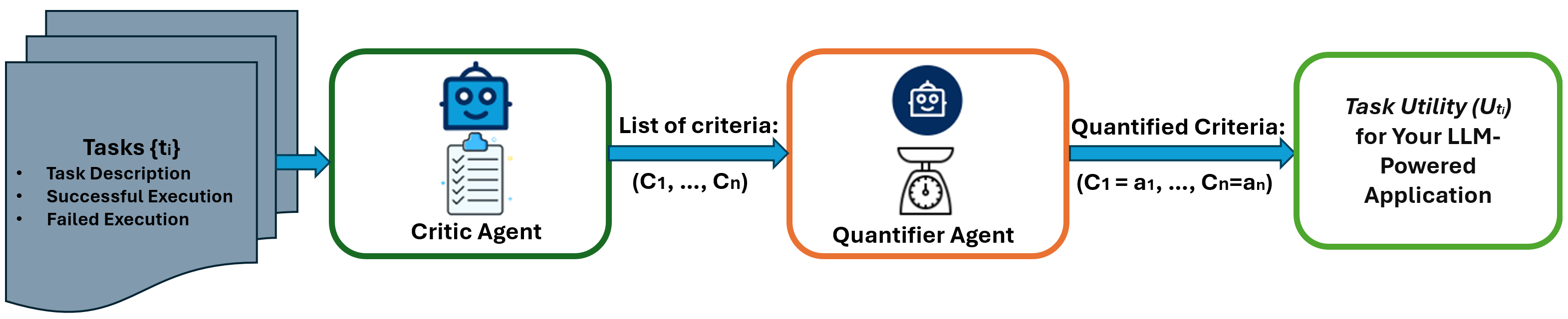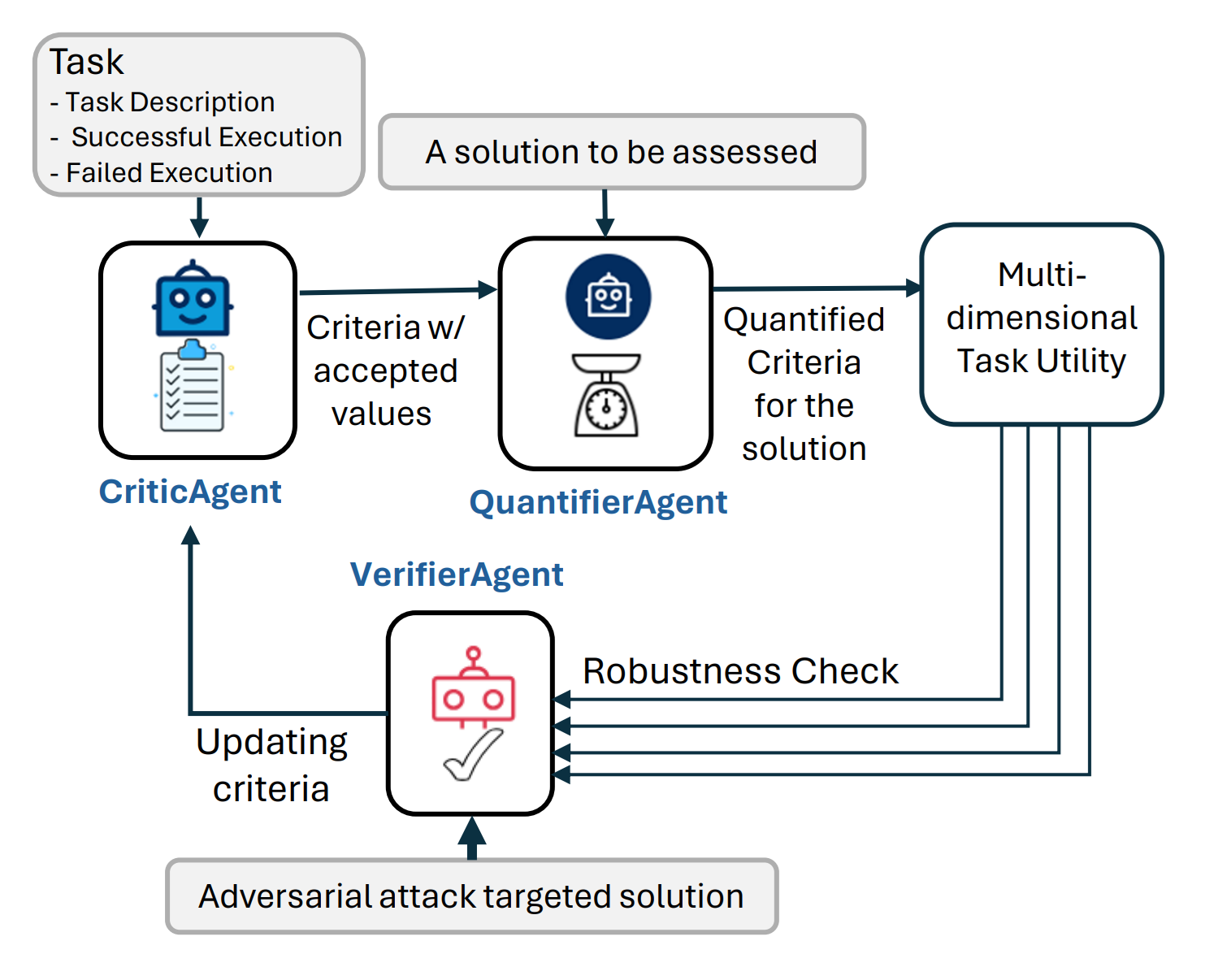
Fig.1 illustrates the general flow of AgentEval with verification step
TL;DR:
- As a developer, how can you assess the utility and effectiveness of an LLM-powered application in helping end users with their tasks?
- To shed light on the question above, we previously introduced
AgentEval— a framework to assess the multi-dimensional utility of any LLM-powered application crafted to assist users in specific tasks. We have now embedded it as part of the AutoGen library to ease developer adoption. - Here, we introduce an updated version of AgentEval that includes a verification process to estimate the robustness of the QuantifierAgent. More details can be found in this paper.
Introduction
Previously introduced AgentEval is a comprehensive framework designed to bridge the gap in assessing the utility of LLM-powered applications. It leverages recent advancements in LLMs to offer a scalable and cost-effective alternative to traditional human evaluations. The framework comprises three main agents: CriticAgent, QuantifierAgent, and VerifierAgent, each playing a crucial role in assessing the task utility of an application.
CriticAgent: Defining the Criteria
The CriticAgent's primary function is to suggest a set of criteria for evaluating an application based on the task description and examples of successful and failed executions. For instance, in the context of a math tutoring application, the CriticAgent might propose criteria such as efficiency, clarity, and correctness. These criteria are essential for understanding the various dimensions of the application's performance. It’s highly recommended that application developers validate the suggested criteria leveraging their domain expertise.
QuantifierAgent: Quantifying the Performance
Once the criteria are established, the QuantifierAgent takes over to quantify how well the application performs against each criterion. This quantification process results in a multi-dimensional assessment of the application's utility, providing a detailed view of its strengths and weaknesses.
VerifierAgent: Ensuring Robustness and Relevance
VerifierAgent ensures the criteria used to evaluate a utility are effective for the end-user, maintaining both robustness and high discriminative power. It does this through two main actions:
-
Criteria Stability:
- Ensures criteria are essential, non-redundant, and consistently measurable.
- Iterates over generating and quantifying criteria, eliminating redundancies, and evaluating their stability.
- Retains only the most robust criteria.
-
Discriminative Power:
- Tests the system's reliability by introducing adversarial examples (noisy or compromised data).
- Assesses the system's ability to distinguish these from standard cases.
- If the system fails, it indicates the need for better criteria to handle varied conditions effectively.
A Flexible and Scalable Framework
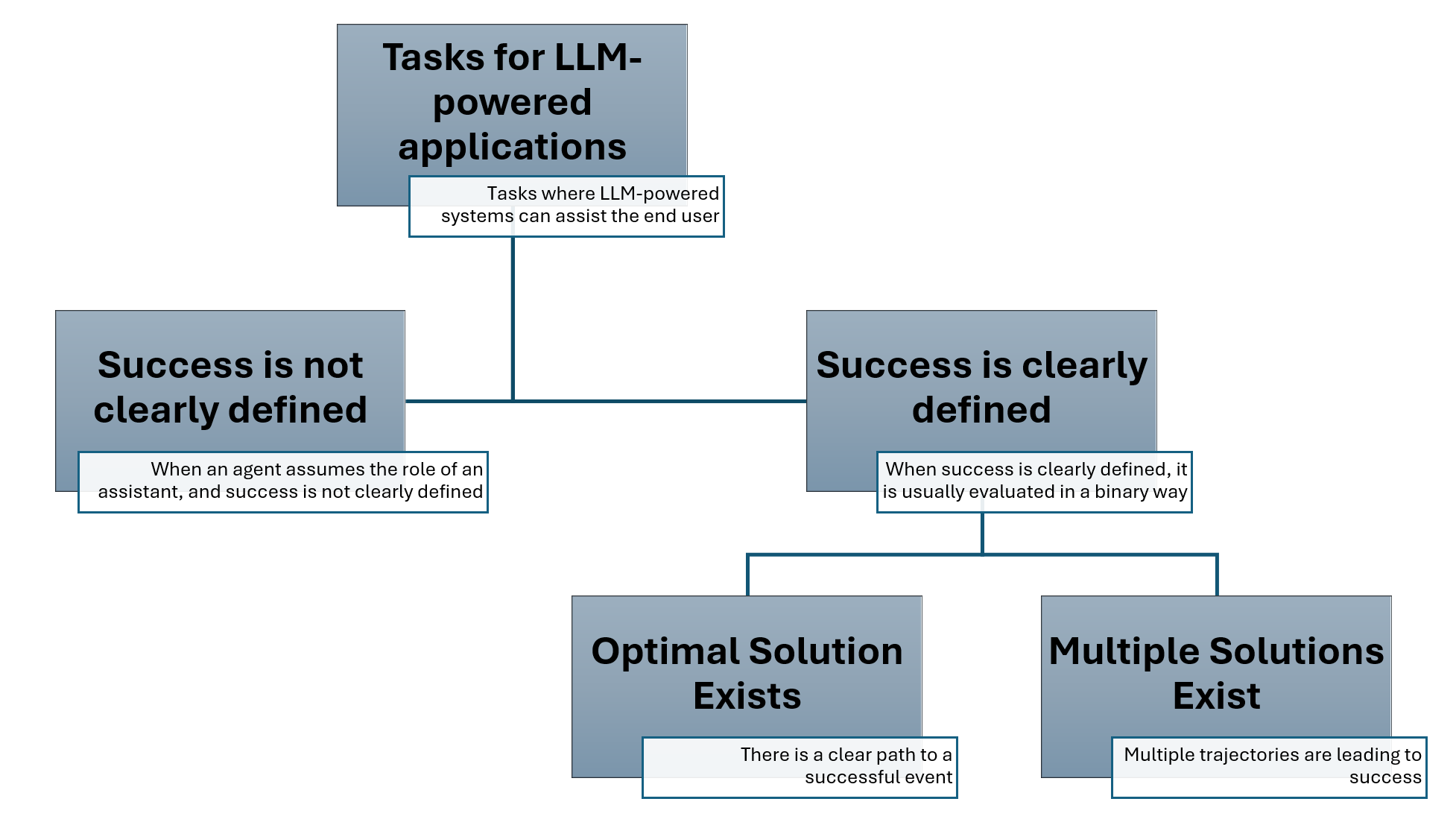
One of AgentEval's key strengths is its flexibility. It can be applied to a wide range of tasks where success may or may not be clearly defined. For tasks with well-defined success criteria, such as household chores, the framework can evaluate whether multiple successful solutions exist and how they compare. For more open-ended tasks, such as generating an email template, AgentEval can assess the utility of the system's suggestions.
Furthermore, AgentEval allows for the incorporation of human expertise. Domain experts can participate in the evaluation process by suggesting relevant criteria or verifying the usefulness of the criteria identified by the agents. This human-in-the-loop approach ensures that the evaluation remains grounded in practical, real-world considerations.
Empirical Validation
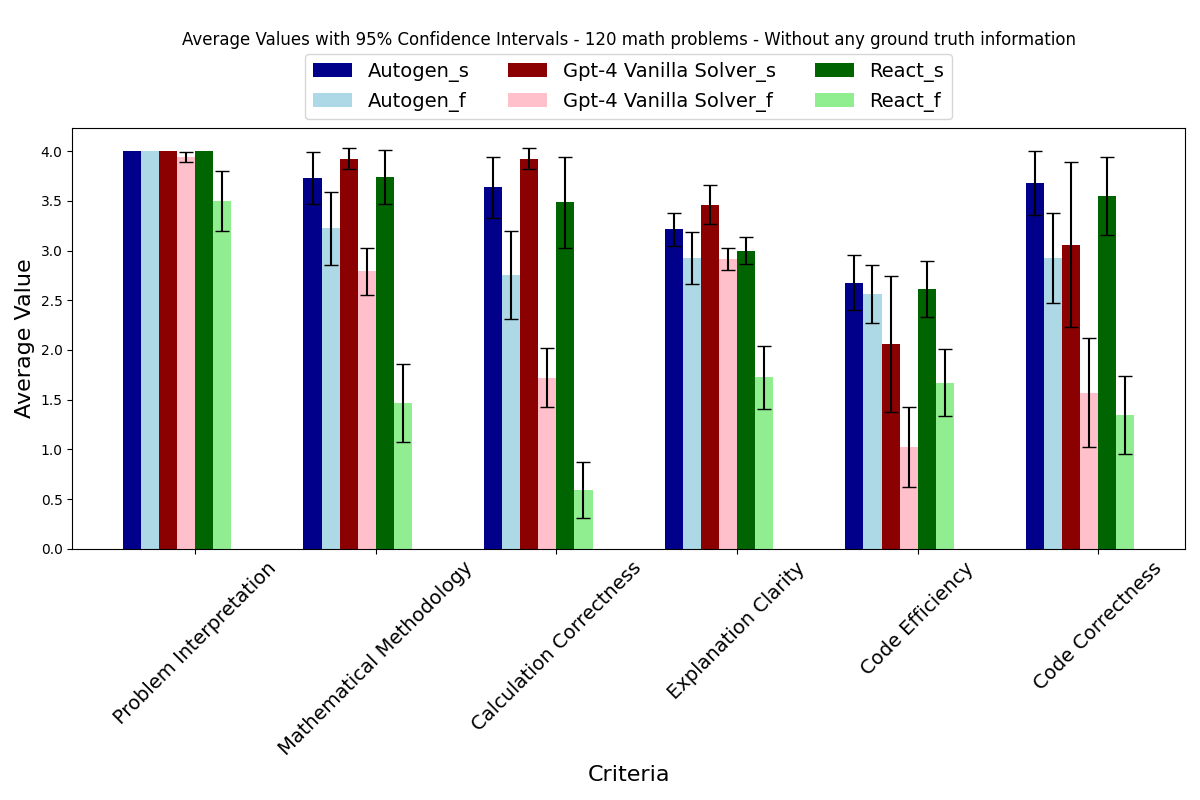
To validate AgentEval, the framework was tested on two applications: math problem solving and ALFWorld, a household task simulation. The math dataset comprised 12,500 challenging problems, each with step-by-step solutions, while the ALFWorld dataset involved multi-turn interactions in a simulated environment. In both cases, AgentEval successfully identified relevant criteria, quantified performance, and verified the robustness of the evaluations, demonstrating its effectiveness and versatility.
How to use AgentEval
AgentEval currently has two main stages; criteria generation and criteria quantification (criteria verification is still under development). Both stages make use of sequential LLM-powered agents to make their determinations.
Criteria Generation:
During criteria generation, AgentEval uses example execution message chains to create a set of criteria for quantifying how well an application performed for a given task.
def generate_criteria(
llm_config: Optional[Union[Dict, Literal[False]]] = None,
task: Task = None,
additional_instructions: str = "",
max_round=2,
use_subcritic: bool = False,
)
Parameters:
- llm_config (dict or bool): llm inference configuration.
- task (Task): The task to evaluate.
- additional_instructions (str, optional): Additional instructions for the criteria agent.
- max_round (int, optional): The maximum number of rounds to run the conversation.
- use_subcritic (bool, optional): Whether to use the Subcritic agent to generate subcriteria. The Subcritic agent will break down a generated criteria into smaller criteria to be assessed.
Example code:
config_list = autogen.config_list_from_json("OAI_CONFIG_LIST")
task = Task(
**{
"name": "Math problem solving",
"description": "Given any question, the system needs to solve the problem as consisely and accurately as possible",
"successful_response": response_successful,
"failed_response": response_failed,
}
)
criteria = generate_criteria(task=task, llm_config={"config_list": config_list})
Note: Only one sample execution chain (success/failure) is required for the task object but AgentEval will perform better with an example for each case.
Example Output:
[
{
"name": "Accuracy",
"description": "The solution must be correct and adhere strictly to mathematical principles and techniques appropriate for the problem.",
"accepted_values": ["Correct", "Minor errors", "Major errors", "Incorrect"]
},
{
"name": "Conciseness",
"description": "The explanation and method provided should be direct and to the point, avoiding unnecessary steps or complexity.",
"accepted_values": ["Very concise", "Concise", "Somewhat verbose", "Verbose"]
},
{
"name": "Relevance",
"description": "The content of the response must be relevant to the question posed and should address the specific problem requirements.",
"accepted_values": ["Highly relevant", "Relevant", "Somewhat relevant", "Not relevant"]
}
]
Criteria Quantification:
During the quantification stage, AgentEval will use the generated criteria (or user defined criteria) to assess a given execution chain to determine how well the application performed.
def quantify_criteria(
llm_config: Optional[Union[Dict, Literal[False]]],
criteria: List[Criterion],
task: Task,
test_case: str,
ground_truth: str,
)
Parameters:
- llm_config (dict or bool): llm inference configuration.
- criteria (Criterion): A list of criteria for evaluating the utility of a given task. This can either be generated by the
generate_criteriafunction or manually created. - task (Task): The task to evaluate. It should match the one used during the
generate_criteriastep. - test_case (str): The execution chain to assess. Typically this is a json list of messages but could be any string representation of a conversation chain.
- ground_truth (str): The ground truth for the test case.
Example Code:
test_case="""[
{
"content": "Find $24^{-1} \\pmod{11^2}$. That is, find the residue $b$ for which $24b \\equiv 1\\pmod{11^2}$.\n\nExpress your answer as an integer from $0$ to $11^2-1$, inclusive.",
"role": "user"
},
{
"content": "To find the modular inverse of 24 modulo 11^2, we can use the Extended Euclidean Algorithm. Here is a Python function to compute the modular inverse using this algorithm:\n\n```python\ndef mod_inverse(a, m):\n..."
"role": "assistant"
}
]"""
quantifier_output = quantify_criteria(
llm_config={"config_list": config_list},
criteria=criteria,
task=task,
test_case=test_case,
ground_truth="true",
)
The output will be a json object consisting of the ground truth and a dictionary mapping each criteria to it's score.
{
"actual_success": true,
"estimated_performance": {
"Accuracy": "Correct",
"Conciseness": "Concise",
"Relevance": "Highly relevant"
}
}
What is next?
- Enabling AgentEval in AutoGen Studio for a nocode solution.
- Fully implementing VerifierAgent in the AgentEval framework.
Conclusion
AgentEval represents a significant advancement in the evaluation of LLM-powered applications. By combining the strengths of CriticAgent, QuantifierAgent, and VerifierAgent, the framework offers a robust, scalable, and flexible solution for assessing task utility. This innovative approach not only helps developers understand the current performance of their applications but also provides valuable insights that can drive future improvements. As the field of intelligent agents continues to evolve, frameworks like AgentEval will play a crucial role in ensuring that these applications meet the diverse and dynamic needs of their users.
Further reading
Please refer to our paper and codebase for more details about AgentEval.
If you find this blog useful, please consider citing:
@article{arabzadeh2024assessing,
title={Assessing and Verifying Task Utility in LLM-Powered Applications},
author={Arabzadeh, Negar and Huo, Siging and Mehta, Nikhil and Wu, Qinqyun and Wang, Chi and Awadallah, Ahmed and Clarke, Charles LA and Kiseleva, Julia},
journal={arXiv preprint arXiv:2405.02178},
year={2024}
}