About
A collection of pragmatic design guidelines helping application and library developers to produce idiomatic Rust that scales.
Version: 2026.6
Meta Design Principles
We build on existing high-quality guidelines, most notably the Rust API Guidelines, addressing topics often encountered by Rust developers. For a guideline to make it into this book, we expect it to meet the following criteria:
-
It positively affects { safety, COGs, maintenance }; i.e., it must where applicable
- promote safety best-practices and prevent sources of risk
- lead to high throughput, low latency, and low memory usage
- make code readable and understandable
- A majority of experienced (3+ years) Rust developers would agree with the guideline.
- The guideline is reasonably comprehensible to Rust novices (4+ weeks).
- It is pragmatic, as unrealistic guidelines won't be followed.
Applicability
Guidelines declared must are supposed to always hold, where should guidelines indicate more flexibility.
That said, teams are free to adopt these guidelines as they see fit, and you occasionally might have good reasons to do things differently.
We recommend you try to apply all items to your project. If an item does not make sense, get in touch. Either the item has issues and we should update it, or it does not apply (and we might update it anyway to point these edge cases out).
The Golden Rule Each item here exists for a reason; and it is the spirit that counts, not the letter.
Before attempting to work around a guideline, you should understand why it exists and what it tries to safeguard. Likewise, you should not blindly follow a guideline if it becomes apparent that doing so would violate its underlying motivation!
Submitting New Guidelines
Do you have a practical guideline that leads to better safety, COGS or maintainability? We'd love to hear from you! Here is the process you should follow:
- Check if your guideline follows the meta design principles above.
- Check if your suggestion is not already covered by the API Guidelines or Clippy.
- File a PR or issue.
Checklist
- Universal
- Follow the upstream guidelines (M-UPSTREAM-GUIDELINES)
- Use static verification (M-STATIC-VERIFICATION)
-
Lint overrides should use
#[expect](M-LINT-OVERRIDE-EXPECT) - Public types are Debug (M-PUBLIC-DEBUG)
- Public types meant to be read are Display (M-PUBLIC-DISPLAY)
- If in doubt, split the crate (M-SMALLER-CRATES)
- Names are free of weasel words (M-WEASEL-WORDS)
- Names of items are short (M-SHORT-NAMES)
- Prefer regular over associated functions (M-REGULAR-FN)
- Magic values are documented (M-DOCUMENTED-MAGIC)
- Use structured logging with message templates (M-LOG-STRUCTURED)
- Library / Interoperability
- Types are Send (M-TYPES-SEND)
- Native escape hatches (M-ESCAPE-HATCHES)
- Don't leak external types (M-DONT-LEAK-TYPES)
- Items come from their original crate (M-FOREIGN-REEXPORTS)
-
Accept
impl AsRef<>where feasible (M-IMPL-ASREF) -
Accept
impl RangeBounds<>where feasible (M-IMPL-RANGEBOUNDS) -
Accept
impl 'IO'where feasible ('sans IO') (M-IMPL-IO)
- Library / UX
- Abstractions don't visibly nest (M-SIMPLE-ABSTRACTIONS)
- Avoid smart pointers and wrappers in APIs (M-AVOID-WRAPPERS)
- Prefer types over generics, generics over dyn traits (M-DI-HIERARCHY)
- Errors are canonical structs (M-ERRORS-CANONICAL-STRUCTS)
-
Canonical error conversion uses
From, notmap_err(M-FROM-ERROR) - Complex type construction has builders (M-INIT-BUILDER)
- Complex type initialization hierarchies are cascaded (M-INIT-CASCADED)
- Services are Clone (M-SERVICES-CLONE)
- Essential functionality should be inherent (M-ESSENTIAL-FN-INHERENT)
- Modules are balanced in size and scope (M-BALANCED-MODULES)
- Don't define preludes (M-NO-PRELUDE)
- Parameter ordering is consistent (M-PARAMETER-CONSISTENCY)
- Collections implement the appropriate iter traits (M-COLLECTION-TRAITS)
-
Functions are
asyncover returning a Future (M-ASYNC-FN)
- Library / Resilience
- I/O and system calls are mockable (M-MOCKABLE-SYSCALLS)
- Test utilities are feature gated (M-TEST-UTIL)
-
Integration tests live under
tests/(M-INTEGRATION-TESTS) - Use the proper type family (M-STRONG-TYPES)
- Newtypes guard their invariants (M-STRONG-TYPES-GUARD)
-
Builders validate in final
.build()(M-BUILD-RESULT) - Don't glob re-export items (M-NO-GLOB-REEXPORTS)
- Avoid statics (M-AVOID-STATICS)
- Production code uses telemetry, not println (M-LOG-NOT-PRINT)
- Library / Building
- Libraries work out of the box (M-OOBE)
-
Native
-syscrates compile without dependencies (M-SYS-CRATES) - Features are additive (M-FEATURES-ADDITIVE)
- Macros
- Macros are a last resort (M-MACRO-LAST-RESORT)
- Prefer 'macros by example' over proc macros (M-EXAMPLE-OVER-PROC)
- Macros don't lie about signatures (M-MACROS-DONT-LIE)
- Macros assume main crate (M-MACRO-MAIN-CRATE)
-
Third party items come from hidden
_privatemodule (M-MACRO-HELPERS) - Proc macros should have separate impl crate incl. tests (M-PROC-IMPL)
- Proc macros don't produce implied or hidden items (M-PROC-IMPLIED-ITEMS)
- Applications
- Use mimalloc for apps (M-MIMALLOC-APPS)
- Applications may use Anyhow or derivatives (M-APP-ERROR)
- Applications target highest viable target-cpu (M-TARGET-CPU)
- FFI
- Isolate DLL state between FFI libraries (M-ISOLATE-DLL-STATE)
- Business logic belongs in core crates, FFI only translates (M-FFI-TRANSLATES)
- FFI crates follow established naming conventions (M-FFI-NAMING)
- Correctness
- Unsafe needs reason, should be avoided (M-UNSAFE)
- Unsafe implies undefined behavior (M-UNSAFE-IMPLIES-UB)
- All code must be sound (M-UNSOUND)
- Panic means 'stop the program' (M-PANIC-IS-STOP)
- Detected programming bugs are panics, not errors (M-PANIC-ON-BUG)
- Panic continuation is last resort (M-PANIC-CONTINUATION)
- Custom panics have a helpful message (M-PANIC-MESSAGE)
- Performance
- Optimize for throughput, avoid empty cycles (M-THROUGHPUT)
- Identify, profile, optimize the hot path early (M-HOTPATH)
- Long-running tasks should have yield points (M-YIELD-POINTS)
- Reuse allocations where possible (M-MEM-REUSE)
- Library telemetry does not tank performance (M-LOG-OVERHEAD)
- Nested type hierarchies should avoid needless indirection (M-AVOID-INDIRECTION)
- Use boxed slices and strings for immutable owned sequences (M-BOX-DST)
- Shrink collections to fit after building (M-SHRINK-TO-FIT)
- Use a fast hasher where possible (M-FAST-HASHER)
- Collections are created with sufficient initial capacity (M-INITIAL-CAPACITY)
-
Hot
asyncfunctions reduce stack size (M-ASYNC-STACK-SIZE)
- Project
- Common settings come from the workspace Cargo.toml (M-CARGO-WORKSPACE)
- The workspace lists and versions all crates (M-CRATES-IN-WORKSPACE)
- All crates are siblings in one folder (M-CRATES-FLAT-FOLDER)
- New crates target latest edition (M-LATEST-EDITION)
- MSRV is conservatively updated (M-MSRV)
- Documentation
- First sentence is one line; approx. 15 words (M-FIRST-DOC-SENTENCE)
- Has comprehensive module documentation (M-MODULE-DOCS)
- Documentation has canonical sections (M-CANONICAL-DOCS)
-
Mark
pub useitems with#[doc(inline)](M-DOC-INLINE)
- AI
- Design with AI use in mind (M-DESIGN-FOR-AI)
- Items are only visible through one path (M-SINGLE-ITEM-PATH)
- Avoid meta design documentation (M-NO-META-DESIGN-DOCUMENTATION)
- Tests do not assert ground truth (M-TAUTOLOGICAL-TESTS)
- Rust code solves Rust problems (M-RUST-SHAPED)
Universal Guidelines
Follow the upstream guidelines (M-UPSTREAM-GUIDELINES)
The guidelines in this book complement existing Rust guidelines, in particular:
We recommend you read through these as well, and apply them in addition to this book's items. Pay special attention to the ones below, as they are frequently forgotten:
-
C-CONV - Ad-hoc conversions
follow
as_,to_,into_conventions - C-GETTER - Getter names follow Rust convention
-
C-COMMON-TRAITS - Types eagerly implement common traits
Copy,Clone,Eq,PartialEq,Ord,PartialOrd,Hash,Default,DebugDisplaywhere type wants to be displayed
-
C-CTOR -
Constructors are static, inherent methods
- In particular, have
Foo::new(), even if you haveFoo::default()
- In particular, have
- C-FEATURE - Feature names are free of placeholder words
Use static verification (M-STATIC-VERIFICATION)
Projects should use the following static verification tools to help maintain the quality of the code. These tools can be configured to run on a developer's machine during normal work, and should be used as part of check-in gates.
- compiler lints offer many lints to avoid bugs and improve code quality.
- clippy lints contain hundreds of lints to avoid bugs and improve code quality.
- rustfmt ensures consistent source formatting.
- cargo-audit verifies crate dependencies for security vulnerabilities.
- cargo-hack validates that all combinations of crate features work correctly.
- cargo-udeps detects unused dependencies in Cargo.toml files.
- miri validates the correctness of unsafe code.
Compiler Lints
The Rust compiler generally produces exceptionally good diagnostics. In addition to the default set of diagnostics, projects should explicitly enable the following set of compiler lints:
[lints.rust]
ambiguous_negative_literals = "warn"
missing_debug_implementations = "warn"
redundant_imports = "warn"
redundant_lifetimes = "warn"
trivial_numeric_casts = "warn"
unsafe_op_in_unsafe_fn = "warn"
unused_lifetimes = "warn"
Clippy Lints
For clippy, projects should enable all major lint categories, and additionally enable some lints from the restriction lint group.
Undesired lints (e.g., numeric casts) can be opted back out of on a case-by-case basis:
[lints.clippy]
cargo = { level = "warn", priority = -1 }
complexity = { level = "warn", priority = -1 }
correctness = { level = "warn", priority = -1 }
pedantic = { level = "warn", priority = -1 }
perf = { level = "warn", priority = -1 }
style = { level = "warn", priority = -1 }
suspicious = { level = "warn", priority = -1 }
# nursery = { level = "warn", priority = -1 } # optional, might cause more false positives
# These lints are from the `restriction` lint group and prevent specific
# constructs being used in source code in order to drive up consistency,
# quality, and brevity
allow_attributes_without_reason = "warn"
as_pointer_underscore = "warn"
assertions_on_result_states = "warn"
clone_on_ref_ptr = "warn"
deref_by_slicing = "warn"
disallowed_script_idents = "warn"
empty_drop = "warn"
empty_enum_variants_with_brackets = "warn"
empty_structs_with_brackets = "warn"
fn_to_numeric_cast_any = "warn"
if_then_some_else_none = "warn"
map_err_ignore = "warn"
redundant_type_annotations = "warn"
renamed_function_params = "warn"
semicolon_outside_block = "warn"
string_to_string = "warn"
undocumented_unsafe_blocks = "warn"
unnecessary_safety_comment = "warn"
unnecessary_safety_doc = "warn"
unneeded_field_pattern = "warn"
unused_result_ok = "warn"
# May cause issues with structured logging otherwise.
literal_string_with_formatting_args = "allow"
# Define custom opt outs here
# ...
Lint overrides should use #[expect] (M-LINT-OVERRIDE-EXPECT)
When overriding project-global lints inside a submodule or item, you should do so via #[expect], not #[allow].
Expected lints emit a warning if the marked warning was not encountered, thus preventing the accumulation of stale lints.
That said, #[allow] lints are still useful when applied to generated code, and can appear in macros.
Overrides should be accompanied by a reason:
#![allow(unused)] fn main() { #[expect(clippy::unused_async, reason = "API fixed, will use I/O later")] pub async fn ping_server() { // Stubbed out for now } }
Public types are Debug (M-PUBLIC-DEBUG)
All public types exposed by a crate should implement Debug. Most types can do so via #[derive(Debug)]:
#![allow(unused)] fn main() { #[derive(Debug)] struct Endpoint(String); }
Types designed to hold sensitive data should also implement Debug, but do so via a custom implementation.
This implementation must employ unit tests to ensure sensitive data isn't actually leaked, and will not be in the future.
#![allow(unused)] fn main() { use std::fmt::{Debug, Formatter}; struct UserSecret(String); impl Debug for UserSecret { fn fmt(&self, f: &mut Formatter<'_>) -> std::fmt::Result { write!(f, "UserSecret(...)") } } #[test] fn test() { let key = "552d3454-d0d5-445d-ab9f-ef2ae3a8896a"; let secret = UserSecret(key.to_string()); let rendered = format!("{:?}", secret); assert!(rendered.contains("UserSecret")); assert!(!rendered.contains(key)); } }
Public types meant to be read are Display (M-PUBLIC-DISPLAY)
If your type is expected to be read by upstream consumers, be it developers or end users, it should implement Display. This in particular includes:
- Error types, which are mandated by
std::error::Errorto implementDisplay - Wrappers around string-like data
Implementations of Display should follow Rust customs; this includes rendering newlines and escape sequences.
The handling of sensitive data outlined in M-PUBLIC-DEBUG applies analogously.
If in doubt, split the crate (M-SMALLER-CRATES)
You should err on the side of having too many crates rather than too few, as this leads to dramatic compile time improvements—especially during the development of these crates—and prevents cyclic component dependencies.
Essentially, if a submodule can be used independently, its contents should be moved into a separate crate.
Performing this crate split may cause you to lose access to some pub(crate) fields or methods. In many situations, this is a desirable
side-effect and should prompt you to design more flexible abstractions that would give your users similar affordances.
In some cases, it is desirable to re-join individual crates back into a single umbrella crate, such as when dealing with proc macros, or runtimes.
Functionality split for technical reasons (e.g., a foo_proc proc macro crate) should always be re-exported. Otherwise, re-exports should be used sparingly.
Features vs. Crates As a rule of thumb, crates are for items that can reasonably be used on their own. Features should unlock extra functionality that can't live on its own. In the case of umbrella crates, see below, features may also be used to enable constituents (but then that functionality was extracted into crates already).
For example, if you defined a
webcrate with the following modules, users only needing client calls would also have to pay for the compilation of server code:web::server web::client web::protocolsInstead, you should introduce individual crates that give users the ability to pick and choose:
web_server web_client web_protocols
Names are free of weasel words (M-WEASEL-WORDS)
Symbol names, especially type and trait names, should be free of weasel words that do not meaningfully
add information. Common offenders include Service, Manager, and Factory.
While your library may very well contain or communicate with a booking service—or even hold an HttpClient
instance named booking_service—one should rarely encounter a BookingService type in code.
An item handling many bookings can just be called Bookings. If it does anything more specific, then that quality
should be appended instead. It submits these items elsewhere? Calling it BookingDispatcher would be more helpful.
The same is true for Managers. All code manages something, so that moniker is rarely useful. With rare
exceptions, life cycle issues should likewise not be made the subject of some manager. Items are created in whatever
way they are needed, their disposal is governed by Drop, and only Drop.
Regarding factories, at least the term should be avoided. While the concept FooFactory has its use, its canonical
Rust name is Builder (compare M-INIT-BUILDER). A builder that can produce items repeatedly is still a builder.
In addition, accepting factories (builders) as parameters is an unidiomatic import of OO concepts into Rust. If
repeatable instantiation is required, functions should ask for an impl Fn() -> Foo over a FooBuilder or
similar. In contrast, standalone builders have their use, but primarily to reduce parametric permutation complexity
around optional values (again, M-INIT-BUILDER).
Names of items are short (M-SHORT-NAMES)
The Rust convention that item identifiers are short should be followed:
- identifiers should not compound more than 2 short words (
AppConfigoverGlobalApplicationConfig), - module or crate information shouldn't be baked into prefixes (
foo::Idoverfoo::FooId), in particular when the direct 'super' item is sufficiently descriptive - in these cases users are expected to disambiguate items locally via qualifiers where needed (fn convert(foo::Id) -> bar::Id). - abbreviations are preferred (
CallbackFnoverCallbackFunction),
Any of these rules can be broken where it makes local sense, but on a per-crate bases these exceptions should be exceptional and well motivated.
Prefer regular over associated functions (M-REGULAR-FN)
Associated functions should primarily be used for instance creation, not general purpose computation.
In contrast to some OO languages, regular functions are first-class citizens in Rust and need no module or class to host them. Functionality that
does not clearly belong to a receiver should therefore not reside in a type's impl block:
struct Database {}
impl Database {
// Ok, associated function creates an instance
fn new() -> Self {}
// Ok, regular method with `&self` as receiver
fn query(&self) {}
// Not ok, this function is not directly related to `Database`,
// it should therefore not live under `Database` as an associated
// function.
fn check_parameters(p: &str) {}
}
// As a regular function this is fine
fn check_parameters(p: &str) {}Regular functions are more idiomatic, and reduce unnecessary noise on the caller side. Associated trait functions are perfectly idiomatic though:
#![allow(unused)] fn main() { pub trait Default { fn default() -> Self; } struct Foo; impl Default for Foo { fn default() -> Self { Self } } }
Magic values are documented (M-DOCUMENTED-MAGIC)
Hardcoded magic values in production code must be accompanied by a comment. The comment should outline:
- why this value was chosen,
- non-obvious side effects if that value is changed,
- external systems that interact with this constant.
You should prefer named constants over inline values.
// Bad: it's relatively obvious that this waits for a day, but not why
wait_timeout(60 * 60 * 24).await // Wait at most a day
// Better
wait_timeout(60 * 60 * 24).await // Large enough value to ensure the server
// can finish. Setting this too low might
// make us abort a valid request. Based on
// `api.foo.com` timeout policies.
// Best
/// How long we wait for the server.
///
/// Large enough value to ensure the server
/// can finish. Setting this too low might
/// make us abort a valid request. Based on
/// `api.foo.com` timeout policies.
const UPSTREAM_SERVER_TIMEOUT: Duration = Duration::from_secs(60 * 60 * 24);Use structured logging with message templates (M-LOG-STRUCTURED)
Logging should use structured events with named properties and message templates following the message templates specification.
Note: Examples use the
tracingcrate'sevent!macro, but these principles apply to any logging API that supports structured logging (e.g.,log,slog, custom telemetry systems).
Avoid String Formatting
String formatting allocates memory at runtime. Message templates defer formatting until viewing time. We recommend that message template includes all named properties for easier inspection at viewing time.
// Bad: String formatting causes allocations
tracing::info!("file opened: {}", path);
tracing::info!(format!("file opened: {}", path));
// Good: Message templates with named properties
event!(
name: "file.open.success",
Level::INFO,
file.path = path.display(),
"file opened: {{file.path}}",
);Note: Use the
{{property}}syntax in message templates which preserves the literal text while escaping Rust's format syntax. String formatting is deferred until logs are viewed.
Name Your Events
Use hierarchical dot-notation: <component>.<operation>.<state>
// Bad: Unnamed events
event!(
Level::INFO,
file.path = file_path,
"file {{file.path}} processed succesfully",
);
// Good: Named events
event!(
name: "file.processing.success", // event identifier
Level::INFO,
file.path = file_path,
"file {{file.path}} processed succesfully",
);Named events enable grouping and filtering across log entries.
Follow OpenTelemetry Semantic Conventions
Use OTel semantic conventions for common attributes if needed. This enables standardization and interoperability.
event!(
name: "file.write.success",
Level::INFO,
file.path = path.display(), // Standard OTel name
file.size = bytes_written, // Standard OTel name
file.directory = dir_path, // Standard OTel name
file.extension = extension, // Standard OTel name
file.operation = "write", // Custom name
"{{file.operation}} {{file.size}} bytes to {{file.path}} in {{file.directory}} extension={{file.extension}}",
);Common conventions:
- HTTP:
http.request.method,http.response.status_code,url.scheme,url.path,server.address - File:
file.path,file.directory,file.name,file.extension,file.size - Database:
db.system.name,db.namespace,db.operation.name,db.query.text - Errors:
error.type,error.message,exception.type,exception.stacktrace
Redact Sensitive Data
Do not log plain sensitive data as this might lead to privacy and security incidents.
// Bad: Logs potentially sensitive data
event!(
name: "file.operation.started",
Level::INFO,
user.email = user.email, // Sensitive data
file.name = "license.txt",
"reading file {{file.name}} for user {{user.email}}",
);
// Good: Redact sensitive parts
event!(
name: "file.operation.started",
Level::INFO,
user.email.redacted = redact_email(user.email),
file.name = "license.txt",
"reading file {{file.name}} for user {{user.email.redacted}}",
);Sensitive data includes email addresses, file paths revealing user identity, filenames containing secrets or tokens,
file contents with PII, temporary file paths with session IDs and more. Consider using the data_privacy crate for consistent redaction.
Further Reading
Library Guidelines
Guidelines for libraries. If your crate contains a lib.rs you should consider these:
Libraries / Interoperability Guidelines
Types are Send (M-TYPES-SEND)
Public types should be Send for compatibility reasons:
- All futures produced (explicitly or implicitly) must be
Send - Most other types should be
Send, but there might be exceptions
Futures
When declaring a future explicitly you should ensure it is, and remains, Send.
#![allow(unused)] fn main() { use std::future::Future; use std::pin::Pin; use std::task::{Context, Poll}; struct Foo {} impl Future for Foo { // Explicit implementation of `Future` for your type type Output = (); fn poll(self: Pin<&mut Self>, _: &mut Context<'_>) -> Poll<<Self as Future>::Output> { todo!() } } // You should assert your type is `Send` const fn assert_send<T: Send>() {} const _: () = assert_send::<Foo>(); }
When returning futures implicitly through async method calls, you should make sure these are Send too.
You do not have to test every single method, but you should at least validate your main entry points.
#![allow(unused)] fn main() { async fn foo() { } // TODO: We want this as a macro as well fn assert_send<T: Send>(_: T) {} _ = assert_send(foo()); }
Regular Types
Most regular types should be Send, as they otherwise infect futures turning them !Send if held across .await points.
#![allow(unused)] fn main() { use std::rc::Rc; async fn read_file(x: &str) {} async fn foo() { let rc = Rc::new(123); // <-- Holding this across an .await point prevents read_file("foo.txt").await; // the future from being `Send`. dbg!(rc); } }
That said, if the default use of your type is instantaneous, and there is no reason for it to be otherwise held across .await boundaries, it may be !Send.
#![allow(unused)] fn main() { use std::rc::Rc; struct Telemetry; impl Telemetry { fn ping(&self, _: u32) {} } fn telemetry() -> Telemetry { Telemetry } async fn read_file(x: &str) {} async fn foo() { // Here a hypothetical instance Telemetry is summoned // and used ad-hoc. It may be ok for Telemetry to be !Send. telemetry().ping(0); read_file("foo.txt").await; telemetry().ping(1); } }
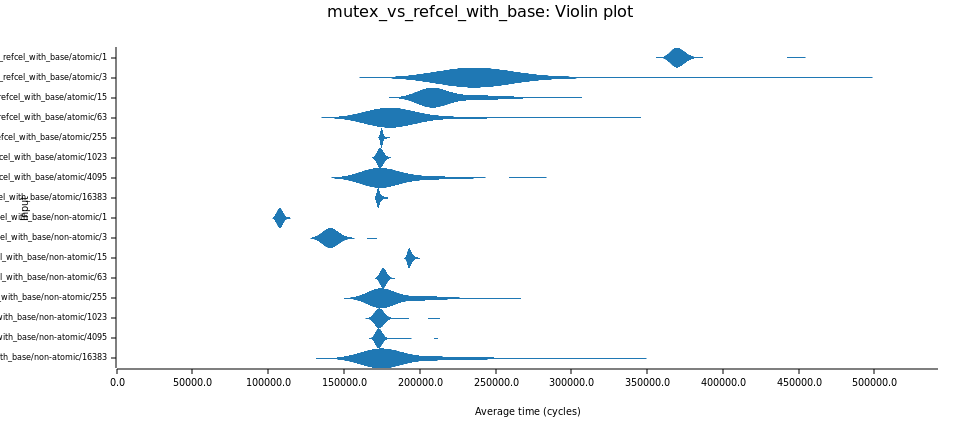
The Cost of Send Ideally, there would be abstractions that are
Sendin work-stealing runtimes, and!Sendin thread-per-core models based on non-atomic types likeRcandRefCellinstead.Practically these abstractions don't exist, preventing Tokio compatibility in the non-atomic case. That in turn means you would have to "reinvent the world" to get anything done in a thread-per-core universe.
The good news is, in most cases atomics and uncontended locks only have a measurable impact if accessed more frequently than every 64 words or so.
Working with a large
Vec<AtomicUsize>in a hot loop is a bad idea, but doing the occasional uncontended atomic operation from otherwise thread-per-core async code has no performance impact, but gives you widespread ecosystem compatibility.
Native escape hatches (M-ESCAPE-HATCHES)
Types wrapping native handles should provide unsafe escape hatches. In interop scenarios your users might have gotten a native handle from somewhere
else, or they might have to pass your wrapped handle over FFI. To enable these use cases you should provide unsafe conversion methods.
#![allow(unused)] fn main() { type HNATIVE = *const u8; pub struct Handle(HNATIVE); impl Handle { pub fn new() -> Self { // Safely creates handle via API calls todo!() } // Constructs a new Handle from a native handle the user got elsewhere. // This method should then also document all safety requirements that // must be fulfilled. pub unsafe fn from_native(native: HNATIVE) -> Self { Self(native) } // Various extra methods to permanently or temporarily obtain // a native handle. pub fn into_native(self) -> HNATIVE { self.0 } pub fn to_native(&self) -> HNATIVE { self.0 } } }
Don't leak external types (M-DONT-LEAK-TYPES)
Where possible, you should prefer std1 types in public APIs over types coming from external crates. Exceptions should be carefully considered.
Any type in any public API will become part of that API's contract. Since std and constituents are the only crates
shipped by default, and since they come with a permanent stability guarantee, their types are the only ones that come without an interoperability risk.
A crate that exposes another crate's type is said to leak that type.
For maximal long term stability your crate should, theoretically, not leak any types. Practically, some leakage is unavoidable, sometimes even beneficial. We recommend you follow this heuristic:
- if you can avoid it, do not leak third-party types
- if you are part of an umbrella crate,2 you may freely leak types from sibling crates.
-
behind a relevant feature flag, types may be leaked (e.g.,
serde) - without a feature only if they give a substantial benefit. Most commonly that is interoperability with significant other parts of the Rust ecosystem based around these types.
1 In rare instances, e.g., high performance libraries used from embedded, you might even want to limit yourself to core only.
2 For example, a runtime crate might be the umbrella of runtime_rt, runtime_app and runtime_clock As users are
expected to only interact with the umbrella, siblings may leak each others types.
Items come from their original crate (M-FOREIGN-REEXPORTS)
Crates should generally not re-export items from other crates. For example, if your crate contains a method foo::download(url: bar::Url), you should not do pub use bar::Url from inside foo. This avoids having possibly dozens of aliases in context, which can get confusing for both users and agents, in particular if these are mixed with genuinely different types of the same name from other crates.
When a crate accepts or returns a type defined in some third-party crate, users are expected to depend on that third-party crate directly and import the type from there. That said, there are a few valid exceptions to this rule:
- Umbrella crates (compare M-DONT-LEAK-TYPES) by definition re-export other types
- Crates split for technical reasons (e.g., exporting
foo_core::Urlfromfoo) - Macro use to provide stable paths, e.g., via some hidden
foo::__private::Url
Accept impl AsRef<> where feasible (M-IMPL-ASREF)
In function signatures, accept impl AsRef<T> for types that have a
clear reference hierarchy, where you
do not need to take ownership, or where object creation is relatively cheap.
| Instead of ... | accept ... |
|---|---|
&str, String | impl AsRef<str> |
&Path, PathBuf | impl AsRef<Path> |
&[u8], Vec<u8> | impl AsRef<[u8]> |
use std::path::Path;
// Definitely use `AsRef`, the function does not need ownership.
fn print(x: impl AsRef<str>) {}
fn read_file(x: impl AsRef<Path>) {}
fn send_network(x: impl AsRef<[u8]>) {}
// Further analysis needed. In these cases the function wants
// ownership of some `String` or `Vec<u8>`. If those are
// "low freqency, low volume" functions `AsRef` has better ergonomics,
// otherwise accepting a `String` or `Vec<u8>` will have better
// performance.
fn new_instance(x: impl AsRef<str>) -> HoldsString {}
fn send_to_other_thread(x: impl AsRef<[u8]>) {}In contrast, types should generally not be infected by these bounds:
// Generally not ok. There might be exceptions for performance
// reasons, but those should not be user visible.
struct User<T: AsRef<str>> {
name: T
}
// Better
struct User {
name: String
}
Accept impl RangeBounds<> where feasible (M-IMPL-RANGEBOUNDS)
Functions that accept a range of numbers must use a Range type or trait over hand-rolled parameters:
// Bad
fn select_range(low: usize, high: usize) {}
fn select_range(range: (usize, usize)) {}In addition, functions that can work on arbitrary ranges, should accept impl RangeBounds<T> rather than Range<T>.
#![allow(unused)] fn main() { use std::ops::{RangeBounds, Range}; // Callers must call with `select_range(1..3)` fn select_range(r: Range<usize>) {} // Callers may call as // select_any(1..3) // select_any(1..) // select_any(..) fn select_any(r: impl RangeBounds<usize>) {} }
Accept impl 'IO' where feasible ('sans IO') (M-IMPL-IO)
Functions and types that only need to perform one-shot I/O during initialization should be written "sans-io",
and accept some impl T, where T is the appropriate I/O trait, effectively outsourcing I/O work to another type:
// Bad, caller must provide a File to parse the given data. If this
// data comes from the network, it'd have to be written to disk first.
fn parse_data(file: File) {}#![allow(unused)] fn main() { // Much better, accepts // - Files, // - TcpStreams, // - Stdin, // - &[u8], // - UnixStreams, // ... and many more. fn parse_data(data: impl std::io::Read) {} }
Synchronous functions should use std::io::Read and
std::io::Write. Asynchronous functions targeting more than one runtime should use
futures::io::AsyncRead and similar.
Types that need to perform runtime-specific, continuous I/O should follow M-RUNTIME-ABSTRACTED instead.
Libraries / UX Guidelines
Abstractions don't visibly nest (M-SIMPLE-ABSTRACTIONS)
When designing your public types and primary API surface, avoid exposing nested or complex parametrized types to your users.
While powerful, type parameters introduce a cognitive load, even more so if the involved traits are crate-specific. Type parameters become infectious to user code holding on to these types in their fields, often come with complex trait hierarchies on their own, and might cause confusing error messages.
From the perspective of a user authoring Foo, where the other structs come from your crate:
struct Foo {
service: Service // Great
service: Service<Backend> // Acceptable
service: Service<Backend<Store>> // Bad
list: List<Rc<u32>> // Great, `List<T>` is simple container,
// other types user provided.
matrix: Matrix4x4 // Great
matrix: Matrix4x4<f32> // Still ok
matrix: Matrix<f32, Const<4>, Const<4>, ArrayStorage<f32, 4, 4>> // ?!?
}Visible type parameters should be avoided in service-like types (i.e., types mainly instantiated once per thread / application that are often passed as dependencies), in particular if the nestee originates from the same crate as the service.
Containers, smart-pointers and similar data structures obviously must expose a type parameter, e.g., List<T> above. Even then, care should
be taken to limit the number and nesting of parameters.
To decide whether type parameter nesting should be avoided, consider these factors:
- Will the type be named by your users?
- Service-level types are always expected to be named (e.g.,
Library<T>), - Utility types, such as the many
std::itertypes likeChain,Cloned,Cycle, are not expected to be named.
- Service-level types are always expected to be named (e.g.,
- Does the type primarily compose with non-user types?
- Do the used type parameters have complex bounds?
- Do the used type parameters affect inference in other types or functions?
The more of these factors apply, the bigger the cognitive burden.
As a rule of thumb, primary service API types should not nest on their own volition, and if they do, only 1 level deep. In other words, these
APIs should not require users having to deal with an Foo<Bar<FooBar>>. However, if Foo<T> users want to bring their own A<B<C>> as T they
should be free to do so.
Type Magic for Better UX? The guideline above is written with 'bread-and-butter' types in mind you might create during normal development activity. Its intention is to reduce friction users encounter when working with your code.
However, when designing API patterns and ecosystems at large, there might be valid reasons to introduce intricate type magic to overall lower the cognitive friction involved, Bevy's ECS or Axum's request handlers come to mind.
The threshold where this pays off is high though. If there is any doubt about the utility of your creative use of generics, your users might be better off without them.
Avoid smart pointers and wrappers in APIs (M-AVOID-WRAPPERS)
As a specialization of M-ABSTRACTIONS-DONT-NEST, generic wrappers and smart pointers like
Rc<T>, Arc<T>, Box<T>, or RefCell<T> should be avoided in public APIs.
From a user perspective these are mostly implementation details, and introduce infectious complexity that users have to resolve. In fact, these might even be impossible to resolve once multiple crates disagree about the required type of wrapper.
If wrappers are needed internally, they should be hidden behind a clean API that uses simple types like &T, &mut T, or T directly. Compare:
// Good: simple API
pub fn process_data(data: &Data) -> State { ... }
pub fn store_config(config: Config) -> Result<(), Error> { ... }
// Bad: Exposing implementation details
pub fn process_shared(data: Arc<Mutex<Shared>>) -> Box<Processed> { ... }
pub fn initialize(config: Rc<RefCell<Config>>) -> Arc<Server> { ... }Smart pointers in APIs are acceptable when:
-
The smart pointer is fundamental to the API's purpose (e.g., a new container lib)
-
The smart pointer, based on benchmarks, significantly improves performance and the complexity is justified.
Prefer types over generics, generics over dyn traits (M-DI-HIERARCHY)
When asking for async dependencies, prefer concrete types over generics, and generics over dyn Trait.
It is easy to accidentally deviate from this pattern when porting code from languages like C# that heavily rely on interfaces.
Consider you are porting a service called Database from C# to Rust and, inspired by the original IDatabase interface, you naively translate it into:
trait Database {
async fn update_config(&self, file: PathBuf);
async fn store_object(&self, id: Id, obj: Object);
async fn load_object(&self, id: Id) -> Object;
}
impl Database for MyDatabase { ... }
// Intended to be used like this:
async fn start_service(b: Rc<dyn Database>) { ... }Apart from not feeling idiomatic, this approach precludes other Rust constructs that conflict with object safety, can cause issues with asynchronous code, and exposes wrappers (compare M-AVOID-WRAPPERS).
Instead, when more than one implementation is needed, this design escalation ladder should be followed:
If the other implementation is only concerned with providing a sans-io implementation for testing, implement your type as an enum, following M-MOCKABLE-SYSCALLS instead.
If users are expected to provide custom implementations, you should introduce one or more traits, and implement them for your own types
on top of your inherent functions. Each trait should be relatively narrow, e.g., StoreObject, LoadObject. If eventually a single
trait is needed it should be made a subtrait, e.g., trait DataAccess: StoreObject + LoadObject {}.
Code working with these traits should ideally accept them as generic type parameters as long as their use does not contribute to significant nesting (compare M-ABSTRACTIONS-DONT-NEST).
// Good, generic does not have infectious impact, uses only most specific trait
async fn read_database(x: impl LoadObject) { ... }
// Acceptable, unless further nesting makes this excessive.
struct MyService<T: DataAccess> {
db: T,
}Once generics become a nesting problem, dyn Trait can be considered. Even in this case, visible wrapping should be avoided, and custom wrappers should be preferred.
#![allow(unused)] fn main() { use std::sync::Arc; trait DataAccess { fn foo(&self); } // This allows you to expand or change `DynamicDataAccess` later. You can also // implement `DataAccess` for `DynamicDataAccess` if needed, and use it with // regular generic functions. struct DynamicDataAccess(Arc<dyn DataAccess>); impl DynamicDataAccess { fn new<T: DataAccess + 'static>(db: T) -> Self { Self(Arc::new(db)) } } struct MyService { db: DynamicDataAccess, } }
The generic wrapper can also be combined with the enum approach from M-MOCKABLE-SYSCALLS:
enum DataAccess {
MyDatabase(MyDatabase),
Mock(mock::MockCtrl),
Dynamic(DynamicDataAccess)
}
async fn read_database(x: &DataAccess) { ... }
Errors are canonical structs (M-ERRORS-CANONICAL-STRUCTS)
Errors should be a situation-specific struct that contain a Backtrace,
a possible upstream error cause, and helper methods.
Simple crates usually expose a single error type Error, complex crates may expose multiple types, for example
AccessError and ConfigurationError. Error types should provide helper methods for additional information that allows callers to handle the error.
A simple error might look like so:
#![allow(unused)] fn main() { use std::backtrace::Backtrace; use std::fmt::Display; use std::fmt::Formatter; pub struct ConfigurationError { backtrace: Backtrace, } impl ConfigurationError { pub(crate) fn new() -> Self { Self { backtrace: Backtrace::capture() } } } // Impl Debug + Display }
Where appropriate, error types should provide contextual error information, for example:
use std::backtrace::Backtrace;
#[derive(Debug)]
pub struct ConfigurationError {
backtrace: Backtrace,
}
impl ConfigurationError {
pub fn config_file(&self) -> &Path { }
}If your API does mixed operations, or depends on various upstream libraries, store an ErrorKind.
Error kinds, and more generally enum-based errors, should not be used to avoid creating separate public error types when there is otherwise no error overlap:
// Prefer this
fn download_iso() -> Result<(), DownloadError> {}
fn start_vm() -> Result<(), VmError> {}
// Over that
fn download_iso() -> Result<(), GlobalEverythingErrorEnum> {}
fn start_vm() -> Result<(), GlobalEverythingErrorEnum> {}
// However, not every function warrants a new error type. Errors
// should be general enough to be reused.
fn parse_json() -> Result<(), ParseError> {}
fn parse_toml() -> Result<(), ParseError> {}If you do use an inner ErrorKind, that enum should not be exposed directly for future-proofing reasons,
as otherwise you would expose your callers to all possible failure modes, even the ones you consider internal
and unhandleable. Instead, expose various is_xxx() methods as shown below:
#![allow(unused)] fn main() { use std::backtrace::Backtrace; use std::fmt::Display; use std::fmt::Formatter; #[derive(Debug)] pub(crate) enum ErrorKind { Io(std::io::Error), Protocol } #[derive(Debug)] pub struct HttpError { kind: ErrorKind, backtrace: Backtrace, } impl HttpError { pub fn is_io(&self) -> bool { matches!(self.kind, ErrorKind::Io(_)) } pub fn is_protocol(&self) -> bool { matches!(self.kind, ErrorKind::Protocol) } } }
Most upstream errors don't provide a backtrace. You should capture one when creating an Error instance, either via one of
your Error::new() flavors, or when implementing From<UpstreamError> for Error {}.
Error structs must properly implement Display that renders as follows:
impl Display for MyError {
// Print a summary sentence what happened.
// Print `self.backtrace`.
// Print any additional upstream 'cause' information you might have.
fn fmt(&self, f: &mut Formatter<'_>) -> std::fmt::Result {
todo!()
}
}Errors must also implement std::error::Error:
impl std::error::Error for MyError { }Lastly, if you happen to emit lots of errors from your crate, consider creating a private bail!() helper macro to simplify error instantiation.
When You Get Backtraces Backtraces are an invaluable debug tool in complex or async code, since errors might travel far through a callstack before being surfaced.
That said, they are a development tool, not a runtime diagnostic, and by default
Backtrace::capture()will not capture backtraces, as they have a large overhead, e.g., 4μs per capture on the author's PC.Instead, Rust evaluates a set of environment variables, such as
RUST_BACKTRACE, and only walks the call frame when explicitly asked. Otherwise it captures an empty trace, at the cost of only a few CPU instructions.
Canonical error conversion uses From, not map_err (M-FROM-ERROR)
Where an Error type is owned, it should impl From<Other> for Error {} instead of handling the conversion throughout the code via .map_error(). Calling .map_error() is only appropriate when dealing with foreign error types, or if contextual information needs to be preserved.
// Bad, repeats the same conversion at every call site and obscures the happy path.
fn load() -> Result<Config, MyError> {
let bytes = read("config.toml").map_err(|e| MyError::Io(e))?;
let text = str::from_utf8(&bytes).map_err(|e| MyError::Utf8(e))?;
let cfg = toml::from_str(text).map_err(|e| MyError::Parse(e))?;
Ok(cfg)
}
// Good, define the conversion once and let `?` apply it.
impl From<std::io::Error> for MyError { ... }
impl From<std::str::Utf8Error> for MyError { ... }
impl From<toml::de::Error> for MyError { ... }
fn load() -> Result<Config, MyError> {
let bytes = read("config.toml")?;
let text = str::from_utf8(&bytes)?;
let cfg = toml::from_str(text)?;
Ok(cfg)
}
Complex type construction has builders (M-INIT-BUILDER)
Types that could support 4 or more arbitrary initialization permutations should provide builders. In other words, types with up to 2 optional initialization parameters can be constructed via inherent methods:
#![allow(unused)] fn main() { struct A; struct B; struct Foo; // Supports 2 optional construction parameters, inherent methods ok. impl Foo { pub fn new() -> Self { Self } pub fn with_a(a: A) -> Self { Self } pub fn with_b(b: B) -> Self { Self } pub fn with_a_b(a: A, b: B) -> Self { Self } } }
Beyond that, types should provide a builder:
struct A;
struct B;
struct C;
struct Foo;
struct FooBuilder;
impl Foo {
pub fn new() -> Self { ... }
pub fn builder() -> FooBuilder { ... }
}
impl FooBuilder {
pub fn a(mut self, a: A) -> Self { ... }
pub fn b(mut self, b: B) -> Self { ... }
pub fn c(mut self, c: C) -> Self { ... }
pub fn build(self) -> Foo { ... }
}
The proper name for a builder that builds Foo is FooBuilder. Its methods must be chainable, with the final method called
.build(). The buildable struct must have a shortcut Foo::builder(), while the builder itself should not have a public
FooBuilder::new(). Builder methods that set a value x are called x(), not set_x() or similar.
Builders and Required Parameters
Required parameters should be passed when creating the builder, not as setter methods. For builders with multiple required
parameters, encapsulate them into a parameters struct and use the deps: impl Into<Deps> pattern to provide flexibility:
Note: A dedicated deps struct is not required if the builder has no required parameters or only a single simple parameter. However, for backward compatibility and API evolution, it's preferable to use a dedicated struct for deps even in simple cases, as it makes it easier to add new required parameters in the future without breaking existing code.
#[derive(Debug, Clone)]
pub struct FooDeps {
pub logger: Logger,
pub config: Config,
}
impl From<(Logger, Config)> for FooDeps { ... }
impl From<Logger> for FooDeps { ... } // In case we could use default Config instance
impl Foo {
pub fn builder(deps: impl Into<FooDeps>) -> FooBuilder { ... }
}This pattern allows for convenient usage:
Foo::builder(logger)- when only the logger is neededFoo::builder((logger, config))- when both parameters are neededFoo::builder(FooDeps { logger, config })- explicit struct construction
Alternatively, you can use fundle to simplify the creation of FooDeps:
#[derive(Debug, Clone)]
#[fundle::deps]
pub struct FooDeps {
pub logger: Logger,
pub config: Config,
}This pattern enables "dependency injection", see these docs for more details.
Runtime-Specific Builders
For types that are runtime-specific or require runtime-specific configuration, provide dedicated builder creation methods that accept the appropriate runtime parameters:
#[cfg(feature="smol")]
#[derive(Debug, Clone)]
pub struct SmolDeps {
pub clock: Clock,
pub io_context: Context,
}
#[cfg(feature="tokio")]
#[derive(Debug, Clone)]
pub struct TokioDeps {
pub clock: Clock,
}
impl Foo {
#[cfg(feature="smol")]
pub fn builder_smol(deps: impl Into<SmolDeps>) -> FooBuilder { ... }
#[cfg(feature="tokio")]
pub fn builder_tokio(deps: impl Into<TokioDeps>) -> FooBuilder { ... }
}This approach ensures type safety at compile time and makes the runtime dependency explicit in the API surface. The resulting
builder methods follow the pattern builder_{runtime}(deps) where {runtime} indicates the specific runtime or execution environment.
Further Reading
Complex type initialization hierarchies are cascaded (M-INIT-CASCADED)
Types that require 4+ parameters should cascade their initialization via helper types.
struct Deposit;
impl Deposit {
// Easy to confuse parameters and signature generally unwieldy.
pub fn new(bank_name: &str, customer_name: &str, currency_name: &str, currency_amount: u64) -> Self { }
}Instead of providing a long parameter list, parameters should be grouped semantically. When applying this guideline, also check if C-NEWTYPE is applicable:
struct Deposit;
struct Account;
struct Currency
impl Deposit {
// Better, signature cleaner
pub fn new(account: Account, amount: Currency) -> Self { }
}
impl Account {
pub fn new_ok(bank: &str, customer: &str) -> Self { }
pub fn new_even_better(bank: Bank, customer: Customer) -> Self { }
}
Services are Clone (M-SERVICES-CLONE)
Heavyweight service types and 'thread singletons' should implement shared-ownership Clone semantics, including any type you expect to be used from your Application::init.
Per thread, users should essentially be able to create a single resource handler instance, and have it reused by other handlers on the same thread:
impl ThreadLocal for MyThreadState {
fn init(...) -> Self {
// Create common service instance possibly used by many.
let common = ServiceCommon::new();
// Users can freely pass `common` here multiple times
let service_1 = ServiceA::new(&common);
let service_2 = ServiceA::new(&common);
Self { ... }
}
}Services then simply clone their dependency and store a new handle, as if ServiceCommon were a shared-ownership smart pointer:
impl ServiceA {
pub fn new(common: &ServiceCommon) -> Self {
// If we only need to access `common` from `new` we don't have
// to store it. Otherwise, make a clone we store in `Self`.
let common = common.clone();
}
}Under the hood this Clone should not create a fat copy of the entire service. Instead, it should follow the Arc<Inner> pattern:
// Actual service containing core logic and data.
struct ServiceCommonInner {}
#[derive(Clone)]
pub ServiceCommon {
inner: Arc<ServiceCommonInner>
}
impl ServiceCommon {
pub fn new() {
Self { inner: Arc::new(ServiceCommonInner::new()) }
}
// Method forwards ...
pub fn foo(&self) { self.inner.foo() }
pub fn bar(&self) { self.inner.bar() }
}
Essential functionality should be inherent (M-ESSENTIAL-FN-INHERENT)
Types should implement core functionality inherently. Trait implementations should forward to inherent functions, and not replace them. Instead of this
#![allow(unused)] fn main() { trait Download { fn download_file(&self, url: impl AsRef<str>); } struct HttpClient {} // Offloading essential functionality into traits means users // will have to figure out what other traits to `use` to // actually use this type. impl Download for HttpClient { fn download_file(&self, url: impl AsRef<str>) { // ... logic to download a file } } }
do this:
#![allow(unused)] fn main() { trait Download { fn download_file(&self, url: impl AsRef<str>); } struct HttpClient {} impl HttpClient { fn download_file(&self, url: impl AsRef<str>) { // ... logic to download a file } } // Forward calls to inherent impls. `HttpClient` can be used impl Download for HttpClient { fn download_file(&self, url: impl AsRef<str>) { Self::download_file(self, url) } } }
Modules are balanced in size and scope (M-BALANCED-MODULES)
Your module design should approximately follow established UX practices of menu design: A reasonable number of your most important items should be placed in the crate root, and a comprehensible grouping of the remaining functionality into subordinate modules.
Two violations of that rule are encountered most frequently: flat module roots containing dozens of items without clear ordering, or the excessive use of submodules without items in the crate root. While there are crates where this makes sense (e.g., automatically generated -sys crates defining 100s of C items, or umbrella crates like std and tokio), the majority of library crates are not among them.
When designing your module layout, consider these factors:
- Essential items users must find in order to use a crate should go into its root. For example, a
foo_clientcrate should probably have its mainClientstruct inside the root. - Other items should be grouped semantically by use case. Modules named
traitsanderrorsdon't help anyone, butaccount,networkandstatusdo. - Also take into account that modules are the perfect place for module-level documentation that further explains the respective subsystem.
Don't define preludes (M-NO-PRELUDE)
Crates must not define a prelude or any namespace intended to be imported as use foo::*.
While the Rust Standard Library successfully uses preludes to define edition items, preludes in crates cause more harm than good. Given today's IDE support they are not needed, and once multiple preludes are used from different crates there is potential for conflicts:
use foo::prelude::*;
use bar::prelude::*;
use baz::prelude::*;
_ = Client::new();
// error[E0659]: `Client` is ambiguous
// --> src/lib.rs:17:13
// |
// 17 | _ = Client;
// | ^^^^^^ ambiguous name
// |
// = note: ambiguous because of multiple glob imports of a name in the same modulePreludes in particular do not resolve bad module design. If it looks like a prelude would make the crate easier to use or understand, this is almost always an indication that the existing module system needs restructuring, see M-BALANCED-MODULES.
Parameter ordering is consistent (M-PARAMETER-CONSISTENCY)
When the same conceptual parameters appear in multiple functions (within a crate or across crates in the same ecosystem), they should appear in the same order everywhere:
- important or call-specific parameters should generally go first,
- ubiquitous parameters rather go last (e.g.,
&logger), - closures always go last (functions should not accept more than one closure).
// Bad, the order of `user_id` and `tenant_id` flips between functions, and
// the logger sometimes appears first, sometimes last.
fn create_user(logger: &Logger, user_id: UserId, tenant_id: TenantId) -> Result<()> { ... }
fn delete_user(tenant_id: TenantId, user_id: UserId, logger: &Logger) -> Result<()> { ... }
fn rename_user(user_id: UserId, new_name: &str, tenant_id: TenantId, logger: &Logger) -> Result<()> { ... }
// Good, call-specific parameters first in a consistent order, ubiquitous
// `logger` always last.
fn create_user(tenant_id: TenantId, user_id: UserId, logger: &Logger) -> Result<()> { ... }
fn delete_user(tenant_id: TenantId, user_id: UserId, logger: &Logger) -> Result<()> { ... }
fn rename_user(tenant_id: TenantId, user_id: UserId, new_name: &str, logger: &Logger) -> Result<()> { ... }Collections implement the appropriate iter traits (M-COLLECTION-TRAITS)
Custom collections should implement the iterator-facing traits the standard library offers.
Whenever you define a new collection type Collection<T> for consumption by third parties, the following traits and types should also be implemented, see here for more details:
- the structs
IntoIter<T>,Iter<T>andIterMut<T>, - an
impl Iteratorfor all of them, - the methods
c.iter()andc.iter_mut(), - an
impl IntoIteratorforCollection<T>,&Collection<T>and&mut Collection<T>, - an
impl FromIteratorforCollection<T>, - an
ExtendforCollection<T>, DoubleEndedIterator,ExactSizeIterator, ... as applicable
In addition, make sure you implement size_hint() on all iterators and do so truthfully.
Functions are async over returning a Future (M-ASYNC-FN)
Functions should be declared async fn foo() over fn foo() -> impl Future when both are viable.
Functions marked async are more idiomatic and easier to read. An explicit Future-returning signature should only be used when required, for example inside traits or for hot 'n heavy async functions, compare M-ASYNC-STACK-SIZE.
impl Foo {
// Bad, signature is noisier and the body needs an extra `async` block
fn foo() -> impl Future<Output = Result<T, E>> { async { Ok(t) } }
// Good, method and implementation reads normally
async fn foo() -> Result<T, E> { Ok(t) }
}Libraries / Resilience Guidelines
I/O and system calls are mockable (M-MOCKABLE-SYSCALLS)
Any user-facing type doing I/O, or sys calls with side effects, should be mockable to these effects. This includes file and network access, clocks, entropy sources and seeds, and similar. More generally, any operation that is
- non-deterministic,
- reliant on external state,
- depending on the hardware or the environment,
- is otherwise fragile or not universally reproducible
should be mockable.
Mocking Allocations? Unless you write kernel code or similar, you can consider allocations to be deterministic, hardware independent and practically infallible, thus not covered by this guideline.
However, this does not mean you should expect there to be unlimited memory available. While it is ok to accept caller provided input as-is if your library has a reasonable memory complexity, memory-hungry libraries and code handling external input should provide bounded and / or chunking operations.
This guideline has several implications for libraries, they
- should not perform ad-hoc I/O, i.e., call
read("foo.txt") - should not rely on non-mockable I/O and sys calls
- should not create their own I/O or sys call core themselves
- should not offer
MyIoLibrary::default()constructors
Instead, libraries performing I/O and sys calls should either accept some I/O core that is mockable already, or provide mocking functionality themselves:
let lib = Library::new_runtime(runtime_io); // mockable I/O functionality passed in
let (lib, mock) = Library::new_mocked(); // supports inherent mockingLibraries supporting inherent mocking should implement it as follows:
pub struct Library {
some_core: LibraryCore // Encapsulates syscalls, I/O, ... compare below.
}
impl Library {
pub fn new() -> Self { ... }
pub fn new_mocked() -> (Self, MockCtrl) { ... }
}Behind the scenes, LibraryCore is a non-public enum, similar to M-RUNTIME-ABSTRACTED, that either dispatches
calls to the respective sys call, or to an mocking controller.
// Dispatches calls either to the operating system, or to a
// mocking controller.
enum LibraryCore {
Native,
#[cfg(feature = "test-util")]
Mocked(mock::MockCtrl)
}
impl LibraryCore {
// Some function you'd forward to the operating system.
fn random_u32(&self) {
match self {
Self::Native => unsafe { os_random_u32() }
Self::Mocked(m) => m.random_u32()
}
}
}
#[cfg(feature = "test-util")]
mod mock {
// This follows the M-SERVICES-CLONE pattern, so both `LibraryCore` and
// the user can hold on to the same `MockCtrl` instance.
pub struct MockCtrl {
inner: Arc<MockCtrlInner>
}
// Implement required logic accordingly, usually forwarding to
// `MockCtrlInner` below.
impl MockCtrl {
pub fn set_next_u32(&self, x: u32) { ... }
pub fn random_u32(&self) { ... }
}
// Contains actual logic, e.g., the next random number we should return.
struct MockCtrlInner {
next_call: u32
}
}Runtime-aware libraries already build on top of the M-RUNTIME-ABSTRACTED pattern should extend their runtime enum instead:
enum Runtime {
#[cfg(feature="tokio")]
Tokio(tokio::Tokio),
#[cfg(feature="smol")]
Smol(smol::Smol)
#[cfg(feature="test-util")]
Mock(mock::MockCtrl)
}As indicated above, most libraries supporting mocking should not accept mock controllers, but return them via parameter tuples, with the first parameter being the library instance, the second the mock controller. This is to prevent state ambiguity if multiple instances shared a single controller:
impl Library {
pub fn new_mocked() -> (Self, MockCtrl) { ... } // good
pub fn new_mocked_bad(&mut MockCtrl) -> Self { ... } // prone to misuse
}
Test utilities are feature gated (M-TEST-UTIL)
Testing functionality must be guarded behind a feature flag. This includes
- mocking functionality (M-MOCKABLE-SYSCALLS),
- the ability to inspect sensitive data,
- safety check overrides,
- fake data generation.
We recommend you use a single flag only, named test-util. In any case, the feature(s) must clearly communicate they are for testing purposes.
impl HttpClient {
pub fn get() { ... }
#[cfg(feature = "test-util")]
pub fn bypass_certificate_checks() { ... }
}Integration tests live under tests/ (M-INTEGRATION-TESTS)
Tests that only touch public API surface are integration tests and belong under tests/, not mod tests {}.
In projects with coverage targets, it is not uncommon for src/ files to contain more testing code than actual business logic. This can make browsing and understanding the code harder both in IDEs and PRs. Likewise, if a testing goal can be achieved through either an integration test or a unit test, the former is always preferred.
Use the proper type family (M-STRONG-TYPES)
Use the appropriate std type for your task. In general you should use the strongest type available, as early as possible in your API flow. Common offenders are
| Do not use ... | use instead ... | Explanation |
|---|---|---|
String* | PathBuf* | Anything dealing with the OS should be Path-like |
That said, you should also follow common Rust std conventions. Purely numeric types at public API boundaries (e.g., window_size()) are expected to
be regular numbers, not Saturating<usize>, NonZero<usize>, or similar.
* Including their siblings, e.g., &str, Path, ...
Newtypes guard their invariants (M-STRONG-TYPES-GUARD)
When introducing a strong type or newtype that exists to encode an invariant (a non-empty string, a percentage, a port number, a sanitized path, ...), the type itself must enforce that invariant where applicable.
Construction should be fallible, returning a proper error when the invariant cannot be upheld, rather than handing the responsibility off to every user:
// Bad, creates a new type but enforces nothing. Every caller now has to
// re-check that the value is actually a valid month, defeating the point of
// having a dedicated type.
pub struct Month(pub u8);
impl Month {
pub fn new(value: u8) -> Self { ... }
}
// Good, the invariant (1..=12) is checked once, at the boundary, and
// every later use of `Month` can rely on it.
pub struct Month(u8);
impl Month {
pub fn from_u8(value: u8) -> Result<Self, DateError> { ... }
}This means for any newtype that is non-total:
- It must have at least one fallible constructor (e.g.,
fn from_foo(...) -> Result<Self, _>). - Additional panicking constructors are allowed (e.g.,
new), and should preferably beconst. - Conversions from weaker types into the newtype must be fallible (
TryFrom/FromStr). - Infallible
Fromimplementations may not be offered.
Why const?Const constructors allows them to be used inside
const {}blocks, which surfaces these violations as errors. This enables users to dolet month_due = const { Month::new(14) }and avoids hitting these paths during runtime.
Builders validate in final .build() (M-BUILD-RESULT)
A builder's per-field setters should accept input without failing, final validation should be done by .build().
Fallible setters add noise, and still don't guard against interdependent error conditions. Where builders are fallible they should offer a Result-carrying .build() instead.
// Bad, forces repeated error checks that provide no value.
Foo::builder()
.name("Foo")?
.distance(42)?
.build();
// Good, consolidates sanity checking and allows for cross-checks
// between properties.
Foo::builder()
.name("Foo")
.distance(42)
.build()?;That said, individual settings should prefer strong types carrying their own validation where applicable, compare M-STRONG-TYPES-GUARD.
Don't glob re-export items (M-NO-GLOB-REEXPORTS)
Don't pub use foo::* from other modules, especially not from other crates. You might accidentally export more than you want,
and globs are hard to review in PRs. Re-export items individually instead:
pub use foo::{A, B, C};Glob exports are permissible for technical reasons, like doing platform specific re-exports from a set of HAL (hardware abstraction layer) modules:
#[cfg(target_os = "windows")]
mod windows { /* ... */ }
#[cfg(target_os = "linux")]
mod linux { /* ... */ }
// Acceptable use of glob re-exports, this is a common pattern
// and it is clear everything is just forwarded from a single
// platform.
#[cfg(target_os = "windows")]
pub use windows::*;
#[cfg(target_os = "linux")]
pub use linux::*;
Avoid statics (M-AVOID-STATICS)
Libraries should avoid static and thread-local items, if a consistent view of the item is relevant for correctness.
Essentially, any code that would be incorrect if the static magically had another value must not use them. Statics
only used for performance optimizations are ok.
The fundamental issue with statics in Rust is the secret duplication of state.
Consider a crate core with the following function:
#![allow(unused)] fn main() { use std::sync::atomic::AtomicUsize; use std::sync::atomic::Ordering; static GLOBAL_COUNTER: AtomicUsize = AtomicUsize::new(0); pub fn increase_counter() -> usize { GLOBAL_COUNTER.fetch_add(1, Ordering::Relaxed) } }
Now assume you have a crate main, calling two libraries library_a and library_b, each invoking that counter:
// Increase global static counter 2 times
library_a::count_up();
library_a::count_up();
// Increase global static counter 3 more times
library_b::count_up();
library_b::count_up();
library_b::count_up();They eventually report their result:
library_a::print_counter();
library_b::print_counter();
main::print_counter();At this point, what is the value of said counter; 0, 2, 3 or 5?
The answer is, possibly any (even multiple!) of the above, depending on the crate's version resolution!
Under the hood Rust may link to multiple versions of the same crate, independently instantiated, to satisfy declared
dependencies. This is especially observable during a crate's 0.x version timeline, where each x constitutes a separate major version.
If main, library_a and library_b all declared the same version of core, e.g. 0.5, then the reported result will be 5, since all
crates actually see the same version of GLOBAL_COUNTER.
However, if library_a declared 0.4 instead, then it would be linked against a separate version of core; thus main and library_b would
agree on a value of 3, while library_a reported 2.
Although static items can be useful, they are particularly dangerous before a library's stabilization, and for any state where secret duplication would
cause consistency issues when static and non-static variable use interacts. In addition, statics interfere with unit testing, and are a contention point in
thread-per-core designs.
Production code uses telemetry, not println (M-LOG-NOT-PRINT)
Production code paths should emit diagnostics through the project's telemetry framework rather than via println! or dbg!. Console output is reserved for CLIs that intentionally write to stdout as their user interface.
Libraries / Building Guidelines
Libraries work out of the box (M-OOBE)
Libraries must just work on all supported platforms, with the exception of libraries that are expressly platform or target specific.
Rust crates often come with dozens of dependencies, applications with 100's. Users expect cargo build and cargo install
to just work. Consider this installation of bat that pulls in ~250 dependencies:
Compiling writeable v0.5.5
Compiling strsim v0.11.1
Compiling litemap v0.7.5
Compiling crossbeam-utils v0.8.21
Compiling icu_properties_data v1.5.1
Compiling ident_case v1.0.1
Compiling once_cell v1.21.3
Compiling icu_normalizer_data v1.5.1
Compiling fnv v1.0.7
Compiling regex-syntax v0.8.5
Compiling anstyle v1.0.10
Compiling vcpkg v0.2.15
Compiling utf8parse v0.2.2
Compiling aho-corasick v1.1.3
Compiling utf16_iter v1.0.5
Compiling hashbrown v0.15.2
Building [==> ] 29/251: icu_locid_transform_data, serde, winnow, indexma...
This compilation, like practically all other applications and libraries, will just work.
While there are tools targeting specific functionality (e.g., a Wayland compositor) or platform crates like
windows; unless a crate is obviously platform specific, the expectation is that it will otherwise just work.
This means crates must build, ultimately
- on all Tier 1 platforms,1 and
-
without any additional prerequisites beyond
cargoandrust.2
1 It is ok to not support Tier 1 platforms "for now", but abstractions must be present so support can easily be extended. This is usually
done by introducing an internal HAL (Hardware Abstraction Layer) module with a dummy fallback target.
2 A default Rust installation will also have cc and a linker present.
In particular, non-platform crates must not, by default, require the user to install additional tools, or expect environment variables
to compile. If tools were somehow needed (like the generation of Rust from .proto files) these tools should be run as part of the
publishing workflow or earlier, and the resulting artifacts (e.g., .rs files) be contained inside the published crate.
If a dependency is known to be platform specific, the parent must use conditional (platform) compilation or opt-in feature gates.
Libraries are Responsible for Their Dependencies. Imagine you author a
Copilotcrate, which in turn uses anHttpClient, which in turn depends on aperlscript to compile.Then every one of your users, and your user's users, and everyone above, would need to install Perl to compile their crate. In large projects you would have 100's of people who don't know or don't care about your library or Perl, encounter a cryptic compilation error, and now have to figure out how to install it on their system.
In practical terms, such behavior is largely a self-inflicted death sentence in the open source space, since the moment alternatives are available, people will switch to those that just work.
Native -sys crates compile without dependencies (M-SYS-CRATES)
If you author a pair of foo and foo-sys crates wrapping a native foo.lib, you are likely to run into the issues described
in M-OOBE.
Follow these steps to produce a crate that just works across platforms:
-
fully govern the build of
foo.libfrombuild.rsinsidefoo-sys. Only use hand-crafted compilation via the cc crate, do not run Makefiles or external build scripts, as that will require the installation of external dependencies, -
make all external tools optional, such as
nasm, - embed the upstream source code in your crate,
- make the embedded sources verifiable (e.g., include Git URL + hash),
-
pre-generate
bindgenglue if possible, - support both static linking, and dynamic linking via libloading.
Deviations from these points can work, and can be considered on a case-by-case basis:
If the native build system is available as an OOBE crate, that can be used instead of cc invocations. The same applies to external tools.
Source code might have to be downloaded if it does not fit crates.io size limitations. In any case, only servers with an availability comparable to crates.io should be used. In addition, the specific hashes of acceptable downloads should be stored in the crate and verified.
Downloading sources can fail on hermetic build environments, therefore alternative source roots should also be specifiable (e.g., via environment variables).
Features are additive (M-FEATURES-ADDITIVE)
All library features must be additive, and any combination must work, as long as the feature itself would work on the current platform. This implies:
-
You must not introduce a
no-stdfeature, use astdfeature instead -
Adding any feature
foomust not disable or modify any public item- Adding enum variants is fine if these enums are
#[non_exhaustive]
- Adding enum variants is fine if these enums are
- Features must not rely on other features to be manually enabled
- Features must not rely on their parent to skip-enable a feature in one of their children
Further Reading
Macros Guidelines
Macros are a last resort (M-MACRO-LAST-RESORT)
Macros should only be used if no other viable solution exists, compare this adage:
As @littlecalculist always told me, “macros are for when you run out of language”. If you still have language left — and Rust gives you a lot of language — use the language first.
@pcwalton
Macros are powerful, but come with several downsides. They
- are magic, and it can be impossible to predict what they do, or how they do it,
- disproportionally increase compilation time in projects that otherwise don't rely on them,
- can cause subtle breakage at edition boundaries where Rust syntax and semantics can change.
Counterintuitively, the more structurally complex the result of a macro expansion is, the worse an idea it is to use macros for that in the first place. The ideal macro makes your users go "I know exactly what this will generate, but I don't want to write all of that by hand".
Prefer 'macros by example' over proc macros (M-EXAMPLE-OVER-PROC)
When a 'macro by example' can do the job, it should be preferred over proc macros.
Proc macros are more powerful, but their expansion can't easily be inspected. Where this versatility isn't needed, a simple 'macro by example' is the better option.
// Bad, attribute macro requires proc macro machinery, can be hard to
// inspect in some IDEs, and isn't needed here.
#[make_new_id]
struct MyId;
// Good, easier to write, maintain and inspect, faster compilation speed.
make_new_id!(MyId);Macros don't lie about signatures (M-MACROS-DONT-LIE)
Macros must not (make users) misrepresent signatures or the shape of items.
Macros have the ability to arbitrarily rewrite token streams. They could convert structs to enums, traits to functions, or perform any other transformation imaginable. They should, however, do none of that, as the resulting code will be highly confusing and virtually impossible to predict or reason about.
Among others, macros must not
- visibly convert the nature of data types (e.g., structs to enums, ...),
- alter function signatures,
- convert the
async-ness of items, - do anything else that materially detaches what's written from what's happening.
// Bad: Adds extra parameter and marks function `async`. Impossible to
// predict from reading code.
#[magic_transform]
fn foo() { }
foo(token).awaitMacros assume main crate (M-MACRO-MAIN-CRATE)
Procedural macros can (and should) assume they are used through their main crate and emit paths for that.
For crates including proc macros it is common to ship them split in 3 for technical reasons:
foo- the main crate that re-exports macros fromfoo_proc, along with extra traits or types,foo_proc- facade re-exporting macros fromfoo_proc_implwithproc-macro = true,foo_proc_impl- the actual macro implementation and unit tests.
In some cases there can be additional crates involved. Authors might be tempted to make foo, foo_proc, and siblings all work, resulting in complex re-export hierarchies or the use of 3rd party helpers. In reality, the minimal UX gain is usually not worth the added complexity (or compile time overhead), given the ecosystem precedent of mostly not supporting these usage modes in the first place.
This also implies you should not attempt to support use cases where your crate is imported under a different name.
Third party items come from hidden _private module (M-MACRO-HELPERS)
When a macro expansion needs to refer to third-party items, the host crate should re-export those from a hidden module, and the macro should emit fully-qualified paths through that module rather than expecting the user's crate to depend on the third-party crate directly.
For example, a crate foo requiring bar traits would do:
#[doc(hidden)]
pub mod _private {
pub use ::bar::Bar;
}
pub use foo_proc::my_macro;The my_macro! implementation would then rely on its presence in its emitted code:
impl ::foo::_private::Bar for MyType { ... }Proc macros should have separate impl crate incl. tests (M-PROC-IMPL)
Proc macros should be thin shims inside some foo_proc crate that delegate to a separate, regular library crate, usually called foo_proc_impl, which contains the actual token-stream transformation logic and its tests.
As proc macro crates are special, testing them from foo_proc usually requires workarounds for unit and snapshot tests. Instead, consider having a foo_proc_impl crate:
use proc_macro2::TokenStream;
pub fn my_macro(attr: TokenStream, item: TokenStream) -> TokenStream { ... }These can come with regular insta or similar snapshot tests, and are then exported as genuine proc macros via a foo_proc crate like so:
#[proc_macro_attribute]
pub fn my_macro(attr: TokenStream, item: TokenStream) -> TokenStream {
foo_proc_impl::my_macro(attr.into(), item.into()).into()
}The macros are then re-exported from the core crate:
pub use foo_proc::my_macro;Inside the core crate, we also recommend adding trybuild UI tests with negative examples to ensure consistent error messages.
Proc macros don't produce implied or hidden items (M-PROC-IMPLIED-ITEMS)
Macros should not define magic types on their own, in particular not public ones, or ones that don't rely on namespace tricks.
Some macros want to define types, for example
#[my_macro]
struct UserType;
// would expand to
struct UserType;
struct ExtraType;
impl UserType {
fn foo() -> ExtraType { ... };
}This is almost always a bad idea for several reasons:
- they can conflict with existing user-defined types inside the same module,
- if done naively, they can conflict with other expansions of the same macro,
- they can clash with the user's naming conventions,
- they are invisible at source code level and easily forgotten to be re-exported where needed.
While it is possible for users to work around these limitations somewhat, these are paper cuts your users will have to deal with, possibly months after the fact when refactoring otherwise unrelated code.
Note that there is one exception to this rule that has generally acceptable UX, the overloaded use of namespaces made prominent by crates like Rocket:
#[my_macro]
fn foo() { ... }
// would expand to
fn foo() { ... }
struct foo;
impl SomeTrait for foo { ... }Here a new type foo is introduced with the same name as the function foo. Due to Rust's namespace rules they can co-exist and are automatically re-exported with their parent, and due to Rust's casing rules (C-CASE) these are highly unlikely to clash with user-defined types. However, they would still not make for a pretty public type, and are therefore mainly used inside root crates to define request handlers or FFI functions.
Namespaces != Modules Namespaces in Rust have nothing to do with namespaces in other languages. A namespace in C# is approximately a module in Rust. A namespace in Rust is an esoteric property of names (e.g.,
fn foo,struct Bar {},moo!) that decides which 'naming bucket' it lives in inside a module.
Application Guidelines
Use mimalloc for apps (M-MIMALLOC-APPS)
Applications should set mimalloc as their global allocator. This usually results in notable performance increases along allocating hot paths; we have seen up to 25% benchmark improvements.
Changing the allocator only takes a few lines of code. Add mimalloc to your Cargo.toml like so:
[dependencies]
mimalloc = { version = "0.1" } # Or later version if available
Then use it from your main.rs:
use mimalloc::MiMalloc;
#[global_allocator]
static GLOBAL: MiMalloc = MiMalloc;
Applications may use Anyhow or derivatives (M-APP-ERROR)
Note, this guideline is primarily a relaxation and clarification of M-ERRORS-CANONICAL-STRUCTS.
Applications, and crates in your own repository exclusively used from your application, may use ohno::AppError, anyhow, eyre or similar application-level error crates instead of implementing their own types.
For example, in your application crates you may just re-export and use eyre's common Result type, which should be able to automatically
handle all third party library errors, in particular the ones following
M-ERRORS-CANONICAL-STRUCTS.
use ohno::AppError;
fn start_application() -> Result<(), AppError> {
start_server()?;
Ok(())
}Once you selected your application error crate you should switch all application-level errors to that type, and you should not mix multiple application-level error types.
Libraries (crates used by more than one crate) should always follow M-ERRORS-CANONICAL-STRUCTS instead.
Applications target highest viable target-cpu (M-TARGET-CPU)
Server applications should compile against the highest target-cpu that the deployment environment is guaranteed to support, rather than defaulting to the generic baseline.
This can be achieved, for example, by setting inside .cargo/config.toml:
[target.x86_64-unknown-linux-gnu]
rustflags = ["-C", "target-cpu=x86-64-v3"]
[target.x86_64-pc-windows-msvc]
rustflags = ["-C", "target-cpu=x86-64-v3"]
# Add other platforms here based on needs ...
Note this guideline applies only to applications, as target settings are ignored for libraries.
FFI Guidelines
Isolate DLL state between FFI libraries (M-ISOLATE-DLL-STATE)
When loading multiple Rust-based dynamic libraries (DLLs) within one application, you may only share 'portable' state between these libraries. Likewise, when authoring such libraries, you must only accept or provide 'portable' data from foreign DLLs.
Portable here means data that is safe and consistent to process regardless of its origin. By definition, this is a subset of FFI-safe types.
A type is portable if it is #[repr(C)] (or similarly well-defined), and all of the following:
- It must not have any interaction with any
staticor thread local. - It must not have any interaction with any
TypeId. - It must not contain any value, pointer or reference to any non-portable data (it is valid to point into portable data within non-portable data, such as
sharing a reference to an ASCII string held in a
Box).
Interaction means any computational relationship, and therefore also relates to how the type is used. Sending a u128 between DLLs is OK, using it to
exchange a transmuted TypeId isn't.
The underlying issue stems from the Rust compiler treating each DLL as an entirely new compilation artifact, akin to a standalone application. This means each DLL:
- has its own set of
staticand thread-local variables, - the type layout of any
#[repr(Rust)]type (the default) can differ between compilations, - has its own set of unique type IDs, differing from any other DLL.
Notably, this affects:
- ⚠️ any allocated instance, e.g.,
String,Vec<u8>,Box<Foo>, ... - ⚠️ any library relying on other statics, e.g.,
tokio,log, - ⚠️ any struct not
#[repr(C)], - ⚠️ any data structure relying on consistent
TypeId.
In practice, transferring any of the above between libraries leads to data loss, state corruption, and usually undefined behavior.
Take particular note that this may also apply to types and methods that are invisible at the FFI boundary:
/// A method in DLL1 that wants to use a common service from DLL2
#[ffi_function]
fn use_common_service(common: &CommonService) {
// This has at least two issues:
// - `CommonService`, or ANY type nested deep within might have
// a different type layout in DLL2, leading to immediate
// undefined behavior (UB) ⚠️
// - `do_work()` here looks like it will be invoked in DLL2, but
// the code executed will actually come from DLL1. This means that
// `do_work()` invoked here will see a data structure coming from
// DLL2, but will use statics from DLL1 ⚠️
common.do_work();
}Business logic belongs in core crates, FFI only translates (M-FFI-TRANSLATES)
When Rust is used to create FFI libraries, there should be a clear separation of concerns between the core business logic crate foo and the glue crate foo-ffi.
Any operational functionality belongs in the core crate and should be expressed as idiomatic, safe, testable Rust. The FFI crate exists only to translate between native Rust and C constructs, and the core crate must not be infected with interop concerns, even if this means repeating, and slightly adjusting, type and function signatures. For example, given the following type in the core crate foo:
pub struct Message {
destination: [u8; 8],
data: Vec<u8>,
}
impl Message {
pub fn new(destination: [u8; 8], data: Vec<u8>) -> Self { /* ... */ }
pub fn transmit(&self) -> Result<(), TransmitError> { /* ... */ }
}A proper separation of concerns might collapse construction and transmission into a single FFI entry point in foo-ffi:
#[no_mangle]
pub unsafe extern "C" fn transmit_message(
destination: *const [u8; 8],
data: *const u8,
data_len: usize,
) -> u8 {
let data = std::slice::from_raw_parts(data, data_len).to_vec();
match Message::new(*destination, data).transmit() {
Ok(()) => 0,
Err(_) => 1,
}
}However, it would be improper to leak FFI requirements into foo itself: ownership, data models and signatures do not translate seamlessly between the two worlds. Any time saved by skipping a clean split will have to be paid back many times over during refactorings down the line.
#![allow(unused)] fn main() { #[repr(C)] pub struct Message { pub destination: [u8; 8], pub data_ptr: *mut u8, pub data_len: usize, pub data_cap: usize, } }
FFI crates follow established naming conventions (M-FFI-NAMING)
Crates used for FFI should follow established naming practices:
-sysfor crates defining items to call into existing (C-style) libraries-ffifor crates defining (C-style) items when called from existing applications
There are slight variations of this scheme (e.g., -sys2 when a previous -sys crate was abandoned and using - vs _), but overall -ffi clearly defines 'export' libraries, and -sys 'import' ones.
Correctness Guidelines
Unsafe needs reason, should be avoided (M-UNSAFE)
You must have a valid reason to use unsafe. The only valid reasons are
- novel abstractions, e.g., a new smart pointer or allocator,
- performance, e.g., attempting to call
.get_unchecked(), - FFI and platform calls, e.g., calling into C or the kernel, ...
Unsafe code lowers the guardrails used by the compiler, transferring some of the compiler's responsibilities to the programmer. Correctness of the resulting code relies primarily on catching all mistakes in code review, which is error-prone. Mistakes in unsafe code may introduce high-severity security vulnerabilities.
You must not use ad-hoc unsafe to
- shorten a performant and safe Rust program, e.g., 'simplify' enum casts via
transmute, - bypass
Sendand similar bounds, e.g., by doingunsafe impl Send ..., - bypass lifetime requirements via
transmuteand similar.
Ad-hoc here means unsafe embedded in otherwise unrelated code. It is of course permissible to create properly designed, sound abstractions doing these things.
In any case, unsafe must follow the guidelines outlined below.
Novel Abstractions
- Verify there is no established alternative. If there is, prefer that.
- Your abstraction must be minimal and testable.
-
It must be hardened and tested against "adversarial code", esp.
- If they accept closures they must become invalid (e.g., poisoned) if the closure panics
- They must assume any safe trait is misbehaving, esp.
Deref,CloneandDrop.
-
Any use of
unsafemust be accompanied by plain-text reasoning outlining its safety - It must pass Miri, including adversarial test cases
- It must follow all other unsafe code guidelines
Performance
-
Using
unsafefor performance reasons should only be done after benchmarking -
Any use of
unsafemust be accompanied by plain-text reasoning outlining its safety. This applies to both callingunsafemethods, as well as providing_uncheckedones. - The code in question must pass Miri
- You must follow the unsafe code guidelines
FFI
-
We recommend you use an established interop library to avoid
unsafeconstructs - You must follow the unsafe code guidelines
- You must document your generated bindings to make it clear which call patterns are permissible
Further Reading
All code must be sound (M-UNSOUND)
Unsound code is seemingly safe code that may produce undefined behavior when called from other safe code, or on its own accord.
Meaning of 'Safe' The terms safe and
unsafeare technical terms in Rust.A function is safe, if its signature does not mark it
unsafe. That said, safe functions can still be dangerous (e.g.,delete_database()), andunsafeones are, when properly used, usually quite benign (e.g.,vec.get_unchecked()).A function is therefore unsound if it appears safe (i.e., it is not marked
unsafe), but if any of its calling modes would cause undefined behavior. This is to be interpreted in the strictest sense. Even if causing undefined behavior is only a 'remote, theoretical possibility' requiring 'weird code', the function is unsound.Also see Unsafe, Unsound, Undefined.
#![allow(unused)] fn main() { // "Safely" converts types fn unsound_ref<T>(x: &T) -> &u128 { unsafe { std::mem::transmute(x) } } // "Clever trick" to work around missing `Send` bounds. struct AlwaysSend<T>(T); unsafe impl<T> Send for AlwaysSend<T> {} unsafe impl<T> Sync for AlwaysSend<T> {} }
Unsound abstractions are never permissible. If you cannot safely encapsulate something, you must expose unsafe functions instead, and document proper behavior.
No Exceptions
While you may break most guidelines if you have a good enough reason, there are no exceptions in this case: unsound code is never acceptable.
It's the Module Boundaries Note that soundness boundaries equal module boundaries! It is perfectly fine, in an otherwise safe abstraction, to have safe functions that rely on behavior guaranteed elsewhere in the same module.
#![allow(unused)] fn main() { struct MyDevice(*const u8); impl MyDevice { fn new() -> Self { // Properly initializes instance ... todo!() } fn get(&self) -> u8 { // It is perfectly fine to rely on `self.0` being valid, despite this // function in-and-by itself being unable to validate that. unsafe { *self.0 } } } }
Unsafe implies undefined behavior (M-UNSAFE-IMPLIES-UB)
The marker unsafe may only be applied to functions and traits if misuse implies the risk of undefined behavior (UB).
It must not be used to mark functions that are dangerous to call for other reasons.
#![allow(unused)] fn main() { // Valid use of unsafe unsafe fn print_string(x: *const String) { } // Invalid use of unsafe unsafe fn delete_database() { } }
Panic means 'stop the program' (M-PANIC-IS-STOP)
Panics are not exceptions. Instead, they suggest immediate program termination.
Although your code must be minimally panic-safe (i.e., a survived panic may not lead to undefined state), invoking a panic means this program should stop now. It is not valid to:
- use panics to communicate (errors) upstream,
- use panics to handle self-inflicted error conditions,
- assume panics will be caught, even by your own code.
For example, if the application calling you is compiled with a Cargo.toml containing
[profile.release]
panic = "abort"
then any invocation of panic will cause an otherwise functioning program to needlessly abort. Valid reasons to panic are:
- when encountering a programming error, e.g.,
x.expect("must never happen"), - anything invoked from const contexts, e.g.,
const { foo.unwrap() }, - when user requested, e.g., providing an
unwrap()method yourself, - when encountering a poison, e.g., by calling
unwrap()on a lock result (a poisoned lock signals another thread has panicked already).
Any of those are directly or indirectly linked to programming errors.
Detected programming bugs are panics, not errors (M-PANIC-ON-BUG)
As an extension of M-PANIC-IS-STOP above, when an unrecoverable programming error has been detected, libraries and applications must panic, i.e., request program termination.
In these cases, no Error type should be introduced or returned, as any such error could not be acted upon at runtime.
Contract violations, i.e., the breaking of invariants either within a library or by a caller, are programming errors and must therefore panic.
However, what constitutes a violation is situational. APIs are not expected to go out of their way to detect them, as such
checks can be impossible or expensive. Encountering must_be_even == 3 during an already existing check clearly warrants
a panic, while a function parse(&str) clearly must return a Result. If in doubt, we recommend you take inspiration from the standard library.
// Generally, a function with bad parameters must either
// - Ignore a parameter and/or return the wrong result
// - Signal an issue via Result or similar
// - Panic
// If in this `divide_by` we see that y == 0, panicking is
// the correct approach.
fn divide_by(x: u32, y: u32) -> u32 { ... }
// However, it can also be permissible to omit such checks
// and return an unspecified (but not an undefined) result.
fn divide_by_fast(x: u32, y: u32) -> u32 { ... }
// Here, passing an invalid URI is not a contract violation.
// Since parsing is inherently fallible, a Result must be returned.
fn parse_uri(s: &str) -> Result<Uri, ParseError> { };
Make it 'Correct by Construction' While panicking on a detected programming error is the 'least bad option', your panic might still ruin someone's day. For any user input or calling sequence that would otherwise panic, you should also explore if you can use the type system to avoid panicking code paths altogether.
Panic continuation is last resort (M-PANIC-CONTINUATION)
Panic recovery via catch_unwind() is a matter of last resort and must generally be followed by a controlled application restart.
Panics indicate the program has reached an unrecoverable state (compare M-PANIC-IS-STOP and M-PANIC-ON-BUG). Library code in particular should not attempt to catch a panic and continue execution, as there is a risk of observing otherwise impossible state:
thread_local! {
static ALWAYS_EQUAL: RefCell<(i32, i32)> = RefCell::new((0, 0));
}
fn main() {
let _ = panic::catch_unwind(|| {
ALWAYS_EQUAL.with_borrow_mut(|p| {
p.0 += 1;
panic!("Assume some user-provided closure failed here");
p.1 += 1;
});
});
ALWAYS_EQUAL.with_borrow(|p| {
assert_eq!(p.0, p.1); // Broken!
});
}Although the example above is slightly contrived, the side effects and interactions of a caught panic can be harder to identify, can have wide blast radius, and be subtle.
Systems where many unrelated tasks are in flight (e.g., server request handlers) can use catch_unwind on a per-request basis, but should still promote an application restart after a request handler caused a panic. The purpose of catch_unwind here is not to continue execution indefinitely, but to allow all other requests to gracefully finish.
Custom panics have a helpful message (M-PANIC-MESSAGE)
When code panics intentionally (via panic!, assert!, unreachable!, todo!, or similar), a message must be present to clearly state what went wrong and, where applicable, include relevant values.
// Bad, the panic gives the developer little to act on.
assert!(buffer.len() >= HEADER_SIZE);
// Good, message contains reason and actual values.
assert!(buffer.len() >= HEADER_SIZE, "buffer too small for header: got {} bytes, need {HEADER_SIZE}", buffer.len());Messages related to API misuse should be useful to the end user. Messages indicating bugs should be helpful to you-as-the-author, or whoever maintains the project after you, to quickly identify the underlying cause.
Panic messages in tests are not generally needed.
Performance Guidelines
Optimize for throughput, avoid empty cycles (M-THROUGHPUT)
You should optimize your library for throughput, and one of your key metrics should be items per CPU cycle.
This does not mean to neglect latency—after all you can scale for throughput, but not for latency. However, in most cases you should not pay for latency with empty cycles that come with single-item processing, contended locks and frequent task switching.
Ideally, you should
- partition reasonable chunks of work ahead of time,
- let individual threads and tasks deal with their slice of work independently,
- sleep or yield when no work is present,
- design your own APIs for batched operations,
- perform work via batched APIs where available,
- yield within long individual items, or between chunks of batches (see M-YIELD-POINTS),
- exploit CPU caches, temporal and spatial locality.
You should not:
- hot spin to receive individual items faster,
- perform work on individual items if batching is possible,
- do work stealing or similar to balance individual items.
Shared state should only be used if the cost of sharing is less than the cost of re-computation.
Identify, profile, optimize the hot path early (M-HOTPATH)
You should, early in the development process, identify if your crate is performance or COGS relevant. If it is:
- identify hot paths and create benchmarks around them,
- regularly run a profiler collecting CPU and allocation insights,
- document or communicate the most performance sensitive areas.
For benchmarks we recommend criterion or divan. If possible, benchmarks should not only measure elapsed wall time, but also used CPU time over all threads (this unfortunately requires manual work and is not supported out of the box by the common benchmark utils).
Profiling Rust on Windows works out of the box with Intel VTune
and Superluminal. However, to gain meaningful CPU insights you should enable debug symbols for benchmarks in your Cargo.toml:
[profile.bench]
debug = 1
Documenting the most performance sensitive areas helps other contributors take better decision. This can be as simple as sharing screenshots of your latest profiling hot spots.
Further Reading
How much faster? Some of the most common 'language related' issues we have seen include:
- frequent re-allocations, esp. cloned, growing or
format!assembled strings,- short lived allocations over bump allocations or similar,
- memory copy overhead that comes from cloning Strings and collections,
- repeated re-hashing of equal data structures
- the use of Rust's default hasher where collision resistance wasn't an issue
Anecdotally, we have seen ~15% benchmark gains on hot paths where only some of these
Stringproblems were addressed, and it appears that up to 50% could be achieved in highly optimized versions.
Long-running tasks should have yield points (M-YIELD-POINTS)
If you perform long running computations, they should contain yield_now().await points.
Your future might be executed in a runtime that cannot work around blocking or long-running tasks. Even then, such tasks are considered bad design and cause runtime overhead. If your complex task performs I/O regularly it will simply utilize these await points to preempt itself:
async fn process_items(items: &[items]) {
// Keep processing items, the runtime will preempt you automatically.
for i in items {
read_item(i).await;
}
}If your task performs long-running CPU operations without intermixed I/O, it should instead cooperatively yield at regular intervals, to not starve concurrent operations:
async fn process_items(zip_file: File) {
let items = zip_file.read().async;
for i in items {
decompress(i);
yield_now().await;
}
}If the number and duration of your individual operations are unpredictable you should use APIs such as has_budget_remaining() and
related APIs to query your hosting runtime.
Yield how often? In a thread-per-core model the overhead of task switching must be balanced against the systemic effects of starving unrelated tasks.
Under the assumption that runtime task switching takes 100's of ns, in addition to the overhead of lost CPU caches, continuous execution in between should be long enough that the switching cost becomes negligible (<1%).
Thus, performing 10 - 100μs of CPU-bound work between yield points would be a good starting point.
Reuse allocations where possible (M-MEM-REUSE)
When designing APIs you should allow users to hold onto reusable resources. Inside your code you should make use of them where available.
The cost of repeated allocations inside hot loops can be significant, and from a user's perspective they can be invisible unless profiled:
// Bad, API design forces new allocation per element.
for id in ids {
let value = db.get(id);
}While this style of API may exist for convenience, it should be auxiliary. Instead, the core APIs should allow users to own the underlying object and re-use it:
// Good, allows users to decide whether a new allocation is needed.
let mut value = Value::new();
for id in ids {
db.get_in(id, &mut value);
}The canonical method on reusable types to reuse them is .clear(), as can be found on many std items. Multiple flavors of this pattern exist. In simple cases user-owned types can hold a preexisting, reusable collection directly:
#![allow(unused)] fn main() { struct Value { data: Vec<u8> } }
In heavyweight, deeply nested libraries it can be worthwhile to either pass a bump-style Arena, or to encapsulate one inside the user types, so it can be used throughout the call stack:
struct Query {
arena: Arena,
request: Request,
data: Vec<u8>
}
fn client_do_work(query: &mut Query) {
let request = rewrite_request(&query.request, &query.arena);
get_in(request, &mut query.data);
}Library telemetry does not tank performance (M-LOG-OVERHEAD)
Library code that emits telemetry should ensure that doing so does not meaningfully impact throughput or latency on the hot path.
Crates offered to 3rd parties emitting logs or metrics should assume telemetry will be permanently enabled, or under load. Care should therefore be taken that the volume and overhead of emitted events is reasonable, and will not cause excessive performance degradation.
Hot, inner loops should preferably stay free of telemetry emission entirely. If it can't be avoided, the events emitted should be lightweight and avoid allocations (e.g., format! string concatenation).
// Bad, logs each message and invokes allocation-based formatting.
for m in messages {
log(format!("Emitting message {}", m.id()))
}
// Better, avoids per-message allocations.
for m in messages {
log(("Emitting message", m.id()))
}
// Best: If possible, let telemetry users reconstruct what happened offline
log(("Processing message batch", messages.batch_id()))
for m in messages { ... }Nested type hierarchies should avoid needless indirection (M-AVOID-INDIRECTION)
Hot types should avoid nested heap indirection and consider lifting hot, cacheable deep fields to improve cache utilization.
While the gold standard is to benchmark, a pattern that emerges repeatedly when porting C# code to Rust is to reflexively Arc nested types, often multiple layers deep. Although this can make sense on very wide or heavyweight types that genuinely need to be shared by multiple owners, this pattern can ruin access latency when multiple rounds of DRAM lookup have to be performed sequentially.
Where nested, shared ownership isn't strictly needed, it is usually better to start with local, embedded data, and lift cacheable fields.
// Bad, `print` (assuming it is reasonably hot) needs 2 indirections
// to query whether it is enabled.
struct Item {
config: Arc<Config>,
payload: Payload,
}
struct Config {
feature: Arc<Feature>
}
impl Item {
fn print(&self) {
if self.config.feature.is_enabled() { ... }
}
}
// Better: `enabled` resides nearby and is likely immediately available
// once `print` is called.
struct Item {
config: Arc<Config>,
payload: Payload,
enabled: bool,
}
impl Item {
fn print(&self) {
if self.enabled { ... }
}
}
Use boxed slices and strings for immutable owned sequences (M-BOX-DST)
Frequently used, internal, immutable sequences that will not be resized after construction should be stored as Box<[T]>, Arc<str> or similar, rather than their original Vec<T> or String counterparts.
Regular growable collections consist of a (ptr, len, capacity) triple. Converting them to boxed slices makes them immutable, executes a shrink-to-fit, and drops the capacity bit, reducing their handle size by 1/3. For this pattern to be useful, the following preconditions should apply:
- the sequence should be frequently instantiated (e.g., >1000's of instances),
- it must be immutable,
- it should not be user-visible, i.e., regular users would just deal with
&stror similar.
Some collections provide dedicated methods for this, e.g., String::into_boxed_str.
// Bad, with many entries this wastes space and makes
// traversal ultimately slower.
struct Data {
ids: Vec<String>
}
// Good, reduces memory consumption and fits more elements
// into cache.
struct Data {
ids: Vec<Box<str>>
}Shrink collections to fit after building (M-SHRINK-TO-FIT)
Where large, long-lived, growable collections such as Vec or String were built without an exact size reservation (compare M-INITIAL-CAPACITY), the resulting collection should be shrunk via shrink_to_fit before storing it.
Many Rust collections grow by powers of two when iteratively adding elements. In the worst case a collection might therefore use ~2x of its needed memory.
// Bad, long lived object might end up using 2x needed memory.
let mut long_lived = Vec::new();
for x in large_iter {
long_lived.push(x);
}
// Good, frees up extra memory.
long_lived.shrink_to_fit();Note that this does not apply to conversions done via into_boxed_* and friends (compare M-BOX-DST), as these generally shrink before converting already.
Use a fast hasher where possible (M-FAST-HASHER)
When hashing trusted, internal keys, prefer a fast non-cryptographic hasher (e.g., foldhash, FxHash) over the standard library default.
Rust's default hasher is reasonably DoS safe on untrusted user input, but this comes at a performance penalty. If you can trust that keys are not maliciously crafted to overflow individual buckets, a custom fast hasher can yield significant performance gains.
// Bad, uses default hasher for keys we control.
let lookup = HashMap::<UserID, Data>::with_capacity(1024);
// Good, uses faster foldhash for internal keys.
let lookup = foldhash::HashMap<UserID, Data>::with_capacity(1024);
<!-- Copyright (c) Microsoft Corporation. Licensed under the MIT license. -->
# Collections are created with sufficient initial capacity (M-INITIAL-CAPACITY) { #M-INITIAL-CAPACITY }
<why>efficient collection creation.</why>
Where the final or approximate size of a collection (`Vec`, `String`, `HashMap`, `HashSet`, etc.) is known at construction time, it should be created via `with_capacity` rather than `new` or `default`.
Collections created without capacity may be re-allocated multiple times during their initialization, which also includes copying their content. Creating them with sufficient capacity can entirely avoid this needless overhead.
```rust,ignore
// Bad, probably re-allocates and copies content over multiple times.
let mut rval = Vec::new();
for x in &other {
rval.push(convert(x));
}
// Better, creates collection with sufficient capacity upfront.
let mut rval = Vec::with_capacity(other.len());
for x in &other {
rval.push(convert(x));
}Iterator-driven construction (collect) inherits this behavior via size_hint and should be preferred over manual push loops when possible:
// Ideal, looks nicer and is performant
let rval: Vec<_> = other.iter().map(convert).collect();Hot async functions reduce stack size (M-ASYNC-STACK-SIZE)
Functions marked async in the hot path should track their future sizes, and take one or more of the following steps to reduce their impact:
- reduction of parameter and rval type size,
- reduction of type size of items held across
.awaitpoints, - returning
impl Futureand extracting setup logic fromasync {}capture.
Future 'Stack' Sizes In Futures, what would naively be considered their stack, is actually part of a significantly more complicated machinery under their hood.
Regular locals, that only live momentarily between two
.awaitpoints, still remain part of the runtime thread's regular stack. However, any locals that live across.awaitpoints, or parameters passed during construction, become part of that Future's state machine type, and the layout of this type is currently not as optimized as it could be.This not only can cause stack-to-heap memcpy operations when creating or boxing Futures, it can also force large upfront stack sizes of the hypothetical most deeply nested cross-async call stack of the involved async function (which, on a side note, is why they can't simply recurse).
async fn foo(_large: Large) { let within_future = [0_u8; 1024]; // Crosses .await below, embedded in `foo` type let on_stack = [0_u8; 1024]; // Does not cross .await points, lives on stack let sneaky = Droppable::with_size(1024); // Secretly crosses .await point! dbg!(&on_stack, &sneaky); bar(&within_future).await; dbg!(&within_future); // <- `sneaky` dropped here, despite otherwise not being used! } let future = foo(Large::new()); // `Large` becomes embedded in `foo` type, // blowing up its size, despite it not even // being used. // Here, despite `foo` not running yet, we might consume up to `Large` + // 2kb of this thread's stack memory. Once we spawn this is memcpy'ed // to runtime Task structure: rt.spawn(future);
For many async functions this isn't an issue, as their associated Future-cost is negligible. However, functions used along the hot path, that are either called or instantiated frequently (e.g., 1000's of calls per second or concurrent tasks) might benefit from monitoring and optimizations.
Hot futures should be tracked via size_of_val:
async fn hot() { ... }
#[test]
fn has_reasonable_size() {
let f = hot();
assert!(size_of_val(&f) < ...); // Determine value / limit at first run.
}Then consider a combination of the following:
// 1) Return an `impl Future` instead, this prevents large arguments
// from infecting the future size, among others.
fn hot(args: Args) -> impl Future<Output = Result<T>> {
// 2) Process arguments outside async context if processing does
// not require async functionality.
let args = args.do_something();
if args.invalid() {
// 3) Use `Either` to return a single `impl Future` type, as
// otherwise you'd have to invent a new type.
async { Err(InvalidArgs) }.left_future()
} else {
// 4) Chain future invocations via future helpers, which again
// prevents heavy locals from being passed through the state
// machine.
read(args).then(|x| foo(x)).right_future()
}
}Project Guidelines
Common settings come from the workspace Cargo.toml (M-CARGO-WORKSPACE)
Any repo with two or more crates that somehow belong together should unify these crates with a workspace Cargo.toml. Members then inherit shared metadata and dependency versions from the workspace root via [workspace.dependencies], [workspace.lints], ... rather than duplicating these values in each crate.
Where a dependency is crate-specific, it should still be defined in the workspace. Workspace definitions should generally not enable dependency features (except basic ones such as ["std"]), and should instead use default-features = false.
The workspace lists and versions all crates (M-CRATES-IN-WORKSPACE)
Every crate produced by the project should be listed as a workspace member, and its version should be declared in [workspace.dependencies] so that intra-workspace dependencies resolve to a single canonical version.
# Bad, crate links its sibling directly
[dependencies]
sibling.path = "../sibling"
# Good, going through workspace
[dependencies]
sibling.workspace = true
[workspace.dependencies]
sibling = { path = "crates/sibling", version = "0.5.2" }
All crates are siblings in one folder (M-CRATES-FLAT-FOLDER)
A repository should contain a single workspace Cargo.toml, and all Rust crates should be subordinate to it. All crates should then live in a single, direct subdirectory (e.g., crates/) below the workspace (for up to 1-2 dozen of crates), beyond that some folder hierarchy should be used (e.g., common/, server/, client/) to organize siblings.
# Ideal for most workspaces
Cargo.toml
crates/
foo/Cargo.toml
foo_core/Cargo.toml
foo_proc/Cargo.toml
foo_tests/Cargo.toml
bar/Cargo.toml
baz/Cargo.toml
# Ok for large workspaces
Cargo.toml
crates/
server/
main/Cargo.toml
routes/Cargo.toml
client/
foo/Cargo.toml
bar/Cargo.toml
common/
error/Cargo.toml
Placing crates inside other crates (at or below their Cargo.toml), or even inside their src/ folder is never acceptable. If a crate relationship should be expressed, this is done via common prefixes instead (e.g., foo, foo_util, foo_build).
# Never acceptable, crates inside `src/` folder
Cargo.toml
crates/
foo/Cargo.toml
src/lib.rs
deps/bar/Cargo.toml
Rare exceptions to this rule can occur if your crate is in the business of processing workspaces and has a collection of UI tests or similar it relies on; but even then these are usually dummy crates in nature.
New crates target latest edition (M-LATEST-EDITION)
When creating a new crate or workspace, set edition to the latest stable edition (at least 2024 at the time of writing); the resolver field is generally not needed.
Using an older edition generally has no upsides for new projects, but forces you to write 'old Rust' that is less idiomatic and has worse UX edge cases. Notably, using an older edition does not grant any compatibility benefits with the rest of the ecosystem. An application based on 2015 can use libraries written for 2024 just fine.
MSRV is conservatively updated (M-MSRV)
A Minimum Supported Rust Version (MSRV) should be set when libraries are first created. It can be updated as new Rust features are needed, but should be kept a few versions behind the most recent compiler release.
The ecosystem expectation is that projects are compiled with a reasonably modern Rust compiler.
Bumping MSRV therefore does not require a major release, but can be handled through a minor update (e.g., 1.3 to 1.4). In fact, any project depending on 3rd party crates is already inherently bound to this contract; forcing a major version bump will not confer any benefits, but could possibly bifurcate downstream dependencies.
Documentation
First sentence is one line; approx. 15 words (M-FIRST-DOC-SENTENCE)
When you document your item, the first sentence becomes the "summary sentence" that is extracted and shown in the module summary:
#![allow(unused)] fn main() { /// This is the summary sentence, shown in the module summary. /// /// This is other documentation. It is only shown in that item's detail view. /// Sentences here can be as long as you like and it won't cause any issues. fn some_item() { } }
Since Rust API documentation is rendered with a fixed max width, there is a naturally preferred sentence length you should not exceed to keep things tidy on most screens.
If you keep things in a line, your docs will become easily skimmable. Compare, for example, the standard library:

Otherwise, you might end up with widows and a generally unpleasant reading flow:

As a rule of thumb, the first sentence should not exceed 15 words.
Has comprehensive module documentation (M-MODULE-DOCS)
Any public library module must have //! module documentation, and the first sentence must follow M-DOC-FIRST-SENTENCE.
pub mod ffi {
//! Contains FFI abstractions.
pub struct String {};
}The rest of the module documentation should be comprehensive, i.e., cover the most relevant technical aspects of the contained items, including
- what the module contains
- when it should be used, possibly when not
- examples
- subsystem specifications (e.g.,
std::fmtalso describes its formatting language) - observable side effects, including what guarantees are made about these, if any
- relevant implementation details, e.g., the used system APIs
Great examples include:
This does not mean every module should contain all of these items. But if there is something to say about the interaction of the contained types, their module documentation is the right place.
Documentation has canonical sections (M-CANONICAL-DOCS)
Public library items must contain the canonical doc sections. The summary sentence must always be present. Extended documentation and examples are strongly encouraged. The other sections must be present when applicable.
#![allow(unused)] fn main() { /// Summary sentence < 15 words. /// /// Extended documentation in free form. /// /// # Examples /// One or more examples that show API usage like so. /// /// # Errors /// If fn returns `Result`, list known error conditions /// /// # Panics /// If fn may panic, list when this may happen /// /// # Safety /// If fn is `unsafe` or may otherwise cause UB, this section must list /// all conditions a caller must uphold. /// /// # Abort /// If fn may abort the process, list when this may happen. pub fn foo() {} }
In contrast to other languages, you should not create a table of parameters. Instead parameter use is explained in plain text. In other words, do not
/// Copies a file.
///
/// # Parameters
/// - src: The source.
/// - dst: The destination.
fn copy(src: File, dst: File) {}but instead:
/// Copies a file from `src` to `dst`.
fn copy(src: File, dst: File) {}Related Reading
- Function docs include error, panic, and safety considerations (C-FAILURE)
Mark pub use items with #[doc(inline)] (M-DOC-INLINE)
When publicly re-exporting crate items via pub use foo::Foo or pub use foo::*, they show up in an opaque re-export block. In most cases, this is not
helpful to the reader:
Instead, you should annotate them with #[doc(inline)] at the use site, for them to be inlined organically:
pub(crate) mod foo { pub struct Foo; }
#[doc(inline)]
pub use foo::*;
// or
#[doc(inline)]
pub use foo::Foo;
This does not apply to std or 3rd party types; these should always be re-exported without inlining to make it clear they are external.
Still avoid glob exports The
#[doc(inline)]trick above does not change M-NO-GLOB-REEXPORTS; you generally should not re-export items via wildcards.
AI Guidelines
Design with AI use in mind (M-DESIGN-FOR-AI)
As a general rule, making APIs easier to use for humans also makes them easier to use by AI. If you follow the guidelines in this book, you should be in good shape.
Rust's strong type system is a boon for agents, as their lack of genuine understanding can often be counterbalanced by comprehensive compiler checks, which Rust provides in abundance.
With that said, there are a few guidelines which are particularly important to help make AI coding in Rust more effective:
-
Create Idiomatic Rust API Patterns. The more your APIs, whether public or internal, look and feel like the majority of Rust code in the world, the better it is for AI. Follow the Rust API Guidelines along with the guidelines from Library / UX.
-
Provide Thorough Docs. Agents love good detailed docs. Include docs for all of your modules and public items in your crate. Assume the reader has a solid, but not expert, level of understanding of Rust, and that the reader understands the standard library. Follow C-CRATE-DOC, C-FAILURE, C-LINK, and M-MODULE-DOCS M-CANONICAL-DOCS.
-
Provide Thorough Examples. Your documentation should have directly usable examples, the repository should include more elaborate ones. Follow C-EXAMPLE C-QUESTION-MARK.
-
Use Strong Types. Avoid primitive obsession by using strong types with strict well-documented semantics. Follow C-NEWTYPE.
-
Make Your APIs Testable. Design APIs which allow your customers to test their use of your API in unit tests. This might involve introducing some mocks, fakes, or cargo features. AI agents need to be able to iterate quickly to prove that the code they are writing that calls your API is working correctly.
-
Ensure Test Coverage. Your own code should have good test coverage over observable behavior. This enables agents to work in a mostly hands-off mode when refactoring.
Items are only visible through one path (M-SINGLE-ITEM-PATH)
Public items within a crate should be reachable only through one path. For example some crate::db::Connection should not also be visible as crate::Connection:
// Not OK
pub mod db {
pub struct Connection;
}
pub use db::Connection;This rule is often violated by agents creating or refactoring large code bases over several iterations. In an attempt to simplify their task, they re-export items under multiple paths, often previous ones from before some change, instead of cleanly redesigning structures where it makes sense.
Note this only targets the duplication of user-facing items. Within a crate it is acceptable (and often unavoidable) to see the same item multiple times as export trees are constructed:
// OK
pub(crate) mod db {
pub struct Connection;
}
pub use db::Connection;Similarly, re-exports of foreign items are not covered by this rule, although they should follow M-FOREIGN-REEXPORTS.
Likewise, this rule also does not apply to public-but-hidden _private modules needed by macros, compare M-MACRO-HELPERS.
Avoid meta design documentation (M-NO-META-DESIGN-DOCUMENTATION)
Crate and module documentation must be free of meta design narratives that were only relevant during the creation of a crate. In other words, it is the end-state that is to be documented, not the design journey.
Agents frequently produce sections that describe how a change was designed, "why we picked X over Y" essays, and design journals inside user-facing documentation. These artifacts might be interesting diagnostics while working on the project, but they are mostly meaningless to end users.
For example, an agent might append a self-report like this, summarizing which guidelines it claims to have followed:
| Rule | Applied | Where |
| --- | :---: | --- |
| M-SHORT-NAMES | ✅ | Shortened method names across the data-access and HTTP handler layers. |
| M-WEASEL-WORDS | ✅ | Removed weasel words from type and field names throughout the public API. |
| M-PUBLIC-DISPLAY | ✅ | Added `Display` impls for all user-facing identifier and error types. |
| M-ASYNC-FN | ✅ | Migrated I/O-facing APIs from `impl Future` returns to `async fn`. |
This kind of content describes process, not behaviour, and goes stale over time. That said, it is of course perfectly reasonable to have a Design Principles or similar section in the project's README, that on a high level describes the enduring architectural goals that are relevant to end users (e.g., a crate being allocation free, having an OSI architecture, or being designed with #[no_std] in mind).
Tests do not assert ground truth (M-TAUTOLOGICAL-TESTS)
Unit tests should verify meaningful behavior instead of repeating foundational definitions.
Agents frequently produce tests that re-state the expected value from the same logic the code under test uses, or that simply mirror the implementation's branches. Such tests pass by construction, provide virtually no value, but increase the noise floor of subsequent changes:
#![allow(unused)] fn main() { const CHECKPOINTS: [u32; 4] = [0, 90, 180, 270]; #[test] fn checkpoints_are_correct() { assert_eq!(CHECKPOINTS, [0, 90, 180, 270]); } }
Where these are used to satisfy mutation tests, the mutation test should be skipped instead.
Instead, a meaningful test would check a property the constants are supposed to satisfy, for example that they are evenly spaced, monotonically increasing, or impose some direction in related logic.
Rust code solves Rust problems (M-RUST-SHAPED)
When (automatically) porting C#, Java, C++, or similar code to Rust, technical constructs must not be copied 1-on-1.
It is prudent to separate domain aspects from language aspects. Domain aspects address business problems. An algorithm to compute prime numbers or logic for processing a customer table can (and should) work the same when translating between languages.
However, many patterns exist to solve problems particular to the ecosystem they stem from. The Rust ecosystem has its own problems, and these need to be addressed by idioms that work for Rust. These include
- error handling,
- management of tasks and threads,
- component abstractions and their lifetimes,
- ownership of parameters,
- the absence of 'object-oriented' programming,
- structural differences between interfaces and traits,
- and many others.
While some language constructs simply don't translate at all (e.g., compared to C#, Rust does not have any meaningful reflection), others are deceptively similar and might only bite months down the line (e.g., statics, compare M-AVOID-STATICS).
As a rule of thumb, structs and their methods can have vaguely similar names, flows, inputs and outputs, as far as their business functionality is concerned. However, any striking technical similarity between Rust and { C#, Java, Python, ... } implementations is indicative of deeper architectural problems; a throw_if_null() never makes sense.
Agents & LLMs
While these guidelines have been carefully handcrafted, they have been written with LLM consumption in mind. We offer condensed versions you can include in your agent sessions when authoring or reviewing code.
Available Resources
Changelog
This page tracks notable changes to the Pragmatic Rust Guidelines.
2026.6
This update substantially expanded the guidelines, adding 41 new entries spanning macros, performance, project layout, FFI, AI-assisted development, and more:
| Guideline | Title |
|---|---|
| M-ASYNC-FN | Functions are async over returning a Future |
| M-ASYNC-STACK-SIZE | Hot async functions reduce stack size |
| M-AVOID-INDIRECTION | Nested type hierarchies should avoid needless indirection |
| M-BALANCED-MODULES | Modules are balanced in size and scope |
| M-BOX-DST | Use boxed slices and strings for immutable owned sequences |
| M-BUILD-RESULT | Builders validate in final .build() |
| M-CARGO-WORKSPACE | Common settings come from the workspace Cargo.toml |
| M-COLLECTION-TRAITS | Collections implement the appropriate iter traits |
| M-CRATES-FLAT-FOLDER | All crates are siblings in one folder |
| M-CRATES-IN-WORKSPACE | The workspace lists and versions all crates |
| M-EXAMPLE-OVER-PROC | Prefer 'macros by example' over proc macros |
| M-FAST-HASHER | Use a fast hasher where possible |
| M-FFI-NAMING | FFI crates follow established naming conventions |
| M-FFI-TRANSLATES | Business logic belongs in core crates, FFI only translates |
| M-FOREIGN-REEXPORTS | Items come from their original crate |
| M-FROM-ERROR | Canonical error conversion uses From, not map_err |
| M-INITIAL-CAPACITY | Collections are created with sufficient initial capacity |
| M-INTEGRATION-TESTS | Integration tests live under tests/ |
| M-LATEST-EDITION | New crates target latest edition |
| M-LOG-NOT-PRINT | Production code uses telemetry, not println |
| M-LOG-OVERHEAD | Library telemetry does not tank performance |
| M-MACRO-HELPERS | Third party items come from hidden _private module |
| M-MACRO-LAST-RESORT | Macros are a last resort |
| M-MACRO-MAIN-CRATE | Macros assume main crate |
| M-MACROS-DONT-LIE | Macros don't lie about signatures |
| M-MEM-REUSE | Reuse allocations where possible |
| M-MSRV | MSRV is conservatively updated |
| M-NO-META-DESIGN-DOCUMENTATION | Avoid meta design documentation |
| M-NO-PRELUDE | Don't define preludes |
| M-PANIC-CONTINUATION | Panic continuation is last resort |
| M-PANIC-MESSAGE | Custom panics have a helpful message |
| M-PARAMETER-CONSISTENCY | Parameter ordering is consistent |
| M-PROC-IMPL | Proc macros should have separate impl crate incl. tests |
| M-PROC-IMPLIED-ITEMS | Proc macros don't produce implied or hidden items |
| M-RUST-SHAPED | Rust code solves Rust problems |
| M-SHORT-NAMES | Names of items are short |
| M-SHRINK-TO-FIT | Shrink collections to fit after building |
| M-SINGLE-ITEM-PATH | Items are only visible through one path |
| M-STRONG-TYPES-GUARD | Newtypes guard their invariants |
| M-TARGET-CPU | Applications target highest viable target-cpu |
| M-TAUTOLOGICAL-TESTS | Tests do not assert ground truth |
We also removed the guideline-specific versioning.
2025
Initial release of the Pragmatic Rust Guidelines.
FAQ
How can I contribute?
Go to our GitHub page and file an issue or PR. New guidelines should be compatible with the meta design principles.
I disagree with a guideline ...
If you find a mistake or issue, let us know. Also let us know if a must guideline interferes with a valid use case. If you disagree with a should guideline, there are usually valid exceptions we haven't documented. If you think a should guideline generally leads to worse outcomes, let us know.