MSCCL++ Design Document
Introduction
MSCCL++ redefines inter-GPU communication interfaces, thereby delivering a highly efficient and customizable communication stack for distributed GPU applications. Its design is specifically tailored to accommodate diverse performance optimization scenarios often encountered in state-of-the-art AI applications. The figure below provides a high-level overview of MSCCL++ abstractions in CUDA, C, and Python.
MSCCL++ Abstractions Overview
The followings highlight the key features of MSCCL++.
Light-weight and multi-layer abstractions. MSCCL++ provides communication abstractions at lowest level close to hardware and at the highest level close to application API. The lowest level of abstraction is ultra light weight which enables a user to implement logics of data movement for a collective operation such as AllReduce inside a GPU kernel extremely efficiently without worrying about memory ordering of different ops. The modularity of MSCCL++ enables a user to construct the building blocks of MSCCL++ in a high level abstraction in Python and feed them to a CUDA kernel in order to facilitate the user’s productivity.
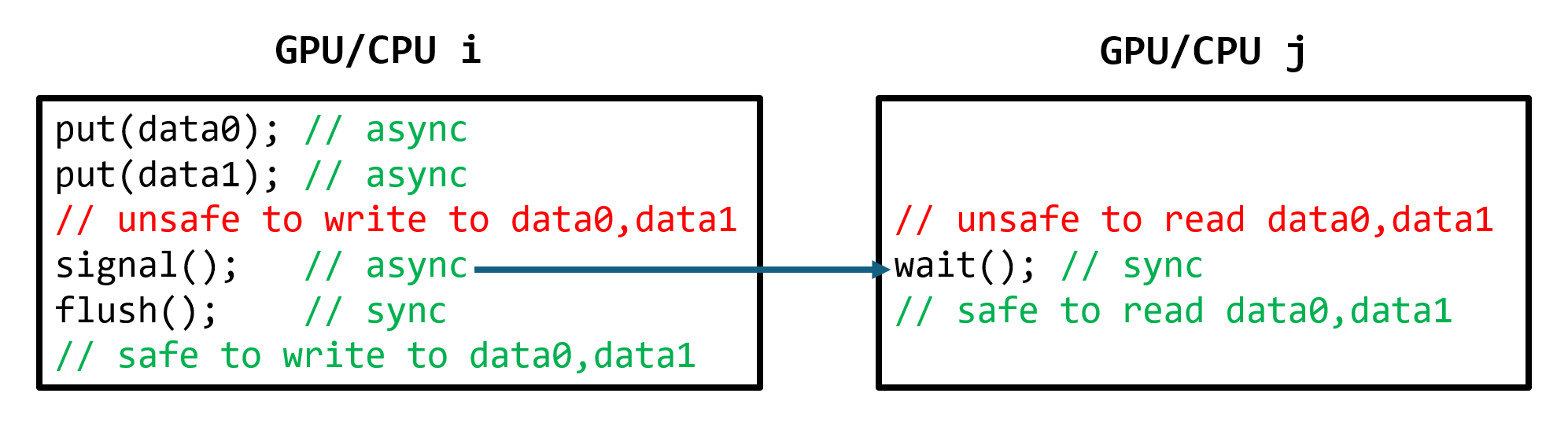
1-sided 0-copy synchronous and asynchronous abstracts. MSCCL++ provides fine-grained synchronous and asynchronous 0-copy 1-sided abstracts for communication primitives such as
put(),get(),signal(),flush(), andwait(). The 1-sided abstractions allows a user to asynchronouslyput()their data on the remote GPU as soon as it is ready without requiring the remote side to issue any receive instruction. This enables users to easily implement flexible communication logics, such as overlapping communication with computation, or implementing customized collective communication algorithms without worrying about potential deadlocks. Additionally, the 0-copy capability enables MSCCL++ to directly transfer data between user’s buffers without using intermediate internal buffers which saves GPU bandwidth and memory capacity.Unified abstractions for different interconnection hardware. MSCCL++ provides consistent abstractions regardless of the location of the remote GPU (either on the local node or on a remote node) or the underlying link (either NVLink/xGMI or InfiniBand). This simplifies the code for inter-GPU communication, which is often complex due to memory ordering of GPU/CPU read/writes and therefore, is error-prone.
Concepts
To implement the list of features above, some concepts are introduced.
Channel
MSCCL++ provides peer-to-peer communication methods between GPUs. A peer-to-peer connection between two GPUs is called a Channel. Channels are constructed by MSCCL++ host-side interfaces and copied to GPUs during initialization. Channels provide GPU-side interfaces, which means that all communication methods are defined as a device function to be called from a GPU kernel code. Following code shows the basic usage for channel, the put() method in the following code copies 1KB data from the local GPU to a remote GPU.
__global__ void gpuKernel() {
...
// Only one thread is needed for this method.
channel.put(/*dstOffset=*/ 0, /*srcOffset=*/ 0, /*size=*/ 1024);
...
}
MSCCL++ also provides efficient synchronization methods, signal(), flush(), and wait(). We will discuss these methods in the following sections.
MemoryChannel & PortChannel
MSCCL++ delivers two types of channels, PortChannel and MemoryChannel. PortChannel provides port-mapping-based data copy and synchronization methods. When called, these methods send/receive a signal to/from a host-side proxy, which will trigger (R)DMA (such as cudaMemcpy* or ibv_post_send) or issue synchronization methods (such as cudaStreamSynchronize or ibv_poll_cq). Since the key functionalities are run by the proxy, PortChannel requires only a single GPU thread to call its methods. See all PortChannel methods from here.
On the other hand, MemoryChannel provides memory-mapping-based copy and synchronization methods. When called, these methods will directly use GPU threads to read/write from/to the remote GPU’s memory space. Comparing against PortChannel, MemoryChannel is especially performant for low-latency scenarios, while it may need many GPU threads to call copying methods at the same time to achieve high copying bandwidth. See all MemoryChannel methods from here.
Fifo & Trigger
One of the key features of MSCCL++ is to offload the communication logic from the GPU to the CPU.
To offload the communication logic from the GPU to the CPU, MSCCL++ introduces the concept of Fifo and Trigger. A Fifo is a circular buffer that shared between the GPU and the CPU. It is used to store Trigger. A Trigger is a signal that is sent from the GPU to the CPU to notify the CPU that there are commands in the Fifo that need to be processed. The CPU will then process the commands in the Fifo and send a signal back to the GPU to notify the GPU that the commands have been processed. The implementation details of Fifo and Trigger can be found in following sections.
ProxyService
Proxy service is a persistent service that resides in the CPU side. It functions as a polling service that receives the message Trigger from the GPU side and then transfers data according to the command. When we use PortChannel for communication, a Trigger is sent from the GPU side to the ProxyService. Then ProxyService will invoke cudaMemcpy* or IB verbs to transfer data to the targe device.
Implementation
The core of MSCCL++ is implemented in C++ and CUDA. We offer both C++ and Python APIs for initializing communication channels. For interactions within the GPU kernel, we offer a collection of low-level device functions. Subsequent sections will delve into these interfaces and the methodology for transferring communication logic from the GPU to the CPU.
Interfaces
This section delivers a comprehensive overview of the MSCCL++ interfaces, encompassing both the setup and initialization of communication channels and the MSCCL++ kernel programming model.
Communication setup and initialization APIs
MSCCL++ provides APIs in both C++ and Python for establishing communication channels, with further information available in the Initialization section. Presently, it supports two types of transports: cudaIPC for NVLink/xGMI, and IB for InfiniBand. Users are empowered to select the connection type that best suits their hardware infrastructure.
MSCCL++ kernel programming model
MSCCL++ offers one-sided communication methods directly callable from a GPU kernel, encompassing two primary API categories: data copy and synchronization. The data copy API features functions such as put(), get(), read(), and write(), while the synchronization API comprises signal(), flush(), and wait(). Demonstrated below, the basic utilization of the data copy API involves the put() method, which facilitates the transfer of 1KB of data from a local GPU to a remote GPU. Then send a signal to remote peer to notify the data is ready to use. To receive the data, the remote peer can call wait() method.
This operation is executed within a kernel launched with a single block.
// Running on rank 0
__device__ void gpuKernel(mscclpp::MemoryChannelDeviceHandle* memoryChannel) {
memoryChannel[0].put(/*dstOffset=*/ 0, /*srcOffset=*/ 0, /*size=*/ 1024, /*threadId*/ threadIdx.x, /*numThreads*/ blockDim.x);
__syncthreads();
if (threadIdx.x == 0) {
memoryChannel[0].signal();
}
}
// Running on rank 1
__device__ void gpuKernel(mscclpp::MemoryChannelDeviceHandle* memoryChannel) {
if (threadIdx.x == 0) {
memoryChannel[0].wait();
}
__syncthreads();
// Data is ready to use
}
Similar to the LL protocol offered by NCCL, MSCCL++ introduces a Packet structure designed to facilitate the transfer of both data and flags within a single instruction, proving particularly beneficial for applications where latency is a critical concern. The following code shows the basic usage of the Packet structure. The flag should be same for sender and receiver side.
// Running on rank 0
__device__ void gpuKernel(mscclpp::MemoryChannelDeviceHandle* memChans, int flag) {
memChans[0].putPackets(/*dstOffset=*/ 0, /*srcOffset=*/ 0, /*size=*/ 1024, /*threadId*/ threadIdx.x, /*numThreads*/ blockDim.x,
/*flag=*/ flag);
}
// Running on rank 1
__device__ void gpuKernel(mscclpp::MemoryChannelDeviceHandle* memChans, int flag) {
memChans[0].getPackets(/*dstOffset=*/ 0, /*srcOffset=*/ 0, /*size=*/ 1024, /*threadId*/ threadIdx.x, /*numThreads*/ blockDim.x,
/*flag=*/ flag);
// Data is ready to use
}
The mechanism for offloading communication logic from the GPU to the CPU
As mentioned in the previous section, the offloading of communication logic from the GPU to the CPU is accomplished through the Fifo and Trigger mechanism.
The accompanying figure details the structure of Tigger, employing three bits to denote the operation type: data transfer, signal, and flush. The remaining fields specify the precise data locations for both local and remote buffers.
|-------------------|-------------------|-------------------|-----------------|-----------------|---------|-------------------|---------------|
| 32bit size | 32bit src offset | 32bit dst offset | 9bit src mem id | 9bit dst mem id | 3bit op | 10bit channel id | 1bit reserved |
|-------------------|-------------------|-------------------|-----------------|-----------------|---------|-------------------|---------------|
Page-locked memory is utilized for the Fifo, guaranteeing access by both the CPU and GPU. On the CPU side, a polling thread periodically checks the Fifo for new commands. Upon processing a command, it updates an incremented counter to signal to the GPU that the command has been executed. Users wishing to ensure a command has been processed can invoke flush(), which waits for the device-side counter to reflect this update.
Use Cases
In this section, we will discuss several use cases that demonstrate the capabilities of MSCCL++.
Overlapping communication with computation
MSCCL++ enables the offloading of communication logic from the GPU to the CPU, facilitating the overlapping of communication and computation processes. The code snippet provided illustrates this overlapping technique. In the depicted scenario, the GPU emits a signal to the CPU indicating readiness for data transfer. Subsequently, while the GPU continues to execute computation tasks, the CPU initiates the data transfer to the designated target device.
__device__ void gpuKernel(mscclpp::PortChannelDeviceHandle* portChannel) {
int tid = threadIdx.x + blockIdx.x * blockDim.x;
// Send a trigger to the CPU
if (tid == 0) {
portChannel[0].putWithSignal(/*dstOffset*/ 0, /*srcOffset*/ 0, /*size*/ 1024);
}
// Continue computation
matrixMul()
// ...
}
Fusion of communication and computation
Traditional communication libraries enforce a separation between communication and computation, creating a bottleneck where communication must await the completion of computation, especially when data dependencies exist. In contrast, MSCCL++ leverages its low-level premitives to facilitate the seamless integration of communication with computation. By segmenting the computation into tiles, MSCCL++ enables the simultaneous pipelining of computation and communication tasks. This approach not only mitigates the communication delay by overlapping processes but also significantly improves throughput by leveraging the low-level API for fine-grained control over the hardware, ensuring optimal efficiency.
Implementing customized collective communication algorithms
MCSCL++ offers a low-level communication API, allowing users to design customized collective communication algorithms. The following code demonstrates how to implement a customized All2All algorithm using MSCCL++.
using DeviceHandle = mscclpp::DeviceHandle<T>;
__device__ void localAlltoall(DeviceHandle<mscclpp::PortChannel>* portChans, int rank,
int nRanksPerNode, size_t nElements) {
int remoteRank = ((int)blockIdx.x < rank) ? blockIdx.x : blockIdx.x + 1;
for (int i = 1; i < nRanksPerNode; i++) {
DeviceHandle<mscclpp::PortChannel> portChan = portChans[blockIdx.x];
if (threadIdx.x == 0 && remoteRank % nRanksPerNode == (rank + i) % nRanksPerNode) {
portChan.putWithSignalAndFlush(rank * nElements * sizeof(int), remoteRank * nElements * sizeof(int),
nElements * sizeof(int));
}
// wait for the data from GPU (rank-i) % nranksPerNode to arrive
if (threadIdx.x == 0 && remoteRank % nRanksPerNode == (rank - i + nRanksPerNode) % nRanksPerNode) {
portChan.wait();
}
deviceSyncer.sync(nRanksPerNode - 1);
}
}