Challenge 4: Explore and Analyze FHIR EHR Data
< Previous Challenge - Home - Next Challenge>
Introduction
In this challenge, you will deploy the OSS FHIR-to-Synapse Analytics Pipeline to move FHIR data from Azure FHIR service to a Azure Data Lake storage in near real time and making it available to a Synapse workspace, which will enable you to query against the entire FHIR dataset with tools such as Synapse Studio, SSMS, and/or Power BI.
This pipeline is an Azure Function solution that extracts data from the FHIR server using FHIR Resource APIs, converts them to hierarchical Parquet files, and writes them to Azure Data Lake storage in near real time. It contains a script to create External Tables and Views in Synapse Serverless SQL pool pointing to the Parquet files. You can also access the Parquet files directly from a Synapse Spark Pool to perform custom transformation to downstream systems, i.e. USCDI datamart, etc.
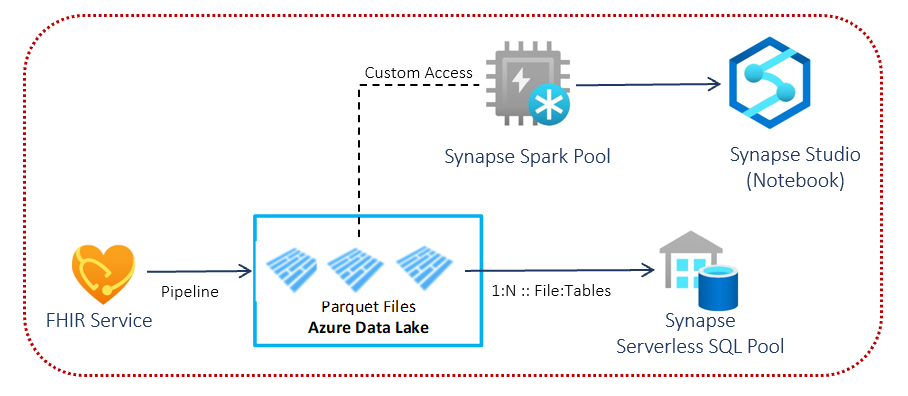
Description
You need to deploy an instance of FHIR service (done in challenge 1) and a Synapse Workspace.
- Deploy the FHIR-to-Synapse Analytics Pipeline
- To deploy the pipeline, run this ARM template for pipeline deployment through the Azure Portal.
- Provide Access of the FHIR server to the Azure Function
- Assign the FHIR Data Reader role to the Azure Function created from the deployment above
-
Verify the data movement as the function app deployed will run automatically and the time taken to write the FHIR dataset to the storage account will depend on the amount of data stored in the FHIR server.
Hint:
- You will see folders for only those Resources that are present in your FHIR server. Running the PowerShell script will create folders for other Resources.
- Provide privilege to your account
- You must provide the following roles to your account to run the PowerShell script in the next step (and revoke these roles after the installation if needed)
- Assign Synapse Administrator role in your Synapse Workspace
- Assign the Storage Blob Data Contributor role in your Storage Account for running the PowerScript below.
- You must provide the following roles to your account to run the PowerShell script in the next step (and revoke these roles after the installation if needed)
- Provide access of the Storage Account to the Synapse Workspace
- Assign the Storage Blob Data Contributor role to your Synapse Workspace.
- Run the PowerShell script
- Run the PowerShell script to create External Tables and Views in Synapse Serverless SQL Pool pointing to the Parquet files in the Storage Account.
Success Criteria
- You have verfied that Parquet files are stored in the Storage Account after the Azure Function execution is completed
- You have verified that there are folders corresponding to different FHIR resources in the container’s results folder.
- You have queried the
fhirdbdata in Synapse Studio to explore the External Tables and Views to see the exported FHIR resource entities. - You have validated that new persisted FHIR data are fetched automatically to the Data Lake and are available for querying.