Object Detection
Frequently asked questions
This document tries to answer frequent questions related to object detection. For generic Machine Learning questions, such as “How many training examples do I need?” or “How to monitor GPU usage during training?” see also the image classification FAQ.
- General
- Data
- Technology
- Training
General
Why Torchvision?
Torchvision has a large active user-base and hence its object detection implementation is easy to use, well tested, and uses state-of-the-art technology which has proven itself in the community. For these reasons we decided to use Torchvision as our object detection library. For advanced users who want to experiment with the latest cutting-edge technology, we recommend to start with our Torchvision notebooks and then also to look into more researchy implementations such as the mmdetection repository.
Data
How to annotate images?
Annotated object locations are required to train and evaluate an object detector. One of the best open source UIs which runs on Windows and Linux is VOTT. Another good tool is LabelImg.
VOTT can be used to manually draw rectangles around one or more objects in an image. These annotations can then be exported in Pascal-VOC format (single xml-file per image) which the provided notebooks know how to read.
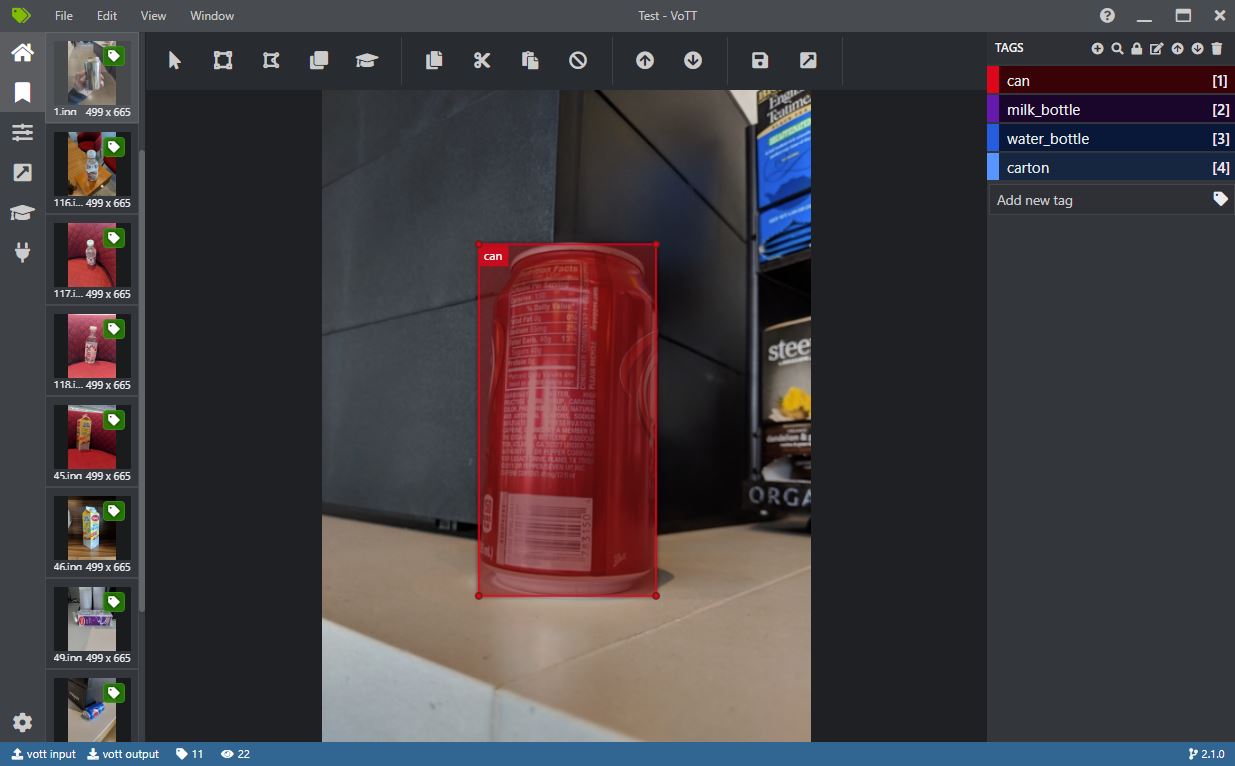
When creating a new project in VOTT, note that the “source connection” can simply point to a local folder which contains the images to be annotated, and respectively the “target connection” to a folder where to write the output. Pascal VOC style annotations can be exported by selecting “Pascal VOC” in the “Export Settings” tab and then using the “Export Project” button in the “Tags Editor” tab.
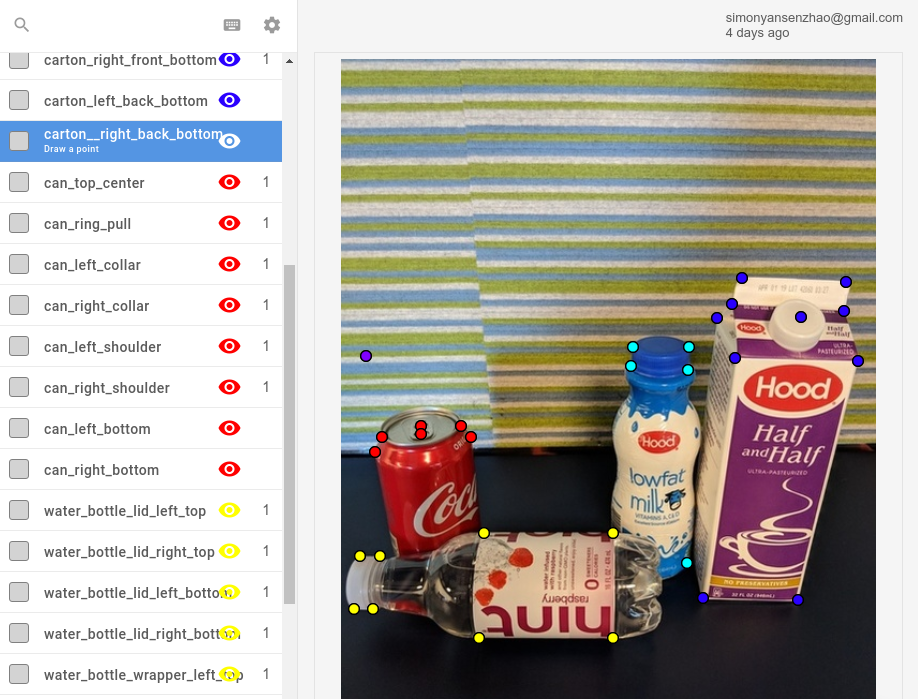
For mask (segmentation) annotation, an easy-to-use online tool is Labelbox, shown in the screenshot below. See the demo Introducing Image Segmentation at Labelbox on how to use the tool, and the 02_mask_rcnn notebook how to convert the Labelbox annotations to Pascal VOC format. Alternatives to Labelbox include CVAT or RectLabel (Mac only).

Besides drawing masks, Labelbox can also be used to annotate keypoints.
Selection and annotating images is complex and consistency is key. For example:
- All objects in an image need to be annotated, even if the image contains many of them. Consider removing the image if this would take too much time.
- Ambiguous images should be removed, for example if it is unclear to a human if an object is lemon or a tennis ball, or if the image is blurry, etc.
- Occluded objects should either be always annotated, or never.
- Ensuring consistency is difficult especially if multiple people are involved. Hence our recommendation is, if possible, that the person who trains the model annotates all images. This also helps in gaining a better understanding of the problem domain.
Especially the test set used for evaluation should be of high annotation quality so that accuracy measures reflect the true performance of the model. The training set can, but ideally shouldn’t be, noisy.
Technology
How does the technology work?
State-of-the-art object detection methods, such as used in this repository, are based on Convolutional Neural Networks (CNN) which have been shown to work well on image data. Most such methods use a CNN as backbone which was pre-trained on millions of images (typically using the ImageNet dataset). Such a pre-trained model is then incorporated into an object detection pipeline, and can be fine-tuned with only a small amount of annotated images. For a more detailed explanation of “fine-tuning”, including code examples, see the classification folder.
R-CNN Object Detection Approaches
R-CNNs for Object Detection were introduced in 2014 by Ross Girshick et al., and shown to outperform previous state-of-the-art approaches on one of the major object recognition challenges: Pascal VOC. The main drawback of the approach was its slow inference speed. Since then, three major follow-up papers were published which introduced significant speed improvements: Fast R-CNN and Faster R-CNN, and Mask R-CNN.
Similar to most object detection methods, R-CNN use a deep Neural Network which was trained for image classification using millions of annotated images and modify it for the purpose of object detection. The basic idea from the first R-CNN paper is illustrated in the figure below (taken from the paper):
- Given an input image
- A large number region proposals, aka Regions-of-Interests (ROIs), are generated.
- These ROIs are then independently sent through the network which outputs a vector of e.g. 4096 floating point values for each ROI.
- Finally, a classifier is learned which takes the 4096 floats ROI representation as input and outputs a label and confidence to each ROI.
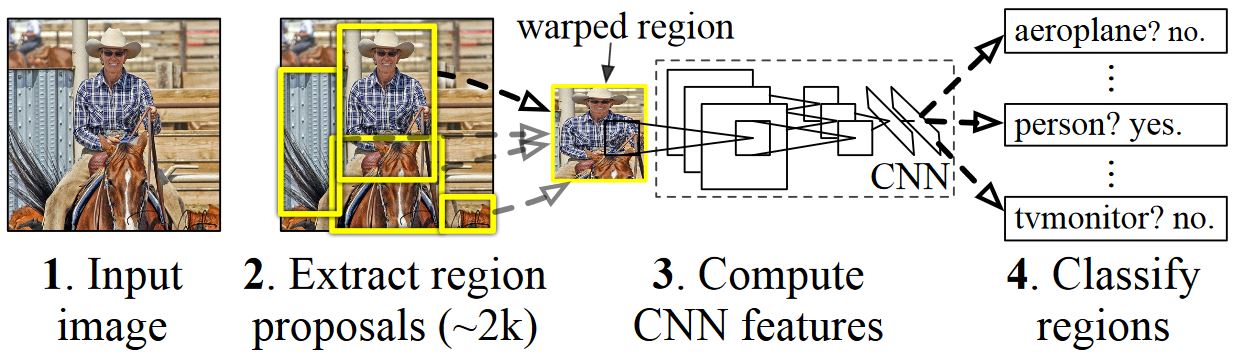
While this approach works well in terms of accuracy, it is very costly to compute since the Neural Network has to be evaluated for each ROI. Fast R-CNN addresses this drawback by only evaluating most of the network (to be specific: the convolution layers) a single time per image. According to the authors, this leads to a 213 times speed-up during testing and a 9x speed-up during training without loss of accuracy. Faster R-CNN then shows how ROIs can be computed as part of the network, essentially combining all steps in the figure above into a single DNN.
Intersection-over-Union overlap metric
It is often necessary to measure by how much two given rectangles overlap. For example, one rectangle might correspond to the ground-truth location of an object, while the second rectangle corresponds to the estimated location, and the goal is to measure how precise the object was detected.
For this, a metric called Intersection-over-Union (IoU) is typically used. In the example below, the IoU is given by dividing the yellow area by the combined yellow and blue areas. An IoU of 1.0 corresponds to a perfect match, while an IoU of 0 indicates that the two rectangles do not overlap. Typically an IoU of 0.5 is considered a good localization. See also this page for a more in-depth discussion.

Non-maxima suppression
Object detection methods often output multiple detections which fully or partly cover the same object in an image. These detections need to be pruned to be able to count objects and obtain their exact locations. This is traditionally done using a technique called Non-Maxima Suppression (NMS), and is implemented by iteratively selecting the detection with highest confidence and removing all other detections which (i) are classified to be of the same class; and (ii) have a significant overlap measured using the Intersection-over-Union (IOU) metric.
Detection results with confidence scores before (left) and after non-maxima Suppression using IOU thresholds of (middle) 0.8 and (right) 0.5:

Mean Average Precision
Once trained, the quality of the model can be measured using different criteria, such as precision, recall, accuracy, area-under-curve, etc. A common metric which is used for the Pascal VOC object recognition challenge is to measure the Average Precision (AP) for each class. Average Precision takes confidence in the detections into account and hence assigns a smaller penalty to false detections with low confidence. For a description of Average Precision see Everingham et. al. The mean Average Precision (mAP) is then computed by taking the average over all APs.
Training
How to improve accuracy?
One way to improve accuracy is by optimizing the model architecture or the training procedure. The following parameters tend to have the highest influence on accuracy:
- Image resolution: increase to e.g. 1200 pixels input resolution by setting
IM_SIZE = 1200. - Number of proposals: increase to e.g. these values:
rpn_pre_nms_top_n_train = rpn_post_nms_top_n_train = 10000andrpn_pre_nms_top_n_test = rpn_post_nms_top_n_test = 5000. - Learning rate and number of epochs: the respective default values specified e.g. in the 01 notebook should work well in most cases. However, one could try somewhat higher/smaller values for learning rate and epochs.
See also the image classification FAQ for more suggestions to improve model accuracy or to increase inference/training speed.