്യക്ഷമവും കേന്ദ്രീകൃതവുമാക്കുന്നു.
ഇവിടെ Python-ൽ ഒരു ട്രാവൽ ഏജന്റിനായുള്ള ഉദാഹരണമായി, ഒരു ലക്ഷ്യത്തോടെ പദ്ധതി ബൂട്ട്സ്ട്രാപ്പ് ചെയ്ത് പിന്നീട് അതിനെ ആവർത്തിക്കുന്ന വിധം എങ്ങനെ ചെയ്യാമെന്നുള്ള ഒരു ഉദാഹരണം കാണാം:
രംഗം
ഒരു ട്രാവൽ ഏജന്റ് ക്ലയന്റിന് ഒരു വ്യക്തിഗത അവധിക്കാല യാത്ര പ്ലാൻ തയ്യാറാക്കാൻ ആഗ്രഹിക്കുന്നു. ലക്ഷ്യം ക്ലയന്റിന്റെ മുൻഗണനകളും ബജറ്റും പരിഗണിച്ച് ക്ലയന്റിന്റെ സംതൃപ്തി പരമാവധി ആക്കുന്നതായ ഒരു യാത്രാമുനുകപ്പത്രം (itinerary) സൃഷ്ടിക്കുന്നതാണ്.
ഘട്ടങ്ങൾ
- ക്ലയന്റിന്റെ മുൻഗണനകളും ബജറ്റും നിർവചിക്കുക.
- ഈ മുൻഗണനകളെ അടിസ്ഥാനമാക്കി തുടക്കത്തിന് ഒരു പ്ലാൻ ബൂട്ട്സ്ട്രാപ്പ് ചെയ്യുക.
- പ്ലാൻ മെച്ചപ്പെടുത്തുന്നതിനായി ആവർത്തിച്ചു refine ചെയ്യുക, ക്ലയന്റിന്റെ സംതൃപ്തിക്ക് അനുസൃതമായി ഓപ്റ്റിമൈസ് ചെയ്യുക.
Python കോഡ്
class TravelAgent:
def __init__(self, destinations):
self.destinations = destinations
def bootstrap_plan(self, preferences, budget):
plan = []
total_cost = 0
for destination in self.destinations:
if total_cost + destination['cost'] <= budget and self.match_preferences(destination, preferences):
plan.append(destination)
total_cost += destination['cost']
return plan
def match_preferences(self, destination, preferences):
for key, value in preferences.items():
if destination.get(key) != value:
return False
return True
def iterate_plan(self, plan, preferences, budget):
for i in range(len(plan)):
for destination in self.destinations:
if destination not in plan and self.match_preferences(destination, preferences) and self.calculate_cost(plan, destination) <= budget:
plan[i] = destination
break
return plan
def calculate_cost(self, plan, new_destination):
return sum(destination['cost'] for destination in plan) + new_destination['cost']
# ഉദാഹരണ ഉപയോഗം
destinations = [
{"name": "Paris", "cost": 1000, "activity": "sightseeing"},
{"name": "Tokyo", "cost": 1200, "activity": "shopping"},
{"name": "New York", "cost": 900, "activity": "sightseeing"},
{"name": "Sydney", "cost": 1100, "activity": "beach"},
]
preferences = {"activity": "sightseeing"}
budget = 2000
travel_agent = TravelAgent(destinations)
initial_plan = travel_agent.bootstrap_plan(preferences, budget)
print("Initial Plan:", initial_plan)
refined_plan = travel_agent.iterate_plan(initial_plan, preferences, budget)
print("Refined Plan:", refined_plan)
കോഡ് വിശദീകരണം
-
Initialization (
__init__method):TravelAgentക്ലാസ് വിവിധ ലക്ഷ്യസ്ഥാനങ്ങളുടെ ലിസ്റ്റുമായി ഇൻഷ്യലൈസ് ചെയ്യപ്പെടുന്നു; ഓരോ ലക്ഷ്യസ്ഥലത്തിനും name, cost, activity type പോലെയുള്ള ആട്രിബ്യൂട്ടുകൾ നിശ്ചിതമാകുന്നു. -
Bootstrapping the Plan (
bootstrap_planmethod): ഈ മെത്തഡ് ക്ലയന്റിന്റെ മുൻഗണനകളും ബജറ്റും അടിസ്ഥാനമാക്കി ഒരു ആരംഭობრივი യാത്രാ പദ്ധതി உருவാക്കുന്നു. ഇത് ലക്ഷ്യസ്ഥാനങ്ങളുടെ ലിസ്റ്റിൽ ഇടതു മുതൽ പരിശോധിച്ച് ക്ലയന്റിന്റെ മുൻഗണനകൾക്ക് ഒത്തു കൂടുന്നവയും ബജറ്റിനുള്ളിൽ വരുന്നതുമായവയാണെങ്കിൽ പ്ലാനിൽ ചേർക്കും. -
Matching Preferences (
match_preferencesmethod): ഒരു ലക്ഷ്യസ്ഥലം ക്ലയന്റിന്റെ മുൻഗണനകൾക്ക് ഒത്തുനിൽക്കുന്നുണ്ടോ എന്നു പരിശോധിക്കുന്ന മെത്തഡ് ആണ് ഇത്. -
Iterating the Plan (
iterate_planmethod): നിലവിലുള്ള പദ്ധതി മെച്ചപ്പെടുത്താൻ,每 ഒരു ലക്ഷ്യസ്ഥലവും അനുവർത്തിച്ച് കൂടുതൽ അനുയോജ്യമായ ഒരു ലക്ഷ്യസ്ഥലിൽ മാറ്റി നോക്കുന്നതു വഴിയിലൂടെ പ്ലാൻ refine ചെയ്യുന്നു, ക്ലയന്റിന്റെ മുൻഗണനകളും ബജറ്റ് പരിധികളും പരിഗണിച്ചുകൊണ്ട്. -
Calculating Cost (
calculate_costmethod): നിലവിലുള്ള പദ്ധതിയുടെ മൊത്തച്ചെലവ്, ഒരു പുതിയ ലക്ഷ്യസ്ഥലം ചേർക്കുമ്പോൾ ഉൾപ്പെടുത്തുന്നത് എന്നിവ കണക്കാക്കുന്ന മെത്തഡ് ആണ് ഇത്.
ഉദാഹരണ ഉപയോഗം
- Initial Plan: ട്രാവൽ ഏജന്റ് ക്ലയന്റിന്റെ sightseeing മുൻഗണനയും $2000 ബജറ്റും അടിസ്ഥാനമാക്കി ഒരു ആരംഭ പദ്ധതിയാണ് സൃഷ്ടിക്കുന്നത്.
- Refined Plan: ട്രാവൽ ഏജന്റ് പദ്ധതി iterative ആയി മെച്ചപ്പെടുത്തി, ക്ലയന്റിന്റെ മുൻഗണനകളും ബജറ്റും പരിഗണിച്ച് മികച്ചതാക്കുന്നു.
ലക്ഷ്യം (ഉദാഹരണത്തിന്, ക്ലയന്റിന്റെ സംതൃപ്തി പരമാവധി ആക്കൽ) വ്യക്തമായി നിർവചിച്ച് പദ്ധതിയേ ബൂട്ട്സ്ട്രാപ്പ് ചെയ്ത് പിന്നീട് ആവർത്തിച്ച് refine ചെയ്യുന്നതിലൂടെ, ട്രാവൽ ഏജന്റ് ഒരു വ്യക്തിഗതവും ഓപ്റ്റിമൈസഡ് ആയും ഉള്ള യാത്രാ പദ്ധതിയൊരുക്കാൻ കഴിയും. ഈ സമീപനം ആരംഭത്തിൽ തന്നെ ക്ലയന്റിന്റെ മുൻഗണനകളും ബജറ്റും അനുസരിച്ച് പദ്ധതിALIGN ചെയ്യുകയും ഓരോ ആവർത്തനത്തോടും കൂടി അതിനെ മെച്ചപ്പെടുത്തുകയും ചെയ്യുന്നു.
റീ-റാങ്കിംഗിനും സ്കോറിംഗിനും LLM ഉപയോഗം
വലിയ ഭാഷാ മോഡലുകൾ (LLMs) നെ റീ-റാങ്കിംഗിനും സ്കോറിംഗിനും ഉപയോഗിക്കാം — തിരികെ കിട്ടിയ ഡോക്യുമെന്റുകളുടെ പ്രാസക്തിയും ഗുണനിലവാരവും വിലയിരുത്തുന്നതിലൂടെ. പ്രവർത്തന രീതി താഴെപ്പറയുന്നതുപോലെയാണ്:
Retrieval: തുടക്കത്തിലെ retrieval നിലക് ക്വറിയിന്റെ അടിസ്ഥാനത്തിൽ ഒരു കാൻഡിഡേറ്റ് ഡോക്യുമെന്റ് സെറ്റ് ലഭിക്കുന്നു.
Re-ranking: LLM ഈ കാൻഡിഡേറ്റുകൾ വിലയിരുത്തുകയും ಅವയെ പ്രാസക്തിയുടെയും ഗുണനിലവാരത്തിന്റെയും അടിസ്ഥാനത്തിൽ പുനരാഞ്ചനമാക്കുകയും ചെയ്യുന്നു. ഇതിലൂടെ ഏറ്റവും പ്രസക്തവും ഉയർന്ന ഗുണമേൻമയുള്ള വിവരങ്ങൾ മുൻനിരയിലേക്ക് കൊണ്ടുവരപ്പെടും.
Scoring: LLM ഓരോ കാൻഡിഡേറ്റിനും ഒരു സ്കോർ എക്സൈൻ ചെയ്യുന്നു, അവയുടെ പ്രസക്തിയും ഗുണനിലവാരവും പ്രതിഫലിപ്പിക്കുന്നതുദ്ദേശിച്ച്. ഇത് ഏറ്റവും മികച്ച മറുപടി/ഡോക്യുമെന്റ് തിരഞ്ഞെടുക്കാൻ സഹായിക്കുന്നു.
LLM-കളെ റീ-റാങ്കിംഗിനും സ്കോറിംഗിനും ഉപയോഗിച്ച് ලබාപ്പെടുന്നതിലൂടെ, സിസ്റ്റം കൂടുതൽ തികച്ചും പ്രസക്തവും കണ്ടക്സ്-അനുസൃതവുമായ വിവരങ്ങൾ നൽകാൻ കഴിയും, അതുവഴി ഉപയോക്തൃ അനുഭവം മെച്ചപ്പെടും.
ഇവിടെയാണ് ഒരു ട്രാവൽ ഏജന്റ് ഉപയോക്താവിന്റെ മുൻഗണനകൾ അടിസ്ഥാനാക്കി യാത്രാ ലക്ഷ്യസ്ഥാനങ്ങളെ റീ-റാങ്ക് ചെയ്ത് സ്കോർ ചെയ്യാൻ Azure OpenAI സേവനങ്ങൾ എങ്ങനെ ഉപയോഗിക്കാമെന്നുള്ള ഉദാഹരണം:
സീനാരിയോ - മുൻഗണനകളെ അടിസ്ഥാനമാക്കിയുള്ള യാത്ര
ഒരു ട്രാവൽ ഏജന്റ് ഉപയോക്താവിന്റെ മുൻഗണനകളെ അടിസ്ഥാനമാക്കി മികച്ച യാത്രാ ലക്ഷ്യസ്ഥാനങ്ങൾ ശുപാർശ ചെയ്യാൻ ആഗ്രഹിക്കുന്നു. LLM അവയെ റീ-റാങ്ക് ചെയ്ത് സ്കോർചെയ്ത് ഏറ്റവും പ്രസക്തമായ ഓപ്ഷനുകൾ മുൻപിൽ കാണിക്കും.
ഘട്ടങ്ങൾ:
- ഉപയോക്തൃ മുൻഗണനകൾ ശേഖരിക്കുക.
- সম্ভാവ്യ യാത്രാ ലക്ഷ്യസ്ഥാനങ്ങളുടെ ലിസ്റ്റ് തിരികെയെടുക്കുക.
- ഉപയോക്തൃ മുൻഗണനകൾ അടിസ്ഥാനമാക്കി LLM ഉപയോഗിച്ച് ലക്ഷ്യസ്ഥാനങ്ങൾ റീ-റാങ്ക് ചെയ്ത് സ്കോർ ചെയ്യുക.
Here’s how you can update the previous example to use Azure OpenAI Services:
Requirements
- നിങ്ങൾക്ക് Azure subscription ഉണ്ടായിരിക്കണം.
- Azure OpenAI resource സൃഷ്ടിച്ചു നിങ്ങളുടെ API key നേടുക.
Example Python Code
import requests
import json
class TravelAgent:
def __init__(self, destinations):
self.destinations = destinations
def get_recommendations(self, preferences, api_key, endpoint):
# Azure OpenAI-ക്കായി ഒരു പ്രോമ്പ്റ്റ് സൃഷ്ടിക്കുക
prompt = self.generate_prompt(preferences)
# അഭ്യർത്ഥനയ്ക്ക് ഹെഡറുകളും പേലോഡും നിർവചിക്കുക
headers = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {api_key}'
}
payload = {
"prompt": prompt,
"max_tokens": 150,
"temperature": 0.7
}
# പുനഃക്രമീകരിച്ചും സ്കോർ ചെയ്തതുമായ ലക്ഷ്യസ്ഥലങ്ങൾ ലഭിക്കാൻ Azure OpenAI API വിളിക്കുക
response = requests.post(endpoint, headers=headers, json=payload)
response_data = response.json()
# ശുപാർശകൾ എടുക്കുകയും തിരികെ നൽകുകയും ചെയ്യുക
recommendations = response_data['choices'][0]['text'].strip().split('\n')
return recommendations
def generate_prompt(self, preferences):
prompt = "Here are the travel destinations ranked and scored based on the following user preferences:\n"
for key, value in preferences.items():
prompt += f"{key}: {value}\n"
prompt += "\nDestinations:\n"
for destination in self.destinations:
prompt += f"- {destination['name']}: {destination['description']}\n"
return prompt
# ഉദാഹരണ ഉപയോഗം
destinations = [
{"name": "Paris", "description": "City of lights, known for its art, fashion, and culture."},
{"name": "Tokyo", "description": "Vibrant city, famous for its modernity and traditional temples."},
{"name": "New York", "description": "The city that never sleeps, with iconic landmarks and diverse culture."},
{"name": "Sydney", "description": "Beautiful harbour city, known for its opera house and stunning beaches."},
]
preferences = {"activity": "sightseeing", "culture": "diverse"}
api_key = 'your_azure_openai_api_key'
endpoint = 'https://your-endpoint.com/openai/deployments/your-deployment-name/completions?api-version=2022-12-01'
travel_agent = TravelAgent(destinations)
recommendations = travel_agent.get_recommendations(preferences, api_key, endpoint)
print("Recommended Destinations:")
for rec in recommendations:
print(rec)
കോഡ് വിശദീകരണം - പ്രിഫറൻസ് ബുക്കർ
-
Initialization:
TravelAgentക്ലാസ് നാമം, വിവരണം പോലുള്ള attributes ഉള്ള ഒരു ലക്ഷ്യസ്ഥലങ്ങളുടെ ലിസ്റ്റുമായി ഇൻഷ്യലൈസ് ചെയ്യപ്പെടുന്നു. -
Getting Recommendations (
get_recommendationsmethod): ഉപയോക്തൃ മുൻഗണനകളെ അടിസ്ഥാനമാക്കി Azure OpenAI സേവനത്തിന് prompt ജൻറേറ്റ് ചെയ്ത് HTTP POST അഭ്യർത്ഥന അയയ്ക്കാൻ ഈ മെത്തഡ് ഉപയോഗിക്കുന്നു, ഫലം റീ-റാങ്ക് ചെയ്ത് സ്കോർ ചെയ്ത ലക്ഷ്യസ്ഥാനങ്ങളായിരിക്കും. -
Generating Prompt (
generate_promptmethod): ഉപയോക്തൃ മുൻഗണനകളും ലക്ഷ്യസ്ഥലങ്ങളുടെ ലിസ്റ്റും ഉൾപ്പെടുത്തി Azure OpenAI-നുള്ള ഒരു prompt നിർമ്മിക്കാൻ ഈ മെത്തഡ് വഴി നിർദ്ദേശങ്ങൾ ഉണ്ടാക്കുന്നു. prompt മോഡലിനെ റീ-റാങ്ക് ചെയ്യാനും സ്കോർ ചെയ്യാനും മാർഗനിർദ്ദേശം നൽകുന്നു. -
API Call:
requestsലൈബ്രറി ഉപയോഗിച്ച് Azure OpenAI API എണ്ട്പോയിന്റിലേക്ക് HTTP POST അഭ്യർത്ഥന നടത്തുന്നു. റെസ്പോൺസ് റീ-റാങ്ക് ചെയ്തതും സ്കോർ ചെയ്തതുമായ ലക്ഷ്യസ്ഥാനങ്ങൾ സമർപ്പിക്കും. -
Example Usage: ട്രാവൽ ഏജന്റ് ഉപയോക്തൃ മുൻഗണനകൾ (ഉദാഹരണത്തിന് sightseeing-ൽ രുചിയുള്ളവയും വൈവിധ്യമാർന്ന സാംസ്കാരിക താൽപര്യവും) ശേഖരിച്ചു Azure OpenAI സേവനം വഴി റീ-റാങ്കുചെയ്തും സ്കോർ ചെയ്തതും പങ്കുവെയ്ക്കുന്ന ശുപാർശകൾ നേടും.
ദയവായി your_azure_openai_api_key ന് പകരം നിങ്ങളുടെ യഥാർത്ഥ Azure OpenAI API കീ ഉപയോഗിക്കുക, കൂടാതെ https://your-endpoint.com/... എന്ന URL-നെ നിങ്ങളുടെ Azure OpenAI ഡിപ്പ്ലോയ്മെന്റിന്റെ യഥാർത്ഥ എണ്ട്പോയിന്റ് URL-നായി മാറ്റാൻ ശ്രദ്ധിക്കുക.
LLM-നെ റീ-റാങ്കിംഗിനും സ്കോറിംഗിനും ഉപയോഗിക്കുന്നത് വഴി ട്രാവൽ ഏജന്റ് കൂടുതൽ വ്യക്തിഗതവും പ്രസക്തവുമായ ശുപാർശകൾ നൽകിയുകൊണ്ട് ഉപഭോക്തൃ അനുഭവം വർധിപ്പിക്കാനാകും.
RAG: പ്രോംപ്റ്റിംഗ് സാങ്കേതികത vs ഉപകരണം
Retrieval-Augmented Generation (RAG) ഒരു പ്രോംപ്റ്റിംഗ് സാങ്കേതികതയും ഒരു ഉപകരണവുമായിരിക്കും. ഇവ രണ്ടിന്റെ വ്യത്യാസം മനസ്സിലാക്കുന്നത് RAG-നെ നിങ്ങളുടെ പ്രോജക്ടുകളിൽ കൂടുതൽ പോരമേയിലായാണ് ഉപയോഗിക്കാൻ സഹായിക്കുന്നു.
പ്രോംപ്റ്റിംഗ് സാങ്കേതികതയായ RAG
അത് എന്താണ്?
- പ്രോംപ്റ്റിംഗ് സാങ്കേതികതയായി RAG എന്നത് വലിയ കോർപ്പസ് അല്ലെങ്കിൽ ഡാറ്റാബേസ് മുതലുള്ള പ്രസക്തമായ വിവരങ്ങൾ തിരയ്ക്കാൻ നന്നായി രൂപകൽപ്പന ചെയ്ത ക്വെറികൾ അല്ലെങ്കിൽ പ്രോംപ്റുകൾ തയ്യാറാക്കുന്നതാണ്. തുടർന്ന് ഈ വിവരങ്ങൾ ഉപയോഗിച്ച് മറുപടികൾ അല്ലെങ്കിൽ പ്രവർത്തനങ്ങൾ ഉത്പാദിപ്പിക്കുന്നു.
എങ്ങനെ പ്രവർത്തിക്കുന്നു:
- Formulate Prompts: നെറയായ ടാസ്ക്കിനോ ഉപയോക്താവിന്റെ ഇൻപുട്ടിനോ അനുസരിച്ച് നന്നായി ഘടിപ്പിച്ച പ്രോംപ്റ്റുകൾ/ക്വെറികൾ സൃഷ്ടിക്കുക.
- Retrieve Information: നിലവിലുള്ള നോളേജ് ബെസ് അല്ലെങ്കിൽ ഡാറ്റാസെറ്റിൽ നിന്നുളള പ്രസക്തമായ ഡാറ്റ തിരയാൻ ആ പ്രോംപ്റ്റുകൾ ഉപയോഗിക്കുക.
- Generate Response: retrieval വഴി കിട്ടിയ വിവരങ്ങൾ ജനറേറ്റീവ് AI മോഡലുകളുമായി സംയോജിപ്പിച്ച് സമഗ്രവും coherent-ഉം ആയ മറുപടി തയ്യാറാക്കുക.
ചുരുക്കം - ട്രാവൽ ഏജന്റിന്റെ ഉദാഹരണം:
- ഉപയോക്തൃ ഇൻപുട്ട്: “I want to visit museums in Paris.”
- പ്രോംപ്റ്റ്: “Find top museums in Paris.”
- Retrieved Information: Louvre Museum, Musée d’Orsay എന്നിവയുടെ വിവരങ്ങൾ.
- Generated Response: “Here are some top museums in Paris: Louvre Museum, Musée d’Orsay, and Centre Pompidou.”
ഉപകരണമെന്ന നിലയിൽ RAG
അത് എന്താണ്?
- ഉപകരണമായി RAG എന്നത് retrieval-നും generation-നും എന്ന പ്രക്രിയകൾ ഓട്ടോമേറ്റുചെയ്യുന്ന ഒരു സംയോജിത സിസ്റ്റമാണ്, ഡവലപ്പർമാർക്ക് ഓരോ ക്വറിയിനും മാനually പ്രോംപ്റ്റ് തയ്യാറാക്കേണ്ടതെന്ന ബാധ്യത ഇല്ലാതാക്കുന്നു.
എങ്ങനെ പ്രവർത്തിക്കുന്നു:
- Integration: AI ഏജന്റിന്റെ ആർക്കിടെക്ചറിലേക്ക് RAG എ/embed ചെയ്യുക, ഇത് retrieval-നും generation-നും സ്വയം കൈകാര്യം ചെയ്യട്ടെ.
- Automation: ഉപകരണമെന്ന നിലയിൽ, ഉപയോഗിക്കാവുന്ന എൻപുട്ട് സ്വീകരിക്കുന്നത് തുടങ്ങി അന്തിമ മറുപടി ജനറേറ്റ് ചെയ്യുന്നതുവരെ മുഴുവൻ പ്രക്രിയയും കൈകാര്യം ചെയ്യുന്നു.
- Efficiency: retrieval-നും generation-നും streamline ചെയ്യുന്നത് ഏജന്റിന്റെ പ്രകടനം മെച്ചപ്പെടുത്തുന്നു, വേഗത്തിൽ കൂടുതൽ കൃത്യമായ മറുപടികൾ നൽകാൻ സാധിക്കുന്നു.
ട്രാവൽ ഏജന്റ് ഉദാഹരണം:
- ഉപയോക്തൃ ഇൻപുട്ട്: “I want to visit museums in Paris.”
- RAG ഉപകരണം: സ്വയമേവ മ്യൂസിയങ്ങളേക്കുറിച്ചുള്ള വിവരങ്ങൾ തിരക്കി മറുപടി ജനറേറ്റ് ചെയ്യുന്നു.
- Generated Response: “Here are some top museums in Paris: Louvre Museum, Musée d’Orsay, and Centre Pompidou.”
താരതമ്യം
| വശം | പ്രോംപ്റ്റിംഗ് സാങ്കേതികത | ഉപകരണം |
|---|---|---|
| മാനുവൽ vs ഓട്ടോമാറ്റിക് | ഓരോ ക്വറിയിനും പ്രോംപ്റ്റുകൾ മാനുവലായി രൂപകല്പ്പന ചെയ്യുക. | retrieval-നും generation-നും വേണ്ടി ഓട്ടോമേറ്റഡ് പ്രോസസ്. |
| നിയന്ത്രണം | തിരയൽ പ്രക്രിയയിൽ കൂടുതൽ നിയന്ത്രണം നൽകുന്നു. | retrieval-നും generation-നും streamline ചെയ്തും ഓട്ടോമേറ്റ് ചെയ്തും കൊടുക്കുന്നു. |
| ഇളവ് | പ്രത്യേക ആവശ്യങ്ങൾക്ക് അനുയോജ്യമായ കസ്റ്റമൈസ്ഡ് പ്രോംപ്റ്റുകൾ അനുവദിക്കുന്നു. | വലിയ തോതിലുള്ള നടപ്പാക്കലുകൾക്കായി കൂടുതൽ കാര്യക്ഷമമാണ്. |
| സങ്കീർണത | പ്രോംപ്റ്റുകൾ രൂപകൽപ്പന ചെയ്യുവാനും മെച്ചപ്പെടുത്താനും അമിത ശ്രദ്ധ ആവശ്യമാണ്. | AI ഏജന്റിന്റെ ആർക്കിടെക്ചറിലുള്ള സംയോജനം എളുപ്പമാണ്. |
പ്രായോഗിക ഉദാഹരണങ്ങൾ
പ്രോംപ്റ്റിംഗ് സാങ്കേതികത ഉദാഹരണം:
def search_museums_in_paris():
prompt = "Find top museums in Paris"
search_results = search_web(prompt)
return search_results
museums = search_museums_in_paris()
print("Top Museums in Paris:", museums)
ഉപകരണം ഉദാഹരണം:
class Travel_Agent:
def __init__(self):
self.rag_tool = RAGTool()
def get_museums_in_paris(self):
user_input = "I want to visit museums in Paris."
response = self.rag_tool.retrieve_and_generate(user_input)
return response
travel_agent = Travel_Agent()
museums = travel_agent.get_museums_in_paris()
print("Top Museums in Paris:", museums)
പ്രസക്തി മൂല്യനിർണയം
പ്രസക്തിയെ വിലയിരുത്തുക എന്നത് AI ഏജന്റിന്റെ പ്രകടനത്തിനുള്ള നിർണായക ഭാഗമാണ്. ഇത് ഏജന്റ് തിരിച്ച് എടുത്തും ജനറേറ്റ് ചെയ്തതും ഉപയോക്താവിന് അനുയോജ്യവുമായ, ശരിയായതുമായ, ഉപകാരപ്രദവുമായ വിവരമാണെന്ന് ഉറപ്പാക്കുന്നു. നാം AI ഏജന്റുകളിൽ പ്രസക്തി എങ്ങനെ വിലയിരുത്താമെന്ന് പ്രായോഗിക ഉദാഹരണങ്ങളോടുകൂടി പരിശോധിക്കാം.
പ്രസക്തി മൂല്യനിർണയത്തിലുണ്ടാകുന്ന പ്രധാന ആശയങ്ങൾ
- സന്ദർഭ ബോധം (Context Awareness):
- ഏജന്റ് ഉപയോക്താവിന്റെ ക്വറിയുടെ സന്ദർഭം മനസ്സിലാക്കണം, അതിനനുസരിച്ച് പ്രസക്തമായ വിവരങ്ങൾ തിരയാനും ജനറേറ്റ് ചെയ്യാനും.
- ഉദാഹരണം: ഉപയോക്താവ് “best restaurants in Paris” എന്ന് ചോദിച്ചാൽ, ഏജന്റ് ഉപയോക്താവിന്റെ ഇഷ്ടം (ഉദാ., ഭക്ഷ്യശൈലി)വും ബജറ്റും പരിഗണിക്കണം.
- ఖൃത്യത (Accuracy):
- ഏജന്റ് നൽകുന്ന വിവരങ്ങൾ സത്യസന്ധവും അപ്ഡേറ്റും ആയിരിക്കണം.
- ഉദാഹരണം: ഇപ്പോള് തുറന്നിരിക്കുന്ന, നല്ല റിവ്യൂ ഉള്ള restaurants ശുപാർശ ചെയ്യുക; പെട്ടെന്ന് അടഞ്ഞോ പഴയോ ആയ ഓപ്ഷനുകൾ ശുപാർശ ചെയ്യരുത്.
- ഉപയോക്തൃ ഉദ്ദേശ്യം (User Intent):
- ക്വറിയിന്റെ പിന്നിലുള്ള ഉപയോക്താവിന്റെ ഉദ്ദേശ്യംferences അറിയാൻ ഏജന്റ് ശ്രമിക്കണം, ആനുസരിച്ച് കൂടുതൽ പ്രസക്തമായ വിവരങ്ങൾ നൽകുക.
- ഉദാഹരണം: ഉപയോക്താവ് “budget-friendly hotels” എന്ന് ചോദിച്ചാൽ, ഏജന്റ് വിലക്കുറവുള്ള ഓപ്ഷനുകൾക്ക് മുൻതൂക്കം നൽകണം.
- ഇറിവ് ചക്രം (Feedback Loop):
- ഉപയോക്തൃ പ്രതികരണങ്ങൾ ചക്രരീതിയിലുള്ളുള്ള വിലയിരുത്തലിൽ ഉൾക്കൊള്ളിച്ച് ഏജന്റ് പ്രസക്തി മൂല്യനിർണയം മെച്ചപ്പെടുത്താൻ ബന്ധവത്കരിക്കണം.
- ഉദാഹരണം: മുൻപ് ശുപാർശ ചെയ്തവയിലുണ്ടായ ഉപയോക്തൃ റേറ്റിങ്ങ്/ഫീഡ്ബാക്ക് ഉൾപ്പെടുത്തുക, ഭാവി ശുപാർശകൾ മെച്ചപ്പെടുത്താൻ.
പ്രസക്തി മൂല്യനിർണയത്തിന് പ്രായോഗിക സാങ്കേതികതകൾ
- Relevance Scoring:
- റിട്ട്രീവ് ചെയ്ത ഓരോ ഐറ്റത്തിനും ഉപയോക്താവിന്റെ ക്വറിയും മുൻഗണനകളും എത്രമാത്രം പൊരുത്തപ്പെടുന്നു എന്നതടിസ്ഥാനമാക്കി ഒരു പ്രസക്തി സ്കോർ നല്കുക.
-
ഉദാഹരണം:
def relevance_score(item, query): score = 0 if item['category'] in query['interests']: score += 1 if item['price'] <= query['budget']: score += 1 if item['location'] == query['destination']: score += 1 return score
- Filtering and Ranking:
- പ്രസക്തമല്ലാത്ത ഐറ്റങ്ങൾ ഫിൽട്ടർ ചെയ്ത് അവശിഷ്ടങ്ങളെ അവരുടെ പ്രസക്തി സ്കോറുകളുടെ അടിസ്ഥാനത്തിൽ റാങ്ക് ചെയ്യുക.
-
ഉദാഹരണം:
def filter_and_rank(items, query): ranked_items = sorted(items, key=lambda item: relevance_score(item, query), reverse=True) return ranked_items[:10] # മുകളിലെ 10 പ്രസക്തമായ ഇനങ്ങൾ തിരികെ നൽകുക
- Natural Language Processing (NLP):
- ഉപയോക്താവിന്റെ ക്വറിയെ മനസ്സിലാക്കാനും പ്രസക്തമായ വിവരങ്ങൾ തിരയാനുമുള്ള NLP സാങ്കേതികതകൾ ഉപയോഗിക്കുക.
-
ഉദാഹരണം:
def process_query(query): # ഉപയോക്താവിന്റെ ചോദ്യംയിൽ നിന്നുള്ള പ്രധാന വിവരങ്ങൾ എടുക്കാൻ NLP ഉപയോഗിക്കുക processed_query = nlp(query) return processed_query
- User Feedback Integration:
- നൽകിയ ശുപാർശകളിൽ ഉപയോക്താവിന്റെ ഫീഡ്ബാക്ക് ശേഖരിച്ച് അത് ഭാവിയിലെ പ്രസക്തി മൂല്യനിർണയങ്ങളിൽ ഉപയോഗിക്കുക.
-
ഉദാഹരണം:
def adjust_based_on_feedback(feedback, items): for item in items: if item['name'] in feedback['liked']: item['relevance'] += 1 if item['name'] in feedback['disliked']: item['relevance'] -= 1 return items
ഉദാഹരണം: ട്രാവൽ ഏജന്റിൽ പ്രസക്തി മൂല്യനിർണയം
താഴെ Travel Agent ഒരു യാത്രാ ശുപാർശയുടെ പ്രസക്തി എങ്ങനെ വിലയിരുത്താം എന്നതിനുള്ള പ്രായോഗിക ഉദാഹരണമാണ്:
class Travel_Agent:
def __init__(self):
self.user_preferences = {}
self.experience_data = []
def gather_preferences(self, preferences):
self.user_preferences = preferences
def retrieve_information(self):
flights = search_flights(self.user_preferences)
hotels = search_hotels(self.user_preferences)
attractions = search_attractions(self.user_preferences)
return flights, hotels, attractions
def generate_recommendations(self):
flights, hotels, attractions = self.retrieve_information()
ranked_hotels = self.filter_and_rank(hotels, self.user_preferences)
itinerary = create_itinerary(flights, ranked_hotels, attractions)
return itinerary
def filter_and_rank(self, items, query):
ranked_items = sorted(items, key=lambda item: self.relevance_score(item, query), reverse=True)
return ranked_items[:10] # മുകളിലെ 10 ഏറ്റവും പ്രസക്തമായ ഇനങ്ങൾ മടക്കി നൽകുക
def relevance_score(self, item, query):
score = 0
if item['category'] in query['interests']:
score += 1
if item['price'] <= query['budget']:
score += 1
if item['location'] == query['destination']:
score += 1
return score
def adjust_based_on_feedback(self, feedback, items):
for item in items:
if item['name'] in feedback['liked']:
item['relevance'] += 1
if item['name'] in feedback['disliked']:
item['relevance'] -= 1
return items
# ഉദാഹരണ ഉപയോഗം
travel_agent = Travel_Agent()
preferences = {
"destination": "Paris",
"dates": "2025-04-01 to 2025-04-10",
"budget": "moderate",
"interests": ["museums", "cuisine"]
}
travel_agent.gather_preferences(preferences)
itinerary = travel_agent.generate_recommendations()
print("Suggested Itinerary:", itinerary)
feedback = {"liked": ["Louvre Museum"], "disliked": ["Eiffel Tower (too crowded)"]}
updated_items = travel_agent.adjust_based_on_feedback(feedback, itinerary['hotels'])
print("Updated Itinerary with Feedback:", updated_items)
ഉദ്ദേശ്യത്തോടെ തിരയൽ (Search with Intent)
ഉദ്ദേശ്യത്തോടെ തിരയൽ എന്നത് ഉപയോക്താവിന്റെ ക്വറിയുടെ പിന്നിലുള്ള ലക്ഷ്യത്തെയും ലക്ഷ്യത്തിനായുള്ള ഉദ്ദേശ്യത്തെയും മനസ്സിലാക്കി ഏറ്റവും പ്രസക്തവുമായ വിവരങ്ങൾ തിരയുകയും ജനറേറ്റ് ചെയ്യുകയും ചെയ്യുന്നതിനാണ്. ഇത് സിമ്പിളായി കീവേഡുകൾ പൊരുത്തപ്പെടുത്തുന്നതിന് മുകളിലാണു പ്രവർത്തിക്കുന്നത്, ഉപയോക്താവിന്റെ യഥാർത്ഥ ആവശ്യവും സന്ദർഭവും പിടികൂടുന്നതിലാണ് ശ്രദ്ധ.
ഉദ്ദേശ്യത്തോടൊപ്പം തിരയലിന്റെ പ്രധാന ആശയങ്ങൾ
- ഉപയോക്തൃ ഉദ്ദേശ്യം മനസ്സിലാക്കൽ:
- ഉപയോക്തൃ ഉദ്ദേശ്യം പ്രധാനമായി മൂന്ന് തരം ആയി വർഗ്ഗീകരിക്കാം: വിവരാത്മക (informational), നാവിഗേഷണൽ (navigational), ട്രാൻസാക്ഷണൽ (transactional).
- വിവരാത്മക ഉദ്ദേശ്യം: ഉപയോക്താവ് ഒരു വിഷയം സംബന്ധിച്ച് വിവരങ്ങൾ അന്വേഷിക്കുന്നു (ഉദാ., “What are the best museums in Paris?”).
- നാവിഗേഷണൽ ഉദ്ദേശ്യം: ഉപയോക്താവ് ഒരു പ്രത്യേക വെബ്സൈറ്റ് അല്ലെങ്കിൽ പേജ് സന്ദർശിക്കാൻ ആഗ്രഹിക്കുന്നു (ഉദാ., “Louvre Museum official website”).
- ട്രാൻസാക്ഷണൽ ഉദ്ദേശ്യം: ഉപയോക്താവ് ഒരു ട്രാൻസാക്ഷൻ നിർവഹിക്കാൻ ഉദ്ദേശിക്കുന്നു, ഉദാ., ഫ്ലൈറ്റ് ബുക്ക് ചെയ്യൽ (ഉദാ., “Book a flight to Paris”).
- ഉപയോക്തൃ ഉദ്ദേശ്യം പ്രധാനമായി മൂന്ന് തരം ആയി വർഗ്ഗീകരിക്കാം: വിവരാത്മക (informational), നാവിഗേഷണൽ (navigational), ട്രാൻസാക്ഷണൽ (transactional).
- സന്ദർഭ ബോധം:
- ഉപയോക്താവിന്റെ മുൻവിലാസങ്ങൾ, മുൻഗണനകൾ, നിലവിലുള്ള ക്വറിയിന്റെ പ്രത്യേക വിശദാംശങ്ങൾ എന്നിവ പരിഗണിച്ച് അതിന്റെ സന്ദർഭം വിശകലനം ചെയ്യുന്നത് ഉദ്ദേശ്യം ശരിയായി തിരിച്ചറിയാൻ സഹായിക്കുന്നു.
- Natural Language Processing (NLP):
- ഉപയോക്താവിന്റെ നാച്ചുറൽ ഭാഷയുടെ ക്വറിയുകൾ മനസ്സിലാക്കുന്നതിന് NLP സാങ്കേതികതകൾ ഉപയോഗിക്കപ്പെടുന്നു; ഇത് entity recognition, sentiment analysis, query parsing തുടങ്ങിയ ജോലികളെ ഉൾക്കൊള്ളുന്നു.
- Personalization:
- ഉപയോക്താവിന്റെ ചരിത്രം, മുൻഗണനകൾ, ഫീഡ്ബാക്ക് എന്നിവയുടെ അടിസ്ഥാനത്തിൽ തിരയലുകൾ വ്യക്തിഗതമാക്കി പ്രസക്തി വർദ്ധിപ്പിക്കുക.
പ്രായോഗിക ഉദാഹരണം: ട്രാവൽ ഏജന്റിൽ ഉദ്ദേശ്യത്തോടെ തിരയൽ
Travel Agent ഉദാഹരണമായി എടുത്ത് ഉദ്ദേശ്യത്തോടെ തിരയൽ എങ്ങനെ പ്രയോഗിക്കാമെന്ന് നോക്കാം.
-
ഉപയോക്തൃ മുൻഗണനകൾ ശേഖരിക്കൽ
class Travel_Agent: def __init__(self): self.user_preferences = {} def gather_preferences(self, preferences): self.user_preferences = preferences -
ഉപയോക്തൃ ഉദ്ദേശ്യം മനസ്സിലാക്കൽ
def identify_intent(query): if "book" in query or "purchase" in query: return "transactional" elif "website" in query or "official" in query: return "navigational" else: return "informational" -
സന്ദർഭ ബോധം
def analyze_context(query, user_history): # സന്ദർഭം മനസ്സിലാക്കാൻ നിലവിലെ ക്വറിയെ ഉപയോക്താവിന്റെ ചരിത്രവുമായി സംയോജിപ്പിക്കുക context = { "current_query": query, "user_history": user_history } return contextdef analyze_context(query, user_history): # സന്ദർഭം മനസ്സിലാക്കാൻ നിലവിലെ ക്വറിയെ ഉപയോക്താവിന്റെ ചരിത്രവുമായി സംയോജിപ്പിക്കുക context = { "current_query": query, "user_history": user_history } return context -
തിരച്ചിൽ ചെയ്ത് ഫലങ്ങൾ വ്യക്തിഗതമാക്കുക
def search_with_intent(query, preferences, user_history): intent = identify_intent(query) context = analyze_context(query, user_history) if intent == "informational": search_results = search_information(query, preferences) elif intent == "navigational": search_results = search_navigation(query) elif intent == "transactional": search_results = search_transaction(query, preferences) personalized_results = personalize_results(search_results, user_history) return personalized_results def search_information(query, preferences): # വിവരങ്ങൾ അന്വേഷിക്കുന്ന ഉദ്ദേശ്യത്തിന് ഉദാഹരണമായ തിരച്ചിൽ തന്ത്രം results = search_web(f"best {preferences['interests']} in {preferences['destination']}") return results def search_navigation(query): # നാവിഗേഷണൽ ഉദ്ദേശ്യത്തിന് ഉദാഹരണമായി തിരച്ചിൽ തന്ത്രം results = search_web(query) return results def search_transaction(query, preferences): # വിനിമയാത്മക ഉദ്ദേശ്യത്തിന് ഉദാഹരണമായി തിരച്ചിൽ തന്ത്രം results = search_web(f"book {query} to {preferences['destination']}") return results def personalize_results(results, user_history): # വ്യക്തിഗതവത്കരണ തന്ത്രത്തിന്റെ ഉദാഹരണം personalized = [result for result in results if result not in user_history] return personalized[:10] # മുകളിലെ 10 വ്യക്തിഗത ഫലങ്ങൾ തിരികെ നൽകുക -
ഉദാഹരണ ഉപയോഗം
travel_agent = Travel_Agent() preferences = { "destination": "Paris", "interests": ["museums", "cuisine"] } travel_agent.gather_preferences(preferences) user_history = ["Louvre Museum website", "Book flight to Paris"] query = "best museums in Paris" results = search_with_intent(query, preferences, user_history) print("Search Results:", results)
4. ടൂളായി കോഡ് സൃഷ്ടിക്കൽ
കോഡ് നിർമ്മിക്കുന്ന ഏജന്റുകൾ എഐ മോഡലുകൾ ഉപയോഗിച്ച് കോഡ് എഴുതാനും പ്രവർത്തിപ്പിക്കാനും, സങ്കീർണ പ്രശ്നങ്ങൾ പരിഹരിക്കുകയും ടാസ്കുകൾ സ്വയം ഓട്ടോമേറ്റ് ചെയ്യുകയും ചെയ്യുന്നു.
കോഡ് സൃഷ്ടിക്കുന്ന ഏജന്റുകൾ
കോഡ് സൃഷ്ടിക്കുന്ന ഏജന്റുകൾ ജനറേറ്റീവ് എഐ മോഡലുകൾ ഉപയോഗിച്ച് കോഡ് എഴുതാനും പ്രവർത്തിപ്പിക്കാനും ഉപയോഗിക്കുന്നു. വിവിധ പ്രോഗ്രാമിങ് ഭാഷകളിൽ കോഡ് ജനറേറ്റ് ചെയ്ത് ഓടിക്കുന്നതിലൂടെ ഇവ സങ്കീർണ പ്രശ്നങ്ങൾ പരിഹരിക്കാനും, ടാസ്കുകൾ സ്വയം ഓട്ടോമേറ്റ് ചെയ്യാനും, വിലപ്പെട്ട അവബോധങ്ങൾ നൽകാനും കഴിയും.
പ്രായോഗിക പ്രയോഗങ്ങൾ
- Automated Code Generation: പ്രത്യേക ടാസ്കുകൾക്കായുള്ള കോഡ് സ്നിപ്പെറ്റുകൾ ജനറേറ്റ് ചെയ്യുക, ഉദാഹരണത്തിന് ഡാറ്റ അനാലിസിസ്, വെബ് സ്ക്രാപ്പിംഗ്, അല്ലെങ്കിൽ മെഷീൻ ലേണിംഗ്.
- SQL as a RAG: ഡാറ്റാബേസുകളിൽ നിന്ന് ഡാറ്റ പുനർപ്രാപ്തിയാക്കാനും മാനിപുലേറ്റ് ചെയ്യാനും SQL ക്വേറികൾ ഉപയോഗിക്കുക.
- Problem Solving: ആൽഗോരിതങ്ങൾ ഓപ്റ്റിമൈസ് ചെയ്യുന്നതോ ഡാറ്റ വിശകലനം ചെയ്യുന്നതോ പോലുള്ള പ്രത്യേക പ്രശ്നങ്ങൾ പരിഹരിക്കാൻ കോഡ് സൃഷ്ടിക്കുകയും പ്രവർത്തിപ്പിക്കുകയും ചെയ്യുക.
ഉദാഹരണം: ഡാറ്റാ അനാലിസിസിനുള്ള കോഡ് സൃഷ്ടിക്കുന്ന ഏജന്റ്
കേലാക്കി നിങ്ങള് ഒരു കോഡ് സൃഷ്ടിക്കുന്ന ഏജന്റ് രൂപകൽപ്പന ചെയ്യുകയാണെന്ന് കരുതുക. ഇത് എങ്ങനെ പ്രവർത്തിക്കുമെന്ന് ഇതാ:
- കാര്യ്യം: ഒരു ഡാറ്റാസെറ്റ് വിശകലനം ചെയ്ത് പ്രവണതകളും മാതൃകകളും കണ്ടെത്തുക.
- Steps:
- ഡാറ്റാസെറ്റ് ഡാറ്റാ അനാലിസിസ് ടൂളിലേക്ക് ലോഡ് ചെയ്യുക.
- ഡാറ്റ ഫിൽറ്റർ ചെയ്യാനും സംഗ്രഹിക്കാനുമുള്ള SQL ക്വേറികൾ ജനറേറ്റ് ചെയ്യുക.
- ക്വേറികൾ പ്രവർത്തിപ്പിച്ച് ഫലങ്ങൾ നേടുക.
- ഫലങ്ങൾ ഉപയോഗിച്ച് ദൃശ്യവൽക്കരണങ്ങളും അവബോധങ്ങളും സൃഷ്ടിക്കുക.
- Required Resources: ഡാറ്റാസെറ്റ് ആക്സസ്, ഡാറ്റാ അനാലിസിസ് ടൂൾസ്, SQL ശേഷി എന്നിവ.
- Experience: മുമ്പത്തെ വിശകലന ഫലങ്ങൾ ഉപയോഗിച്ച് ഭാവിയിലെ വിശകലനങ്ങളുടെ കൃത്യതയും പ്രസക്തിയും മെച്ചപ്പെടുത്തുക.
ഉദാഹരണം: യാത്രാ ഏജന്റിനുള്ള കോഡ് സൃഷ്ടിക്കുന്ന ഏജന്റ്
ഈ ഉദാഹരണത്തിൽ, നാം ഒരു കോഡ് സൃഷ്ടിക്കുന്ന ഏജന്റ്, Travel Agent, രൂപകൽപ്പന ചെയ്യാം, ഇത് കോഡ് ജനറേറ്റ് ചെയ്ത് പ്രവർത്തിപ്പിച്ചുകൊണ്ട് ഉപയോക്താക്കളെ അവരുടെ യാത്രാ പദ്ധതികൾ ഒരുക്കാൻ സഹായിക്കുന്നു. ഈ ഏജന്റ് യാത്രാ ഓപ്ഷനുകൾ കണ്ടെത്തൽ, ഫലങ്ങൾ ഫിൽറ്റർ ചെയ്യൽ, ഒരു യാത്രാ രൂപരേഖ യോജിപ്പിക്കൽ തുടങ്ങിയകാര്യങ്ങൾ കൈകാര്യം ചെയ്യാൻ കഴിയും.
കോഡ് സൃഷ്ടിക്കുന്ന ഏജന്റിന്റെ അവലോകനം
- ഉപയോക്തൃ താല്പര്യങ്ങൾ ശേഖരണം: ലക്ഷ്യസ്ഥലം, യാത്രാ തീയതികൾ, ബഡ്ജറ്റ്, ഇൻററസ്റ്റുകൾ എന്നിവ പോലുള്ള ഉപയോക്തൃ ഇൻപുട്ടുകൾ ശേഖരിക്കുക.
- ഡാറ്റ എടുക്കാനുള്ള കോഡ് ജനറേറ്റ് ചെയ്യുക: പറവലുകൾ, ഹോട്ടലുകൾ, ആകർഷണങ്ങൾ എന്നിവയെ കുറിച്ചുള്ള ഡാറ്റ ലഭ്യമാക്കാൻ കോഡ് സ്നിപ്പെറ്റുകൾ ജനറേറ്റ് ചെയ്യുക.
- ജനറേറ്റ് ചെയ്ത കോഡ് നടപ്പാക്കുക: റിയൽ-ടൈം വിവരങ്ങൾ എടുക്കാൻ ജനറേറ്റ് ചെയ്ത കോഡ് 실행ചെയ്യുക.
- യാത്രാമുറി ജനറേറ്റ് ചെയ്യുക: ശേഖരിച്ച ഡാറ്റ ഉപയോഗിച്ച് വ്യക്തിഗതമായ ഒരു യാത്രാ പദ്ധതി തയാറാക്കുക.
- പ്രതികരണത്തെ അടിസ്ഥാനമാക്കി ക്രമീകരിക്കൽ: ഉപയോക്തൃ ഫീഡ്ബാക്ക് സ്വീകരിച്ച് ആവശ്യമായാൽ ഫലങ്ങൾ മെച്ചപ്പെടുത്താൻ കോഡ് റീജനറേറ്റ് ചെയ്യുക.
ഘട്ടത്തിനു ഘട്ടം നടപ്പീകരണം
-
Gathering User Preferences
class Travel_Agent: def __init__(self): self.user_preferences = {} def gather_preferences(self, preferences): self.user_preferences = preferences -
Generating Code to Fetch Data
def generate_code_to_fetch_data(preferences): # ഉദാഹരണം: ഉപയോക്താവിന്റെ ഇഷ്ടാനുസൃതികളുടെ അടിസ്ഥാനത്തിൽ വിമാനങ്ങൾ തിരയാനുള്ള കോഡ് സൃഷ്ടിക്കുക code = f""" def search_flights(): import requests response = requests.get('https://api.example.com/flights', params={preferences}) return response.json() """ return code def generate_code_to_fetch_hotels(preferences): # উদাহരണം: ഹോട്ടലുകൾ തിരയാനുള്ള কোഡ് সൃഷ്ടിക്കുക code = f""" def search_hotels(): import requests response = requests.get('https://api.example.com/hotels', params={preferences}) return response.json() """ return code -
Executing Generated Code
def execute_code(code): # സൃഷ്ടിച്ച കോഡ് exec ഉപയോഗിച്ച് നിർവഹിക്കുക exec(code) result = locals() return result travel_agent = Travel_Agent() preferences = { "destination": "Paris", "dates": "2025-04-01 to 2025-04-10", "budget": "moderate", "interests": ["museums", "cuisine"] } travel_agent.gather_preferences(preferences) flight_code = generate_code_to_fetch_data(preferences) hotel_code = generate_code_to_fetch_hotels(preferences) flights = execute_code(flight_code) hotels = execute_code(hotel_code) print("Flight Options:", flights) print("Hotel Options:", hotels) -
Generating Itinerary
def generate_itinerary(flights, hotels, attractions): itinerary = { "flights": flights, "hotels": hotels, "attractions": attractions } return itinerary attractions = search_attractions(preferences) itinerary = generate_itinerary(flights, hotels, attractions) print("Suggested Itinerary:", itinerary) -
Adjusting Based on Feedback
def adjust_based_on_feedback(feedback, preferences): # ഉപയോക്തൃ പ്രതികരണത്തിന്റെ അടിസ്ഥാനത്തിൽ മുൻഗണനകൾ ക്രമീകരിക്കുക if "liked" in feedback: preferences["favorites"] = feedback["liked"] if "disliked" in feedback: preferences["avoid"] = feedback["disliked"] return preferences feedback = {"liked": ["Louvre Museum"], "disliked": ["Eiffel Tower (too crowded)"]} updated_preferences = adjust_based_on_feedback(feedback, preferences) # പുതുക്കിയ മുൻഗണനകളോടെ കോഡ് വീണ്ടും സൃഷ്ടിച്ച് നിർവഹിക്കുക updated_flight_code = generate_code_to_fetch_data(updated_preferences) updated_hotel_code = generate_code_to_fetch_hotels(updated_preferences) updated_flights = execute_code(updated_flight_code) updated_hotels = execute_code(updated_hotel_code) updated_itinerary = generate_itinerary(updated_flights, updated_hotels, attractions) print("Updated Itinerary:", updated_itinerary)
പരിസ്ഥിതി ബോധവും ന്യായീകരണവും പ്രയോജനപ്പെടുത്തൽ
ടേബിളിന്റെ സ്കീമയെ അടിസ്ഥാനമാക്കുന്നത് പരിസ്ഥിതി ബോധവും ന്യായീകരണവും ഉപയോഗിച്ച് ക്വറി സൃഷ്ടി പ്രക്രിയയെ മെച്ചപ്പെടുത്താൻ സഹായിക്കാം.
ഇത് എങ്ങനെ ചെയ്യാമെന്നു കാണിച്ചുള്ള ഒരു ഉദാഹരണം:
- സ്കീമയുടെ മനസ്സിലാക്കൽ: സിസ്റ്റം ടേബിൾ സ്കീമയെ മനസ്സിലാക്കുകയും ഈ വിവരങ്ങൾ ക്വറി ജനറേഷനറുടെ അടിസ്ഥാനമാക്കാൻ ഉപയോഗപ്പെടുത്തുകയും ചെയ്യും.
- ഫീഡ്ബാക്കിനെ അടിസ്ഥാനമാക്കി ക്രമീകരിക്കൽ: സിസ്റ്റം ഫീഡ്ബാക്കിന്റെ അടിസ്ഥാനത്തിൽ ഉപയോക്തൃ താല്പര്യങ്ങൾ ക്രമീകരിക്കുകയും സ്കീമയിലെ ഏതു ഫീൽഡുകൾ അപ്ഡേറ്റ് ചെയ്യേണ്ടതാണെന്ന് നിര്ണയിക്കുകയും ചെയ്യും.
- ക്വേറികൾ സൃഷ്ടിക്കുകയും നടപ്പാക്കുകയും ചെയ്യുക: പുതിയ താല്പര്യങ്ങളുടെ അടിസ്ഥാനത്തിൽ അപ്ഡേറ്റുചെയ്ത ഫ്ലൈറ്റ്, ഹോട്ടൽ ഡാറ്റ എന്നിവയെ കണ്ടെത്താനായി സിസ്റ്റം ക്വേറികൾ സൃഷ്ടിക്കുകയും നടപ്പാക്കുകയും ചെയ്യും.
ഈ ആശയങ്ങൾ ഉൾപ്പെടുത്തുന്ന അപ്ഡേറ്റഡ് Python കോഡ് ഉദാഹരണം ഇവിടെ കൊടുക്കുന്നു:
def adjust_based_on_feedback(feedback, preferences, schema):
# ഉപയോക്തൃ പ്രതികരണത്തിന്റെ അടിസ്ഥാനത്തിൽ മുൻഗണനകൾ ക്രമീകരിക്കുക
if "liked" in feedback:
preferences["favorites"] = feedback["liked"]
if "disliked" in feedback:
preferences["avoid"] = feedback["disliked"]
# മറ്റ് ബന്ധപ്പെട്ട മുൻഗണനകൾ ക്രമീകരിക്കുന്നതിന് സ്കീമയെ ആസ്പദമാക്കിയുള്ള ന്യായീകരണം
for field in schema:
if field in preferences:
preferences[field] = adjust_based_on_environment(feedback, field, schema)
return preferences
def adjust_based_on_environment(feedback, field, schema):
# സ്കീമയും പ്രതികരണവും അടിസ്ഥാനമാക്കി മുൻഗണനകൾ ക്രമീകരിക്കാൻ ഇഷ്ടാനുസൃത തർക്കരീതി
if field in feedback["liked"]:
return schema[field]["positive_adjustment"]
elif field in feedback["disliked"]:
return schema[field]["negative_adjustment"]
return schema[field]["default"]
def generate_code_to_fetch_data(preferences):
# അപ്ഡേറ്റ് ചെയ്ത മുൻഗണനകളുടെ അടിസ്ഥാനത്തിൽ വിമാന ഡാറ്റ നേടുന്ന കോഡ് തയാറാക്കുക
return f"fetch_flights(preferences={preferences})"
def generate_code_to_fetch_hotels(preferences):
# അപ്ഡേറ്റ് ചെയ്ത മുൻഗണനകളുടെ അടിസ്ഥാനത്തിൽ ഹോട്ടൽ ഡാറ്റ നേടുന്ന കോഡ് തയാറാക്കുക
return f"fetch_hotels(preferences={preferences})"
def execute_code(code):
# കോഡ് പ്രവർത്തനം അനുകരിച്ച് മാതൃകാ ഡാറ്റ മടക്കി നൽകുക
return {"data": f"Executed: {code}"}
def generate_itinerary(flights, hotels, attractions):
# വിമാനങ്ങൾ, ഹോട്ടലുകൾ, ആകർഷണങ്ങൾ എന്നിവയുടെ അടിസ്ഥാനത്തിൽ യാത്രാപട്ടിക സൃഷ്ടിക്കുക
return {"flights": flights, "hotels": hotels, "attractions": attractions}
# ഉദാഹരണ സ്കീമ
schema = {
"favorites": {"positive_adjustment": "increase", "negative_adjustment": "decrease", "default": "neutral"},
"avoid": {"positive_adjustment": "decrease", "negative_adjustment": "increase", "default": "neutral"}
}
# ഉദാഹരണ ഉപയോഗം
preferences = {"favorites": "sightseeing", "avoid": "crowded places"}
feedback = {"liked": ["Louvre Museum"], "disliked": ["Eiffel Tower (too crowded)"]}
updated_preferences = adjust_based_on_feedback(feedback, preferences, schema)
# അപ്ഡേറ്റ് ചെയ്ത മുൻഗണനകളോടെ കോഡ് പുനഃസൃഷ്ടിച്ച് പ്രവർത്തിപ്പിക്കുക
updated_flight_code = generate_code_to_fetch_data(updated_preferences)
updated_hotel_code = generate_code_to_fetch_hotels(updated_preferences)
updated_flights = execute_code(updated_flight_code)
updated_hotels = execute_code(updated_hotel_code)
updated_itinerary = generate_itinerary(updated_flights, updated_hotels, feedback["liked"])
print("Updated Itinerary:", updated_itinerary)
വിശദീകരണം - ഫീഡ്ബാക്കിനെ അടിസ്ഥാനമാക്കി ബുക്കിംഗ്
- സ്കീമ ബോധം:
schemaഡിക്ഷണറി ഫീഡ്ബാക്കിന്റെ അടിസ്ഥാനത്തിൽ താല്പര്യങ്ങൾ എങ്ങനെ ക്രമീകരിക്കാനാണെന്ന് നിർവചിക്കുന്നു. ഇത്favoritesևavoidപോലുള്ള ഫീൽഡുകൾക്കും ബന്ധപ്പെട്ട ക്രമീകരണങ്ങൾക്കും ഉൾക്കൊള്ളുന്നു. - പ്രഫറൻസുകൾ ക്രമീകരിക്കൽ (
adjust_based_on_feedbackmethod): ഈ മെത്തഡ് ഉപയോക്തൃ ഫീഡ്ബാക്കിന്റെയും സ്കീമയുടെയും അടിസ്ഥാനത്തിൽ പ്രഫറൻസുകൾ ക്രമീകരിക്കുന്നു. - പരിസ്ഥിതി-ആധാരിത ക്രമീകരണങ്ങൾ (
adjust_based_on_environmentmethod): ഈ മെത്തഡ് സ്കീമയും ഫീഡ്ബാക്കും അടിസ്ഥാനമാക്കി ക്രമീകരണങ്ങൾക്ക് അനുയോജ്യമായ മാറ്റങ്ങൾ ചെയ്യുന്നു. - ക്വേറികൾ സൃഷ്ടിക്കുകയും നടപ്പാക്കുകയും ചെയ്യുക: ക്രമീകരിച്ച പ്രഫറൻസുകൾ അടിസ്ഥാനമാക്കി അപ്ഡേറ്റചെയ്ത ഫ്ലൈറ്റ്, ഹോട്ടൽ ഡാറ്റ എന്നിവ പകത്താൻ സിസ്റ്റം കോഡ് തയാറാക്കുകയും ഈ ക്വേറികളുടെ എക്സിക്യൂഷൻ സിമുലേറ്റ് ചെയ്യുകയും ചെയ്യുന്നു.
- യാത്രാമുറി ജെനറേറ്റ് ചെയ്യുക: പുതിയ ഫ്ലൈറ്റ്, ഹോട്ടൽ, ആകർഷണ ഡാറ്റ അടിസ്ഥാനമാക്കി സിസ്റ്റം അപ്ഡേറ്റചെയ്ത യാത്രാമുറി സൃഷ്ടിക്കുന്നു.
സിസ്റ്റംപരിസ്ഥിതി-ബോധമുള്ളതും സ്കീമയെ അടിസ്ഥാനമാക്കി ന്യായീകരിച്ചും ഉള്ളപ്പോൾ, ഇത് കൂടുതൽ കൃത്യമായും പ്രസക്തമായും ക്വേറികൾ ജനറേറ്റ് ചെയ്യാൻ സഹായിക്കുകയും മികച്ച യാത്രാ ശിപാർശകൾക്കും വ്യക്തിഗത അനുഭവത്തിനും നയിക്കുകയും ചെയ്യും.
SQL-നെ Retrieval-Augmented Generation (RAG) സാങ്കേതികതയായി ഉപയോഗിക്കൽ
SQL (Structured Query Language) ഡാറ്റാബേസുകളുമായി ഇടപഴകാൻ ശക്തിയുള്ള ഒരു ഉപകരണമാണ്. Retrieval-Augmented Generation (RAG) സമീപനത്തിന്റെ ഭാഗമായ når SQL ഉപയോഗിച്ചാൽ, ഡാറ്റാബേസിനിന്ന് പ്രസക്തമായ ഡാറ്റ എടുക്കാനും അത് എഐ ഏജന്റുകളുടെ പ്രതികരണങ്ങൾ അല്ലെങ്കിൽ പ്രവർത്തനങ്ങൾ നിർമ്മിക്കാൻ ഉപയോഗിക്കാനും കഴിയും. ട്രാവൽ ഏജന്റ് പ്രেক্ষപ്തിയിൽ SQL RAG സാങ്കേതികമായി എങ്ങനെ ഉപയോഗിക്കാമെന്നു നമുക്ക് അന്വേഷിക്കും.
മുഖ്യ ആശയങ്ങൾ
- ഡേറ്റാബേസ് ഇന്ററാക്ഷൻ:
- SQL ഡാറ്റാബേസുകൾ ക്വറി ചെയ്യാനും, പ്രസക്തമായ വിവരങ്ങൾ പ്രാപ്തിയാക്കാനും, ഡാറ്റ മാനിപ്പുലേറ്റ് ചെയ്യാനും ഉപയോഗിക്കുന്നു.
- ഉദാഹരണം: യാത്രാ ഡാറ്റാബേസിൽ നിന്ന് ഫ്ലൈറ്റ് വിശദാംശങ്ങൾ, ഹോട്ടൽ தகவൽ, ആകർഷണങ്ങൾ എന്നിവ കണ്ടെത്തൽ.
- RAG-യുമായി സംയോജനം:
- SQL ക്വേറുകൾ ഉപയോക്തൃ ഇൻപുട്ടും താല്പര്യങ്ങളും അടിസ്ഥാനമാക്കി ജനറേറ്റ് ചെയ്യപ്പെടും.
- പ്രാപ്തമാക്കിയ ഡാറ്റ വ്യക്തിഗത ശിപാർശകൾ അല്ലെങ്കിൽ പ്രവർത്തനങ്ങൾ ജനറേറ്റ് ചെയ്യാൻ ഉപയോഗിക്കും.
- ഡൈനാമിക് ക്വറി ജനറേഷൻ:
- AI ഏജന്റ് സ.context ന്റെ അടിസ്ഥാനത്തിൽ ആധാരമാക്കി ഡൈനാമിക് SQL ക്വേറുകൾ സൃഷ്ടിക്കും.
- ഉദാഹരണം: ബഡ്ജറ്റ്, തീയതികൾ, താല്പര്യങ്ങൾ എന്നിവയെ അടിസ്ഥാനമാക്കി ഫലങ്ങൾ ഫിൽറ്റർ ചെയ്യാൻ SQL ക്വേറുകൾ ക്രമീകരിക്കൽ.
പ്രയോഗങ്ങൾ
- Automated Code Generation: പ്രത്യേക ടാസ്കുകൾക്കായുള്ള കോഡ് സ്നിപ്പെറ്റുകൾ 생성 ചെയ്യുക.
- SQL as a RAG: ഡാറ്റ മാനിപ്പുലേറ്റ് ചെയ്യാൻ SQL ക്വേറികൾ ഉപയോഗിക്കുക.
- Problem Solving: പ്രശ്നങ്ങൾ പരിഹരിക്കാൻ കോഡ് സൃഷ്ടിക്കുകയും 실행ചെയ്യുകയും ചെയ്യുക.
ഉദാഹരണം: ഒരു ഡാറ്റാ അനാലിസിസ് ഏജന്റ്:
- കാര്യ്യം: ട്രെൻഡുകൾ കണ്ടെത്താൻ ഒരു ഡാറ്റാസെറ്റ് വിശകലനം ചെയ്യുക.
- ഘട്ടങ്ങൾ:
- ഡാറ്റാസെറ്റ് ലോഡ് ചെയ്യുക.
- ഡാറ്റ ഫിൽറ്ററിംഗ് നടത്താൻ SQL ക്വേറുകൾ ജനറേറ്റ് ചെയ്യുക.
- ക്വേറുകൾ 실행ചെയ്യുകയും ഫലങ്ങൾ ലഭ്യമാക്കുകയും ചെയ്യുക.
- ദൃശ്യവൽക്കരണങ്ങളും洞洞 അവബോധങ്ങളും生成 ചെയ്യുക.
- വിഭവങ്ങൾ: ഡാറ്റാസെറ്റ് ആക്സസ്, SQL ശേഷി.
- അനുഭവം: മുന് ഫലങ്ങൾ ഉപയോഗിച്ച് ഭവिष्यത്തെ വിശകലനങ്ങൾ മെച്ചപ്പെടുത്തുക.
പ്രായോഗിക ഉദാഹരണം: ട്രാവൽ ഏജന്റിൽ SQL ഉപയോഗിക്കൽ
-
Gathering User Preferences
class Travel_Agent: def __init__(self): self.user_preferences = {} def gather_preferences(self, preferences): self.user_preferences = preferences -
Generating SQL Queries
def generate_sql_query(table, preferences): query = f"SELECT * FROM {table} WHERE " conditions = [] for key, value in preferences.items(): conditions.append(f"{key}='{value}'") query += " AND ".join(conditions) return query -
Executing SQL Queries
import sqlite3 def execute_sql_query(query, database="travel.db"): connection = sqlite3.connect(database) cursor = connection.cursor() cursor.execute(query) results = cursor.fetchall() connection.close() return results -
Generating Recommendations
def generate_recommendations(preferences): flight_query = generate_sql_query("flights", preferences) hotel_query = generate_sql_query("hotels", preferences) attraction_query = generate_sql_query("attractions", preferences) flights = execute_sql_query(flight_query) hotels = execute_sql_query(hotel_query) attractions = execute_sql_query(attraction_query) itinerary = { "flights": flights, "hotels": hotels, "attractions": attractions } return itinerary travel_agent = Travel_Agent() preferences = { "destination": "Paris", "dates": "2025-04-01 to 2025-04-10", "budget": "moderate", "interests": ["museums", "cuisine"] } travel_agent.gather_preferences(preferences) itinerary = generate_recommendations(preferences) print("Suggested Itinerary:", itinerary)
Example SQL Queries
-
Flight Query
SELECT * FROM flights WHERE destination='Paris' AND dates='2025-04-01 to 2025-04-10' AND budget='moderate'; -
Hotel Query
SELECT * FROM hotels WHERE destination='Paris' AND budget='moderate'; -
Attraction Query
SELECT * FROM attractions WHERE destination='Paris' AND interests='museums, cuisine';
SQL-നെ Retrieval-Augmented Generation (RAG) സാങ്കേതികതയുടെ ഭാഗമായും ഉപയോഗിക്കുന്നതിലൂടെ, Travel Agent പോലുള്ള AI ഏജന്റുകൾ ഡൈനാമിക്കായി പ്രസക്തമായ ഡാറ്റ പുനർപ്രാപ്തിയാക്കുകയും അതിനെ ഉപയോഗിച്ച് കൃത്യവും വ്യക്തിഗതവുമായ ശിപാർശകൾ നൽകുകയും ചെയ്യുക.
മെറ്റാകോഗ്നിഷൻ ഉദാഹരണം
മെറ്റാകോഗ്നിഷന്റെ ഒരു നടപ്പാക്കൽ പ്രകടിപ്പിക്കാൻ, ഒരു എളുപ്പമുള്ള ഏജന്റ് നിർമ്മിക്കാം, ഇത് ഒരു പ്രശ്നം പരിഹരിക്കുമ്പോൾ തീരുമാൻ എടുക്കുന്ന പ്രക്രിയയെപ്പറ്റി പ്രതിബിംബിക്കുന്നു. ഈ ഉദാഹരണത്തിനായി, ഒരു ഏജന്റ് വിലയും ഗുണനിലവാരവും സംയോജിപ്പിച്ച് ഹോട്ടൽ തിരഞ്ഞെടുക്കാൻ ശ്രമിക്കുന്ന ഒരു സിസ്റ്റം നിർമ്മിക്കുകയും, പിന്നീട് അതിന്റെ ന്യായീകരണത്തെ self-evaluate ചെയ്യുകയും, പിഴവുകൾ ഉണ്ടാകുമ്പോൾ തന്ത്രം ക്രമീകരിക്കുകയും ചെയ്യും.
നാം ഒരു അടിസ്ഥാന ഉദാഹരണത്തിലൂടെ ഇത് സിമുലേറ്റ് ചെയ്യാം: ഏജന്റ് വിലയും ഗുണനിലവാരവും അധിഷ്ഠിതമായി ഹോട്ടലുകൾ തിരഞ്ഞെടുക്കുന്നു, പക്ഷേ تصمیمങ്ങൾ “reflect” ചെയ്യുകയും അനുസരിച്ച് ക്രമീകരിക്കുകയും ചെയ്യും.
ഇത് മെറ്റാകോഗ്നിഷനെ എങ്ങനെ വിശദീകരിക്കുന്നു:
- ആരംഭകരമായ നിർദ്ദേശം: ഏജന്റ് ഏറ്റവും കുറഞ്ഞ വിലയുള്ള ഹോട്ടൽ തിരഞ്ഞെടുക്കും, ഗുണനിലവാരത്തിന്റെ പ്രഭാവം മനസ്സിലാക്കാതെ.
- പരാമർശവും മൂല്യനിർണയവും: ആദ്യ തിരഞ്ഞെടുപ്പിന് ശേഷം, ഉപയോക്തൃ ഫീഡ്ബാക്ക് ഉപയോഗിച്ച് ഹോട്ടൽ “തെറ്റായ” തിരഞ്ഞെടുപ്പാണോയെന്ന് ഏജന്റ് പരിശോധിക്കും. ഹോട്ടലിന്റെ ഗുണനിലവാരം വളരെ താഴെയാണെന്ന് കണ്ടെത്തിയാൽ, അത് തന്റെ ന്യായീകരണത്തെ മറിച്ചു നോക്കും.
- തന്ത്രമാറ്റം: പ്രതിഫലനത്തിന്റെ അടിസ്ഥാനത്തിൽ ഏജന്റ് തന്ത്രം ക്രമീകരിക്കുന്നു — “cheapest” മുതൽ “highest_quality” വരെ മാറിപ്പോകുന്നു, ഇതുവഴി ഭാവിയിലെ തീരുമാനമെടുക്കൽ പ്രക്രിയ മെച്ചപ്പെടുത്തുന്നു.
ഇവിടെ ഒരു ഉദാഹരണം:
class HotelRecommendationAgent:
def __init__(self):
self.previous_choices = [] # മുമ്പ് തിരഞ്ഞെടുക്കപ്പെട്ട ഹോട്ടലുകൾ സംഭരിക്കുന്നു
self.corrected_choices = [] # തിരുത്തിയ തിരഞ്ഞെടുപ്പുകൾ സംഭരിക്കുന്നു
self.recommendation_strategies = ['cheapest', 'highest_quality'] # ലഭ്യമായ തന്ത്രങ്ങൾ
def recommend_hotel(self, hotels, strategy):
"""
Recommend a hotel based on the chosen strategy.
The strategy can either be 'cheapest' or 'highest_quality'.
"""
if strategy == 'cheapest':
recommended = min(hotels, key=lambda x: x['price'])
elif strategy == 'highest_quality':
recommended = max(hotels, key=lambda x: x['quality'])
else:
recommended = None
self.previous_choices.append((strategy, recommended))
return recommended
def reflect_on_choice(self):
"""
Reflect on the last choice made and decide if the agent should adjust its strategy.
The agent considers if the previous choice led to a poor outcome.
"""
if not self.previous_choices:
return "No choices made yet."
last_choice_strategy, last_choice = self.previous_choices[-1]
# അവസാന തിരഞ്ഞെടുപ്പ് നല്ലതായിരുന്നോ അല്ലയോ എന്ന് പറയുന്ന ഉപയോക്തൃ പ്രതികരണം ഉണ്ടെന്ന് കരുതാം
user_feedback = self.get_user_feedback(last_choice)
if user_feedback == "bad":
# മുൻതിരഞ്ഞെടുപ്പ് തൃപ്തികരമല്ലെങ്കിൽ തന്ത്രം ക്രമീകരിക്കുക
new_strategy = 'highest_quality' if last_choice_strategy == 'cheapest' else 'cheapest'
self.corrected_choices.append((new_strategy, last_choice))
return f"Reflecting on choice. Adjusting strategy to {new_strategy}."
else:
return "The choice was good. No need to adjust."
def get_user_feedback(self, hotel):
"""
Simulate user feedback based on hotel attributes.
For simplicity, assume if the hotel is too cheap, the feedback is "bad".
If the hotel has quality less than 7, feedback is "bad".
"""
if hotel['price'] < 100 or hotel['quality'] < 7:
return "bad"
return "good"
# ഹോട്ടലുകളുടെ പട്ടിക (വിലയും ഗുണനിലവാരവും) സിമുലേറ്റ് ചെയ്യുക
hotels = [
{'name': 'Budget Inn', 'price': 80, 'quality': 6},
{'name': 'Comfort Suites', 'price': 120, 'quality': 8},
{'name': 'Luxury Stay', 'price': 200, 'quality': 9}
]
# ഒരു ഏജന്റ് സൃഷ്ടിക്കുക
agent = HotelRecommendationAgent()
# പടി 1: ഏജന്റ് "cheapest" തന്ത്രം ഉപയോഗിച്ച് ഒരു ഹോട്ടൽ ശുപാർശ ചെയ്യുന്നു
recommended_hotel = agent.recommend_hotel(hotels, 'cheapest')
print(f"Recommended hotel (cheapest): {recommended_hotel['name']}")
# പടി 2: ഏജന്റ് തിരഞ്ഞെടുപ്പിനെ ആലോചിച്ച് ആവശ്യമായെങ്കിൽ തന്ത്രം ക്രമീകരിക്കുന്നു
reflection_result = agent.reflect_on_choice()
print(reflection_result)
# പടി 3: ഏജന്റ് വീണ്ടും ശുപാർശ ചെയ്യുന്നു, ഈ തവണ ക്രമീകരിച്ച തന്ത്രം ഉപയോഗിച്ച്
adjusted_recommendation = agent.recommend_hotel(hotels, 'highest_quality')
print(f"Adjusted hotel recommendation (highest_quality): {adjusted_recommendation['name']}")
ഏജന്റുകളുടെ മെറ്റാകോഗ്നിഷൻ ശേഷികൾ
തീർച്ചയായും പ്രധാന കാര്യം ഏജന്റിന്റെ കഴിവാണ്:
- അതിന്റെ മുമ്പത്തെ തിരഞ്ഞെടുപ്പുകളും തീരുമാനം എടുക്കുന്ന പ്രക്രിയയും വിലയിരുത്തുക.
- ആ പ്രതിഫലനത്തെ അടിസ്ഥാനമാക്കി തന്ത്രം ക്രമീകരിക്കുക, അഥവാ പ്രവർത്തനത്തിലുള്ള മെറ്റാകോഗ്നിഷൻ.
ഇത് ഒരു ലളിതമായ രീതിയിലുള്ള മെറ്റാകോഗ്നിഷനാണ്, യഥാർത്ഥത്തിൽ സിസ്റ്റം ഇന്റർണൽ ഫീഡ്ബാക്കിനെ അടിസ്ഥാനമാക്കി അതിന്റെ ന്യായീകരണ പ്രക്രിയ ക്രമീകരിക്കാൻ കഴിവുള്ളതാണ്.
നിഗമനം
മെറ്റാകോഗ്നിഷൻ ശക്തമായ ഒരു ഉപകരണമാണ്, അത് എഐ ഏജന്റുകളുടെ ശേഷികളെ ശ്രദ്ധേയമായി വർദ്ധിപ്പിക്കാനും സഹായിക്കുന്നു. മെറ്റാകോഗ്നിറ്റീവ് പ്രക്രിയകൾ ഉൾപ്പെടുത്തിക്കൊണ്ട്, നിങ്ങൾ കൂടുതൽ ബുദ്ധിമുട്ടുള്ള, അനുകൂലിച്ച് നിലനിൽക്കുന്ന, കാര്യക്ഷമമായ ഏജന്റുകൾ രൂപകൽപ്പന ചെയ്യാൻ കഴിയും. മെറ്റാകോഗ്നിഷന്റെ രസകരമായ ലോകത്തെങ്കിലും കൂടുതൽ അന്വേഷിക്കാൻ അധിക വിഭവങ്ങൾ ഉപയോഗിക്കൂ.
മെറ്റാകോഗ്നിഷൻ ഡിസൈൻ പാറ്റേൺ സംബന്ധിച്ച കൂടുതൽ ചോദ്യങ്ങളുണ്ടോ?
മറ്റുള്ള പഠിതാക്കളെ സമീപിക്കാൻ, ഓഫീസ് മണിക്കൂറുകളിൽ പങ്കെടുക്കാൻ, നിങ്ങളുടെ AI ഏജന്റുകളുമായി ബന്ധപ്പെട്ട ചോദ്യങ്ങൾക്ക് ഉത്തരം നേടാൻ Microsoft Foundry ഡിസ്കോർഡ് യിൽ ചേക്കൂ.
മുമ്പത്തെ പാഠം
അടുത്ത പാഠം
അറിയിപ്പ്: ഈ രേഖ AI വിവർത്തന സേവനമായ Co-op Translator (https://github.com/Azure/co-op-translator) ഉപയോഗിച്ച് വിവർത്തനം ചെയ്തതാണ്. നാം ശരിയായി വിവർത്തനം ചെയ്യാൻ ശ്രമിച്ചിരുന്നാലും ഓട്ടോമേറ്റഡ് വിവർത്തനങ്ങളിൽ പിശകുകളോ തകരാറുകളോ ഉണ്ടാകാവുന്നതാണെന്ന് ദയവായി ശ്രദ്ധിക്കുക. പ്രധാന ഉറവിടമായി പരിഗണിക്കേണ്ടത് അതിന്റെ മാതൃഭാഷയിലാണ് ഉള്ള മൂല രേഖയാണ്. നിർണായക വിവരങ്ങൾക്കായി പ്രൊഫഷണൽ മനുഷ്യ വിവർത്തനം ശുപാർശ ചെയ്യപ്പെടുന്നു. ഈ വിവർത്തനം ഉപയോഗിക്കുന്നതിൽ നിന്ന് ഉണ്ടായേക്കാവുന്ന യാതൊരു തെറ്റിദ്ധാരണകൾക്കും അല്ലെങ്കിൽ തെറ്റായ വ്യാഖ്യാനങ്ങൾക്കും ഞങ്ങൾ ഉത്തരവാദികളല്ല.