
TL;DR:
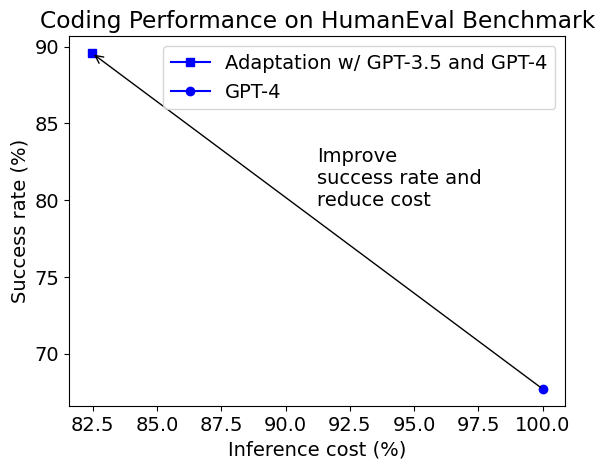
- A case study using the HumanEval benchmark shows that an adaptive way of using multiple GPT models can achieve both much higher accuracy (from 68% to 90%) and lower inference cost (by 18%) than using GPT-4 for coding.
GPT-4 is a big upgrade of foundation model capability, e.g., in code and math, accompanied by a much higher (more than 10x) price per token to use over GPT-3.5-Turbo. On a code completion benchmark, HumanEval, developed by OpenAI, GPT-4 can successfully solve 68% tasks while GPT-3.5-Turbo does 46%. It is possible to increase the success rate of GPT-4 further by generating multiple responses or making multiple calls. However, that will further increase the cost, which is already nearly 20 times of using GPT-3.5-Turbo and with more restricted API call rate limit. Can we achieve more with less?
In this blog post, we will explore a creative, adaptive way of using GPT models which leads to a big leap forward.
Observations
- GPT-3.5-Turbo can already solve 40%-50% tasks. For these tasks if we never use GPT-4, we can save nearly 40-50% cost.
- If we use the saved cost to generate more responses with GPT-4 for the remaining unsolved tasks, it is possible to solve some more of them while keeping the amortized cost down.
The obstacle of leveraging these observations is that we do not know a priori which tasks can be solved by the cheaper model, which tasks can be solved by the expensive model, and which tasks can be solved by paying even more to the expensive model.
To overcome that obstacle, one may want to predict which task requires what model to solve and how many responses are required for each task. Let's look at one example code completion task:
def vowels_count(s):
"""Write a function vowels_count which takes a string representing
a word as input and returns the number of vowels in the string.
Vowels in this case are 'a', 'e', 'i', 'o', 'u'. Here, 'y' is also a
vowel, but only when it is at the end of the given word.
Example:
>>> vowels_count("abcde")
2
>>> vowels_count("ACEDY")
3
"""
Can we predict whether GPT-3.5-Turbo can solve this task or do we need to use GPT-4? My first guess is that GPT-3.5-Turbo can get it right because the instruction is fairly straightforward. Yet, it turns out that GPT-3.5-Turbo does not consistently get it right, if we only give it one chance. It's not obvious (but an interesting research question!) how to predict the performance without actually trying.
What else can we do? We notice that: It's "easier" to verify a given solution than finding a correct solution from scratch.
Some simple example test cases are provided in the docstr. If we already have a response generated by a model, we can use those test cases to filter wrong implementations, and either use a more powerful model or generate more responses, until the result passes the example test cases. Moreover, this step can be automated by asking GPT-3.5-Turbo to generate assertion statements from the examples given in the docstr (a simpler task where we can place our bet) and executing the code.
Solution
Combining these observations, we can design a solution with two intuitive ideas:
- Make use of auto-generated feedback, i.e., code execution results, to filter responses.
- Try inference configurations one by one, until one response can pass the filter.
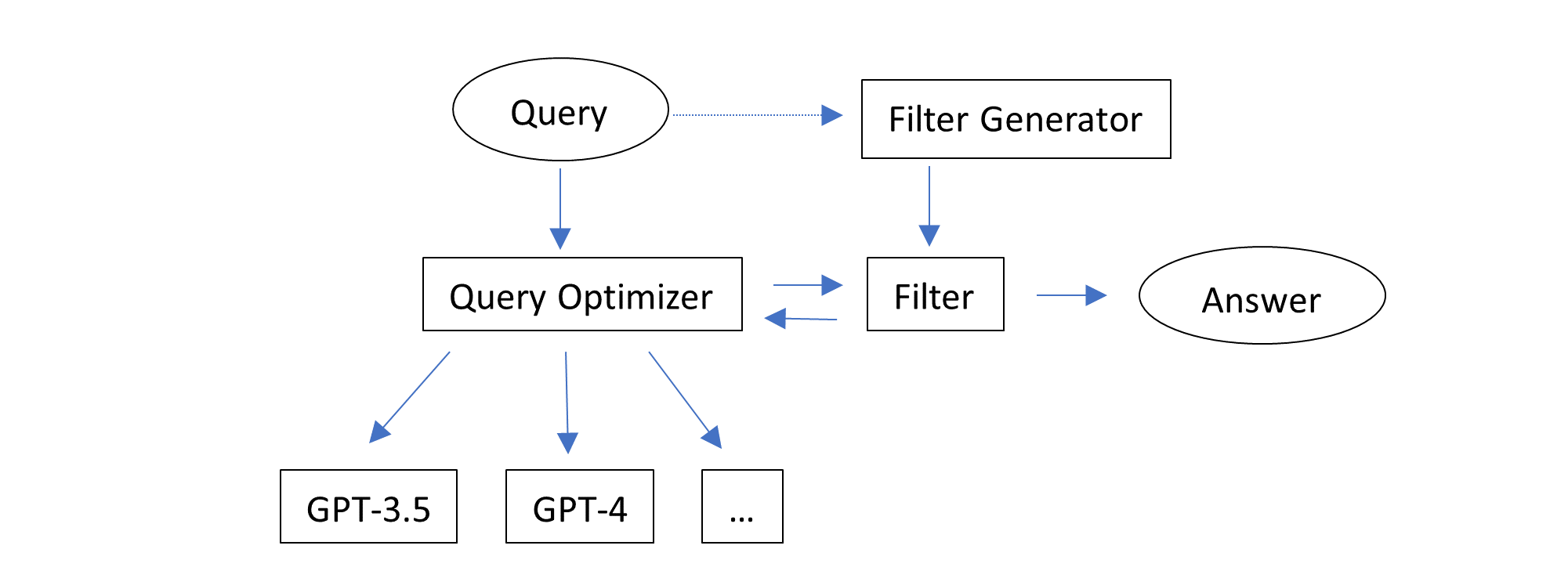
This solution works adaptively without knowing or predicting which task fits which configuration. It simply tries multiple configurations one by one, starting from the cheapest configuration. Note that one configuration can generate multiple responses (by setting the inference parameter n larger than 1). And different configurations can use the same model and different inference parameters such as n and temperature. Only one response is returned and evaluated per task.
An implementation of this solution is provided in autogen. It uses the following sequence of configurations:
- GPT-3.5-Turbo, n=1, temperature=0
- GPT-3.5-Turbo, n=7, temperature=1, stop=["\nclass", "\ndef", "\nif", "\nprint"]
- GPT-4, n=1, temperature=0
- GPT-4, n=2, temperature=1, stop=["\nclass", "\ndef", "\nif", "\nprint"]
- GPT-4, n=1, temperature=1, stop=["\nclass", "\ndef", "\nif", "\nprint"]
Experiment Results
The first figure in this blog post shows the success rate and average inference cost of the adaptive solution compared with default GPT-4. The inference cost includes the cost for generating the assertions in our solution. The generated assertions are not always correct, and programs that pass/fail the generated assertions are not always right/wrong. Despite of that, the adaptive solution can increase the success rate (referred to as pass@1 in the literature) from 68% to 90%, while reducing the cost by 18%.
Here are a few examples of function definitions which are solved by different configurations in the portfolio.
- Solved by GPT-3.5-Turbo, n=1, temperature=0
def compare(game,guess):
"""I think we all remember that feeling when the result of some long-awaited
event is finally known. The feelings and thoughts you have at that moment are
definitely worth noting down and comparing.
Your task is to determine if a person correctly guessed the results of a number of matches.
You are given two arrays of scores and guesses of equal length, where each index shows a match.
Return an array of the same length denoting how far off each guess was. If they have guessed correctly,
the value is 0, and if not, the value is the absolute difference between the guess and the score.
example:
compare([1,2,3,4,5,1],[1,2,3,4,2,-2]) -> [0,0,0,0,3,3]
compare([0,5,0,0,0,4],[4,1,1,0,0,-2]) -> [4,4,1,0,0,6]
"""
- Solved by GPT-3.5-Turbo, n=7, temperature=1, stop=["\nclass", "\ndef", "\nif", "\nprint"]: the
vowels_countfunction presented earlier. - Solved by GPT-4, n=1, temperature=0:
def string_xor(a: str, b: str) -> str:
""" Input are two strings a and b consisting only of 1s and 0s.
Perform binary XOR on these inputs and return result also as a string.
>>> string_xor('010', '110')
'100'
"""
- Solved by GPT-4, n=2, temperature=1, stop=["\nclass", "\ndef", "\nif", "\nprint"]:
def is_palindrome(string: str) -> bool:
""" Test if given string is a palindrome """
return string == string[::-1]
def make_palindrome(string: str) -> str:
""" Find the shortest palindrome that begins with a supplied string.
Algorithm idea is simple:
- Find the longest postfix of supplied string that is a palindrome.
- Append to the end of the string reverse of a string prefix that comes before the palindromic suffix.
>>> make_palindrome('')
''
>>> make_palindrome('cat')
'catac'
>>> make_palindrome('cata')
'catac'
"""
- Solved by GPT-4, n=1, temperature=1, stop=["\nclass", "\ndef", "\nif", "\nprint"]:
def sort_array(arr):
"""
In this Kata, you have to sort an array of non-negative integers according to
number of ones in their binary representation in ascending order.
For similar number of ones, sort based on decimal value.
It must be implemented like this:
>>> sort_array([1, 5, 2, 3, 4]) == [1, 2, 3, 4, 5]
>>> sort_array([-2, -3, -4, -5, -6]) == [-6, -5, -4, -3, -2]
>>> sort_array([1, 0, 2, 3, 4]) [0, 1, 2, 3, 4]
"""
The last problem is an example with wrong example test cases in the original definition. It misleads the adaptive solution because a correct implementation is regarded as wrong and more trials are made. The last configuration in the sequence returns the right implementation, even though it does not pass the auto-generated assertions. This example demonstrates that:
- Our adaptive solution has a certain degree of fault tolerance.
- The success rate and inference cost for the adaptive solution can be further improved if correct example test cases are used.
It is worth noting that the reduced inference cost is the amortized cost over all the tasks. For each individual task, the cost can be either larger or smaller than directly using GPT-4. This is the nature of the adaptive solution: The cost is in general larger for difficult tasks than that for easy tasks.
An example notebook to run this experiment can be found at: https://github.com/microsoft/FLAML/blob/v1.2.1/notebook/research/autogen_code.ipynb. The experiment was run when AutoGen was a subpackage in FLAML.
Discussion
Our solution is quite simple to implement using a generic interface offered in autogen, yet the result is quite encouraging.
While the specific way of generating assertions is application-specific, the main ideas are general in LLM operations:
- Generate multiple responses to select - especially useful when selecting a good response is relatively easier than generating a good response at one shot.
- Consider multiple configurations to generate responses - especially useful when:
- Model and other inference parameter choice affect the utility-cost tradeoff; or
- Different configurations have complementary effect.
A previous blog post provides evidence that these ideas are relevant in solving math problems too.
autogen uses a technique EcoOptiGen to support inference parameter tuning and model selection.
There are many directions of extensions in research and development:
- Generalize the way to provide feedback.
- Automate the process of optimizing the configurations.
- Build adaptive agents for different applications.
Do you find this approach applicable to your use case? Do you have any other challenge to share about LLM applications? Do you like to see more support or research of LLM optimization or automation? Please join our Discord server for discussion.
For Further Reading
- Documentation about
autogenand Research paper. - Blog post about a related study for math.