OCR-NER Dataset Generation
OCR-NER Dataset Generation¶
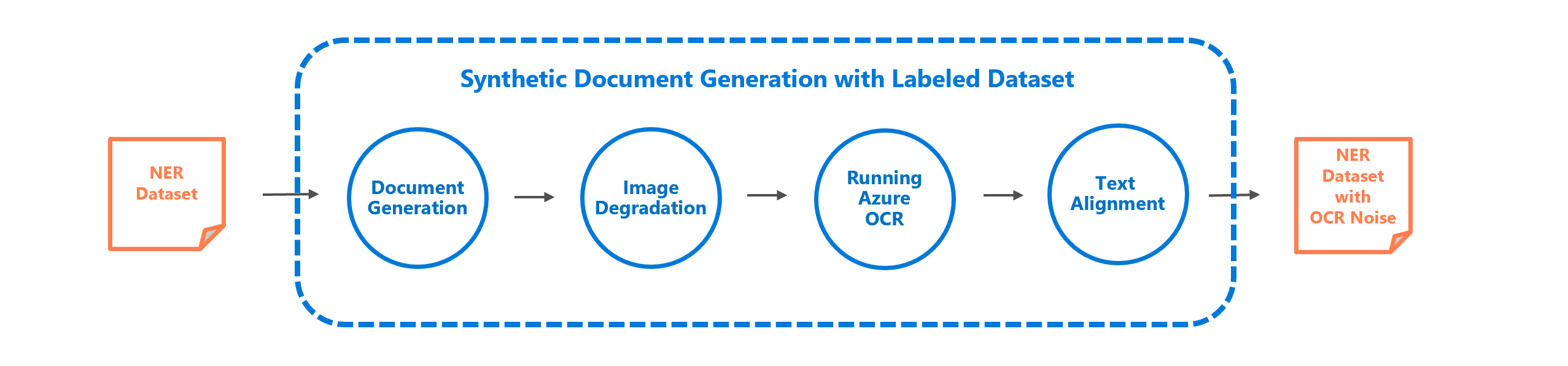
If you were brought here by our paper, you may be interested in the data preparation pipeline built with genalog. The figure above shows the steps involved in tranforming a Named-Entity Recognition (NER) dataset like CoNLL 2003 with synthetic Optical Character Recognition (OCR) errors. This OCR-NER dataset is useful to train an error-prune NER model against common OCR mistakes. You can find the full dataset prepration pipeline in this notebook from our repo.
We believe this methodology of inducing OCR errors onto the dataset can be applied to other NLP tasks to improve model performance against inherent noise from OCR outputs. We welcome the community to contribute if this fits your use cases.