# Copyright (c) 2025 Microsoft Corporation.
import sys
sys.path.insert(1, "../../../")
%load_ext dotenv
%dotenv
import asyncio
import json
import logging
import os
import pandas as pd
import tiktoken
from pydantic import SecretStr
from benchmark_qed.autod.data_processor.embedding import TextEmbedder
from benchmark_qed.autod.io.text_unit import load_text_units
from benchmark_qed.autoq.io.activity import (
save_activity_context,
)
from benchmark_qed.autoq.io.question import (
load_questions,
save_questions,
)
from benchmark_qed.config.llm_config import LLMConfig, LLMProvider
from benchmark_qed.llm.factory import ModelFactory
logging.basicConfig(level=logging.INFO)
if logging.getLogger("httpx") is not None:
logging.getLogger("httpx").setLevel(logging.ERROR)
AutoQ¶
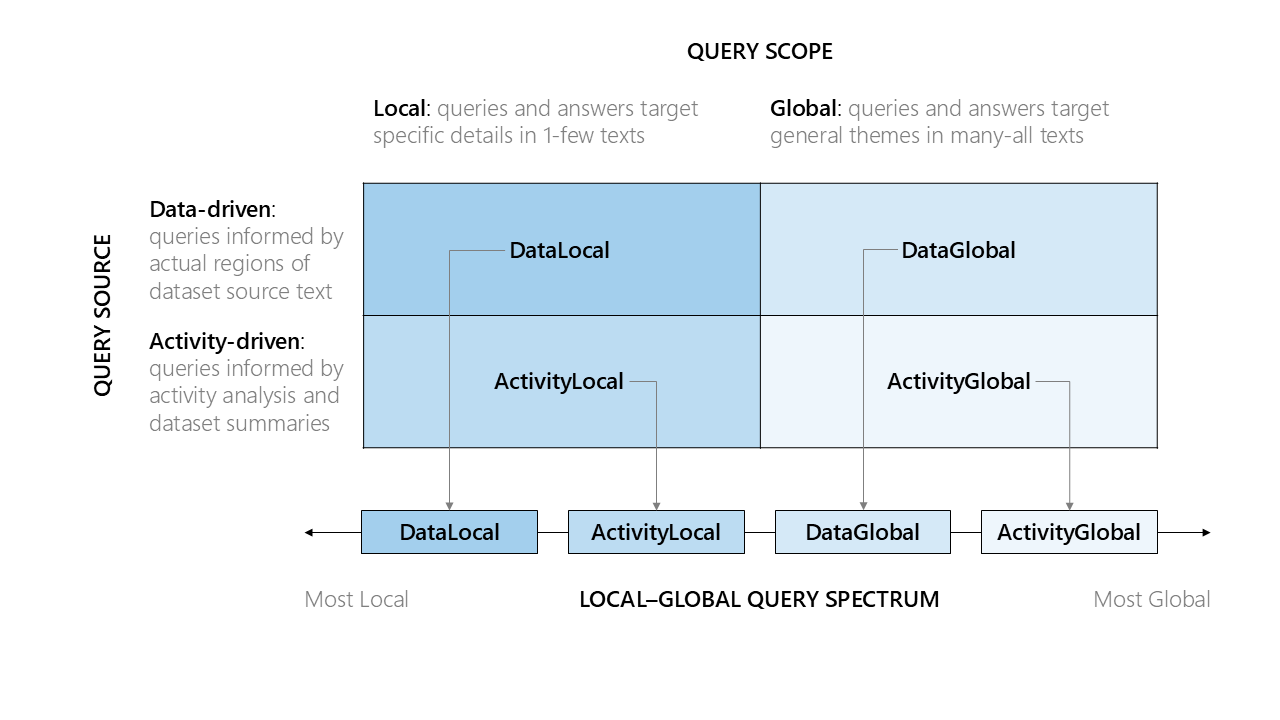
AutoQ is an automated approach to question generation that supports the following typology of information-seeking questions:
- Question Scope: the extent of the dataset that the question addresses
- Local questions targeting specific details of a text corpus
- Global questions targeting general aspects of a text corpus (e.g., themes, concerns, opportunities)
- Question Source: the information used to generate local and global questions
- Data-driven questions based on text sampled from the overall corpus
- Activity-driven questions based on potential activities consistent with the data
This typology gives four major question types, generated using LLM-based methods. In addition, data-linked questions are a variant of data-driven local questions that combine multiple local questions sharing named entities into multi-hop questions. The question generation process generally consists of 2 main steps:
- Candidate Generation: Use an LLM model to generate a large pool of candidate questions, typically oversampled (based on a specified oversample factor) to ensure sufficient variety for downstream selection.
- Ranking and Selection: The candidate questions are clustered, ranked, and filtered using various metrics to select the final set of target questions.
Below is a more detailed description of the question generation method for each question class:
- Data-driven local questions
- Sample texts are extracted from the input text corpus, with target text regions selected
- Candidate local questions are generated for each target text region using a two-step (extract+expand) process
- Candidate questions are clustered and ranked using semantic similarity-based metrics to select a smaller subset of best questions.
- Relevant claims are extracted for each question based on the sources texts in the corresponding text region
- (Optional): assertions are generated for each question based on the extracted claims. These assertions can then be used to evaluate assertion-based accuracy of RAG methods.
- Any abstract categories (e.g., themes) reflected by the sample text are captured
- Data-linked local questions (multi-hop variant of data-driven local)
- Local questions are grouped by shared named entities
- Candidate multi-hop questions are generated for each entity group, covering bridge, comparison, intersection, and temporal question types
- Candidate questions are validated using batch quality checks to filter low-quality outputs
- Questions are selected using MMR sampling with type-balance to ensure diversity across question types
- (Optional): assertions are generated for each selected question based on claims from the linked source texts
- Data-driven global questions
- For each abstract category with 2+ local questions, generate a global question
- Relevant claims are extracted for each global question by aggregating relevant claims from the referenced local questions.
- Candidate questions are clustered and ranked using counts of extracted claims' references and input local questions to select a smaller subset of best questions.
- (Optional): assertions are generated for each selected question based on the extracted claims. These assertions can then be used to evaluate assertion-based accuracy of RAG methods.
- Activity-driven local questions
- A dataset summary is generated from the sample texts using AutoD
- A set of {persona, task, relevant entities} is generated based on the dataset summary and sample texts
- Candidate local questions are generated for each {persona, task, entities} combination
- Candidate questions are clustered and ranked using entity similarity metrics to select a smaller subset of best questions.
- Activity-driven global questions
- Generate candidate global questions for each {dataset, persona, task} combination
- Candidate global questions are clustered and ranked using a similarity-based metric to select a smaller subset of representative questions.
Configs¶
# DATA CONFIGS
INPUT_DATA_PATH = "../../datasets/AP_news/raw_data"
OUTPUT_DATA_PATH = "../../output/AP_news/processed_data"
OUTPUT_QUESTIONS_PATH = "../../output/AP_news/questions"
TEXT_COLUMN = "body_nitf"
METADATA_COLUMNS = ["headline", "firstcreated"]
FILE_ENCODING = "utf-8-sig"
# tokenizer used for chunking documents into text units
ENCODING_MODEL = "o200k_base"
CHUNK_SIZE = 600
CHUNK_OVERLAP = 100
# DATA SAMPLING CONFIGS
# These configs control the breadth and depth of the selected data sample.
# Adjust these parameters based on your data size and the number of questions to be generated (e.g. try increasing number of clusters if you want to generate more diverse questions)
# The final sample size will be NUM_CLUSTERS * NUM_SAMPLES_PER_CLUSTER
NUM_CLUSTERS = 20
NUM_SAMPLES_PER_CLUSTER = 10
RANDOM_SEED = 42
# GENERAL QUESTION GENERATION CONFIGS
# Number of questions to generate for each question class. You can also specify a different number of questions for each class.
NUM_QUESTIONS = 10
# Factor by which to overgenerate candidate questions (you can specify a different factor for each question class). These candidate questions will be ranked and filtered using a question sampler to select the final questions.
OVERSAMPLE_FACTOR = 2.0
# CONFIGS SPECIFIC TO ACTIVITY QUESTIONS
# these configs should be adjusted based on the number of questions to be generated. Try increasing these configs if you want to generate more questions.
NUM_PERSONAS = 5
NUM_TASKS_PER_PERSONA = 2
NUM_ENTITIES_PER_TASK = 5
# MODEL CONFIGS
API_KEY = SecretStr(os.getenv("OPENAI_API_KEY", ""))
EMBEDDING_MODEL = "text-embedding-3-large"
LLM_MODEL = "gpt-4.1"
LLM_PARAMS = {
"temperature": 0.0,
"seed": 42,
} # adjust this based on your model. For example, some reasoning models do not support temperature settings
CONCURRENT_REQUESTS = (
8 # Control for request concurrency. Adjust this based on your model capacity.
)
# ASSERTION GENERATION CONFIGS
MAX_ASSERTIONS = 20 # Maximum number of assertions per question (set to 0 to disable)
ENABLE_VALIDATION = True # Set to True to validate assertions against sources
MIN_VALIDATION_SCORE = 3 # Minimum score (1-5) for grounding, relevance, verifiability
# Global assertion generation configs (map-reduce with semantic grouping)
BATCH_SIZE = 100 # Batch size for processing claims when semantic grouping is disabled
MAP_DATA_TOKENS = 8000 # Maximum tokens per cluster in the map step
REDUCE_DATA_TOKENS = 32000 # Maximum input data tokens for the reduce step
ENABLE_SEMANTIC_GROUPING = True # Group similar claims using embeddings before map step
VALIDATE_MAP_ASSERTIONS = True # Validate assertions in the map step (filters early)
VALIDATE_REDUCE_ASSERTIONS = True # Validate assertions after reduce step
# Parallelism for assertion generation (adjust based on your model rate limits)
CONCURRENT_LOCAL_QUESTIONS = 8 # Questions to process in parallel for local assertions
CONCURRENT_GLOBAL_QUESTIONS = 2 # Questions to process in parallel for global assertions (lower due to internal parallelism, set to 1 for sequential)
text_embedder = TextEmbedder(
ModelFactory.create_embedding_model(
LLMConfig(
model=EMBEDDING_MODEL,
api_key=API_KEY,
llm_provider=LLMProvider.OpenAIEmbedding,
)
)
)
llm = ModelFactory.create_chat_model(
model_config=LLMConfig(
model=LLM_MODEL,
api_key=API_KEY,
llm_provider=LLMProvider.OpenAIChat,
call_args=LLM_PARAMS,
)
)
token_encoder = tiktoken.get_encoding(ENCODING_MODEL)
Data Sampling¶
In this step, we load documents from the input folders, chunk them into text units, and embed all text units. We then sample a subset of text units using the specified number of clusters and number of samples for each cluster. These clustered sample texts will be used to ground the question generation process.
from benchmark_qed.autod.sampler.sample_gen import acreate_clustered_sample
clustered_sample = asyncio.run(
acreate_clustered_sample(
input_path=INPUT_DATA_PATH,
output_path=OUTPUT_DATA_PATH,
text_embedder=text_embedder,
num_clusters=NUM_CLUSTERS,
num_samples_per_cluster=NUM_SAMPLES_PER_CLUSTER,
input_type="json",
text_tag=TEXT_COLUMN,
metadata_tags=METADATA_COLUMNS,
chunk_size=CHUNK_SIZE,
chunk_overlap=CHUNK_OVERLAP,
file_encoding=FILE_ENCODING,
token_encoding=ENCODING_MODEL,
random_seed=RANDOM_SEED,
)
)
print(
f"Sampled {len(clustered_sample.sample_texts)} samples from {len(clustered_sample.text_units)} text units in {len(clustered_sample.documents)} documents."
)
Data-Local Questions¶
from graphrag_storage.file_storage import FileStorage
from benchmark_qed.autoq.config import (
AssertionConfig,
GlobalAssertionConfig,
LinkedAssertionConfig,
LocalAssertionConfig,
)
from benchmark_qed.autoq.question_gen.data_questions.local_question_gen import (
DataLocalQuestionGen,
)
# load clustered text sample (result from the data sampling step)
# If you have previously run the data sampling step, you can load the sample from disk instead of re-running the data sampling step as the below example.
# Otherwise, you can use clustered_sample.sample_texts directly
sample_texts_df = pd.read_parquet(f"{OUTPUT_DATA_PATH}/sample_texts.parquet")
sample_texts = load_text_units(df=sample_texts_df)
# Configure assertion generation using the assertion generation configs
# Set max_assertions to an integer to limit assertions, 0 to disable, None for unlimited
# Set enable_validation=True to validate assertions against source text
local_assertion_config = LocalAssertionConfig(
max_assertions=MAX_ASSERTIONS,
enable_validation=ENABLE_VALIDATION,
min_validation_score=MIN_VALIDATION_SCORE,
concurrent_llm_calls=CONCURRENT_REQUESTS,
max_concurrent_questions=CONCURRENT_LOCAL_QUESTIONS,
)
global_assertion_config = GlobalAssertionConfig(
max_assertions=MAX_ASSERTIONS,
enable_validation=ENABLE_VALIDATION,
min_validation_score=MIN_VALIDATION_SCORE,
batch_size=BATCH_SIZE,
map_data_tokens=MAP_DATA_TOKENS,
reduce_data_tokens=REDUCE_DATA_TOKENS,
enable_semantic_grouping=ENABLE_SEMANTIC_GROUPING,
validate_map_assertions=VALIDATE_MAP_ASSERTIONS,
validate_reduce_assertions=VALIDATE_REDUCE_ASSERTIONS,
concurrent_llm_calls=CONCURRENT_REQUESTS,
max_concurrent_questions=CONCURRENT_GLOBAL_QUESTIONS,
)
linked_assertion_config = LinkedAssertionConfig(
max_assertions=MAX_ASSERTIONS,
enable_validation=ENABLE_VALIDATION,
min_validation_score=MIN_VALIDATION_SCORE,
concurrent_llm_calls=CONCURRENT_REQUESTS,
max_concurrent_questions=CONCURRENT_LOCAL_QUESTIONS, # Linked questions use local-style concurrency
)
assertion_config = AssertionConfig(
local=local_assertion_config,
linked=linked_assertion_config,
**{
"global": global_assertion_config
}, # Use dict unpacking since "global" is a keyword
)
data_local_generator = DataLocalQuestionGen(
llm=llm,
llm_params=LLM_PARAMS,
text_embedder=text_embedder,
text_units=sample_texts,
concurrent_coroutines=CONCURRENT_REQUESTS,
random_seed=RANDOM_SEED,
assertion_config=assertion_config,
)
data_local_question_results = asyncio.run(
data_local_generator.agenerate(
num_questions=NUM_QUESTIONS,
oversample_factor=OVERSAMPLE_FACTOR,
)
)
data_local_storage = FileStorage(f"{OUTPUT_QUESTIONS_PATH}/data_local_questions/")
# save both candidate questions and the final selected questions
asyncio.run(
save_questions(
data_local_question_results.selected_questions,
data_local_storage,
"selected_questions",
)
)
asyncio.run(
save_questions(
data_local_question_results.selected_questions,
data_local_storage,
"selected_questions_text",
question_text_only=True,
)
)
asyncio.run(
save_questions(
data_local_question_results.candidate_questions,
data_local_storage,
"candidate_questions",
)
)
Data Global Questions¶
from benchmark_qed.autoq.question_gen.data_questions.global_question_gen import (
DataGlobalQuestionGen,
)
# Load candidate questions (result from the data local question generation step)
# Please note that we load all the candidate local questions (not just the selected ones) as that gives us a bigger pool of local questions to aggregate from.
# If you have previously run the data local question generation step, you can load the candidate questions from disk instead of re-running the data local question generation step as the below example.
# Otherwise, you can use data_local_question_results.candidate_questions directly
local_questions = asyncio.run(
load_questions(
data_local_storage,
"candidate_questions.json",
)
)
print(f"Loaded {len(local_questions)} candidate local questions.")
# Reuse the same assertion config from data local questions
data_global_generator = DataGlobalQuestionGen(
llm=llm,
llm_params=LLM_PARAMS,
text_embedder=text_embedder,
local_questions=local_questions,
concurrent_coroutines=CONCURRENT_REQUESTS,
random_seed=RANDOM_SEED,
assertion_config=assertion_config,
)
data_global_question_results = asyncio.run(
data_global_generator.agenerate(
num_questions=NUM_QUESTIONS,
oversample_factor=OVERSAMPLE_FACTOR,
)
)
data_global_storage = FileStorage(f"{OUTPUT_QUESTIONS_PATH}/data_global_questions/")
# save both candidate questions and the final selected questions
asyncio.run(
save_questions(
data_global_question_results.selected_questions,
data_global_storage,
"selected_questions",
)
)
asyncio.run(
save_questions(
data_global_question_results.selected_questions,
data_global_storage,
"selected_questions_text",
question_text_only=True,
)
)
asyncio.run(
save_questions(
data_global_question_results.candidate_questions,
data_global_storage,
"candidate_questions",
)
)
Data-Linked Questions¶
Data-linked questions are multi-hop style local questions generated by combining local questions that share named entities. These questions require combining information from a small set of text chunks—less localized than data-local questions (which target a single text region), but still local-scoped since the number of related chunks remains small.
The pipeline:
- Entity Grouping: Group local questions by shared named entities
- Question Generation: Generate questions of different types (bridge, comparison, intersection, temporal)
- Validation: Run batch validation to filter low-quality questions
- Selection: Use MMR sampling with type-balance to select diverse, high-quality questions
- Assertion Generation (optional): Generate assertions for each selected question
Question Types¶
- Bridge: Questions that require connecting information from multiple sources
- Comparison: Questions comparing attributes, outcomes, or characteristics
- Intersection: Questions about common elements or shared properties
- Temporal: Questions about timing, sequence, or chronology of events
# Data-Linked Question Generation Configuration
# These configs control the linked question generation process
# Linked question generation specific configs
LINKED_QUESTION_TYPES = [
"bridge",
"comparison",
"intersection",
"temporal",
] # Question types to generate
LINKED_MIN_QUESTIONS_PER_ENTITY = (
2 # Minimum local questions per entity to form a linked group
)
LINKED_MAX_QUESTIONS_PER_ENTITY = 10 # Maximum local questions per entity
LINKED_MIN_QUALITY_SCORE = 4 # Minimum quality score (1-5) for generated questions
LINKED_ENABLE_BATCH_VALIDATION = True # Enable batch validation to filter bad questions
LINKED_MMR_LAMBDA = 0.7 # MMR trade-off: 0=max diversity, 1=max quality
LINKED_TYPE_BALANCE_WEIGHT = (
0.5 # Type-balance penalty in MMR (0=ignore, 1=strong penalty)
)
LINKED_OVERSAMPLE_FACTOR = (
10.0 # Higher oversample for linked questions due to validation filtering
)
print("Linked question generation configured:")
print(f" Question types: {LINKED_QUESTION_TYPES}")
print(f" Min questions per entity: {LINKED_MIN_QUESTIONS_PER_ENTITY}")
print(f" Type balance weight: {LINKED_TYPE_BALANCE_WEIGHT}")
print(f" Batch validation enabled: {LINKED_ENABLE_BATCH_VALIDATION}")
print(f" Oversample factor: {LINKED_OVERSAMPLE_FACTOR}")
print(
f" Assertion config (linked): max_assertions={assertion_config.linked.max_assertions}, validation={assertion_config.linked.enable_validation}"
)
from benchmark_qed.autoq.question_gen.data_questions.linked_question_gen import (
DataLinkedQuestionGen,
)
# Load candidate local questions (result from the data local question generation step)
# Linked questions are generated from local questions that share named entities.
# We use candidate local questions to have a larger pool for entity linking.
local_questions = asyncio.run(
load_questions(data_local_storage, "candidate_questions.json")
)
print(
f"Loaded {len(local_questions)} candidate local questions for linked question generation."
)
# Create the linked question generator
data_linked_generator = DataLinkedQuestionGen(
llm=llm,
text_embedder=text_embedder,
local_questions=local_questions,
token_encoder=token_encoder,
assertion_config=assertion_config,
llm_params=LLM_PARAMS,
concurrent_coroutines=CONCURRENT_REQUESTS,
random_seed=RANDOM_SEED,
# Linked-specific parameters
min_questions_per_entity=LINKED_MIN_QUESTIONS_PER_ENTITY,
max_questions_per_entity=LINKED_MAX_QUESTIONS_PER_ENTITY,
min_quality_score=LINKED_MIN_QUALITY_SCORE,
question_types=LINKED_QUESTION_TYPES,
enable_batch_validation=LINKED_ENABLE_BATCH_VALIDATION,
mmr_lambda=LINKED_MMR_LAMBDA,
type_balance_weight=LINKED_TYPE_BALANCE_WEIGHT,
)
# Generate linked questions (using higher oversample factor due to validation filtering)
data_linked_question_results = asyncio.run(
data_linked_generator.agenerate(
num_questions=NUM_QUESTIONS,
oversample_factor=LINKED_OVERSAMPLE_FACTOR,
)
)
data_linked_storage = FileStorage(f"{OUTPUT_QUESTIONS_PATH}/data_linked_questions/")
# Save both candidate questions and the final selected questions
asyncio.run(
save_questions(
data_linked_question_results.selected_questions,
data_linked_storage,
"selected_questions",
)
)
asyncio.run(
save_questions(
data_linked_question_results.selected_questions,
data_linked_storage,
"selected_questions_text",
question_text_only=True,
)
)
asyncio.run(
save_questions(
data_linked_question_results.candidate_questions,
data_linked_storage,
"candidate_questions",
)
)
print(
f"\nGenerated {len(data_linked_question_results.selected_questions)} linked questions"
)
print(f" (from {len(data_linked_question_results.candidate_questions)} candidates)")
Activity Questions¶
Generate Activity Context¶
Generate personas, their associated tasks, and relevant entities used to ground the activity-based question generation process
from benchmark_qed.autoq.question_gen.activity_questions.context_gen.activity_context_gen import (
ActivityContextGen,
)
# load clustered text sample (result from the data sampling step)
# If you have previously run the data sampling step, you can load the sample from disk instead of re-running the data sampling step as the below example.
# Otherwise, you can use clustered_sample.sample_texts directly
sample_texts_df = pd.read_parquet(f"{OUTPUT_DATA_PATH}/sample_texts.parquet")
sample_texts = load_text_units(
df=sample_texts_df, attributes_cols=["is_representative"]
)
activity_generator = ActivityContextGen(
llm=llm,
llm_params=LLM_PARAMS,
text_embedder=text_embedder,
token_encoder=token_encoder,
text_units=sample_texts,
concurrent_coroutines=CONCURRENT_REQUESTS,
)
activity_context = asyncio.run(
activity_generator.agenerate(
num_personas=NUM_PERSONAS,
num_tasks=NUM_TASKS_PER_PERSONA,
num_entities_per_task=NUM_ENTITIES_PER_TASK,
oversample_factor=OVERSAMPLE_FACTOR,
use_representative_samples_only=True, # if True, we will only use a subset of representative samples from the clustered texts to generate activity context (for efficiency). If False, we will use all the samples in the clustered texts.
)
)
activity_storage = FileStorage(f"{OUTPUT_QUESTIONS_PATH}/context/")
asyncio.run(save_activity_context(activity_context, activity_storage))
Generate Activity Local Questions¶
from pathlib import Path
from benchmark_qed.autoq.data_model.activity import ActivityContext
from benchmark_qed.autoq.question_gen.activity_questions.local_question_gen import (
ActivityLocalQuestionGen,
)
# load activity context (result from the activity context generation step)
# If you have previously run the activity context generation step, you can load the context from disk instead of re-running the activity context generation step as the below example.
activity_context = ActivityContext(
**json.loads(
Path(f"{OUTPUT_QUESTIONS_PATH}/context/activity_context_full.json").read_text()
)
)
print(f"Loaded {len(activity_context.task_contexts)} tasks.")
activity_local_generator = ActivityLocalQuestionGen(
llm=llm,
llm_params=LLM_PARAMS,
text_embedder=text_embedder,
activity_context=activity_context,
concurrent_coroutines=CONCURRENT_REQUESTS,
random_seed=RANDOM_SEED,
)
activity_local_question_results = asyncio.run(
activity_local_generator.agenerate(
num_questions=NUM_QUESTIONS,
oversample_factor=OVERSAMPLE_FACTOR,
)
)
activity_local_storage = FileStorage(
f"{OUTPUT_QUESTIONS_PATH}/activity_local_questions/"
)
# save both candidate questions and the final selected questions
asyncio.run(
save_questions(
activity_local_question_results.selected_questions,
activity_local_storage,
"selected_questions",
)
)
asyncio.run(
save_questions(
activity_local_question_results.selected_questions,
activity_local_storage,
"selected_questions_text",
question_text_only=True,
)
)
asyncio.run(
save_questions(
activity_local_question_results.candidate_questions,
activity_local_storage,
"candidate_questions",
)
)
Generate Activity Global Questions¶
from benchmark_qed.autoq.question_gen.activity_questions.global_question_gen import (
ActivityGlobalQuestionGen,
)
# load activity context (result from the activity context generation step)
# If you have previously run the activity context generation step, you can load the context from disk instead of re-running the activity context generation step as the below example.
activity_context = ActivityContext(
**json.loads(
Path(f"{OUTPUT_QUESTIONS_PATH}/context/activity_context_full.json").read_text()
)
)
print(f"Loaded {len(activity_context.task_contexts)} tasks.")
activity_global_generator = ActivityGlobalQuestionGen(
llm=llm,
llm_params=LLM_PARAMS,
text_embedder=text_embedder,
activity_context=activity_context,
concurrent_coroutines=CONCURRENT_REQUESTS,
random_seed=RANDOM_SEED,
)
activity_global_question_results = asyncio.run(
activity_global_generator.agenerate(
num_questions=NUM_QUESTIONS,
oversample_factor=OVERSAMPLE_FACTOR,
)
)
activity_global_storage = FileStorage(
f"{OUTPUT_QUESTIONS_PATH}/activity_global_questions/"
)
# save both candidate questions and the final selected questions
asyncio.run(
save_questions(
activity_global_question_results.selected_questions,
activity_global_storage,
"selected_questions",
)
)
asyncio.run(
save_questions(
activity_global_question_results.selected_questions,
activity_global_storage,
"selected_questions_text",
question_text_only=True,
)
)
asyncio.run(
save_questions(
activity_global_question_results.candidate_questions,
activity_global_storage,
"candidate_questions",
)
)