Continuous Markdown Translations
You may have noticed that the GenAIScript documentation is now available in French (try the upper-right language dropdown).
The translations are not just a one-time effort; they are continuously updated as the documentation evolves, in a GitHub Actions. This means that whenever new content is added or existing content is modified, the translations are automatically updated to reflect those changes.
In this post, we’ll go through some of the interesting parts of the script and how it works.
The challenge of translating documentation
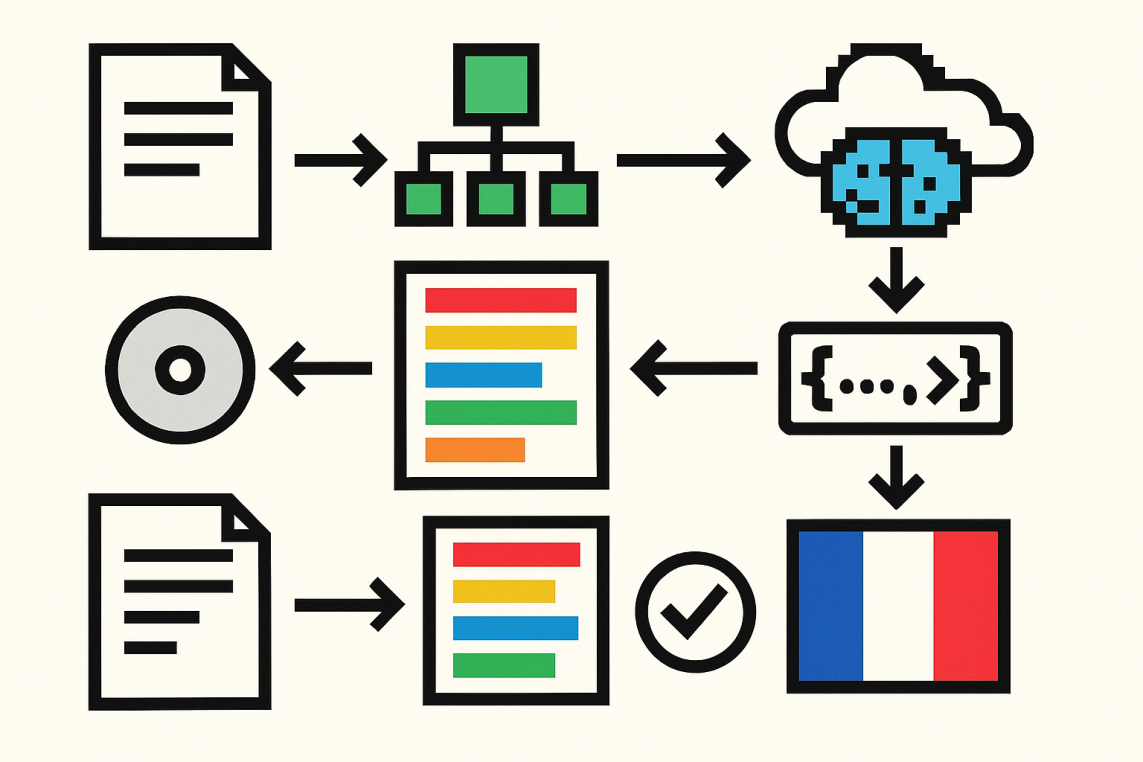
Section titled “The challenge of translating documentation”The goal of this challenge to maintain localized documentation, and automate the process using GenAIScript, GitHub Actions and GitHub Models. To be successful, we need:
- a model that can produce high quality translations (LLMs like
gpt-4oand larger have become quite good at it), - a iterative strategy to partially translate modified chunks in markdown file. We cannot just translate an entire file other the translations will be changing on every round.
- idempotency: if translations are already available, the results should be cached and the script should be a no-op.
- run automatically in a GitHub Action and use GitHub Models for inference.
Let’s get going! The translation functionality described in this blog post is now packaged as a reusable GitHub Action. If you want to read the original script code, here is the script.
Iterative Markdown Translations
Section titled “Iterative Markdown Translations”Since GenAISCript uses markdown for documentation, we’ll focus on this file format exclusively. GenAIScript also uses Astro Starlight which adds some well-known metadata in the frontmatter like title or description.
The core idea behind the translation scripts is the following:
- parse the markdown document into an AST (Abstract Syntax Tree)
- visit the tree and collect all the translatable text chunks (special care for paragraphs)
- replace all translatable chunks with a placeholder a
[T001]bla bla bla...[T002]and prompt the LLM to translate each chunk - parse the LLM answer, extract each chunk translation, and visit the tree again applying the translations
- judge the quality of the translation
- save the translations in a cache that they can be reused in a future run
%3btext-align:center%3b%7d%23mermaid-0 .edgeLabel p%7bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3b%7d%23mermaid-0 .edgeLabel rect%7bopacity:0.5%3bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3bfill:rgba(232%2c232%2c232%2c 0.8)%3b%7d%23mermaid-0 .labelBkg%7bbackground-color:rgba(232%2c 232%2c 232%2c 0.5)%3b%7d%23mermaid-0 .cluster rect%7bfill:%23ffffde%3bstroke:%23aaaa33%3bstroke-width:1px%3b%7d%23mermaid-0 .cluster text%7bfill:%23333%3b%7d%23mermaid-0 .cluster span%7bcolor:%23333%3b%7d%23mermaid-0 div.mermaidTooltip%7bposition:absolute%3btext-align:center%3bmax-width:200px%3bpadding:2px%3bfont-family:arial%2csans-serif%3bfont-size:12px%3bbackground:hsl(80%2c 100%25%2c 96.2745098039%25)%3bborder:1px solid %23aaaa33%3bborder-radius:2px%3bpointer-events:none%3bz-index:100%3b%7d%23mermaid-0 .flowchartTitleText%7btext-anchor:middle%3bfont-size:18px%3bfill:%23333%3b%7d%23mermaid-0 rect.text%7bfill:none%3bstroke-width:0%3b%7d%23mermaid-0 .icon-shape%2c%23mermaid-0 .image-shape%7bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3btext-align:center%3b%7d%23mermaid-0 .icon-shape p%2c%23mermaid-0 .image-shape p%7bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3bpadding:2px%3b%7d%23mermaid-0 .icon-shape rect%2c%23mermaid-0 .image-shape rect%7bopacity:0.5%3bbackground-color:rgba(232%2c232%2c232%2c 0.8)%3bfill:rgba(232%2c232%2c232%2c 0.8)%3b%7d%23mermaid-0 .label-icon%7bdisplay:inline-block%3bheight:1em%3boverflow:visible%3bvertical-align:-0.125em%3b%7d%23mermaid-0 .node .label-icon path%7bfill:currentColor%3bstroke:revert%3bstroke-width:revert%3b%7d%23mermaid-0 :root%7b--mermaid-font-family:arial%2csans-serif%3b%7d%3c/style%3e%3cg%3e%3cmarker orient='auto' markerHeight='8' markerWidth='8' markerUnits='userSpaceOnUse' refY='5' refX='5' viewBox='0 0 10 10' class='marker flowchart-v2' id='mermaid-0_flowchart-v2-pointEnd'%3e%3cpath style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 0 0 L 10 5 L 0 10 z'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='8' markerWidth='8' markerUnits='userSpaceOnUse' refY='5' refX='4.5' viewBox='0 0 10 10' class='marker flowchart-v2' id='mermaid-0_flowchart-v2-pointStart'%3e%3cpath style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 0 5 L 10 10 L 10 0 z'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5' refX='11' viewBox='0 0 10 10' class='marker flowchart-v2' id='mermaid-0_flowchart-v2-circleEnd'%3e%3ccircle style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' r='5' cy='5' cx='5'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5' refX='-1' viewBox='0 0 10 10' class='marker flowchart-v2' id='mermaid-0_flowchart-v2-circleStart'%3e%3ccircle style='stroke-width: 1%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' r='5' cy='5' cx='5'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5.2' refX='12' viewBox='0 0 11 11' class='marker cross flowchart-v2' id='mermaid-0_flowchart-v2-crossEnd'%3e%3cpath style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9'/%3e%3c/marker%3e%3cmarker orient='auto' markerHeight='11' markerWidth='11' markerUnits='userSpaceOnUse' refY='5.2' refX='-1' viewBox='0 0 11 11' class='marker cross flowchart-v2' id='mermaid-0_flowchart-v2-crossStart'%3e%3cpath style='stroke-width: 2%3b stroke-dasharray: 1%2c 0%3b' class='arrowMarkerPath' d='M 1%2c1 l 9%2c9 M 10%2c1 l -9%2c9'/%3e%3c/marker%3e%3cg class='root'%3e%3cg class='clusters'/%3e%3cg class='edgePaths'%3e%3cpath marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)' style='' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' id='L_A_B_0' d='M211.91%2c62L211.91%2c66.167C211.91%2c70.333%2c211.91%2c78.667%2c211.91%2c86.333C211.91%2c94%2c211.91%2c101%2c211.91%2c104.5L211.91%2c108'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)' style='' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' id='L_B_C_0' d='M170.56%2c166L164.179%2c170.167C157.798%2c174.333%2c145.036%2c182.667%2c138.655%2c190.333C132.273%2c198%2c132.273%2c205%2c132.273%2c208.5L132.273%2c212'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)' style='' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' id='L_C_D_0' d='M132.273%2c270L132.273%2c274.167C132.273%2c278.333%2c132.273%2c286.667%2c132.273%2c294.333C132.273%2c302%2c132.273%2c309%2c132.273%2c312.5L132.273%2c316'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)' style='' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' id='L_D_E_0' d='M132.273%2c374L132.273%2c378.167C132.273%2c382.333%2c132.273%2c390.667%2c138.096%2c398.636C143.919%2c406.604%2c155.565%2c414.209%2c161.388%2c418.011L167.211%2c421.813'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)' style='' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' id='L_E_J_0' d='M211.91%2c478L211.91%2c482.167C211.91%2c486.333%2c211.91%2c494.667%2c216.612%2c502.584C221.314%2c510.502%2c230.718%2c518.004%2c235.42%2c521.755L240.122%2c525.506'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)' style='' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' id='L_J_C_0' d='M323.636%2c528L330.818%2c523.833C338.001%2c519.667%2c352.366%2c511.333%2c359.548%2c498.5C366.73%2c485.667%2c366.73%2c468.333%2c366.73%2c451C366.73%2c433.667%2c366.73%2c416.333%2c366.73%2c399C366.73%2c381.667%2c366.73%2c364.333%2c366.73%2c347C366.73%2c329.667%2c366.73%2c312.333%2c348.595%2c299.644C330.459%2c286.955%2c294.187%2c278.911%2c276.052%2c274.888L257.916%2c270.866'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)' style='' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' id='L_J_F_0' d='M277.094%2c582L277.094%2c586.167C277.094%2c590.333%2c277.094%2c598.667%2c277.094%2c606.333C277.094%2c614%2c277.094%2c621%2c277.094%2c624.5L277.094%2c628'/%3e%3cpath marker-end='url(%23mermaid-0_flowchart-v2-pointEnd)' style='' class='edge-thickness-normal edge-pattern-solid edge-thickness-normal edge-pattern-solid flowchart-link' id='L_E_B_0' d='M253.26%2c424L259.641%2c419.833C266.022%2c415.667%2c278.785%2c407.333%2c285.166%2c394.5C291.547%2c381.667%2c291.547%2c364.333%2c291.547%2c347C291.547%2c329.667%2c291.547%2c312.333%2c291.547%2c295C291.547%2c277.667%2c291.547%2c260.333%2c291.547%2c243C291.547%2c225.667%2c291.547%2c208.333%2c285.724%2c195.864C279.901%2c183.396%2c268.255%2c175.791%2c262.432%2c171.989L256.609%2c168.187'/%3e%3c/g%3e%3cg class='edgeLabels'%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' class='labelBkg' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' class='labelBkg' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' class='labelBkg' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' class='labelBkg' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' class='labelBkg' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' class='labelBkg' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' class='labelBkg' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg class='edgeLabel'%3e%3cg transform='translate(0%2c 0)' class='label'%3e%3cforeignObject height='0' width='0'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' class='labelBkg' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='edgeLabel'%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3cg class='nodes'%3e%3cg transform='translate(211.91015625%2c 35)' id='flowchart-A-0' class='node default'%3e%3crect height='54' width='180.046875' y='-27' x='-90.0234375' style='' class='basic label-container'/%3e%3cg transform='translate(-60.0234375%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='120.046875'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eParse Markdown%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(211.91015625%2c 139)' id='flowchart-B-1' class='node default'%3e%3crect height='54' width='167.609375' y='-27' x='-83.8046875' style='' class='basic label-container'/%3e%3cg transform='translate(-53.8046875%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='107.609375'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eCollect Chunks%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(132.2734375%2c 243)' id='flowchart-C-3' class='node default'%3e%3crect height='54' width='248.546875' y='-27' x='-124.2734375' style='' class='basic label-container'/%3e%3cg transform='translate(-94.2734375%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='188.546875'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eReplace with Placeholders%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(132.2734375%2c 347)' id='flowchart-D-5' class='node default'%3e%3crect height='54' width='184.796875' y='-27' x='-92.3984375' style='' class='basic label-container'/%3e%3cg transform='translate(-62.3984375%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='124.796875'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eTranslate Chunks%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(211.91015625%2c 451)' id='flowchart-E-7' class='node default'%3e%3crect height='54' width='190.734375' y='-27' x='-95.3671875' style='' class='basic label-container'/%3e%3cg transform='translate(-65.3671875%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='130.734375'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eApply Translations%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(277.09375%2c 555)' id='flowchart-J-9' class='node default'%3e%3crect height='54' width='157.84375' y='-27' x='-78.921875' style='' class='basic label-container'/%3e%3cg transform='translate(-48.921875%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='97.84375'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eJudge Quality%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3cg transform='translate(277.09375%2c 659)' id='flowchart-F-13' class='node default'%3e%3crect height='54' width='164.953125' y='-27' x='-82.4765625' style='' class='basic label-container'/%3e%3cg transform='translate(-52.4765625%2c -12)' style='' class='label'%3e%3crect/%3e%3cforeignObject height='24' width='104.953125'%3e%3cdiv style='display: table-cell%3b white-space: nowrap%3b line-height: 1.5%3b max-width: 200px%3b text-align: center%3b' xmlns='http://www.w3.org/1999/xhtml'%3e%3cspan class='nodeLabel'%3e%3cp%3eSave to Cache%3c/p%3e%3c/span%3e%3c/div%3e%3c/foreignObject%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/g%3e%3c/svg%3e)
Markdown AST tools
Section titled “Markdown AST tools”The web community has been building a large number of tools to parse and manipulate markdown documents. GenAIScript provides an opinionated plugin, @genaiscript/plugin-mdast that provides the core functionalities without worrying too much about configuration.
- load the plugin
import { mdast } from "@genaiscript/plugin-mdast";
const { visit, parse, stringify, SKIP } = await mdast();- parse the markdown file
const root = parse(file);- visit the tree and collect chunks
const nodes: Record<string, NodeType> = {};visit(root, ["text", "paragraph"], (node) => { const hash = hashNode(node); dbg(`node: %s -> %s`, node.type, hash); nodes[hash] = node as NodeType;});- convert the tree back to markdown
const markdown = stringify(root);With these primitive operations, we are able create a script that can parse, extract translation work, translate, apply translate and stringify back.
One-shot translations
Section titled “One-shot translations”The approach to the translation is to enclose each translatable chunk in a unique identifier marker like ┌T000┐Continuous Markdown Translations└T000┘,
then prompt the LLM to translate each chunk and return them in a parsable format.
The prompt looks like this for this article:
<ORIGINAL>---title: Continuous Markdown Translationsdescription: A walkthrough the script that translates the GenAIScript documentation into multiple languages.date: 2025-07-02...---
You may have noticed that the GenAIScript documentation is now available in **French** (try the upper-right language dropdown).
The translations are not just a one-time effort; they are **continuously** updated as the documentation evolves, in a GitHub Actions. This means that whenever new content is added or existing content is modified,the translations are automatically updated to reflect those changes.
In this post, we'll go through some of the interesting parts of the script and how it works....</ORIGINAL>
<TRANSLATED>---title: ┌T000┐Continuous Markdown Translations└T000┘description: ┌D001┐A walkthrough the script that translates the GenAIScript documentation into multiple languages.└D001┘...---
┌P002┐You may have noticed that the GenAIScript documentation is now available in **French** (try the upper-right language dropdown).└P002┘
┌P003┐The translations are not just a one-time effort; they are **continuously** updated as the documentation evolves, in a GitHub Actions. This means that whenever new content is added or existing content is modified,the translations are automatically updated to reflect those changes.└P003┘
┌P004┐In this post, we'll go through some of the interesting parts of the script and how it works.└P004┘</TRANSLATED>The LLM is prompted to translate the text between <ORIGINAL> and <TRANSLATED>, and to return the translated text with the same markers, but with unique identifiers for each translatable chunk.
```T000Traductions Markdown Continues```
```D001Un aperçu du script qui traduit la documentation GenAIScript dans plusieurs langues.```
```P002Vous avez peut-être remarqué que la documentation de GenAIScript est désormais disponible en **français** (essayez le menu déroulant de langue en haut à droite).```
```P003Les traductions ne sont pas un effort ponctuel ; elles sont mises à jour **en continu** à mesure que la documentation évolue, grâce à GitHub Actions. Cela signifie que chaque fois que du nouveau contenu est ajouté ou que du contenu existant est modifié,les traductions sont automatiquement mises à jour pour refléter ces changements.```
```P004Dans cet article, nous allons passer en revue certains aspects intéressants du script et son fonctionnement.```
```P005Le défi de la traduction de la documentation```The chunks are parsed and injected back into the AST before rendering to a string. We can also store those chunks in a JSON file for caching purposes, so that the next time the script runs, it can reuse the translations without having to re-translate them.
Judging the translation quality
Section titled “Judging the translation quality”To ensure the quality of the translations, we implement a few strategies:
- mechanically validate that the resulting markdown is still valid. Something special characters can throw off the parser.
- validate that all external URLs are not modified. The LLM did not modify, add or remove any URLs.
- run a LLM-as-Judge prompt that evaluates the translation quality. This is done by prompting the LLM to compare the original and translated text, and provide a quality score.
Commit and push the changes
Section titled “Commit and push the changes”Once the translations have passed all the checks, the script commits the changes to the repository and pushes them to the remote branch… and voilà! The translations are now available in the documentation.
Detailed code walkthrough.
Section titled “Detailed code walkthrough.”The following is an AI-generated code walkthrough of the script in all its glory. It’s a bit long, but it covers all the interesting parts of the script and how it works.
Imports
Section titled “Imports”import { hash } from "crypto";import { classify } from "@genaiscript/runtime";import { mdast } from "@genaiscript/plugin-mdast";import "mdast-util-mdxjs-esm";import "mdast-util-mdx-jsx";import type { Node, Text, Heading, Paragraph, PhrasingContent, Yaml } from "mdast";import { basename, dirname, join, relative } from "path";import { URL } from "url";import { xor } from "es-toolkit";import type { MdxJsxFlowElement } from "mdast-util-mdx-jsx";hashis used to create unique identifiers for document sections.classifyis imported from @genaiscript/runtime to judge translation quality.mdastparses and builds Markdown Abstract Syntax Trees (ASTs).- The
"mdast-util-mdxjs-esm"and"mdast-util-mdx-jsx"modules add support for MDX features. - Types from
"mdast"help define the structure of Markdown nodes. - Path and URL helpers organize file handling and patch URLs.
xorcompares arrays to find differences.MdxJsxFlowElementdefines MDX JSX block nodes.
Script configuration
Section titled “Script configuration”script({ accept: ".md,.mdx", files: "src/rag/markdown.md", parameters: { to: { type: "string", default: "fr", description: "The iso-code target language for translation.", }, force: { type: "boolean", default: false, description: "Force translation even if the file has already been translated.", }, },});- Sets which file types and paths to process (
.md,.mdx). - Defines parameters:
to(target language, default French),force(retranslate even if already translated).
Constants and helpers
Section titled “Constants and helpers”const HASH_LENGTH = 20;const maxPromptPerFile = 5;const nodeTypes = ["text", "paragraph", "heading", "yaml"];const starlightDir = "docs/src/content/docs";const starlightBase = "genaiscript";const startlightBaseRx = new RegExp(`^/${starlightBase}/`);const MARKER_START = "┌";const MARKER_END = "└";type NodeType = Text | Paragraph | Heading | Yaml;const langs = { fr: "French",};- Defines how many characters for hashes, max translation attempts, which Markdown nodes to translate, paths, and translation language codes.
const isUri = (str: string): URL => { try { return new URL(str); } catch { return undefined; }};- Checks if a string is a valid URL.
const hasMarker = (str: string): boolean => { return str.includes(MARKER_START) || str.includes(MARKER_END);};- Checks if a string contains translation markers.
Main script logic
Section titled “Main script logic”export default async function main() {- The script entry point.
const { dbg, output, vars } = env; const dbgc = host.logger(`script:md`); const dbgt = host.logger(`script:tree`); const dbge = host.logger(`script:text`); const dbgm = host.logger(`script:mdx`); const { force } = vars as { to: string; force: boolean; };- Prepares logging, debugging, and grabs user parameters.
const tos = vars.to .split(",") .map((s) => s.trim()) .filter(Boolean); dbg(`tos: %o`, tos);- Supports translating to multiple languages.
const ignorer = await parsers.ignore(".mdtranslatorignore"); const files = env.files .filter((f) => ignorer([f]).length) .filter(({ filename }) => !tos.some((to) => filename.includes(`/${to.toLowerCase()}/`))); if (!files.length) cancel("No files selected."); dbg( `files: %O`, files.map((f) => f.filename), );- Ignores files using a local ignore file and excludes already translated files.
const { visit, parse, stringify, SKIP } = await mdast();- Loads Markdown parsing and tree traversal functions.
const hashNode = (node: Node | string) => { if (typeof node === "object") { node = structuredClone(node); visit(node, (node) => delete node.position); } const chunkHash = hash("sha-256", JSON.stringify(node)); return chunkHash.slice(0, HASH_LENGTH).toUpperCase(); };- Hashes nodes (removing position info) to create unique identifiers for each piece of content.
for (const to of tos) { let lang = langs[to]; if (!lang) { const res = await prompt`Respond human friendly name of language: ${to}`.options({ cache: true, systemSafety: false, responseType: "text", throwOnError: true, }); lang = res.text; }- Looks up the language name, or asks the AI if it’s not in the dictionary.
output.heading(2, `Translating Markdown files to ${lang} (${to})`); const translationCacheFilename = `docs/translations/${to.toLowerCase()}.json`; dbg(`cache: %s`, translationCacheFilename); output.itemValue("cache", translationCacheFilename); // hash -> text translation const translationCache: Record<string, string> = force ? {} : (await workspace.readJSON(translationCacheFilename)) || {}; for (const [k, v] of Object.entries(translationCache)) { if (hasMarker(v)) delete translationCache[k]; } dbgc(`translation cache: %O`, translationCache);- Loads a cache of previous translations so work is not redone. Removes any placeholder translations.
for (const file of files) { const { filename } = file; output.heading(3, `${filename}`);
try { const starlight = filename.startsWith(starlightDir); const translationFn = starlight ? filename.replace(starlightDir, join(starlightDir, to.toLowerCase())) : path.changeext(filename, `.${to.toLowerCase()}.md`); dbg(`translation %s`, translationFn);- Determines the output file path for the translation.
const patchFn = (fn: string, trailingSlash?: boolean) => { if (typeof fn === "string" && /^\./.test(fn) && starlight) { const originalDir = dirname(filename); const translationDir = dirname(translationFn); const relativeToOriginal = relative(translationDir, originalDir); let r = join(relativeToOriginal, fn); if (trailingSlash && !r.endsWith("/")) r += "/"; dbg(`patching %s -> %s`, fn, r); return r; } return fn; };- Adjusts image and local import paths so translated files keep working.
let content = file.content; dbgc(`md: %s`, content);
// normalize content dbgc(`normalizing content`); content = stringify(parse(content));- Reads file contents and normalizes formatting before processing.
// parse to tree dbgc(`parsing %s`, filename); const root = parse(content); dbgt(`original %O`, root.children); // collect original nodes nodes const nodes: Record<string, NodeType> = {}; visit(root, nodeTypes, (node) => { const hash = hashNode(node); dbg(`node: %s -> %s`, node.type, hash); nodes[hash] = node as NodeType; });
dbg(`nodes: %d`, Object.keys(nodes).length);
const llmHashes: Record<string, string> = {}; const llmHashTodos = new Set<string>();- Parses content into a Markdown AST and collects unique nodes to translate.
// apply translations and mark untranslated nodes with id let translated = structuredClone(root); visit(translated, nodeTypes, (node) => { const nhash = hashNode(node); const translation = translationCache[nhash]; if (translation) { dbg(`translated: %s`, nhash); Object.assign(node, translation); } else { // mark untranslated nodes with a unique identifier if (node.type === "text") { if (!/\s*[.,:;<>\]\[{}\(\)…]+\s*/.test(node.value) && !isUri(node.value)) { dbg(`text node: %s`, nhash); // compress long hash into LLM friendly short hash const llmHash = `T${Object.keys(llmHashes).length.toString().padStart(3, "0")}`; llmHashes[llmHash] = nhash; llmHashTodos.add(llmHash); node.value = `┌${llmHash}┐${node.value}└${llmHash}┘`; } } else if (node.type === "paragraph" || node.type === "heading") { dbg(`paragraph/heading node: %s`, nhash); const llmHash = `P${Object.keys(llmHashes).length.toString().padStart(3, "0")}`; llmHashes[llmHash] = nhash; llmHashTodos.add(llmHash); node.children.unshift({ type: "text", value: `┌${llmHash}┐`, } as Text); node.children.push({ type: "text", value: `└${llmHash}┘`, }); return SKIP; // don't process children of paragraphs } else if (node.type === "yaml") { dbg(`yaml node: %s`, nhash); const data = parsers.YAML(node.value); if (data) { if (starlight) { if (Array.isArray(data?.hero?.actions)) { data.hero.actions.forEach((action) => { if (typeof action.text === "string") { const nhash = hashNode(action.text); const tr = translationCache[nhash]; dbg(`yaml hero.action: %s -> %s`, nhash, tr); if (!tr) action.text = tr; else { const llmHash = `T${Object.keys(llmHashes).length.toString().padStart(3, "0")}`; llmHashes[llmHash] = nhash; llmHashTodos.add(llmHash); action.text = `┌${llmHash}┐${action.text}└${llmHash}┘`; } } }); } if (data?.cover?.image) { data.cover.image = patchFn(data.cover.image); dbg(`yaml cover image: %s`, data.cover.image); } } if (typeof data.excerpt === "string") { const nhash = hashNode(data.excerpt); const tr = translationCache[nhash]; if (tr) data.excerpt = tr; else { const llmHash = `T${Object.keys(llmHashes).length.toString().padStart(3, "0")}`; llmHashes[llmHash] = nhash; llmHashTodos.add(llmHash); data.excerpt = `┌${llmHash}┐${data.excerpt}└${llmHash}┘`; } } if (typeof data.title === "string") { const nhash = hashNode(data.title); const tr = translationCache[nhash]; if (tr) data.title = tr; else { const llmHash = `T${Object.keys(llmHashes).length.toString().padStart(3, "0")}`; llmHashes[llmHash] = nhash; llmHashTodos.add(llmHash); data.title = `┌${llmHash}┐${data.title}└${llmHash}┘`; } } if (typeof data.description === "string") { const nhash = hashNode(data.description); const tr = translationCache[nhash]; if (tr) data.title = tr; else { const llmHash = `D${Object.keys(llmHashes).length.toString().padStart(3, "0")}`; llmHashes[llmHash] = nhash; llmHashTodos.add(llmHash); data.description = `┌${llmHash}┐${data.description}└${llmHash}┘`; } } node.value = YAML.stringify(data); return SKIP; } } else { dbg(`untranslated node type: %s`, node.type); } } });- For each node, applies cached translation or marks it with a unique code (e.g.
┌T001┐ ... └T001┘) for AI to translate.
// patch images and esm imports visit(translated, ["mdxJsxFlowElement"], (node) => { const flow = node as MdxJsxFlowElement; for (const attribute of flow.attributes || []) { if (attribute.type === "mdxJsxAttribute" && attribute.name === "title") { // collect title attributes dbgm(`attribute title: %s`, attribute.value); let title = attribute.value; const nhash = hashNode(title); const tr = translationCache[nhash]; if (tr) title = tr; else { const llmHash = `T${Object.keys(llmHashes).length.toString().padStart(3, "0")}`; llmHashes[llmHash] = nhash; llmHashTodos.add(llmHash); title = `┌${llmHash}┐${title}└${llmHash}┘`; } attribute.value = title; return SKIP; } } });- Ensures MDX JSX title attributes are handled for translation.
dbgt(`translated %O`, translated.children); let attempts = 0; let lastLLmHashTodos = llmHashTodos.size + 1; while ( llmHashTodos.size && llmHashTodos.size < lastLLmHashTodos && attempts < maxPromptPerFile ) { attempts++; output.itemValue(`missing translations`, llmHashTodos.size); dbge(`todos: %o`, Array.from(llmHashTodos)); const contentMix = stringify(translated); dbgc(`translatable content: %s`, contentMix);- Tracks translation attempts and missing nodes to avoid infinite loops.
translation prompt
Section titled “translation prompt” const { fences, error } = await runPrompt( async (ctx) => { const originalRef = ctx.def("ORIGINAL", file.content, { lineNumbers: false }); const translatedRef = ctx.def("TRANSLATED", contentMix, { lineNumbers: false }); ctx.$`You are an expert at translating technical documentation into ${lang} (${to}).
## Task Your task is to translate a Markdown (GFM) document to ${lang} (${to}) while preserving the structure and formatting of the original document. You will receive the original document as a variable named ${originalRef} and the currently translated document as a variable named ${translatedRef}.
Each Markdown AST node in the translated document that has not been translated yet will be enclosed with a unique identifier in the form of \`┌node_identifier┐\` at the start and \`└node_identifier┘\` at the end of the node. You should translate the content of each these nodes individually. Example:
\`\`\`markdown ┌T001┐ This is the content to be translated. └T001┘
This is some other content that does not need translation.
┌T002┐ This is another piece of content to be translated. └T002┘ \`\`\`
## Output format
Respond using code regions where the language string is the HASH value For example:
\`\`\`T001 translated content of text enclosed in T001 here (only T001 content!) \`\`\`
\`\`\`T002 translated content of text enclosed in T002 here (only T002 content!) \`\`\`
\`\`\`T003 translated content of text enclosed in T003 here (only T003 content!) \`\`\` ...
## Instructions
- Be extremely careful about the HASH names. They are unique identifiers for each node and should not be changed. - Always use code regions to respond with the translated content. - Do not translate the text outside of the HASH tags. - Do not change the structure of the document. - As much as possible, maintain the original formatting and structure of the document. - Do not translate inline code blocks, code blocks, or any other code-related content. - Use ' instead of ’ - Always make sure that the URLs are not modified by the translation. - Translate each node individually, preserving the original meaning and context. - If you are unsure about the translation, skip the translation.
`.role("system"); }, { responseType: "text", systemSafety: false, system: [], cache: true, label: `translating ${filename} (${llmHashTodos.size} nodes)`, }, );- Asks the AI to translate only inside the special hash markers, and reply in code blocks with the hash as the language.
if (error) { output.error(`Error translating ${filename}: ${error.message}`); break; }
// collect translations for (const fence of fences) { const llmHash = fence.language; if (llmHashTodos.has(llmHash)) { llmHashTodos.delete(llmHash); const hash = llmHashes[llmHash]; dbg(`translation: %s - %s`, llmHash, hash); let chunkTranslated = fence.content.replace(/\r?\n$/, "").trim(); const node = nodes[hash]; dbg(`original node: %O`, node); if (node?.type === "text" && /\s$/.test(node.value)) { dbg(`patch trailing space for %s`, hash); chunkTranslated += " "; } chunkTranslated = chunkTranslated .replace(/┌[A-Z]\d{3,5}┐/g, "") .replace(/└[A-Z]\d{3,5}┘/g, ""); dbg(`content: %s`, chunkTranslated); translationCache[hash] = chunkTranslated; } }
lastLLmHashTodos = llmHashTodos.size; }- Updates the translation cache with AI responses, strips hash markers, and continues if there are missing translations.
// apply translations translated = structuredClone(root);
// apply translations visit(translated, nodeTypes, (node) => { if (node.type === "yaml") { const data = parsers.YAML(node.value); if (data) { if (starlight) { if (data?.hero?.image?.file) { data.hero.image.file = patchFn(data.hero.image.file); dbg(`yaml hero image: %s`, data.hero.image.file); } if (Array.isArray(data?.hero?.actions)) { data.hero.actions.forEach((action) => { if (typeof action.link === "string") { action.link = action.link.replace( startlightBaseRx, `/${starlightBase}/${to.toLowerCase()}/`, ); dbg(`yaml hero action link: %s`, action.link); } if (typeof action.text === "string") { const nhash = hashNode(action.text); const tr = translationCache[nhash]; dbg(`yaml hero.action: %s -> %s`, nhash, tr); if (tr) action.text = tr; } if (action?.image?.file) { action.image.file = patchFn(action.image.file); dbg(`yaml hero action image: %s`, action.image.file); } }); } if (data?.cover?.image) { data.cover.image = patchFn(data.cover.image); dbg(`yaml cover image: %s`, data.cover.image); } } if (typeof data.excerpt === "string") { const nhash = hashNode(data.excerpt); const tr = translationCache[nhash]; dbg(`yaml excerpt: %s -> %s`, nhash, tr); if (tr) data.excerpt = tr; } if (typeof data.title === "string") { const nhash = hashNode(data.title); const tr = translationCache[nhash]; dbg(`yaml title: %s -> %s`, nhash, tr); if (tr) data.title = tr; } if (typeof data.description === "string") { const nhash = hashNode(data.description); const tr = translationCache[nhash]; dbg(`yaml description: %s -> %s`, nhash, tr); if (tr) data.description = tr; } node.value = YAML.stringify(data); return SKIP; } } else { const hash = hashNode(node); const translation = translationCache[hash]; if (translation) { if (node.type === "text") { dbg(`translated text: %s -> %s`, hash, translation); node.value = translation; } else if (node.type === "paragraph" || node.type === "heading") { dbg(`translated %s: %s -> %s`, node.type, hash, translation); try { const newNodes = parse(translation).children as PhrasingContent[]; node.children.splice(0, node.children.length, ...newNodes); return SKIP; } catch (error) { output.error(`error parsing paragraph translation`, error); output.fence(node, "json"); output.fence(translation); } } else { dbg(`untranslated node type: %s`, node.type); } } } });- Walks through the AST and replaces content with translations from cache.
// patch images and esm imports visit(translated, ["mdxjsEsm", "image"], (node) => { if (node.type === "image") { node.url = patchFn(node.url); return SKIP; } else if (node.type === "mdxjsEsm") { // path local imports const rx = /^(import|\})\s*(.*)\s+from\s+(?:\"|')(\.?\.\/.*)(?:\"|');?$/gm; node.value = node.value.replace(rx, (m, k, i, p) => { const pp = patchFn(p); const r = k === "}" ? `} from "${pp}";` : `import ${i} from "${pp}";`; dbg(`mdxjsEsm import: %s -> %s`, m, r); return r; }); return SKIP; } });- Fixes image paths and import statements for translated files.
visit(translated, ["mdxJsxFlowElement"], (node) => { const flow = node as MdxJsxFlowElement; for (const attribute of flow.attributes || []) { if (attribute.type === "mdxJsxAttribute" && attribute.name === "title") { const hash = hashNode(attribute.value); const tr = translationCache[hash]; if (tr) { dbg(`translate title: %s -> %s`, hash, tr); attribute.value = tr; } } } });- Translates the title attributes for MDX JSX nodes.
// patch links visit(translated, "link", (node) => { if (startlightBaseRx.test(node.url)) { node.url = patchFn(node.url.replace(startlightBaseRx, "../"), true); } });- Makes sure internal doc links are updated for the translated folder structure.
dbgt(`stringifying %O`, translated.children); let contentTranslated = await stringify(translated); if (content === contentTranslated) { output.warn(`Unable to translate anything, skipping file.`); continue; }- Converts the AST back into Markdown, and skips files that didn’t change.
// validate it stills parses as Markdown try { parse(contentTranslated); } catch (error) { output.error(`Translated content is not valid Markdown`, error); output.diff(content, contentTranslated); continue; }- Makes sure the output is still valid Markdown.
// validate all external links // have same domain { const originalLinks = new Set<string>(); visit(root, "link", (node) => { if (isUri(node.url)) { originalLinks.add(node.url); } }); const translatedLinks = new Set<string>(); visit(translated, "link", (node) => { if (isUri(node.url)) { translatedLinks.add(node.url); } }); const diffLinks = xor(Array.from(originalLinks), Array.from(translatedLinks)); if (diffLinks.length) { output.warn(`some links have changed`); output.fence(diffLinks, "yaml"); } }- Checks that external links are not changed by the translation.
if (attempts) { // judge quality is good enough const res = await classify( (ctx) => { ctx.$`You are an expert at judging the quality of translations. Your task is to determine the quality of the translation of a Markdown document from English to ${lang} (${to}). The original document is in ${ctx.def("ORIGINAL", content)}, and the translated document is provided in ${ctx.def("TRANSLATED", contentTranslated, { lineNumbers: true })} (line numbers were added).`.role( "system", ); }, { ok: `Translation is faithful to the original document and conveys the same meaning.`, bad: `Translation is of low quality or has a different meaning from the original.`, }, { label: `judge translation ${to} ${basename(filename)}`, explanations: true, system: ["system.annotations"], systemSafety: false, }, );
output.resultItem(res.label === "ok", `Translation quality: ${res.label}`); if (res.label !== "ok") { output.fence(res.answer); output.diff(content, contentTranslated); continue; } }- Uses
classifyfrom GenAIScript Runtime to ask the AI if the translation is good enough.
// apply translations and save dbgc(`translated: %s`, contentTranslated); dbg(`writing translation to %s`, translationFn);
await workspace.writeText(translationFn, contentTranslated); await workspace.writeText( translationCacheFilename, JSON.stringify(translationCache, null, 2), ); } catch (error) { output.error(error); break; } } }}- Writes the translated Markdown and updates the cache for next time.