Tracing and Observability#
AutoGen has built-in support for tracing and observability for collecting comprehensive records on the execution of your application. This feature is useful for debugging, performance analysis, and understanding the flow of your application.
This capability is powered by the OpenTelemetry library, which means you can use any OpenTelemetry-compatible backend to collect and analyze traces.
AutoGen follows the OpenTelemetry Semantic Conventions for tracing, for agents and tools. It also follows the Semantic Conventions for GenAI Systems currently under development.
Setup#
To begin, you need to install the OpenTelemetry Python package. You can do this using pip:
pip install opentelemetry-sdk opentelemetry-exporter-otlp-proto-grpc opentelemetry-instrumentation-openai
Once you have the SDK installed, the simplest way to set up tracing in AutoGen is to:
Configure an OpenTelemetry tracer provider
Set up an exporter to send traces to your backend
Connect the tracer provider to the AutoGen runtime
Telemetry Backend#
To collect and view traces, you need to set up a telemetry backend. Several open-source options are available, including Jaeger, Zipkin. For this example, we will use Jaeger as our telemetry backend.
For a quick start, you can run Jaeger locally using Docker:
docker run -d --name jaeger \
-e COLLECTOR_OTLP_ENABLED=true \
-p 16686:16686 \
-p 4317:4317 \
-p 4318:4318 \
jaegertracing/all-in-one:latest
This command starts a Jaeger instance that listens on port 16686 for the Jaeger UI and port 4317 for the OpenTelemetry collector. You can access the Jaeger UI at http://localhost:16686.
Tracing an AgentChat Team#
In the following section, we will review how to enable tracing with an AutoGen GroupChat team. The AutoGen runtime already supports open telemetry (automatically logging message metadata). To begin, we will create a tracing service that will be used to instrument the AutoGen runtime.
from opentelemetry import trace
from opentelemetry.exporter.otlp.proto.grpc.trace_exporter import OTLPSpanExporter
from opentelemetry.instrumentation.openai import OpenAIInstrumentor
from opentelemetry.sdk.resources import Resource
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
# Set up telemetry span exporter.
otel_exporter = OTLPSpanExporter(endpoint="http://localhost:4317", insecure=True)
span_processor = BatchSpanProcessor(otel_exporter)
# Set up telemetry trace provider.
tracer_provider = TracerProvider(resource=Resource({"service.name": "autogen-test-agentchat"}))
tracer_provider.add_span_processor(span_processor)
trace.set_tracer_provider(tracer_provider)
# Instrument the OpenAI Python library
OpenAIInstrumentor().instrument()
# we will get reference this tracer later using its service name
# tracer = trace.get_tracer("autogen-test-agentchat")
Overriding of current TracerProvider is not allowed
Attempting to instrument while already instrumented
All of the code to create a team should already be familiar to you.
Note
AgentChat teams are run using the AutoGen Core’s agent runtime.
In turn, the runtime is already instrumented to log, see Core Telemetry Guide.
To disable the agent runtime telemetry, you can set the trace_provider to
opentelemetry.trace.NoOpTracerProvider in the runtime constructor.
Additionally, you can set the environment variable AUTOGEN_DISABLE_RUNTIME_TRACING to true to disable the agent runtime telemetry if you don’t have access to the runtime constructor. For example, if you are using ComponentConfig.
from autogen_agentchat.agents import AssistantAgent
from autogen_agentchat.conditions import MaxMessageTermination, TextMentionTermination
from autogen_agentchat.teams import SelectorGroupChat
from autogen_agentchat.ui import Console
from autogen_core import SingleThreadedAgentRuntime
from autogen_ext.models.openai import OpenAIChatCompletionClient
def search_web_tool(query: str) -> str:
if "2006-2007" in query:
return """Here are the total points scored by Miami Heat players in the 2006-2007 season:
Udonis Haslem: 844 points
Dwayne Wade: 1397 points
James Posey: 550 points
...
"""
elif "2007-2008" in query:
return "The number of total rebounds for Dwayne Wade in the Miami Heat season 2007-2008 is 214."
elif "2008-2009" in query:
return "The number of total rebounds for Dwayne Wade in the Miami Heat season 2008-2009 is 398."
return "No data found."
def percentage_change_tool(start: float, end: float) -> float:
return ((end - start) / start) * 100
async def main() -> None:
model_client = OpenAIChatCompletionClient(model="gpt-4o")
# Get a tracer with the default tracer provider.
tracer = trace.get_tracer("tracing-autogen-agentchat")
# Use the tracer to create a span for the main function.
with tracer.start_as_current_span("run_team"):
planning_agent = AssistantAgent(
"PlanningAgent",
description="An agent for planning tasks, this agent should be the first to engage when given a new task.",
model_client=model_client,
system_message="""
You are a planning agent.
Your job is to break down complex tasks into smaller, manageable subtasks.
Your team members are:
WebSearchAgent: Searches for information
DataAnalystAgent: Performs calculations
You only plan and delegate tasks - you do not execute them yourself.
When assigning tasks, use this format:
1. <agent> : <task>
After all tasks are complete, summarize the findings and end with "TERMINATE".
""",
)
web_search_agent = AssistantAgent(
"WebSearchAgent",
description="An agent for searching information on the web.",
tools=[search_web_tool],
model_client=model_client,
system_message="""
You are a web search agent.
Your only tool is search_tool - use it to find information.
You make only one search call at a time.
Once you have the results, you never do calculations based on them.
""",
)
data_analyst_agent = AssistantAgent(
"DataAnalystAgent",
description="An agent for performing calculations.",
model_client=model_client,
tools=[percentage_change_tool],
system_message="""
You are a data analyst.
Given the tasks you have been assigned, you should analyze the data and provide results using the tools provided.
If you have not seen the data, ask for it.
""",
)
text_mention_termination = TextMentionTermination("TERMINATE")
max_messages_termination = MaxMessageTermination(max_messages=25)
termination = text_mention_termination | max_messages_termination
selector_prompt = """Select an agent to perform task.
{roles}
Current conversation context:
{history}
Read the above conversation, then select an agent from {participants} to perform the next task.
Make sure the planner agent has assigned tasks before other agents start working.
Only select one agent.
"""
task = "Who was the Miami Heat player with the highest points in the 2006-2007 season, and what was the percentage change in his total rebounds between the 2007-2008 and 2008-2009 seasons?"
runtime = SingleThreadedAgentRuntime(
tracer_provider=trace.NoOpTracerProvider(), # Disable telemetry for runtime.
)
runtime.start()
team = SelectorGroupChat(
[planning_agent, web_search_agent, data_analyst_agent],
model_client=model_client,
termination_condition=termination,
selector_prompt=selector_prompt,
allow_repeated_speaker=True,
runtime=runtime,
)
await Console(team.run_stream(task=task))
await runtime.stop()
await model_client.close()
# asyncio.run(main())
await main()
---------- TextMessage (user) ----------
Who was the Miami Heat player with the highest points in the 2006-2007 season, and what was the percentage change in his total rebounds between the 2007-2008 and 2008-2009 seasons?
---------- TextMessage (PlanningAgent) ----------
To find the information requested, we need to follow these steps:
1. Identify the Miami Heat player with the highest points during the 2006-2007 season.
2. Get the total rebounds for that player in both the 2007-2008 and 2008-2009 seasons.
3. Calculate the percentage change in total rebounds between these two seasons.
Here are the tasks assigned to achieve this:
1. WebSearchAgent: Find the Miami Heat player with the highest points during the 2006-2007 season.
2. WebSearchAgent: After identifying the player, find the total rebounds for that player in the 2007-2008 and 2008-2009 seasons.
3. DataAnalystAgent: Calculate the percentage change in the player's total rebounds between the 2007-2008 and 2008-2009 seasons.
---------- ToolCallRequestEvent (WebSearchAgent) ----------
[FunctionCall(id='call_hS8yod9l6CYUllDveUffp58e', arguments='{"query":"Miami Heat leading scorer 2006-2007 season"}', name='search_web_tool')]
---------- ToolCallExecutionEvent (WebSearchAgent) ----------
[FunctionExecutionResult(content='Here are the total points scored by Miami Heat players in the 2006-2007 season:\n Udonis Haslem: 844 points\n Dwayne Wade: 1397 points\n James Posey: 550 points\n ...\n ', name='search_web_tool', call_id='call_hS8yod9l6CYUllDveUffp58e', is_error=False)]
---------- ToolCallSummaryMessage (WebSearchAgent) ----------
Here are the total points scored by Miami Heat players in the 2006-2007 season:
Udonis Haslem: 844 points
Dwayne Wade: 1397 points
James Posey: 550 points
...
---------- ToolCallRequestEvent (WebSearchAgent) ----------
[FunctionCall(id='call_bUJxtpxUXFSxECDogye9WL0g', arguments='{"query":"Dwyane Wade total rebounds in 2007-2008 season"}', name='search_web_tool')]
---------- ToolCallExecutionEvent (WebSearchAgent) ----------
[FunctionExecutionResult(content='The number of total rebounds for Dwayne Wade in the Miami Heat season 2007-2008 is 214.', name='search_web_tool', call_id='call_bUJxtpxUXFSxECDogye9WL0g', is_error=False)]
---------- ToolCallSummaryMessage (WebSearchAgent) ----------
The number of total rebounds for Dwayne Wade in the Miami Heat season 2007-2008 is 214.
---------- ToolCallRequestEvent (WebSearchAgent) ----------
[FunctionCall(id='call_pgYNSDhhyodtteot56FRktxp', arguments='{"query":"Dwyane Wade total rebounds in 2008-2009 season"}', name='search_web_tool')]
---------- ToolCallExecutionEvent (WebSearchAgent) ----------
[FunctionExecutionResult(content='The number of total rebounds for Dwayne Wade in the Miami Heat season 2008-2009 is 398.', name='search_web_tool', call_id='call_pgYNSDhhyodtteot56FRktxp', is_error=False)]
---------- ToolCallSummaryMessage (WebSearchAgent) ----------
The number of total rebounds for Dwayne Wade in the Miami Heat season 2008-2009 is 398.
---------- ToolCallRequestEvent (DataAnalystAgent) ----------
[FunctionCall(id='call_A89acjYHlNDLzG09rVNJ0J6H', arguments='{"start":214,"end":398}', name='percentage_change_tool')]
---------- ToolCallExecutionEvent (DataAnalystAgent) ----------
[FunctionExecutionResult(content='85.98130841121495', name='percentage_change_tool', call_id='call_A89acjYHlNDLzG09rVNJ0J6H', is_error=False)]
---------- ToolCallSummaryMessage (DataAnalystAgent) ----------
85.98130841121495
---------- TextMessage (PlanningAgent) ----------
The Miami Heat player with the highest points during the 2006-2007 season was Dwyane Wade, who scored 1,397 points.
The total rebounds for Dwyane Wade in the 2007-2008 season were 214, and in the 2008-2009 season, they were 398.
The percentage change in his total rebounds between these two seasons is approximately 86.0%.
TERMINATE
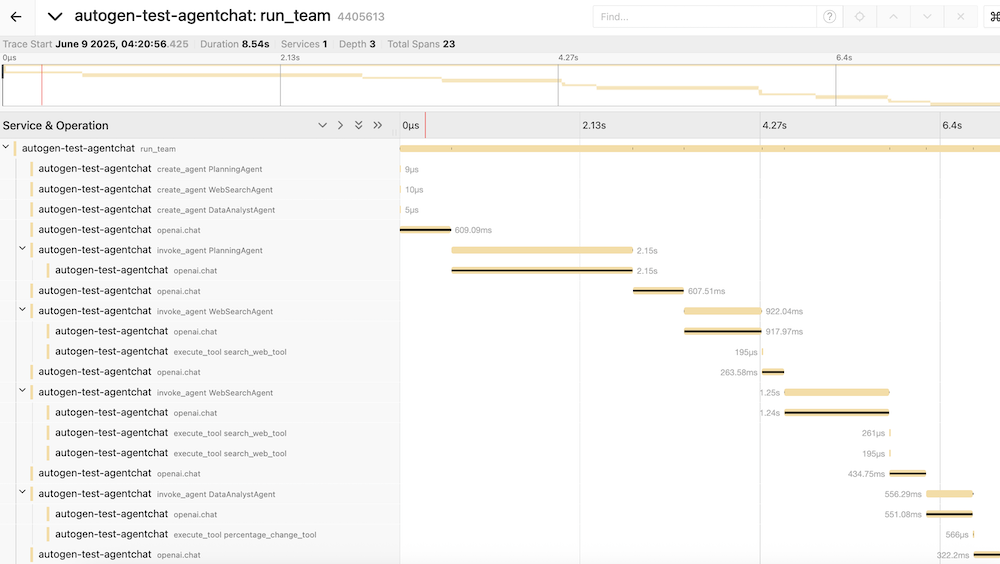
You can then use the Jaeger UI to view the traces collected from the application run above.