For the Data Scientist - Develop with R
This solution package shows how to pre-process data (cleaning and feature engineering), train prediction models, and perform scoring on the SQL Server machine using either R or Python code.
Data scientists who are testing and developing solutions can work from the convenience of their preferred IDE on their client machine, while setting the computation context to SQL (see R or Python folder for code). They can also deploy the completed solutions to SQL Server 2017 by embedding calls to R or Python in stored procedures (see SQLR or SQLPy folder for code). These solutions can then be further automated by the use of SQL Server Integration Services and SQL Server agent: a PowerShell script (.ps1 file) automates the running of the SQL code.
Predicting Hospital Length of Stay
In order for hospitals to optimize resource allocation, it is important to predict accurately how long a newly admitted patient will stay in the hospital.
In this template, we implemented all steps in SQL stored procedures: data preprocessing, and feature engineering are implemented in pure SQL, while data cleaning, and the model training, scoring and evaluation steps are implemented with SQL stored procedures calling either R (Microsoft R Server) or Python code.
All these steps can be executed in an R or Python IDE, and are also presented in R/Python Jupyter notebooks.
Among the key variables to learn from data are number of previous admissions as well as various diagnostic codes and lab results. (View the full data set description. )
In this template, the final scored data is stored in SQL Server - (Boosted_Prediction) model. This data is then visualized in PowerBI.
To try this out yourself, see the Quick Start section on the main page.
This page describes what happens in each of the steps: dataset creation, model development, prediction, and deployment in more detail.
System Requirements
To run the scripts requires the following:
- for R: SQL Server 2016 with Microsoft R Server (version 9.0.1) or higher installed and configured
- for Python: SQL Server 2017 with Machine Learning Services (In-Database) installed and configured
- The SQL user name and password, and the user configured properly to execute R scripts in-memory;
- SQL Database which the user has write permission and execute stored procedures;
- For more information about Machine Learning Services in SQL Server, please visit: https://msdn.microsoft.com/en-us/library/mt604847.aspx
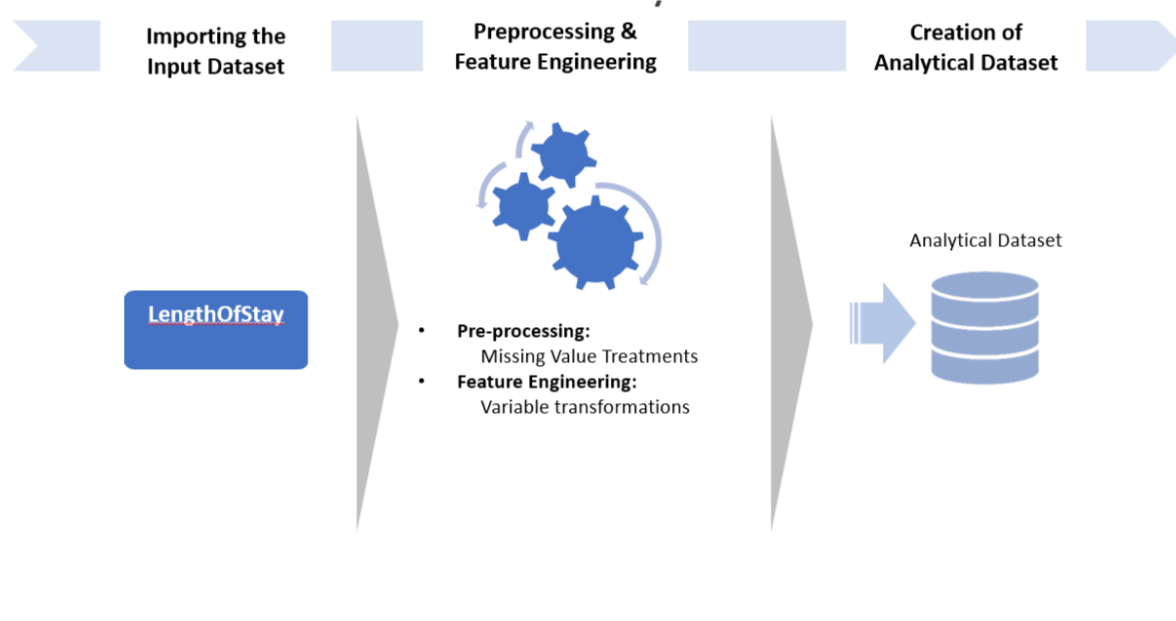
Step1: Pre-Processing and Cleaning
In this step, the raw data is loaded into SQL in a table called LengthOfStay. Then, if there are missing values, the data is cleaned in-place. This assumes that the ID variable (eid) does not contain blanks.
There are two ways to replace missing values:
-
The first provided function,
fill_NA_explicit, will replace the missing values with “missing” (character variables) or -1 (numeric variables). It should be used if it is important to know where the missing values were. -
The second function,
fill_NA_mode_mean, will replace the missing values with the mode (categorical variables) or mean (float variables).
The user can run the one he prefers.
Input:
- Raw data LengthOfStay.csv.
Output:
- A SQL Table
LengthOfStay, with missing values replaced.
Related files:
- R: step1_data_preprocessing.R
- Python: step1_data_preprocessing.Py
Step2: Feature Engineering
In this step, we design new features:
- The continuous laboratory measurements (e.g.
hemo,hematocritic,sodium,glucoseetc.) are standardized: we substract the mean and divide by the standard deviation. number_of_issues: the total number of preidentified medical conditions.
Input:
LengthOfStaytable.
Output:
LoStable containing new features.
Related files:
- R: step2_feature_engineering.R
- Python: step2_feature_engineering.py
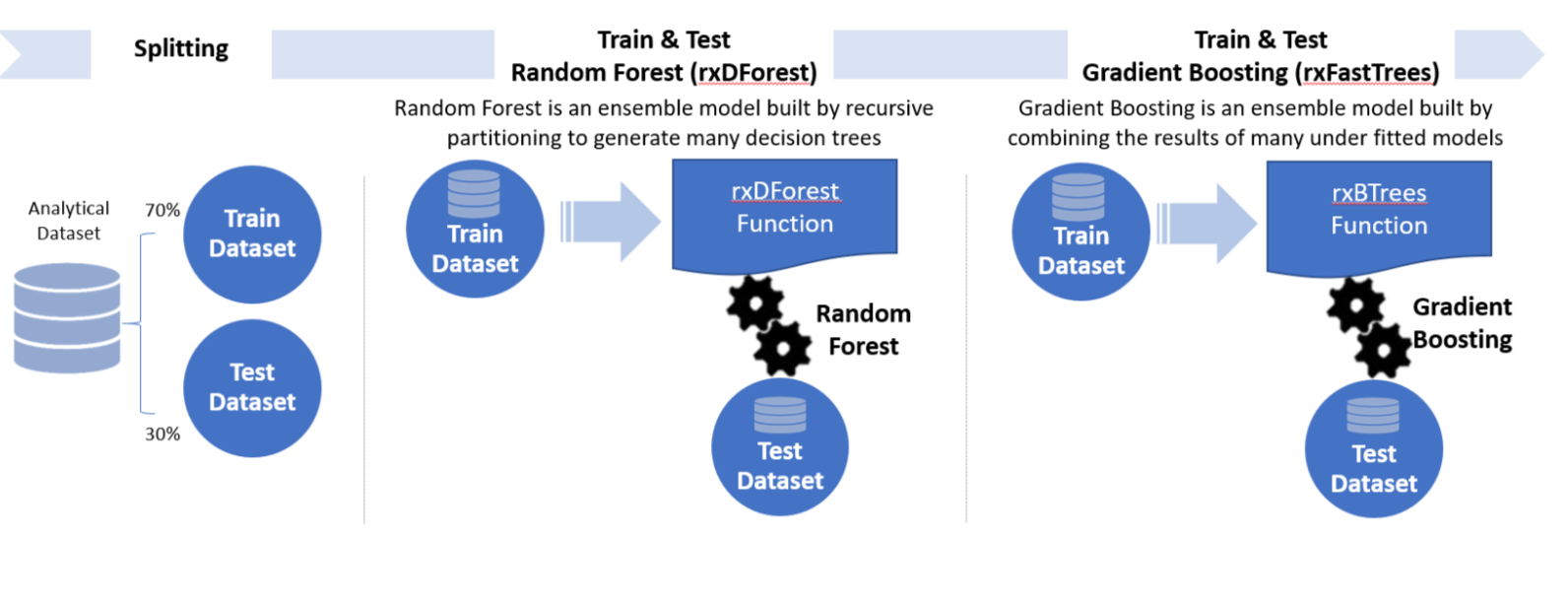
Step3: Splitting, Training, Testing and Evaluating (Regression)
In this step, we split the data into a training set and a testing set. The user has to specify a splitting percentage. For example, if the splitting percentage is 70, 70% of the data will be put in the training set, while the other 30% will be assigned to the testing set. The eid that will end in the training set are stored in the table Train_Id. Then we train a regression Random Forest (rxDForest in R, rx_dforest in Python) and a gradient boosted trees model (rxFastTrees in R, rx_btrees in Python) on the training set. The trained models are uploaded to SQL if needed later. Finally, we score the trained models on the testing set, and then compute regression performance metrics.
Input:
LoStable.
Output:
- Performance metrics and trained models.
Related files:
- R: step3_training_evaluation.R
- Python: step3_training_evaluation.py
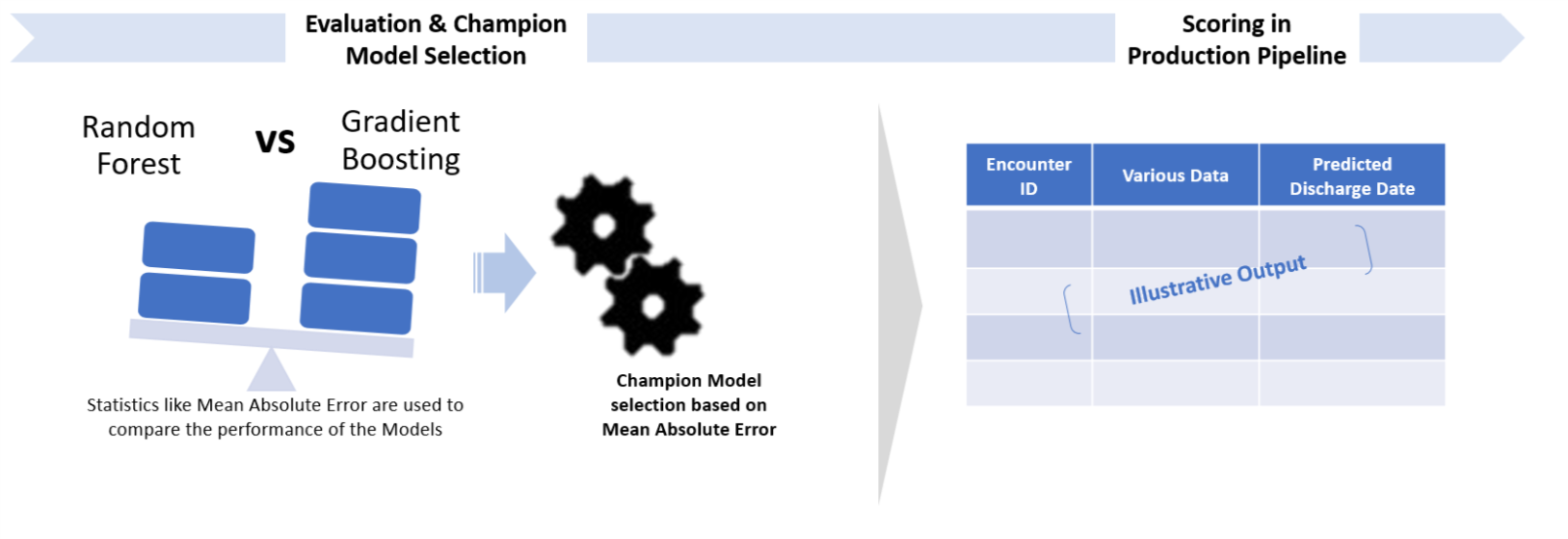
Step 4: Deploy and Visualize Results
See For the Business Manager for a description of the personas who will be interested in using these predictions to aid them in their jobs.
Explore the online version of the dashboard.
Template Contents
View the contents of this solution template.
To try this out yourself:
- View the Quick Start.
