Are you unable to connect to your Virtual Machine? See this important information for
how to resolve.
Fraud detection is one of the earliest industrial applications of data mining and machine learning. This solution shows how to build and deploy a machine learning model for online retailers to detect fraudulent purchase transactions.
Fraud detection is typically handled as a binary classification problem, but the class population is unbalanced because instances of fraud are usually very rare compared to the overall volume of transactions. Moreover, when fraudulent transactions are discovered, the business typically takes measures to block the accounts from transacting to prevent further losses. Therefore, model performance is measured by using account-level metrics, which is discussed in the For the Data Scientist page.
Select the method you wish to explore:
On the VM created for you using the 'Deploy to Azure' button on the Quick Start page, the SQL Server 2017 database 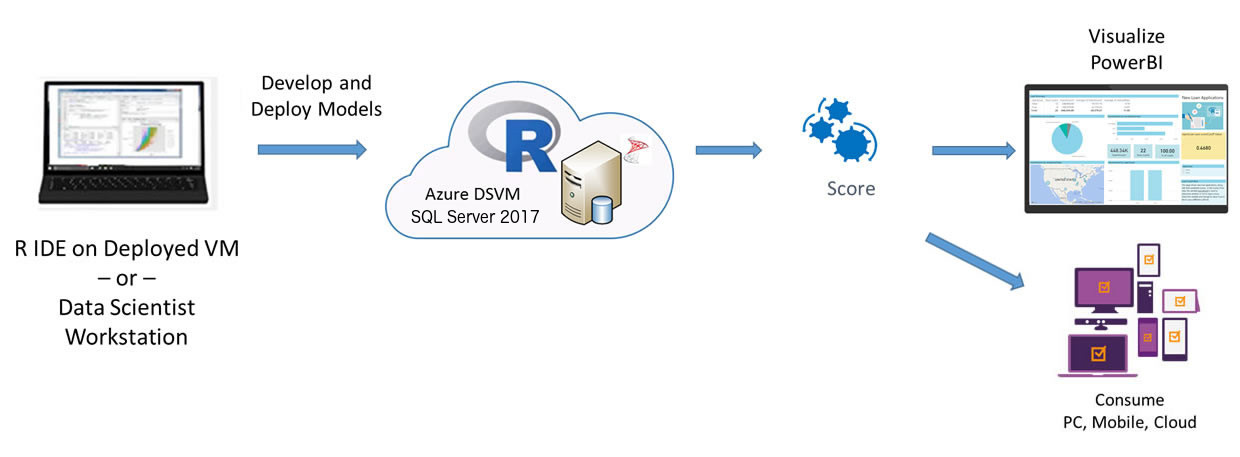
Fraud contains all the data and results of the end-to-end modeling process.
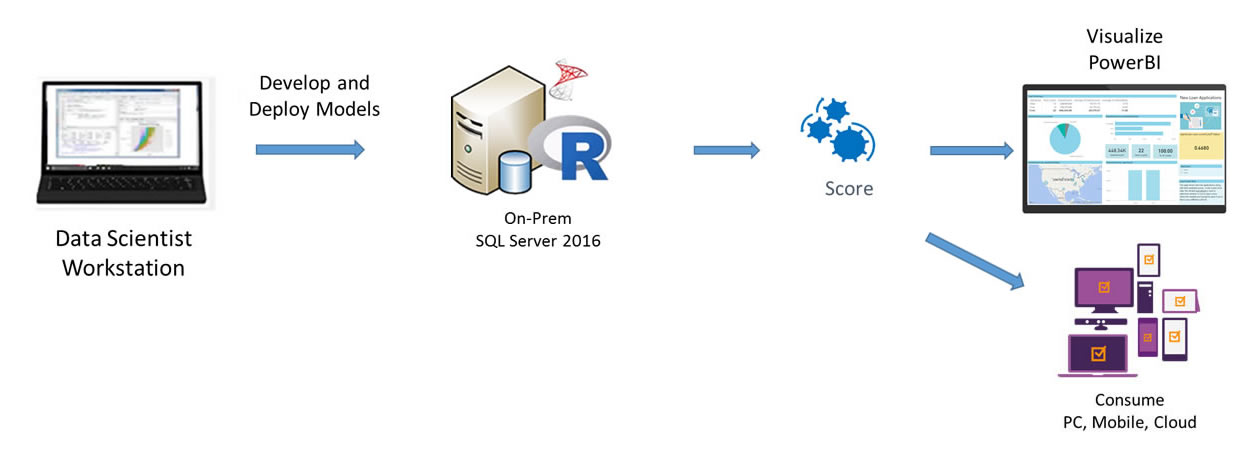
For customers who prefer an on-premise solution, the implementation with SQL Server ML Services is a great option that takes advantage of the powerful combination of SQL Server and the R language. A Windows PowerShell script to invoke the SQL scripts that execute the end-to-end modeling process is provided for convenience.
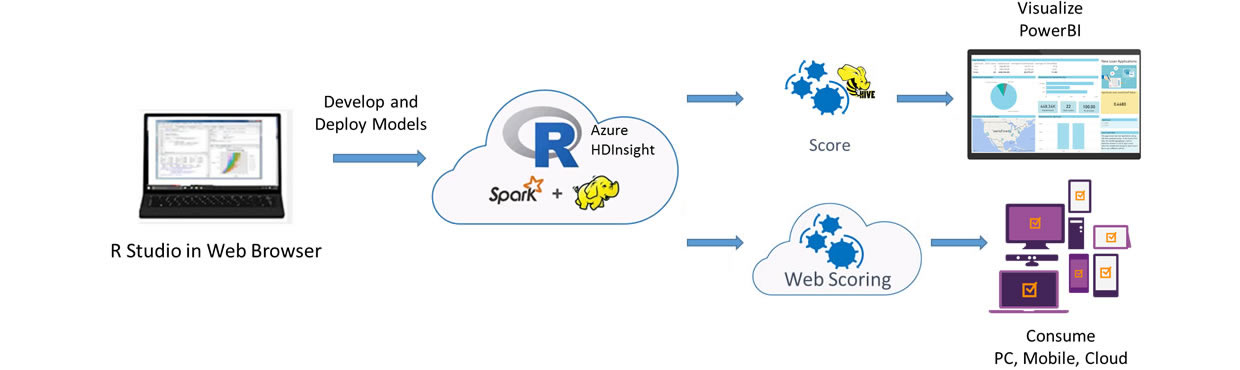
This solution shows how to pre-process data (cleaning and feature engineering), train prediction models, and perform scoring on the HDInsight Spark cluster with Microsoft ML Server deployed using the 'Deploy to Azure' button on the Quick Start page.
HDInsight Spark cluster billing starts once a cluster is created and stops when the cluster is deleted. See these instructions for important information about deleting a cluster and re-using your files on a new cluster.