Architectural Overview
At its core, Hyperspace envisions two layers: Indexing Infrastructure and Query Infrastructure. The following figure shows the layering:
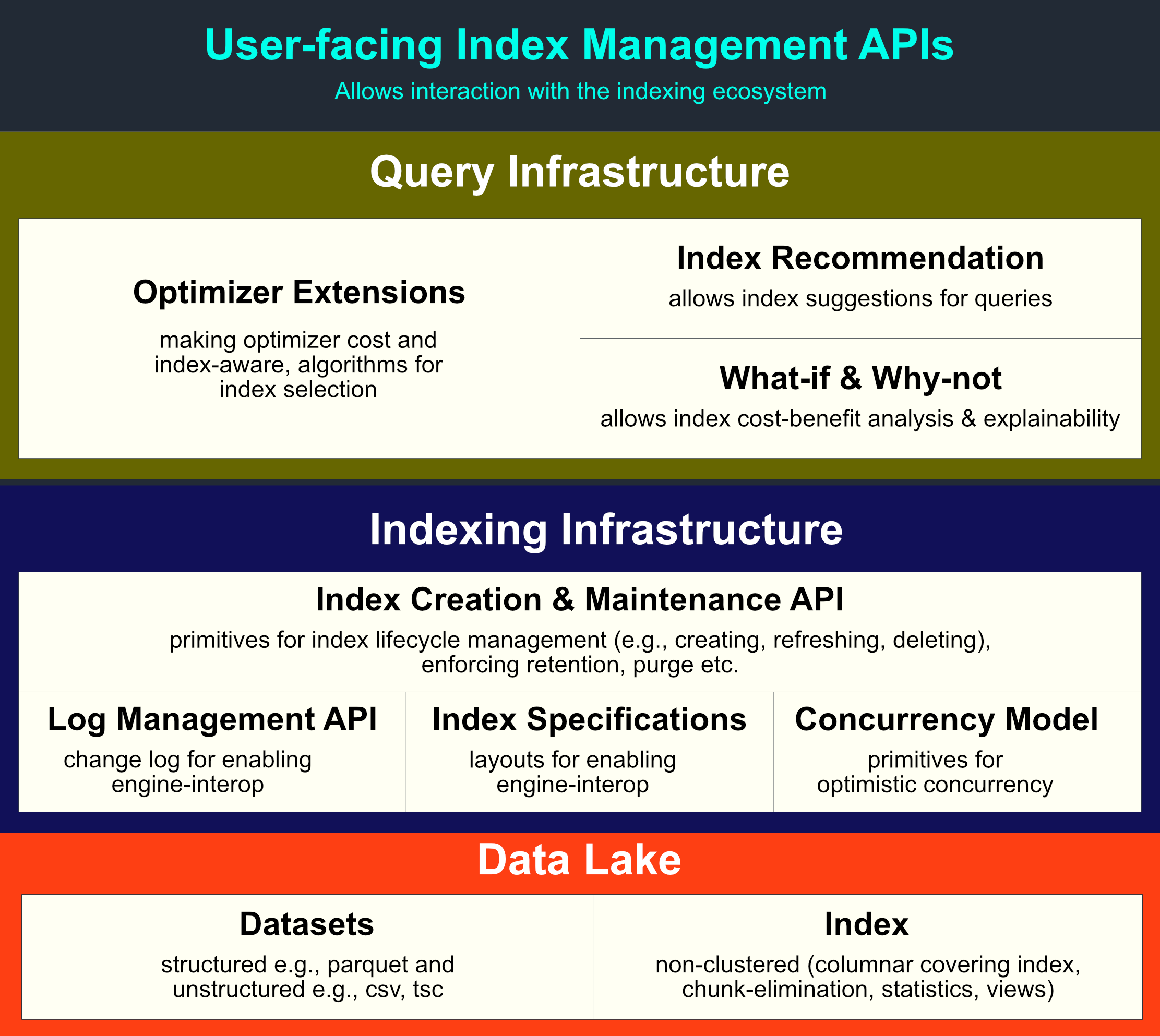
We will cover the components in a bottom-up manner.
Indexing Infrastructure
Index Creation & Maintenance API
At a bare minimum, users can utilize the indexing infrastructure (available as a service or a library) to create and maintain indexes (or derived datasets) on their data through the index creation and maintenance API. For instance, users can create a non-clustered columnar covering index, specifying which columns to create an index on and which columns to include as data columns.
In Hyperspace, note that there is no separate “indexing service” required as a pre-requisite, since the indexing infrastructure, in principle, can leverage any available query engine (e.g., Spark) for index construction. And since indexes and their metadata are stored on the data lake, users can parallelize index scans to the extent that their query engine scales and their environment/business allows.
Index metadata management is another important part of the indexing infrastructure. Internally, index metadata maintenance is managed by an index manager. The index manager takes charge of index metadata creation, update, and deletion when corresponding modification happens to the index data, and thus governs consistency between index data and index metadata. The index manager also provides utility functions to read the index metadata from its serialized format. For example, the query optimizer can read all index metadata and then find the best index for given queries.
Primitives
For developers and contributors of Hyperspace, the library also offers access to the underlying primitive components. Of particular interest are the following:
- Log Management API: A critical design decision we took in order to support multi-engine interoperability was to store all the indexes and their metadata on the lake. To track the lineage of the operations that take place over an index, Hyperspace records user operations in an operation log.
- Index Specs: To support the extensibility goals, Hyperspace requires certain properties from the underlying indexes (or derived datasets). These are exposed via the lifecycle management API and anyone wanting to add an additional auxiliary data structure must implement support for these APIs.
- Concurrency Model: To support multi-user and incremental maintenance scenarios, we use optimistic concurrency control.
Query Infrastructure
Without loss of generality, we discuss the components of the query infrastructure
implemented in the the current version of Hyperspace. The library is written as
an extension of the Spark optimizer (a.k.a, Catalyst) to make it index-aware,
i.e., given a query along with an existing index, Hyperspace-enabled Spark can
perform transparent query rewriting to utilize the existing index. The only
step required on the user’s side to enable Hyperspace’s optimizer extensions is
to execute sparkSession.enableHyperspace() after creating the Spark session.
Since we treat an index as another dataset on the lake,
users can exploit Spark’s distributed nature to automatically scale index scans.
While Hyperspace introduces the notion of indexing, an important aspect of big data administration that critically influences performance is the ability to select indexes to build for a given query or a workload. To decide the right indexes for a workload, it is crucial for users to be able to perform a cost-benefit analysis of the existing indexes and any hypothetical indexes they have in mind. While Hyperspace currently does not have this functionality, we are actively working on contributing these in the upcoming months.