Libraries / Interoperability Guidelines
Types are Send (M-TYPES-SEND)
Public types should be Send for compatibility reasons:
- All futures produced (explicitly or implicitly) must be
Send - Most other types should be
Send, but there might be exceptions
Futures
When declaring a future explicitly you should ensure it is, and remains, Send.
#![allow(unused)] fn main() { use std::future::Future; use std::pin::Pin; use std::task::{Context, Poll}; struct Foo {} impl Future for Foo { // Explicit implementation of `Future` for your type type Output = (); fn poll(self: Pin<&mut Self>, _: &mut Context<'_>) -> Poll<<Self as Future>::Output> { todo!() } } // You should assert your type is `Send` const fn assert_send<T: Send>() {} const _: () = assert_send::<Foo>(); }
When returning futures implicitly through async method calls, you should make sure these are Send too.
You do not have to test every single method, but you should at least validate your main entry points.
#![allow(unused)] fn main() { async fn foo() { } // TODO: We want this as a macro as well fn assert_send<T: Send>(_: T) {} _ = assert_send(foo()); }
Regular Types
Most regular types should be Send, as they otherwise infect futures turning them !Send if held across .await points.
#![allow(unused)] fn main() { use std::rc::Rc; async fn read_file(x: &str) {} async fn foo() { let rc = Rc::new(123); // <-- Holding this across an .await point prevents read_file("foo.txt").await; // the future from being `Send`. dbg!(rc); } }
That said, if the default use of your type is instantaneous, and there is no reason for it to be otherwise held across .await boundaries, it may be !Send.
#![allow(unused)] fn main() { use std::rc::Rc; struct Telemetry; impl Telemetry { fn ping(&self, _: u32) {} } fn telemetry() -> Telemetry { Telemetry } async fn read_file(x: &str) {} async fn foo() { // Here a hypothetical instance Telemetry is summoned // and used ad-hoc. It may be ok for Telemetry to be !Send. telemetry().ping(0); read_file("foo.txt").await; telemetry().ping(1); } }
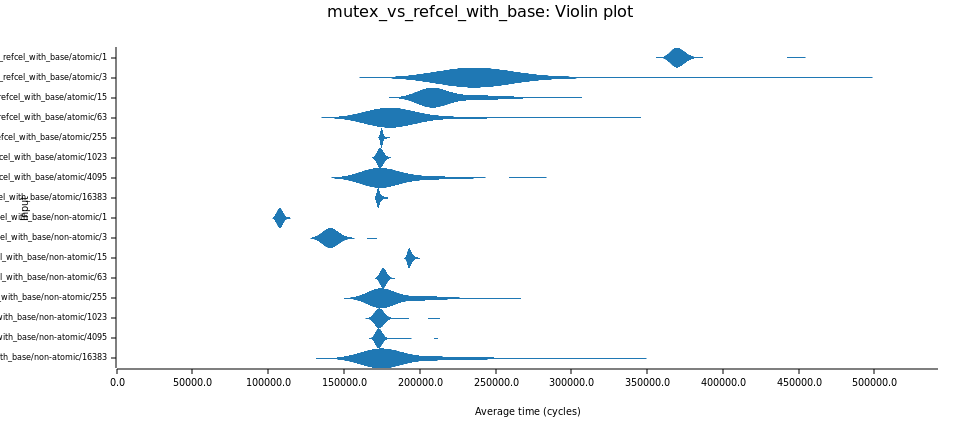
The Cost of Send Ideally, there would be abstractions that are
Sendin work-stealing runtimes, and!Sendin thread-per-core models based on non-atomic types likeRcandRefCellinstead.Practically these abstractions don't exist, preventing Tokio compatibility in the non-atomic case. That in turn means you would have to "reinvent the world" to get anything done in a thread-per-core universe.
The good news is, in most cases atomics and uncontended locks only have a measurable impact if accessed more frequently than every 64 words or so.
Working with a large
Vec<AtomicUsize>in a hot loop is a bad idea, but doing the occasional uncontended atomic operation from otherwise thread-per-core async code has no performance impact, but gives you widespread ecosystem compatibility.
Native escape hatches (M-ESCAPE-HATCHES)
Types wrapping native handles should provide unsafe escape hatches. In interop scenarios your users might have gotten a native handle from somewhere
else, or they might have to pass your wrapped handle over FFI. To enable these use cases you should provide unsafe conversion methods.
#![allow(unused)] fn main() { type HNATIVE = *const u8; pub struct Handle(HNATIVE); impl Handle { pub fn new() -> Self { // Safely creates handle via API calls todo!() } // Constructs a new Handle from a native handle the user got elsewhere. // This method should then also document all safety requirements that // must be fulfilled. pub unsafe fn from_native(native: HNATIVE) -> Self { Self(native) } // Various extra methods to permanently or temporarily obtain // a native handle. pub fn into_native(self) -> HNATIVE { self.0 } pub fn to_native(&self) -> HNATIVE { self.0 } } }
Don't leak external types (M-DONT-LEAK-TYPES)
Where possible, you should prefer std1 types in public APIs over types coming from external crates. Exceptions should be carefully considered.
Any type in any public API will become part of that API's contract. Since std and constituents are the only crates
shipped by default, and since they come with a permanent stability guarantee, their types are the only ones that come without an interoperability risk.
A crate that exposes another crate's type is said to leak that type.
For maximal long term stability your crate should, theoretically, not leak any types. Practically, some leakage is unavoidable, sometimes even beneficial. We recommend you follow this heuristic:
- if you can avoid it, do not leak third-party types
- if you are part of an umbrella crate,2 you may freely leak types from sibling crates.
-
behind a relevant feature flag, types may be leaked (e.g.,
serde) - without a feature only if they give a substantial benefit. Most commonly that is interoperability with significant other parts of the Rust ecosystem based around these types.
1 In rare instances, e.g., high performance libraries used from embedded, you might even want to limit yourself to core only.
2 For example, a runtime crate might be the umbrella of runtime_rt, runtime_app and runtime_clock As users are
expected to only interact with the umbrella, siblings may leak each others types.
Items come from their original crate (M-FOREIGN-REEXPORTS)
Crates should generally not re-export items from other crates. For example, if your crate contains a method foo::download(url: bar::Url), you should not do pub use bar::Url from inside foo. This avoids having possibly dozens of aliases in context, which can get confusing for both users and agents, in particular if these are mixed with genuinely different types of the same name from other crates.
When a crate accepts or returns a type defined in some third-party crate, users are expected to depend on that third-party crate directly and import the type from there. That said, there are a few valid exceptions to this rule:
- Umbrella crates (compare M-DONT-LEAK-TYPES) by definition re-export other types
- Crates split for technical reasons (e.g., exporting
foo_core::Urlfromfoo) - Macro use to provide stable paths, e.g., via some hidden
foo::__private::Url
Accept impl AsRef<> where feasible (M-IMPL-ASREF)
In function signatures, accept impl AsRef<T> for types that have a
clear reference hierarchy, where you
do not need to take ownership, or where object creation is relatively cheap.
| Instead of ... | accept ... |
|---|---|
&str, String | impl AsRef<str> |
&Path, PathBuf | impl AsRef<Path> |
&[u8], Vec<u8> | impl AsRef<[u8]> |
use std::path::Path;
// Definitely use `AsRef`, the function does not need ownership.
fn print(x: impl AsRef<str>) {}
fn read_file(x: impl AsRef<Path>) {}
fn send_network(x: impl AsRef<[u8]>) {}
// Further analysis needed. In these cases the function wants
// ownership of some `String` or `Vec<u8>`. If those are
// "low freqency, low volume" functions `AsRef` has better ergonomics,
// otherwise accepting a `String` or `Vec<u8>` will have better
// performance.
fn new_instance(x: impl AsRef<str>) -> HoldsString {}
fn send_to_other_thread(x: impl AsRef<[u8]>) {}In contrast, types should generally not be infected by these bounds:
// Generally not ok. There might be exceptions for performance
// reasons, but those should not be user visible.
struct User<T: AsRef<str>> {
name: T
}
// Better
struct User {
name: String
}
Accept impl RangeBounds<> where feasible (M-IMPL-RANGEBOUNDS)
Functions that accept a range of numbers must use a Range type or trait over hand-rolled parameters:
// Bad
fn select_range(low: usize, high: usize) {}
fn select_range(range: (usize, usize)) {}In addition, functions that can work on arbitrary ranges, should accept impl RangeBounds<T> rather than Range<T>.
#![allow(unused)] fn main() { use std::ops::{RangeBounds, Range}; // Callers must call with `select_range(1..3)` fn select_range(r: Range<usize>) {} // Callers may call as // select_any(1..3) // select_any(1..) // select_any(..) fn select_any(r: impl RangeBounds<usize>) {} }
Accept impl 'IO' where feasible ('sans IO') (M-IMPL-IO)
Functions and types that only need to perform one-shot I/O during initialization should be written "sans-io",
and accept some impl T, where T is the appropriate I/O trait, effectively outsourcing I/O work to another type:
// Bad, caller must provide a File to parse the given data. If this
// data comes from the network, it'd have to be written to disk first.
fn parse_data(file: File) {}#![allow(unused)] fn main() { // Much better, accepts // - Files, // - TcpStreams, // - Stdin, // - &[u8], // - UnixStreams, // ... and many more. fn parse_data(data: impl std::io::Read) {} }
Synchronous functions should use std::io::Read and
std::io::Write. Asynchronous functions targeting more than one runtime should use
futures::io::AsyncRead and similar.
Types that need to perform runtime-specific, continuous I/O should follow M-RUNTIME-ABSTRACTED instead.