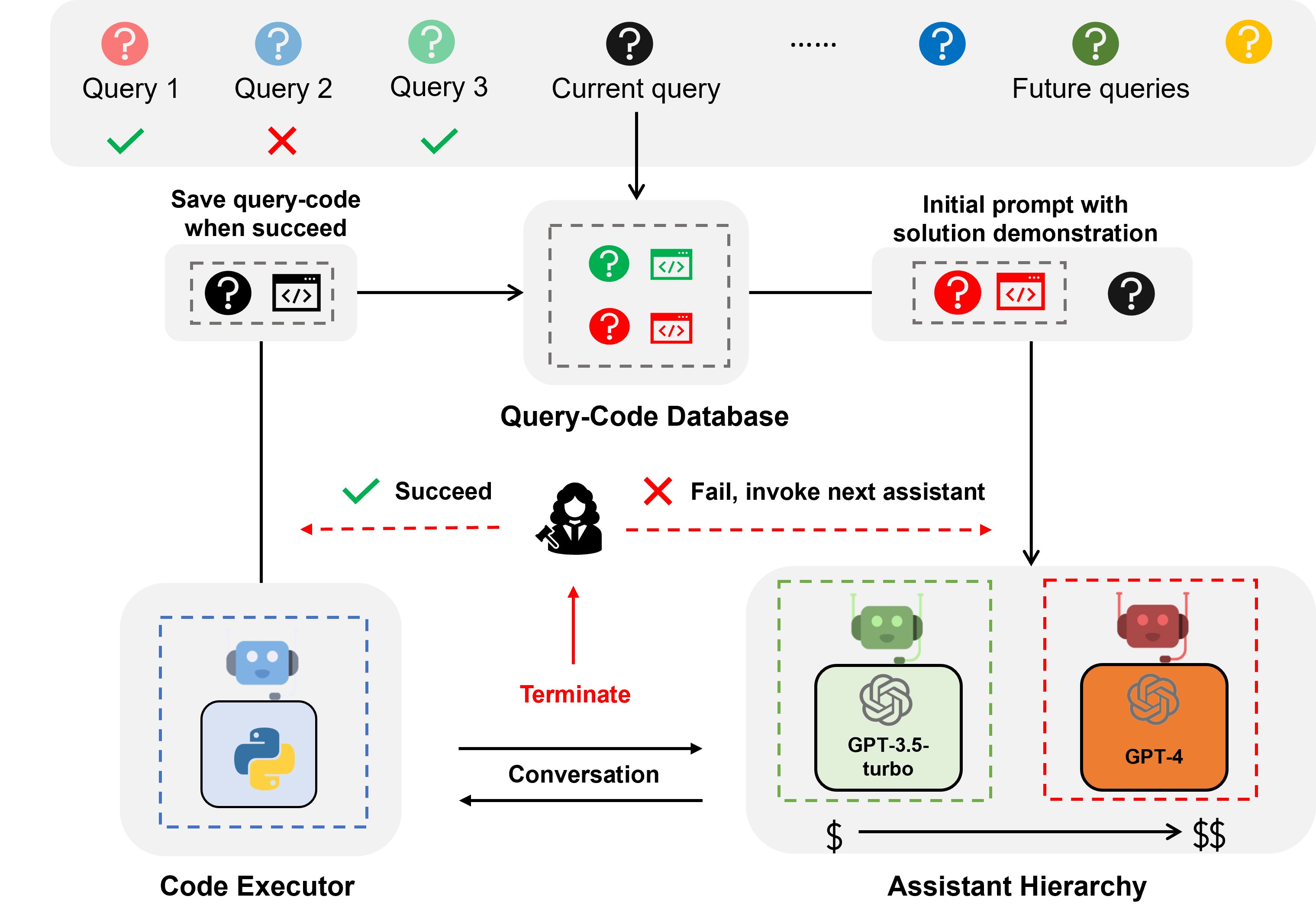
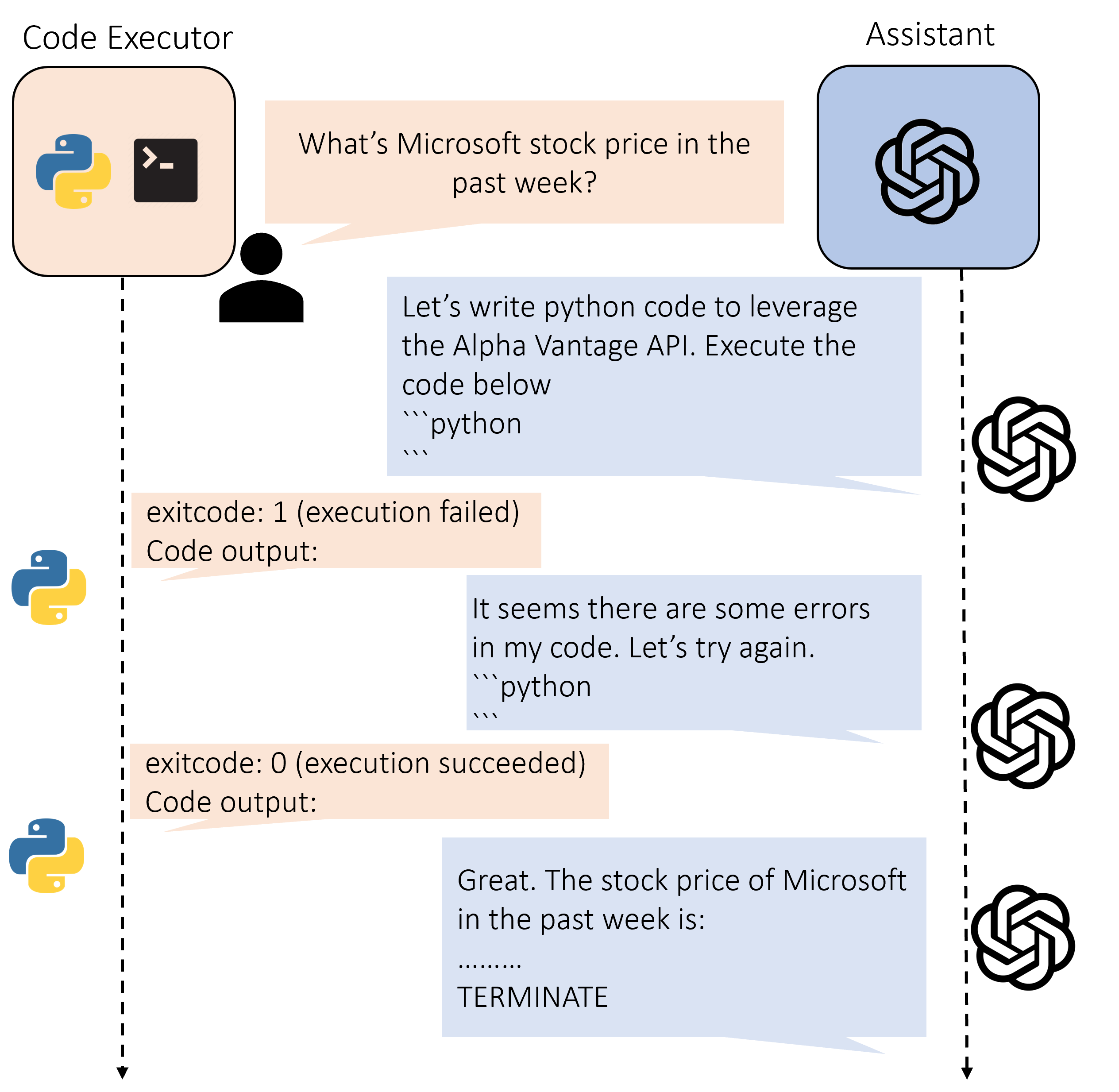
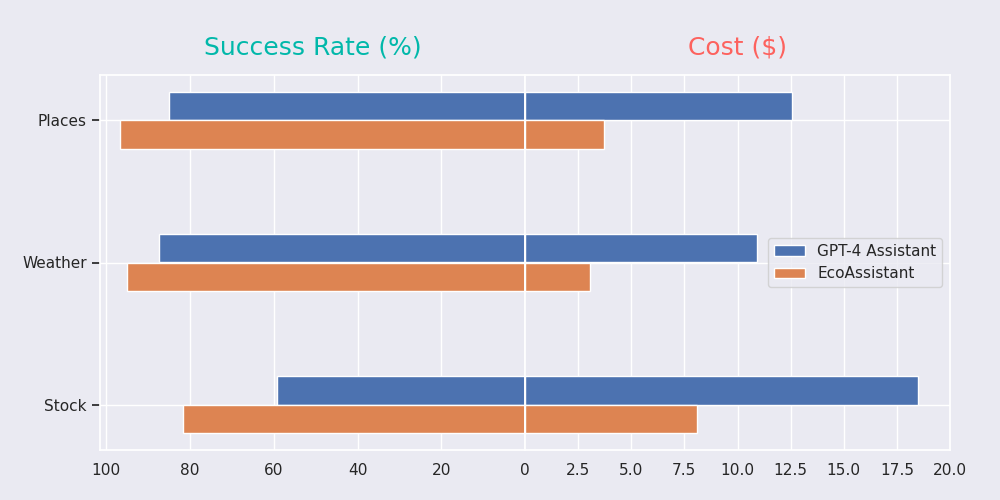
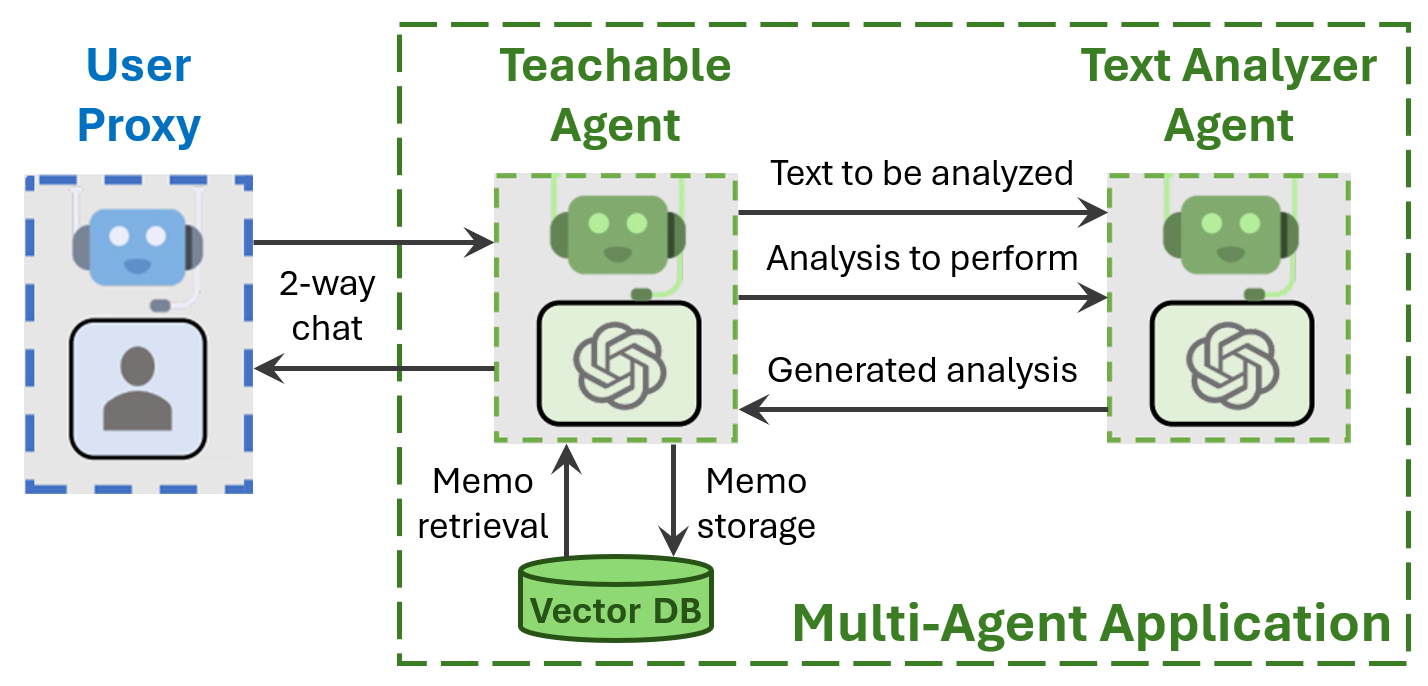
TL;DR
- AutoGen® offers detailed multi-agent observability with AgentOps.
- AgentOps offers the best experience for developers building with AutoGen in just two lines of code.
- Enterprises can now trust AutoGen in production with detailed monitoring and logging from AgentOps.
AutoGen is excited to announce an integration with AgentOps, the industry leader in agent observability and compliance. Back in February, Bloomberg declared 2024 the year of AI Agents. And it's true! We've seen AI transform from simplistic chatbots to autonomously making decisions and completing tasks on a user's behalf.
However, as with most new technologies, companies and engineering teams can be slow to develop processes and best practices. One part of the agent workflow we're betting on is the importance of observability. Letting your agents run wild might work for a hobby project, but if you're building enterprise-grade agents for production, it's crucial to understand where your agents are succeeding and failing. Observability isn't just an option; it's a requirement.
As agents evolve into even more powerful and complex tools, you should view them increasingly as tools designed to augment your team's capabilities. Agents will take on more prominent roles and responsibilities, take action, and provide immense value. However, this means you must monitor your agents the same way a good manager maintains visibility over their personnel. AgentOps offers developers observability for debugging and detecting failures. It provides the tools to monitor all the key metrics your agents use in one easy-to-read dashboard. Monitoring is more than just a “nice to have”; it's a critical component for any team looking to build and scale AI agents.
What is Agent Observability?
Agent observability, in its most basic form, allows you to monitor, troubleshoot, and clarify the actions of your agent during its operation. The ability to observe every detail of your agent's activity, right down to a timestamp, enables you to trace its actions precisely, identify areas for improvement, and understand the reasons behind any failures — a key aspect of effective debugging. Beyond enhancing diagnostic precision, this level of observability is integral for your system's reliability. Think of it as the ability to identify and address issues before they spiral out of control. Observability isn't just about keeping things running smoothly and maximizing uptime; it's about strengthening your agent-based solutions.

Why AgentOps?
AutoGen has simplified the process of building agents, yet we recognized the need for an easy-to-use, native tool for observability. We've previously discussed AgentOps, and now we're excited to partner with AgentOps as our official agent observability tool. Integrating AgentOps with AutoGen simplifies your workflow and boosts your agents' performance through clear observability, ensuring they operate optimally. For more details, check out our AgentOps documentation.

Enterprises and enthusiasts trust AutoGen as the leader in building agents. With our partnership with AgentOps, developers can now natively debug agents for efficiency and ensure compliance, providing a comprehensive audit trail for all of your agents' activities. AgentOps allows you to monitor LLM calls, costs, latency, agent failures, multi-agent interactions, tool usage, session-wide statistics, and more all from one dashboard.
By combining the agent-building capabilities of AutoGen with the observability tools of AgentOps, we're providing our users with a comprehensive solution that enhances agent performance and reliability. This collaboration establishes that enterprises can confidently deploy AI agents in production environments, knowing they have the best tools to monitor, debug, and optimize their agents.
The best part is that it only takes two lines of code. All you need to do is set an AGENTOPS_API_KEY in your environment (Get API key here: https://app.agentops.ai/account) and call agentops.init():
import os
import agentops
agentops.init(os.environ["AGENTOPS_API_KEY"])
AgentOps's Features
AgentOps includes all the functionality you need to ensure your agents are suitable for real-world, scalable solutions.

- Analytics Dashboard: The AgentOps Analytics Dashboard allows you to configure and assign agents and automatically track what actions each agent is taking simultaneously. When used with AutoGen, AgentOps is automatically configured for multi-agent compatibility, allowing users to track multiple agents across runs easily. Instead of a terminal-level screen, AgentOps provides a superior user experience with its intuitive interface.
- Tracking LLM Costs: Cost tracking is natively set up within AgentOps and provides a rolling total. This allows developers to see and track their run costs and accurately predict future costs.
- Recursive Thought Detection: One of the most frustrating aspects of agents is when they get trapped and perform the same task repeatedly for hours on end. AgentOps can identify when agents fall into infinite loops, ensuring efficiency and preventing wasteful computation.
AutoGen users also have access to the following features in AgentOps:
- Replay Analytics: Watch step-by-step agent execution graphs.
- Custom Reporting: Create custom analytics on agent performance.
- Public Model Testing: Test your agents against benchmarks and leaderboards.
- Custom Tests: Run your agents against domain-specific tests.
- Compliance and Security: Create audit logs and detect potential threats, such as profanity and leaks of Personally Identifiable Information.
- Prompt Injection Detection: Identify potential code injection and secret leaks.
Conclusion
By integrating AgentOps into AutoGen, we've given our users everything they need to make production-grade agents, improve them, and track their performance to ensure they're doing exactly what you need them to do. Without it, you're operating blindly, unable to tell where your agents are succeeding or failing. AgentOps provides the required observability tools needed to monitor, debug, and optimize your agents for enterprise-level performance. It offers everything developers need to scale their AI solutions, from cost tracking to recursive thought detection.
Did you find this note helpful? Would you like to share your thoughts, use cases, and findings? Please join our observability channel in the AutoGen Discord.