Language Server Index Format Specification - 0.5.0
The 0.5.0 version of LSIF is currently under construction.
Language Server Index Format
The purpose of the Language Server Index Format (LSIF) is it to define a standard format for language servers or other programming tools to dump their knowledge about a workspace. This dump can later be used to answer language server LSP requests for the same workspace without running the language server itself. Since much of the information would be invalidated by a change to the workspace, the dumped information typically excludes requests used when mutating a document. So, for example, the result of a code complete request is typically not part of such a dump.
Changelog
Version 0.5.0
In version 0.4.0 support was added to dump larger systems project by project (in their reverse dependency order) and then combine the dumps again in a database by linking result sets using their corresponding monikers. Use of the format has shown that a couple of features are missing to make this work nicely:
- support to logical group projects. To support this a
Groupvertex got added. - knowing how unique a moniker is. To support this a
uniqueproperty got added to theMoniker. - the
nextMonikeredge got replaced by a more genericattachedge. This was possible since monikers now carry auniqueproperty which was before encoded in the direction of thenextMonikeredge. - In programming languages supporting polymorphism calls at runtime can be bound to a different type then statically know. An example are overridden methods in object oriented programming languages. Since dumps can be created on a per project basis we need to add additional information to the dumps so that these polymorphic binds can be capture. The general concept of reference links got therefore introduced (see section Multiple Project). In short it allows a tool to annotate an
itemedge with a property valuesreferenceLinks. - To better shard the output into chunks the
itemsedge carry an additional propertyshard. This property was nameddocumentin an early version of the 0.5 specification.
An old 0.4.0 version of the specification is available here
Version 0.4.0
Up to version 0.4.0 the focus of the LSIF format was to ease the generation of the dump for language tool providers. However this made it very hard for consumers of the dump to efficiently import them into a DB unless the DB format one to one mapped to the LSIF format. This version of the specification tries to balance this by requiring tools providers to emit additional events of when certain data is ready to be consumed. It also adds support to partition data per document.
Since 0.4.0 changes some of the LSIF aspects more deeply an old 0.3.x version of the specification is available here
Motivation
Principal design goals:
- The format should not imply the use of a certain persistence technology.
- The data defined should be modeled as closely as possible to the Language Server Protocol to make it possible to serve the data through the LSP without further transformation.
- The data stored is result data usually returned from a LSP request. The dump doesn’t contain any program symbol information nor does the LSIF define any symbol semantics (e.g. where a symbol is defined or referenced or when a method overrides another method). The LSIF therefore doesn’t define a symbol database. Please note that this is consistent with the LSP itself which doesn’t define any symbol semantics either.
- The output format will be based on JSON as with the LSP.
LSP requests that are good candidates to be supported in LSIF are:
textDocument/documentSymboltextDocument/foldingRangetextDocument/documentLinktextDocument/definitiontextDocument/declarationtextDocument/typeDefinitiontextDocument/hovertextDocument/referencestextDocument/implementation
The corresponding LSP requests have one of the following two forms:
request(uri, method) -> result
request(uri, position, method) -> result
where method is the JSON-RPC request method.
Concrete examples are
request(
'file:///Users/dirkb/sample/test.ts',
'textDocument/foldingRange'
) -> FoldingRange[];
request(
'file:///Users/dirkb/sample/test.ts',
{ line: 10, character: 17 },
'textDocument/hover'
) -> Hover;
The input tuple to a request is either [uri, method] or [uri, position, method] and the output is some form of result. For the same uri and [uri, position] tuple, there are many different requests to execute.
The dump format therefore should support the following features:
- Input data must be easily queryable (e.g. the document and the position).
- Each element has a unique id (which may be a string or a number).
- It should be possible to emit data as soon as it is available to allow streaming rather than large memory requirements. For example, emitting data based on document syntax should be done for each file as parsing progresses.
- It should be easy to add additional requests later on.
- It should be easy for a tool to consume a dump and for example import it into a database without holding the dump in memory.
We came to the conclusion that the most flexible way to emit this is a graph, where edges represent the method and vertices are [uri], [uri, position] or a request result. This data could then be stored as JSON or read into a database that can represent these vertices and relationships.
Assume there is a file /Users/dirkb/sample.ts and we want to store the folding range information with it then the indexer emits two vertices: one representing the document with its URI file:///Users/dirkb/sample.ts, the other representing the folding result. In addition, an edge would be emitted representing the textDocument/foldingRange request.
{ id: 1, type: "vertex", label: "document",
uri: "file:///Users/dirkb/sample.ts", languageId: "typescript"
}
{ id: 2, type: "vertex", label: "foldingRangeResult",
result: [ { ... }, { ... }, ... ]
}
{ id: 3, type: "edge", label: "textDocument/foldingRange", outV: 1, inV: 2 }
The corresponding graph looks like this
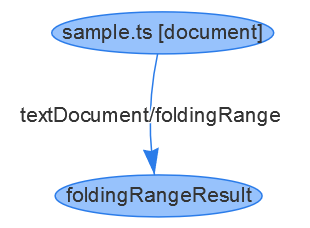
Ranges
For requests that take a position as its input, we need to store the position as well. Usually LSP requests return the same result for positions that point to the same word / name in a document. Take the following TypeScript example:
function bar() {
}
A hover request for a position denoting the b in bar will return the same result as a position denoting the a or r. To make the dump more compact, it will use ranges to capture this instead of single positions. The following vertices will be emitted in this case. Note that line, character are zero based as in the LSP:
{ id: 4, type: "vertex", label: "range",
start: { line: 0, character: 9}, end: { line: 0, character: 12 }
}
To bind the range to a document, we use a special edge labeled contains which points from a document to a set of ranges.
{ id: 5, type: "edge", label: "contains", outV: 1, inVs: [4] }
LSIF supports 1:n edges for the contains relationship which in a graph can easily be mapped to n 1:1 edges. LSIF support this for two reasons: (a) to make the output more compact since a document usually contains hundreds of those ranges and (b) to easy the import and batching for consumers of a LSIF dump.
To bind the hover result to the range, we use the same pattern as we used for the folding ranges. We emit a vertex representing the hover result and an edge representing the textDocument/hover request.
{
id: 6,
type: "vertex",
label: "hoverResult",
result: {
contents: [
{ language: "typescript", value: "function bar(): void" }
]
}
}
{ id: 7, type: "edge", label: "textDocument/hover", outV: 4, inV: 6 }
The corresponding graph looks like this
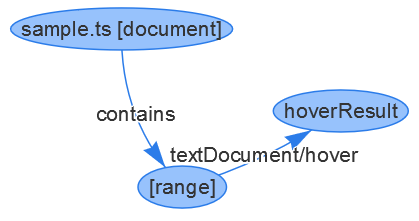
The ranges emitted for a document in the contains relationship must follow these rules:
- a given range ID can only be contained in one document or in other words: ranges must not be shared between documents even if they have the same start / end value.
- No two ranges can be equal.
- No two ranges can overlap, claiming the same position in a document unless one range is entirely contained by the other.
If a position in a document is mapped to a range and more than one range covers the position, the following algorithm should be used:
- sort the ranges by containment with innermost first
- for range in ranges do
- check if the range has an outgoing edge
textDocument/${method} - if yes, use it
- check if the range has an outgoing edge
- end
- return
null
Result Set
Usually the hover result is the same whether you hover over a definition of a function or over a reference of that function. The same is actually true for many LSP requests like textDocument/definition, textDocument/references or textDocument/typeDefinition. In a naïve model, each range would have outgoing edges for all these LSP requests and would point to the corresponding results. To optimize this and to make the graph easier to understand, the concept of a ResultSet is introduced. A result set acts as a hub to be able to store information common to a lot of ranges. The ResultSet itself doesn’t carry any information. So it looks like this:
export interface ResultSet {
}
The corresponding output of the above example with a hover using a result set looks like this:
{ id: 1, type: "vertex", label: "document",
uri: "file:///Users/dirkb/sample.ts", languageId: "typescript"
}
{ id: 2, type: "vertex", label: "resultSet" }
{ id: 3, type: "vertex", label: "range",
start: { line: 0, character: 9}, end: { line: 0, character: 12 }
}
{ id: 4, type: "edge", label: "contains", outV: 1, inVs: [3] }
{ id: 5, type: "edge", label: "next", outV: 3, inV: 2 }
{ id: 6, type: "vertex", label: "hoverResult",
result: {
"contents":[ {
language: "typescript", value:"function bar(): void"
}]
}
}
{ id: 7, type: "edge", label: "textDocument/hover", outV: 2, inV: 6 }
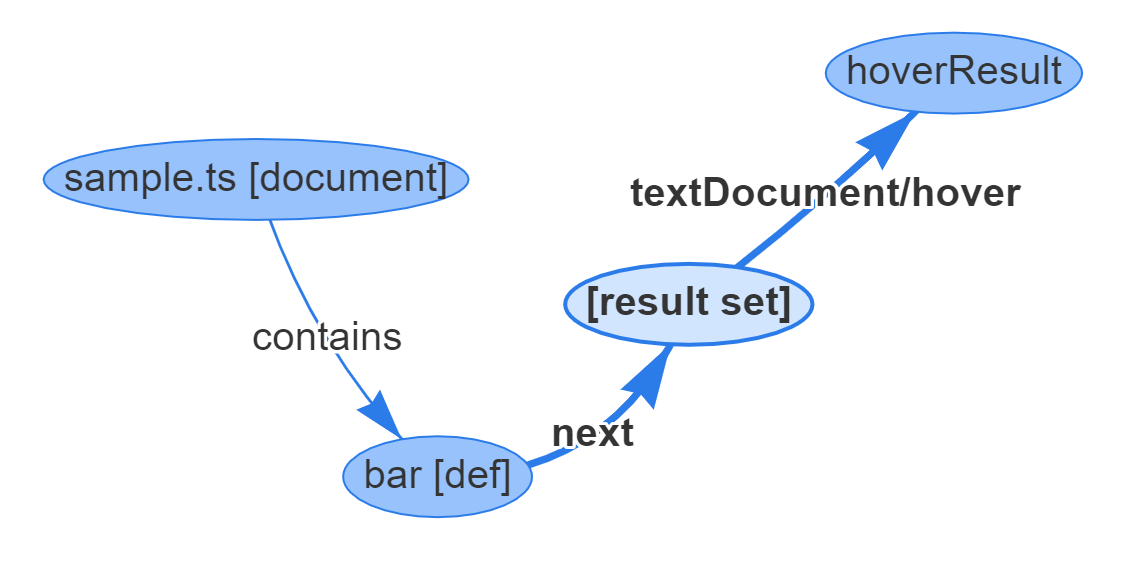
Result sets are linked to ranges using a next edge. A results set can also forward information to another result set by linking to it using a next edge.
The pattern of storing the result with the ResultSet will be used for other requests as well. The lookup algorithm is therefore as follows for a request [document, position, method]:
- find all ranges for [document, position]. If none exist, return
nullas the result - sort the ranges by containment the innermost first
- for range in ranges do
- assign range to out
- while out !==
null- check if out has an outgoing edge
textDocument/${method}. if yes, use it and return the corresponding result - check if out has an outgoing
nextedge. If yes, set out to the target vertex. Else set out tonull
- check if out has an outgoing edge
- end
- end
- otherwise return
null
Language Features
Request: textDocument/definition
The same pattern of connecting a range, result set, or a document with a request edge to a method result is used for other requests as well. Let’s next look at the textDocument/definition request using the following TypeScript sample:
function bar() {
}
function foo() {
bar();
}
This will emit the following vertices and edges to model the textDocument/definition request:
// The document
{ id: 4, type: "vertex", label: "document",
uri: "file:///Users/dirkb/sample.ts", languageId: "typescript"
}
// The result set
{ id: 6, type: "vertex", label: "resultSet" }
// The bar declaration
{ id: 9, type: "vertex", label: "range",
start: { line: 0, character: 9 }, end: { line: 0, character: 12 }
}
{ id: 10, type: "edge", label: "next", outV: 9, inV: 6 }
// The bar reference
{ id: 20, type: "vertex", label: "range",
start: { line: 4, character: 2 }, end: { line: 4, character: 5 }
}
{ id: 21, type: "edge", label: "next", outV: 20, inV: 6}
// The definition result linked to the bar result set
{ id: 22, type: "vertex", label: "definitionResult" }
{ id: 23, type: "edge", label: "textDocument/definition", outV: 6, inV: 22 }
{ id: 24, type: "edge", label: "item", outV: 22, inVs: [9], shard: 4 }
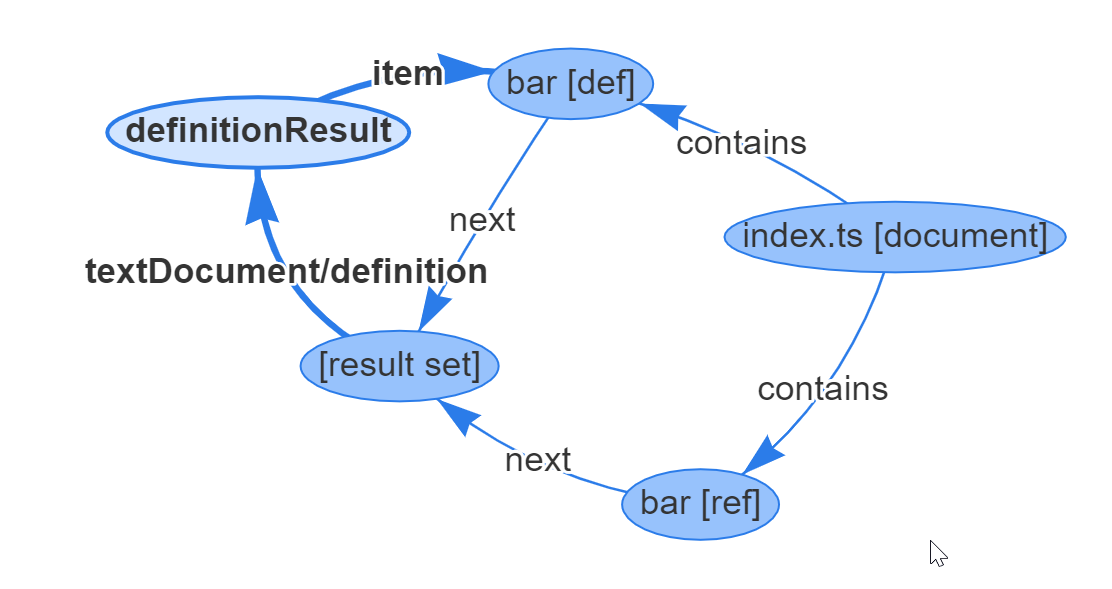
The definition result above has only one value (the range with id ‘9’) and we could have emitted it directly. However, we introduced the definition result vertex for two reasons:
- To have consistency with all other requests that point to a result.
- To have support for languages where a definition can be spread over multiple ranges or even multiple documents. To support multiple documents ranges are added to a definition result using an 1:N
itemedge. Conceptually a definition result is an array to which theitemedge adds items.
Consider the following TypeScript example:
interface X {
foo();
}
interface X {
bar();
}
let x: X;
Running Go to Definition on X in let x: X will show a dialog which lets the user select between the two definitions of the interface X. The emitted JSON in this case looks like this:
{ id : 38, type: "vertex", label: "definitionResult" }
{ id : 40, type: "edge", label: "item", outV: 38, inVs: [9, 13], shard: 4 }
The item edge as an additional property shard which indicate the vertex that is the source (e.g. a document or a project) of these declarations. We added this information to still make it easy to emit the data but also make it easy to process and shard the data when storing into a database. Without that information we would either need to specific an order in which data needs to be emitted (e.g. an item edge and only refer to a range that got already added to a document using a contains edge) or we force processing tools to keep a lot of vertices and edges in memory. The approach of having this shard property looks like a fair balance.
Request: textDocument/declaration
There are programming languages that have the concept of declarations and definitions (like C/C++). If this is the case, the dump can contain a corresponding declarationResult vertex and a textDocument/declaration edge to store the information. They are handled analogously to the entities emitted for the textDocument/definition request.
More about Request: textDocument/hover
In the LSP, the hover is defined as follows:
export interface Hover {
/**
* The hover's content
*/
contents: MarkupContent | MarkedString | MarkedString[];
/**
* An optional range
*/
range?: Range;
}
where the optional range is the name range of the word hovered over.
Side Note: This is a pattern used for other LSP requests as well, where the result contains the word range of the word the position parameter pointed to.
This makes the hover different for every location so we can’t really store it with the result set. But wait, the range is the range of one of the bar references we already emitted and used to start to compute the result. To make the hover still reusable, we ask the index server to fill in the starting range if no range is defined in the result. So for a hover request executed on range { line: 4, character: 2 }, end: { line: 4, character: 5 } the hover result will be:
{ id: 6, type: "vertex", label: "hoverResult",
result: {
contents: [ { language: "typescript", value: "function bar(): void" } ],
range: { line: 4, character: 2 }, end: { line: 4, character: 5 }
}
}
Request: textDocument/references
Storing references will be done in the same way as storing a hover or go to definition ranges. It uses a reference result vertex and item edges to add ranges to the result.
Look at the following example:
function bar() {
}
function foo() {
bar();
}
The relevant JSON output looks like this:
// The document
{ id: 4, type: "vertex", label: "document",
uri: "file:///Users/dirkb/sample.ts", languageId: "typescript"
}
// The bar declaration
{ id: 6, type: "vertex", label: "resultSet" }
{ id: 9, type: "vertex", label: "range",
start: { line: 0, character: 9 }, end: { line: 0, character: 12 }
}
{ id: 10, type: "edge", label: "next", outV: 9, inV: 6 }
// The bar reference range
{ id: 20, type: "vertex", label: "range",
start: { line: 4, character: 2 }, end: { line: 4, character: 5 }
}
{ id: 21, type: "edge", label: "next", outV: 20, inV: 6 }
// The reference result
{ id : 25, type: "vertex", label: "referenceResult" }
// Link it to the result set
{ id : 26, type: "edge", label: "textDocument/references", outV: 6, inV: 25 }
// Add the bar definition as a reference to the reference result
{ id: 27, type: "edge", label: "item",
outV: 25, inVs: [9], shard: 4, property: "definitions"
}
// Add the bar reference as a reference to the reference result
{ id: 28, type: "edge", label: "item",
outV: 25, inVs: [20], shard: 4, property: "references"
}
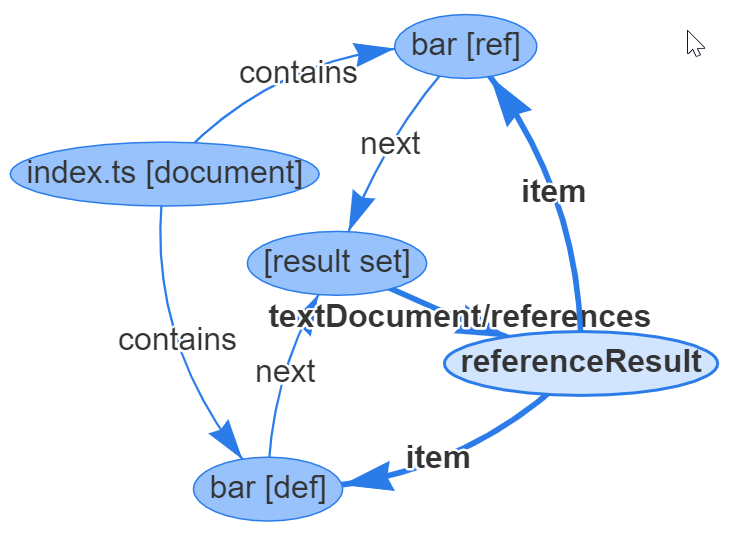
We tag the item edge with id 27 as a definition since the reference result distinguishes between definitions, declarations, and references. This is done since the textDocument/references request takes an additional input parameter includeDeclarations controlling whether declarations and definitions are included in the result as well. Having three distinct properties allows the server to compute the result accordingly.
The item edge also support linking reference results to other reference results. This is useful when computing references to methods overridden in a type hierarchy.
Take the following example:
interface I {
foo(): void;
}
class A implements I {
foo(): void {
}
}
class B implements I {
foo(): void {
}
}
let i: I;
i.foo();
let b: B;
b.foo();
The reference result for the method foo in TypeScript contains all three declarations and both references. While parsing the document, one reference result is created and then shared between all result sets.
The output looks like this:
// The document
{ id: 4, type: "vertex", label: "document",
uri: "file:///Users/dirkb/sample.ts", languageId: "typescript"
}
// The declaration of I#foo
{ id: 13, type: "vertex", label: "resultSet" }
{ id: 16, type: "vertex", label: "range",
start: { line: 1, character: 2 }, end: { line: 1, character: 5 }
}
{ id: 17, type: "edge", label: "next", outV: 16, inV: 13 }
// The reference result for I#foo
{ id: 30, type: "vertex", label: "referenceResult" }
{ id: 31, type: "edge", label: "textDocument/references", outV: 13, inV: 30 }
// The declaration of A#foo
{ id: 29, type: "vertex", label: "resultSet" }
{ id: 34, type: "vertex", label: "range",
start: { line: 5, character: 2 }, end: { line: 5, character: 5 }
}
{ id: 35, type: "edge", label: "next", outV: 34, inV: 29 }
// The declaration of B#foo
{ id: 47, type: "vertex", label: "resultSet" }
{ id: 50, type: "vertex", label: "range",
start: { line: 10, character: 2 }, end: { line: 10, character: 5 }
}
{ id: 51, type: "edge", label: "next", outV: 50, inV: 47 }
// The reference i.foo()
{ id: 65, type: "vertex", label: "range",
start: { line: 15, character: 2 }, end: { line: 15, character: 5 }
}
// The reference b.foo()
{ id: 78, type: "vertex", label: "range",
start: { line: 18, character: 2 }, end: { line: 18, character: 5 }
}
// The insertion of the ranges into the shared reference result
{ id: 90, type: "edge", label: "item",
outV: 30, inVs: [16,34,50], shard: 4, property: "definitions"
}
{ id: 91, type: "edge", label: "item",
outV: 30, inVs: [65,78], shard: 4, property: "references"
}
// Linking A#foo to I#foo
{ id: 101, type: "vertex", label: "referenceResult" }
{ id: 102, type: "edge", label: "textDocument/references", outV: 29, inV: 101 }
{ id: 103, type: "edge", label: "item",
outV: 101, inVs: [30], shard: 4, property: "referenceResults"
}
// Linking B#foo to I#foo
{ id: 114, type: "vertex", label: "referenceResult" }
{ id: 115, type: "edge", label: "textDocument/references", outV: 47, inV: 114 }
{ id: 116, type: "edge", label: "item",
outV: 114, inVs: [30], shard: 4, property: "referenceResults"
}
One goal of the language server index format is that the information can be emitted as soon as possible without caching too much information in memory. With languages that support overriding methods defined in more than one interface, this can be more complicated since the whole inheritance tree might only be known after parsing all documents.
Take the following TypeScript example:
interface I {
foo(): void;
}
interface II {
foo(): void;
}
class B implements I, II {
foo(): void {
}
}
let i: I;
i.foo();
let b: B;
b.foo();
Searching for I#foo() finds 4 references, searching for II#foo() finds 3 reference, and searching on B#foo() finds 5 results. The interesting part here is when the declaration of class B gets processed which implements I and II, neither the reference result bound to I#foo() nor the one bound to II#foo() can be reused. So we need to create a new one. To still be able to profit from the results generated for I#foo and II#foo, the LSIF supports nested references results. This way the one referenced from B#foo will reuse the one from I#foo and II#foo. Depending on how these declarations are parsed, the two reference results might contain the same references. When a language server interprets reference results consisting of other reference results, the server is responsible to de-duplicate the final ranges.
In the above example, there will be three reference results
// The document
{ id: 4, type: "vertex", label: "document",
uri: "file:///Users/dirkb/sample.ts", languageId: "typescript"
}
// Declaration of I#foo
{ id: 13, type: "vertex", label: "resultSet" }
{ id: 16, type: "vertex", label: "range",
start: { line: 1, character: 2 }, end: { line: 1, character: 5 }
}
{ id: 17, type: "edge", label: "next", outV: 16, inV: 13 }
// Declaration of II#foo
{ id: 27, type: "vertex", label: "resultSet" }
{ id: 30, type: "vertex", label: "range",
start: { line: 5, character: 2 }, end: { line: 5, character: 5 }
}
{ id: 31, type: "edge", label: "next", outV: 30, inV: 27 }
// Declaration of B#foo
{ id: 45, type: "vertex", label: "resultSet" }
{ id: 52, type: "vertex", label: "range",
start: { line: 9, character: 2 }, end: { line: 9, character: 5 }
}
{ id: 53, type: "edge", label: "next", outV: 52, inV: 45 }
// Reference result for I#foo
{ id: 46, type: "vertex", label: "referenceResult" }
{ id: 47, type: "edge", label: "textDocument/references", outV: 13, inV: 46 }
// Reference result for II#foo
{ id: 48, type: "vertex", label: "referenceResult" }
{ id: 49, type: "edge", label: "textDocument/references", outV: 27, inV: 48 }
// Reference result for B#foo
{ id: 116 "typ" :"vertex", label: "referenceResult" }
{ id: 117 "typ" :"edge", label: "textDocument/references", outV: 45, inV: 116 }
// Link B#foo reference result to I#foo and II#foo
{ id: 118 "typ" :"edge", label: "item",
outV: 116, inVs: [46,48], document: 4, property: "referenceResults"
}
For Typescript, method references are recorded at their most abstract declaration and if methods are merged (B#foo), they are combined using a reference result pointing to other results.
Request: textDocument/implementation
Supporting a textDocument/implementation request is done reusing what we implemented for a textDocument/references request. In most cases, the textDocument/implementation returns the declaration values of the reference result that a symbol declaration points to. For cases where the result differs, the LSIF provides an ImplementationResult. To nest implementation results the item edge supports a property value "implementationResults".
The corresponding ImplementationResult looks like this:
interface ImplementationResult {
label: `implementationResult`
}
Request: textDocument/typeDefinition
Supporting textDocument/typeDefinition is straightforward. The edge is either recorded at the range or at the ResultSet.
The corresponding TypeDefinitionResult looks like this:
interface TypeDefinitionResult {
label: `typeDefinitionResult`
}
For the following TypeScript example:
interface I {
foo(): void;
}
let i: I;
The relevant emitted vertices and edges looks like this:
// The document
{ id: 4, type: "vertex", label: "document",
uri: "file:///Users/dirkb/sample.ts", languageId: "typescript"
}
// The declaration of I
{ id: 6, type: "vertex", label: "resultSet" }
{ id: 9, type: "vertex", label: "range",
start: { line: 0, character: 10 }, end: { line: 0, character: 11 }
}
{ id: 10, type: "edge", label: "next", outV: 9, inV: 6 }
// The declaration of i
{ id: 26, type: "vertex", label: "resultSet" }
// The type definition result
{ id: 37, type: "vertex", label: "typeDefinitionResult" }
// Hook the result to the declaration
{ id: 38, type: "edge", label: "textDocument/typeDefinition", outV: 26, inV:37 }
// Add the declaration of I as a target range.
{ id: 51, type: "edge", label: "item", outV: 37, inVs: [9], shard: 4 }
As with other results ranges get added using a item edge. In this case without a property since there is only one kind of range.
Document requests
The Language Server Protocol also supports requests for documents only (without any position information). These requests are textDocument/foldingRange, textDocument/documentLink, and textDocument/documentSymbol. We follow the same pattern as before to model these, the difference being that the result is linked to the document instead of to a range.
Request: textDocument/foldingRange
For the folding range result this looks like this:
function hello() {
console.log('Hello');
}
function world() {
console.log('world');
}
function space() {
console.log(' ');
}
hello();space();world();
{ id: 2, type: "vertex", label: "document",
uri: "file:///Users/dirkb/sample.ts", languageId: "typescript"
}
{ id: 112, type: "vertex", label: "foldingRangeResult", result:[
{ startLine: 0, startCharacter: 16, endLine: 2, endCharacter: 1 },
{ startLine: 4, startCharacter: 16, endLine: 6, endCharacter: 1 },
{ startLine: 8, startCharacter: 16, endLine: 10, endCharacter: 1 }
]}
{ id: 113, type: "edge", label: "textDocument/foldingRange", outV: 2, inV: 112 }
The corresponding FoldingRangeResult is defined as follows:
export interface FoldingRangeResult {
label: 'foldingRangeResult';
result: lsp.FoldingRange[];
}
Request: textDocument/documentLink
Again, for document links, we define a result type and a corresponding edge to link it to a document. Since the link location usually appear in comments, the ranges don’t denote any symbol declarations or references. We therefore inline the range into the result like we do with folding ranges.
export interface DocumentLinkResult {
label: 'documentLinkResult';
result: lsp.DocumentLink[];
}
Request: textDocument/documentSymbol
Next we look at the textDocument/documentSymbol request. This request usually returns an outline view of the document in hierarchical form. However, not all programming symbols declared or defined in a document are part of the result (for example, locals are usually omitted). In addition, an outline item needs to provide additional information like the full range and a symbol kind. There are two ways we can model this: either we do the same as we do for folding ranges and the document links and store the information in a document symbol result as literals, or we extend the range vertex with some additional information and refer to these ranges in the document symbol result. Since the additional information for ranges might be helpful in other scenarios as well, we support adding additional tags to these ranges by defining a tag property on the range vertex.
The following tags are currently supported:
/**
* The range represents a declaration
*/
export interface DeclarationTag {
/**
* A type identifier for the declaration tag.
*/
type: 'declaration';
/**
* The text covered by the range
*/
text: string;
/**
* The kind of the declaration.
*/
kind: lsp.SymbolKind;
/**
* The full range of the declaration not including leading/trailing whitespace
* but everything else, e.g comments and code. The range must be included in
* fullRange.
*/
fullRange: lsp.Range;
/**
* Optional detail information for the declaration.
*/
detail?: string;
}
/**
* The range represents a definition
*/
export interface DefinitionTag {
/**
* A type identifier for the declaration tag.
*/
type: 'definition';
/**
* The text covered by the range
*/
text: string;
/**
* The symbol kind.
*/
kind: lsp.SymbolKind;
/**
* The full range of the definition not including leading/trailing whitespace
* but everything else, e.g comments and code. The range must be included in
* fullRange.
*/
fullRange: lsp.Range;
/**
* Optional detail information for the definition.
*/
detail?: string;
}
/**
* The range represents a reference
*/
export interface ReferenceTag {
/**
* A type identifier for the reference tag.
*/
type: 'reference';
/**
* The text covered by the range
*/
text: string;
}
/**
* The type of the range is unknown.
*/
export interface UnknownTag {
/**
* A type identifier for the unknown tag.
*/
type: 'unknown';
/**
* The text covered by the range
*/
text: string;
}
Emitting the tags for the following TypeScript example:
function hello() {
}
hello();
Will look like this:
{ id: 2, type: "vertex", label: "document",
uri: "file:///Users/dirkb/sample.ts", languageId: "typescript"
}
{ id: 4, type: "vertex", label: "resultSet" }
{ id: 7, type: "vertex", label: "range",
start: { line: 0, character: 9 }, end: { line: 0, character: 14 },
tag: {
type: "definition", text: "hello", kind: 12,
fullRange: {
start: { line: 0, character: 0 }, end: { line: 1, character: 1 }
}
}
}
The document symbol result is then modeled as follows:
export interface RangeBasedDocumentSymbol {
id: RangeId
children?: RangeBasedDocumentSymbol[];
}
export interface DocumentSymbolResult extends V {
label: 'documentSymbolResult';
result: lsp.DocumentSymbol[] | RangeBasedDocumentSymbol[];
}
The given TypeScript example:
namespace Main {
function hello() {
}
function world() {
let i: number = 10;
}
}
Produces the following output:
// The document
{ id: 2 , type: "vertex", label: "document",
uri: "file:///Users/dirkb/sample.ts", languageId: "typescript"
}
// The declaration of Main
{ id: 7 , type: "vertex", label: "range",
start: { line: 0, character: 10 }, end: { line: 0, character: 14 },
tag: {
type: "definition", text: "Main", kind: 7,
fullRange: {
start: { line: 0, character: 0 }, end: { line: 5, character: 1 }
}
}
}
// The declaration of hello
{ id: 18 , type: "vertex", label: "range",
start: { line: 1, character: 11 }, end: { line: 1, character: 16 },
tag: {
type: "definition", text: "hello", kind: 12,
fullRange: {
start: { line: 1, character: 2 }, end: { line: 2, character: 3 }
}
}
}
// The declaration of world
{ id: 29 , type: "vertex", label: "range",
start: { line: 3, character: 11 }, end: { line: 3, character: 16 },
tag: {
type: "definition", text: "world", kind: 12,
fullRange: {
start: { line: 3, character: 2 }, end: { line: 4, character: 3 }
}
}
}
// The document symbol
{ id: 39 , type: "vertex", label: "documentSymbolResult",
result: [ { id: 7 , children: [ { id: 18 }, { id: 29 } ] } ]
}
{ id: 40 , type: "edge", label: "textDocument/documentSymbol",
outV: 2, inV: 39
}
Request: textDocument/diagnostic
The only information missing that is useful in a dump are the diagnostics associated with documents. Diagnostics in the LSP are modeled as a push notifications sent from the server to the client. This doesn’t work well with a dump modeled on request method names. However, the push notification can be emulated as a request where the request’s result is the value sent during the push as a parameter.
In the dump, we model diagnostics as follows:
- We introduce a pseudo request
textDocument/diagnostic. - We introduce a diagnostic result which contains the diagnostics associated with a document.
The result looks like this:
export interface DiagnosticResult {
label: 'diagnosticResult';
result: lsp.Diagnostic[];
}
The given TypeScript example:
function foo() {
let x: string = 10;
}
Produces the following output:
{ id: 2, type: "vertex", label: "document",
uri: "file:///Users/dirkb/sample.ts", languageId: "typescript"
}
{ id: 18, type: "vertex", label: "diagnosticResult",
result: [
{
severity: 1, code: 2322,
message: "Type '10' is not assignable to type 'string'.",
range: {
start : { line: 1, character: 5 }, end: { line: 1, character: 6 }
}
}
]
}
{ id: 19, type: "edge", label: "textDocument/diagnostic", outV: 2, inV: 18 }
Since diagnostics are not very common in dumps, no effort has been made to reuse ranges in diagnostics.
The Project vertex
Usually language servers operate in some sort of project context. In TypeScript, a project is defined using a tsconfig.json file. C# and C++ have their own means. The project file usually contains information about compile options and other parameters. Having these in the dump can be valuable. The LSIF therefore defines a project vertex. In addition, all documents that belong to that project are connected to the project using a contains edge. If there was a tsconfig.json in the previous examples, the first emitted edges and vertices would look like this:
{ id: 1, type: "vertex", label: "project",
resource: "file:///Users/dirkb/tsconfig.json", kind: "typescript"
}
{ id: 2, type: "vertex", label: "document",
uri: "file:///Users/dirkb/sample.ts", languageId: "typescript"
}
{ id: 3, type: "edge", label: "contains", outV: 1, inVs: [2] }
The definition of the project vertex looks as follows:
export interface Project extends V {
/**
* The label property.
*/
label: VertexLabels.project;
/**
* The project kind like 'typescript' or 'csharp'. See also the language ids
* in the specification.
* See https://microsoft.github.io/language-server-protocol/specification
*/
kind: string;
/**
* The resource URI of the project file.
*/
resource?: Uri;
/**
* Optional the content of the project file, `base64` encoded.
*/
contents?: string;
}
Embedding contents
It can be valuable to embed the contents of a document or project file into the dump as well. For example, if the content of the document is a virtual document generated from program meta data. The index format therefore supports an optional contents property on the document and project vertex. If used the content needs to be base64 encoded.
Advanced Concepts
Events
To ease the processing of an LSIF dump to for example import it into a database the dump emits begin and end events for documents and projects. After the end event of a document has been emitted the dump must not contain any further data referencing that document. For example no ranges from that document can be referenced in item edges. Nor can result sets or other vertices linked to the ranges in that document. The document can however be referenced in a contains edge adding the document to a project. The begin / end events for documents look like this:
// The actual document
{ id: 4, type: "vertex", label: "document",
uri: "file:///Users/dirkb/sample.ts", languageId: "typescript",
contents: "..."
}
// The begin event
{ id: 5, type: "vertex", label: "$event",
kind: "begin", scope: "document" , data: 4
}
// The end event
{ id: 53, type: "vertex", label: "$event",
kind: "end", scope: "document" , data: 4
}
Between the document vertex 4 and the document begin event 5 no information specific to document 4 can be emitted. Please note that more than one document can be open at a given point in time meaning that there have been n different document begin events without corresponding document end events.
The events for projects looks similar:
{ id: 2, type: "vertex", label: "project", kind: "typescript" }
{ id: 4, type: "vertex", label: "document",
uri: "file:///Users/dirkb/sample.ts", languageId: "typescript",
contents: "..."
}
{ id: 5, type: "vertex", label: "$event",
kind: "begin", scope: "document" , data: 4
}
{ id: 3, type: "vertex", label: "$event",
kind: "begin", scope: "project", data: 2
}
{ id: 53, type: "vertex", label: "$event",
kind: "end", scope: "document", data: 4
}
{ id: 54, type: "edge", label: "contains", outV: 2, inVs: [4] }
{ id: 55, type: "vertex", label: "$event",
kind: "end", scope: "project", data: 2
}
Project exports and external imports (Monikers)
Changed in 0.5.0
One use case of the LSIF is to create dumps for released versions of a product, either a library or a program. If a project P2 references a library P1, it would also be useful if the information in these two dumps could be related. To make this possible, the LSIF introduces optional monikers which can be linked to ranges using a corresponding edge. The monikers can be used to describe what a project exports and what it imports. Let’s first look at the export case.
Consider the following TypeScript file called index.ts:
export function func(): void {
}
export class Emitter {
private doEmit() {
}
public emit() {
this.doEmit();
}
}
{ id: 4, type: "vertex", label: "document",
uri: "file:///Users/dirkb/index.ts", languageId: "typescript",
contents: "..."
}
{ id: 11, type: "vertex", label: "resultSet" }
{ id: 12, type: "vertex", label: "moniker",
kind: "export", scheme: "tsc", identifier: "lib/index:func", unique: "group"
}
{ id: 13, type: "edge", label: "moniker", outV: 11, inV: 12 }
{ id: 14, type: "vertex", label: "range",
start: { line: 0, character: 16 }, end: { line: 0, character: 20 }
}
{ id: 15, type: "edge", label: "next", outV: 14, inV: 11 }
{ id: 18, type: "vertex", label: "resultSet" }
{ id: 19, type: "vertex", label: "moniker",
kind: "export", scheme: "tsc", identifier: "lib/index:Emitter",
unique: "group"
}
{ id: 20, type: "edge", label: "moniker", outV: 18, inV: 19 }
{ id: 21, type: "vertex", label: "range",
start: { line: 3, character: 13 }, end: { line: 3, character: 20 }
}
{ id: 22, type: "edge", label: "next", outV: 21, inV: 18 }
{ id: 25, type: "vertex", label: "resultSet" }
{ id: 26, type: "vertex", label: "moniker",
kind: "export", scheme: "tsc", identifier: "lib/index:Emitter.doEmit",
unique: "group"
}
{ id: 27, type: "edge", label: "moniker", outV: 25, inV: 26 }
{ id: 28, type: "vertex", label: "range",
start: { line: 4, character: 10 }, end: { line: 4, character: 16 }
}
{ id: 29, type: "edge", label: "next", outV: 28, inV: 25 }
{ id: 32, type: "vertex", label: "resultSet" }
{ id: 33, type: "vertex", label: "moniker",
kind: "export", scheme: "tsc", identifier: "lib/index:Emitter.emit",
unique: "group"
}
{ id: 34, type: "edge", label: "moniker", outV: 32, inV: 33 }
{ id: 35, type: "vertex", label: "range",
start: { line: 7, character: 9 }, end: { line: 7, character: 13 }
}
{ id: 36, type: "edge", label: "next", outV: 35, inV: 32 }
This describes the exported declaration inside index.ts with a moniker (e.g. a handle in string format) that is bound to the corresponding range declaration. The generated moniker must be position independent and stable so that it can be used to identify the symbol in other projects or documents. It should be sufficiently unique so as to avoid matching other monikers in other projects unless they actually refer to the same symbol. A moniker therefore has the following properties:
schemeto indicate how theidentifiersis to be interpreted.identifierto actually identify the symbol. Its structure is opaque to the scheme owner. In the above example the monikers are created by the TypeScript compiler tsc and can only be compared to monikers also having the schemetsc.kindto indicate whether the moniker is exported, imported or local to the project.uniqueto indicate how unique the moniker is. See the multi project section for more information on this.
Please also note that the method Emitter#doEmit has an export moniker although the method is private. If private elements do have monikers depends on the programming language. Since TypeScript can’t enforce visibility (it compiles to JS which doesn’t have the concept) we treat them as visible. Even the TypeScript language server does so. Find all references does find all references to private methods even if it is flagged as a visibility violation.
Systems with multiple Projects
New in 0.5.0
Most software systems today consist out of multiple projects. Always creating LSIF dumps for all project of a system even if only one project changes is not very feasible, especially if only internals in a project changed. LSIF since 0.4.0 therefore allows to create an LSIF dump per project and link them to larger system in the DB again. However 0.4.0 was lacking some concepts to make this real. To motivate them consider the following example
Project P1
Project P1 consist of one p1Main.ts file with the following content:
export interface Disposable {
dispose(): void;
}
let d: Disposable;
d.dispose();
Project P2
Project P2 depends on P1 and consists of one p2Main.ts file with the following content:
import { Disposable } from 'p1';
class Widget implements Disposable {
public dispose(): void {
}
}
let w: Widget;
w.dispose();
Now if a user search for reference to Widget#dispose it is expected that the reference d.dispose in P1 is included in the result. However when P1 is process the tools doesn’t know about P2. And when P2 is processed it usually doesn’t know about the source of P1. It only knows about its API shape (e.g. in TypeScript the corresponding d.ts file).
To make this work we first need to group projects into larger units so that we know in which projects d.dispose is actually a match. Assume there is a totally unrelated project PX which also uses Disposable from P1 but P2 is never linked into one system with PX. So an object of type Widget can never flow to code in PX hence reference in PX should not be listed. We therefore introduce the notation of a group to logically group projects into larger systems. Projects belong to a group and groups are identified using a URI. Lets look at the concrete dumps for P1 and P2:
{id: 2, type: "vertex", label: "group",
uri: "https://github.com/microsoft/lsif-node.git/samples/ts-cascade",
conflictResolution: "takeDB", name: "ts-cascade",
rootUri: "file:///Users/dirkb/samples/ts-cascade"
}
{id: 4, type: "vertex", label: "project", kind: "typescript", name: "p1" }
{id: 5, type: "edge", label: "belongsTo", outV: 4, inV:2 }
As a group URI the path in a GitHub repository is used. However the URI could also be something like lsif-group:://com.microsoft/vscode/lsif-node/samples/ts-cascade if the URI should be repository independent. This would be useful if a company store code in many different repository systems. The edge with the id 5 binds the project to the group.
The dump for project P2 looks like this:
{id: 2, type: "vertex", label: "group",
uri: "https://github.com/Microsoft/lsif-node.git/samples/ts-cascade",
conflictResolution: "takeDB", name: "ts-cascade",
rootUri: "file:///Users/dirkb/samples/ts-cascade"
}
{id: 4, type: "vertex", label: "project", kind: "typescript", name: "p2" }
{id: 5, type: "edge", label: "belongsTo", outV: 4, inV: 2 }
Note that this binds P2 to the same group P1 belongs to. To avoid any kind of group management the group carries a property conflictResolution to tell a DB which group information to use if the DB already contains a group with the given URL. takeDB indicates to take the one already store in the DB and takeDump indicates that the one from the dump should overwrite the DB value.
Whenever possible group URIs should be organized hierarchical to allow to group projects into a broader scope. For example a URI https://github.com/microsoft should capture all project organized under the GitHub Microsoft organization.
Now lets look how we ensure that searching for references for Widget#dispose find the d.dispose() match in P1 as well. First lets look what kind of information will be in the dump of P1 for Disposable#dispose:
// The result set for the Disposable#dispose symbol
{ id: 21, type: "vertex", label: "resultSet" }
// The export moniker of Disposable#dispose in P1 (note kind export).
{ id: 22, type: "vertex", label: "moniker",
scheme: "tsc", identifier: "p1/lib/p1Main:Disposable.dispose",
unique: "group", kind:"export"
}
{ id: 23, type: "edge", label: "moniker", outV: 21, inV: 22 }
// The actual definition of the symbol
{ id: 24, type: "vertex", label: "range",
start: { line: 1, character: 1 }, end: { line: 1, character: 8 },
tag: {
type: definition, text: "dispose", kind: 7,
fullRange: {
start : { line: 1, character:1 }, end: { line: 1, character: 17 }
}
}
}
// Bind the reference result to the result set
{ id: 57, type: "vertex", label: "referenceResult" }
{ id: 58, type: "edge", label: "textDocument/references", outV: 21, inV: 57 }
Interesting here is line 22 which defines the moniker for Disposable#dispose. It has new a property unique telling that the moniker is unique inside a group of projects but not necessarily outside. Other possible values for unique are:
documentto indicate that the moniker is only unique inside a document. Used for example for locals or private members.projectto indicate that the moniker is only unique inside a project. Used for example for project internal symbols.groupto indicate that the moniker is unique inside a group of projects. Used for example for exported members.schemeto indicate that the moniker is unique inside the moniker’s scheme. For example if the moniker is generated for a specific package manager (see npm example below) then these monikers are usually unique inside the moniker’s theme (e.g. all moniker generated for npm carry thenpmscheme and are unique)globalto indicate that the moniker is globally unique (e.g. its identifer is unique independent of the scheme or kind)
When generating the dump for P2 the information for Widget#dispose will look like this:
// The import moniker for importing Disposable#dispose into P2
{ id: 22, type: "vertex", label: "moniker",
scheme: "tsc", identifier: "p1/lib/p1Main:Disposable.dispose",
unique: "group", kind: "import"
}
// The result set for Widget#dispose
{ id: 78, type: "vertex", label: "resultSet" }
// The moniker for Widget#dispose. Note that the moniker is local since the
// Widget class is not exported
{ id: 79, type: "vertex", label: "moniker",
scheme: "tsc", identifier: "2Q46RTVRZTuVW1ajf68/Vw==",
unique: "document", kind: "local"
}
{ id: 80, type: "edge", label: "moniker", outV: 78, inV: 79 }
// The actual definition of the symbol
{ id: 81, type: "vertex", label: "range",
start: { line: 3, character: 8 }, end: { line: 3, character: 15 },
tag: {
type: "definition", text: "dispose", kind: 6,
fullRange: {
start: { line: 3, character: 1 }, end: { line: 4, character: 2 }
}
}
}
// Bind the reference result to Widget#dispose
{ id: 116, type: "vertex", label: "referenceResult" }
{ id: 117, type: "edge", label: "textDocument/references", outV: 78, inV: 116}
{ id: 118, type: "edge", label: "item",
outV: 116, inVs: [43], shard: 52, property: "referenceResults"
}
// Link the reference result set of Disposable#dispose to this result set
// using a moniker
{ id: 119, type: "edge", label: "item",
outV: 116, inVs: [22], shard: 52, property: "referenceLinks"
}
{ id: 120, type: "edge", label: "item",
outV: 43, inVs: [81], shard: 52, property: "definitions"
}
{ id: 121, type: "edge", label: "item",
outV: 43, inVs: [96], shard: 52, property: "references"
}
The noteworthy parts are:
- the vertex with
id: 22: is the import moniker forDisposable#disposefrom P1. - the edge with
id: 119: this adds a reference link to the reference result ofWidget#dispose. Item edges with areferenceLinksare conceptual like item edges with areferenceResultsproperty. They allow for composite reference results. The different is that areferenceResultsitem edge references another result using the vertex id since the reference result is part of the same dump. AreferenceLinksitem edge references another result using a moniker. So the actual resolving needs to happen in a database which has the data for both P1 and P2. As withreferenceResultsitem edges a language servers is responsible to de-duplicate the final ranges.
Package Managers
Changed in 0.5.0
How exported elements are visible in other projects in most programming languages depends on how files are packaged into a library or program. In TypeScript, the standard package manager is npm.
Consider that the following package.json file exists:
{
"name": "lsif-ts-sample",
"version": "1.0.0",
"description": "",
"main": "lib/index.js",
"author": "MS",
"license": "MIT",
}
for the following TypeScript file (same as above):
export function func(): void {
}
export class Emitter {
private doEmit() {
}
public emit() {
this.doEmit();
}
}
then these monikers can be translated into monikers that are npm dependent. Instead of replacing the monikers we emit a second set of monikers and link the tsc monikers to corresponding npm monikers using an attachedge:
{ id: 991, type: "vertex", label: "packageInformation",
name: "lsif-ts-sample", manager: "npm", version: "1.0.0"
}
{ id: 987, type: "vertex", label: "moniker",
kind: "export", scheme: "npm", identifier: "lsif-ts-sample::func",
unique: "scheme"
}
{ id: 986, type: "edge", label: "packageInformation", outV: 987, inV: 991 }
{ id: 985, type: "edge", label: "attach", outV: 987, inV: 12 }
{ id: 984, type: "vertex", label: "moniker",
kind: "export", scheme: "npm", identifier: "lsif-ts-sample::Emitter",
unique: "scheme"
}
{ id: 983, type: "edge", label: "packageInformation", outV: 984, inV: 991 }
{ id: 982, type: "edge", label: "attach", outV: 984, inV: 19 }
{ id: 981, type: "vertex", label: "moniker",
kind: "export", scheme: "npm",
identifier: "lsif-ts-sample::Emitter.doEmit", unique: "scheme"
}
{ id: 980, type: "edge", label: "packageInformation", outV: 981, inV: 991 }
{ id: 979, type: "edge", label: "attach", outV: 981, inV: 26 }
{ id: 978, type: "vertex", label: "moniker",
kind: "export", scheme: "npm",
identifier: "lsif-ts-sample::Emitter.emit", unique: "scheme"
}
{ id: 977, type: "edge", label: "packageInformation", outV: 978, inV: 991 }
{ id: 976, type: "edge", label: "attach", outV: 978, inV: 33 }
Things to observe:
- a special
packageInformationvertex got emitted to point to the corresponding npm package information. - the npm moniker refer to the package name.
- its
uniquevalue isschemedenoting that the monikers identifier is unique across allnpmmonikers. - since the file
index.tsis the npm main file the moniker identifier as no file path. The is comparable to importing this module into TypeScript or JavaScript were only the module name and no file path is used (e.g.import * as lsif from 'lsif-ts-sample'). - the
attachedge points from the npm moniker vertex to the tsc moniker vertex.
For LSIF we recommend that a second tool is used to make the monikers emitted by the indexer be package manager dependent. This supports the use of different package managers and allows incorporating custom build tools. In the TypeScript implementation, this is done by a npm specific tool which attaches the monikers taking the npm package information into account.
Reporting importing external symbols is done using the same approach. The LSIF emits monikers of kind import. Consider the following typescript example:
import * as mobx from 'mobx';
let map: mobx.ObservableMap = new mobx.ObservableMap();
where mobx is the npm mobx package. Running the tsc index tools produces:
{ id: 41, type: "vertex", label: "document",
uri: "file:///samples/node_modules/mobx/lib/types/observablemap.d.ts",
languageId: "typescript", contents: "..."
}
{ id: 55, type: "vertex", label: "resultSet" }
{ id: 57, type: "vertex", label: "moniker",
kind: "import", scheme: "tsc",
identifier: "node_modules/mobx/lib/mobx:ObservableMap", unique: 'group'
}
{ id: 58, type: "edge", label: "moniker", outV: 55, inV: 57 }
{ id: 59, type: "vertex", label: "range",
start: { line: 17, character: 538 }, end: { line: 17, character: 551 }
}
{ id: 60, type: "edge", label: "next", outV: 59, inV: 55 }
Three things to note here: First, TypeScript uses declarations files for externally imported symbols. That has the nice effect that the moniker information can be attached to the declaration ranges in these files. In other languages, the information might be attached to the file actually referencing the symbol. Or a virtual document for the referenced item is generated. Second, the tool only generates this information for symbols actually referenced, not for all available symbols. Third these monikers are tsc specific and point to the node_modules folder.
However piping this information through the npm tool will generate the following information:
{ id: 991, type: "vertex", label: "packageInformation",
name: "mobx", manager: "npm", version: "5.6.0",
repository: { type: "git", url: "git+https://github.com/mobxjs/mobx.git" }
}
{ id: 978, type: "vertex", label: "moniker",
kind: "import", scheme: "npm", identifier: "mobx::ObservableMap",
unique: 'scheme'
}
{ id: 977, type: "edge", label: "packageInformation", outV: 978, inV: 991 }
{ id: 976, type: "edge", label: "attach", outV: 978, inV: 57 }
which made the moniker specific to the npm mobx package. In addition information about the mobx package itself got emitted.
Usually monikers are attached to result sets since they are the same for all ranges pointing to the result set. However for dumps that don’t use result sets, monikers can also be emitted on ranges.
For tools processing the dump and importing it into a database it is sometime useful to know whether a result is local to a file or not (for example function arguments can only be navigated inside the file). To help postprocessing tools to efficiently decide this, LSIF generation tools should generate a moniker for locals as well. The corresponding kind to use is local. The identifier should still be unique inside the document.
For the following example
function foo(x: number): void {
}
The moniker for x looks like this:
{ id: 13, type: "vertex", label: "resultSet" }
{ id: 14, type: "vertex", label: "moniker",
kind: "local", scheme: "tsc", identifier: "SfeOP6s53Y2HAkcViolxYA==",
unique: 'document'
}
{ id: 15, type: "edge", label: "moniker", outV: 13, inV: 14 }
{ id: 16, type: "vertex", label: "range",
start: { line: 0, character: 13 }, end: { line: 0, character: 14 },
tag: {
type: "definition", text: "x", kind: 7,
fullRange: {
start: { line: 0, character: 13 }, end: { line: 0, character: 22 }
}
}
}
{ id: 17, type: "edge", label: "next", outV: 16, inV: 13 }
In addition to this moniker schemes starting with $ are reserved and shouldn’t be used by a LSIF tool.
Result ranges
Ranges in LSIF have currently two meanings:
- they act as LSP request sensitive areas in a document (e.g. we use them to decide if for a given position a corresponding LSP request result exists)
- they act as navigation targets (e.g. they are the result of a Go To declaration navigation).
To fulfil the first LSIF specifies that ranges can’t overlap or be the same. However this constraint is not necessary for the second meaning. To support equal or overlapping target ranges we introduce a vertex resultRange. It is not allowed to use a resultRange as a target in a contains edge.
Meta Data Vertex
Changed in 0.5.0
To support versioning the LSIF defines a meta data vertex as follows:
export interface MetaData {
/**
* The label property.
*/
label: 'metaData';
/**
* The version of the LSIF format using semver notation. See
* https://semver.org/. Please note the version numbers starting with 0
* don't adhere to semver and adopters have to assume the each new version
* is breaking.
*/
version: string;
/**
* The string encoding used to compute line and character values in
* positions and ranges. Currently only 'utf-16' is support due to the
* limitations in LSP.
*/
positionEncoding: 'utf-16',
/**
* Information about the tool that created the dump
*/
toolInfo?: {
name: string;
version?: string;
args?: string[];
}
}
Emitting constraints
The following emitting constraints (some of which have already been mentioned in the document) exist:
- a vertex needs to be emitted before it can be referenced in an edge.
- a
rangeandresultRangecan only be contained in one document. - a
resultRangecan not be used as a target in acontainsedge. - after a document end event has been emitted only result sets, reference or implementation results emitted through that document can be referenced in edges. It is for example not allowed to reference ranges or result ranges from that document. This also includes adding monikers to ranges or result sets. The document data so to speak can not be altered anymore.
- if ranges point to result sets and monikers are emitted, they must be emitted on the result set and can’t be emitted on individual ranges.
Additional Information
Tools
lsif-protocol: Protocol defined as TypeScript interfaceslsif-util: Utility tools for LSIF developmentlsif-tsc: LSIF indexer for TypeScriptlsif-npm: Linker for NPM monikers
Open Questions
While implementing this for TypeScript and npm we collected a list of open questions in form of GitHub issues we are already aware of.