

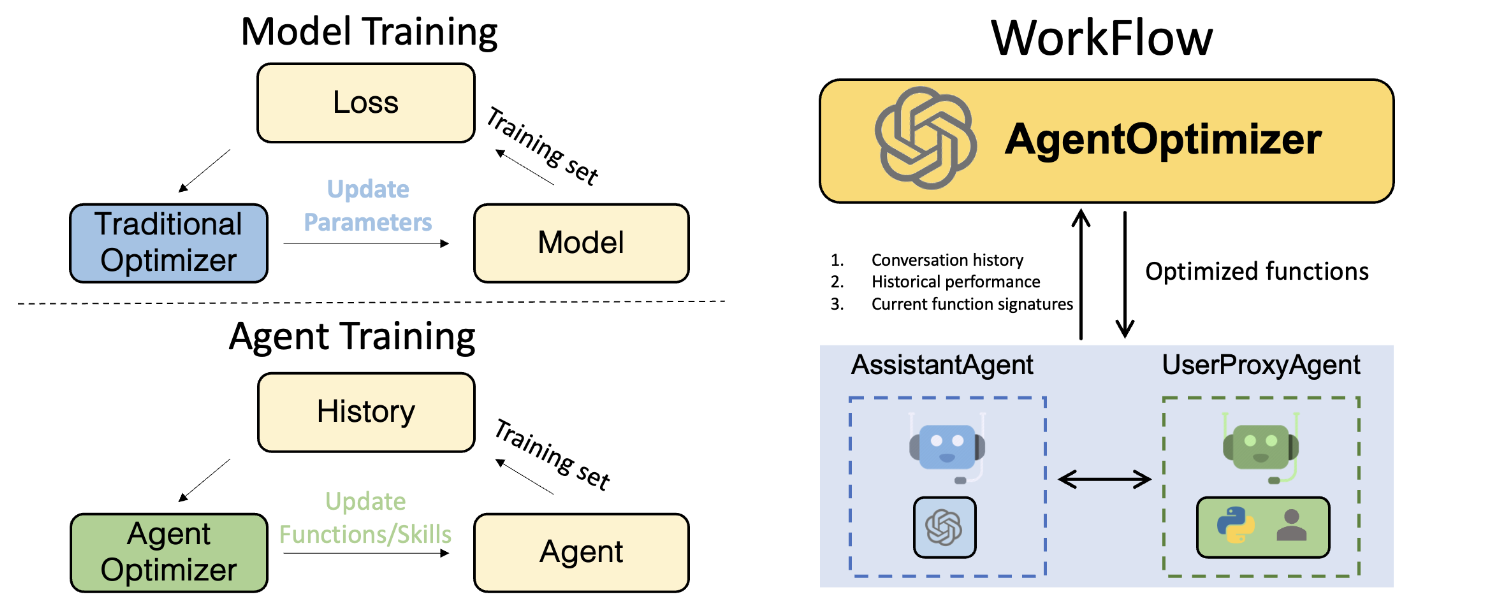
TL;DR: Introducing AgentOptimizer, a new class for training LLM agents in the era of LLMs as a service. AgentOptimizer is able to prompt LLMs to iteratively optimize function/skills of AutoGen agents according to the historical conversation and performance.
More information could be found in:
Paper: https://arxiv.org/abs/2402.11359.
Notebook: https://github.com/microsoft/autogen/blob/0.2/notebook/agentchat_agentoptimizer.ipynb.
Introduction
In the traditional ML pipeline, we train a model by updating its weights according to the loss on the training set, while in the era of LLM agents, how should we train an agent? Here, we take an initial step towards the agent training. Inspired by the function calling capabilities provided by OpenAI, we draw an analogy between model weights and agent functions/skills, and update an agent’s functions/skills based on its historical performance on a training set. Specifically, we propose to use the function calling capabilities to formulate the actions that optimize the agents’ functions as a set of function calls, to support iteratively adding, revising, and removing existing functions. We also include two strategies, roll-back, and early-stop, to streamline the training process to overcome the performance-decreasing problem when training. As an agentic way of training an agent, our approach helps enhance the agents’ abilities without requiring access to the LLM's weights.
AgentOptimizer
AgentOptimizer is a class designed to optimize the agents by improving their function calls. It contains three main methods:
record_one_conversation:
This method records the conversation history and performance of the agents in solving one problem. It includes two inputs: conversation_history (List[Dict]) and is_satisfied (bool). conversation_history is a list of dictionaries which could be got from chat_messages_for_summary in the AgentChat class. is_satisfied is a bool value that represents whether the user is satisfied with the solution. If it is none, the user will be asked to input the satisfaction.
Example:
optimizer = AgentOptimizer(max_actions_per_step=3, llm_config = llm_config)
# ------------ code to solve a problem ------------
# ......
# -------------------------------------------------
history = assistant.chat_messages_for_summary(UserProxy)
optimizer.record_one_conversation(history, is_satisfied=result)
step():
step() is the core method of AgentOptimizer.
At each optimization iteration, it will return two fields register_for_llm and register_for_executor, which are subsequently utilized to update the assistant and UserProxy agents, respectively.
register_for_llm, register_for_exector = optimizer.step()
for item in register_for_llm:
assistant.update_function_signature(**item)
if len(register_for_exector.keys()) > 0:
user_proxy.register_function(function_map=register_for_exector)
reset_optimizer:
This method will reset the optimizer to the initial state, which is useful when you want to train the agent from scratch.
AgentOptimizer includes mechanisms to check the (1) validity of the function and (2) code implementation before returning the register_for_llm, register_for_exector. Moreover, it also includes mechanisms to check whether each update is feasible, such as avoiding the removal of a function that is not in the current functions due to hallucination.
Pseudocode for the optimization process
The optimization process is as follows:
optimizer = AgentOptimizer(max_actions_per_step=3, llm_config = llm_config)
for i in range(EPOCH):
is_correct = user_proxy.initiate_chat(assistant, message = problem)
history = assistant.chat_messages_for_summary(user_proxy)
optimizer.record_one_conversation(history, is_satisfied=is_correct)
register_for_llm, register_for_exector = optimizer.step()
for item in register_for_llm:
assistant.update_function_signature(**item)
if len(register_for_exector.keys()) > 0:
user_proxy.register_function(function_map=register_for_exector)
Given a prepared training dataset, the agents iteratively solve problems from the training set to obtain conversation history and statistical information. The functions are then improved using AgentOptimizer. Each iteration can be regarded as one training step analogous to traditional machine learning, with the optimization elements being the functions that agents have. After EPOCH iterations, the agents are expected to obtain better functions that may be used in future tasks
The implementation technology behind the AgentOptimizer
To obtain stable and structured function signatures and code implementations from AgentOptimizer,
we leverage the function calling capabilities provided by OpenAI to formulate the actions that manipulate the functions as a set of function calls.
Specifically, we introduce three function calls to manipulate the current functions at each step: add_function, remove_function, and revise_function.
These calls add, remove, and revise functions in the existing function list, respectively.
This practice could fully leverage the function calling capabilities of GPT-4 and output structured functions with more stable signatures and code implementation.
Below is the JSON schema of these function calls:
add_function: Add one new function that may be used in the future tasks.
ADD_FUNC = {
"type": "function",
"function": {
"name": "add_function",
"description": "Add a function in the context of the conversation. Necessary Python packages must be declared. The name of the function MUST be the same with the function name in the code you generated.",
"parameters": {
"type": "object",
"properties": {
"name": {"type": "string", "description": "The name of the function in the code implementation."},
"description": {"type": "string", "description": "A short description of the function."},
"arguments": {
"type": "string",
"description": 'JSON schema of arguments encoded as a string. Please note that the JSON schema only supports specific types including string, integer, object, array, boolean. (do not have float type) For example: { "url": { "type": "string", "description": "The URL", }}. Please avoid the error \'array schema missing items\' when using array type.',
},
"packages": {
"type": "string",
"description": "A list of package names imported by the function, and that need to be installed with pip prior to invoking the function. This solves ModuleNotFoundError. It should be string, not list.",
},
"code": {
"type": "string",
"description": "The implementation in Python. Do not include the function declaration.",
},
},
"required": ["name", "description", "arguments", "packages", "code"],
},
},
}
revise_function: Revise one existing function (code implementation, function signature) in the current function list according to the conversation history and performance.
REVISE_FUNC = {
"type": "function",
"function": {
"name": "revise_function",
"description": "Revise a function in the context of the conversation. Necessary Python packages must be declared. The name of the function MUST be the same with the function name in the code you generated.",
"parameters": {
"type": "object",
"properties": {
"name": {"type": "string", "description": "The name of the function in the code implementation."},
"description": {"type": "string", "description": "A short description of the function."},
"arguments": {
"type": "string",
"description": 'JSON schema of arguments encoded as a string. Please note that the JSON schema only supports specific types including string, integer, object, array, boolean. (do not have float type) For example: { "url": { "type": "string", "description": "The URL", }}. Please avoid the error \'array schema missing items\' when using array type.',
},
"packages": {
"type": "string",
"description": "A list of package names imported by the function, and that need to be installed with pip prior to invoking the function. This solves ModuleNotFoundError. It should be string, not list.",
},
"code": {
"type": "string",
"description": "The implementation in Python. Do not include the function declaration.",
},
},
"required": ["name", "description", "arguments", "packages", "code"],
},
},
}
remove_function: Remove one existing function in the current function list. It is used to remove the functions that are not useful (redundant) in the future tasks.
REMOVE_FUNC = {
"type": "function",
"function": {
"name": "remove_function",
"description": "Remove one function in the context of the conversation. Once remove one function, the assistant will not use this function in future conversation.",
"parameters": {
"type": "object",
"properties": {
"name": {"type": "string", "description": "The name of the function in the code implementation."}
},
"required": ["name"],
},
},
}
Limitation & Future work
- Currently, it only supports optimizing the one typical user_proxy and assistant agents pair. We will make this feature more general to support other agent types in future work.
- The current implementation of AgentOptimizer is effective solely on the OpenAI GPT-4 model. Extending this feature/concept to other LLMs is the next step.